
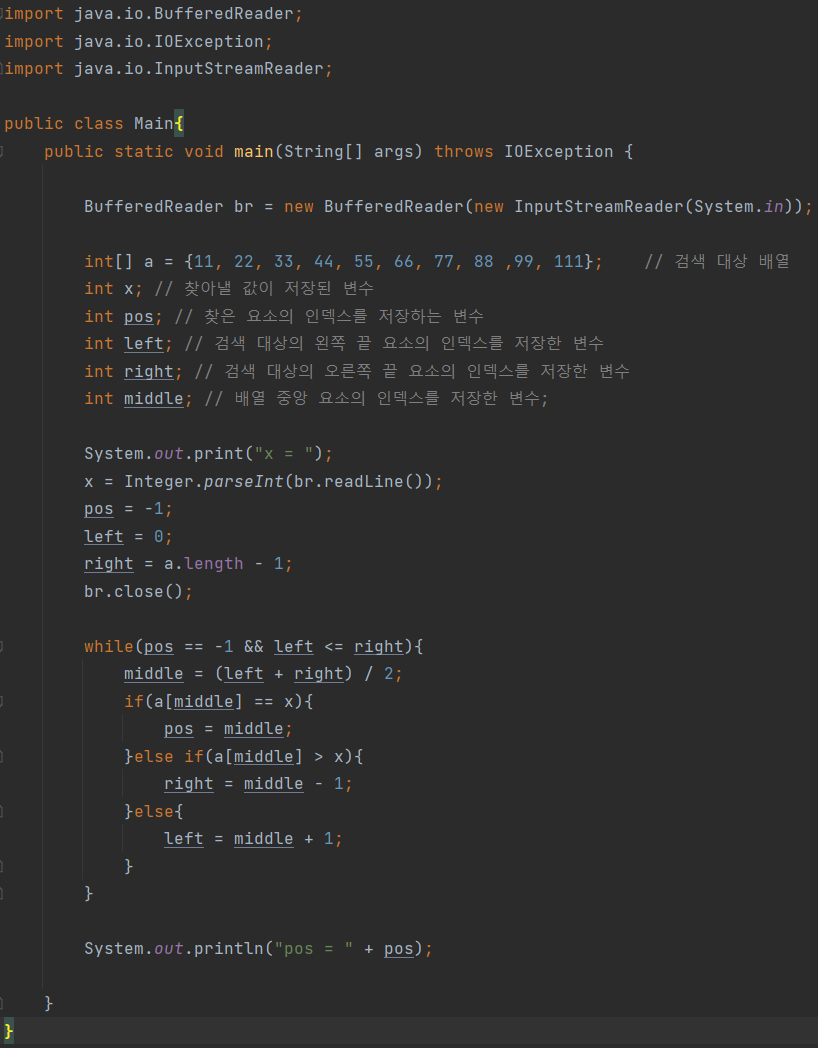
이진 검색 알고리즘은 정렬된 리스트에서 특정한 값의 위치를 찾는 알고리즘이다.
처음 중간의 값을 임의의 값으로 선택하여, 그 값과 찾고자 하는 값의 크고 작음을 비교하는 방식을 이용한다.
순서
1. 검색 대상 배열의 중앙 요소를 확인하여, 다음 중 하나를 실행한다.
- A - 찾는 값과 같다면, 인덱스를 표시하고 종료한다.
- B - 찾는 값보다 크다면, 검색 대상을 앞쪽으로 좁힌다.
- C - 찾는 값보다 작으면, 검색 대상을 뒤쪽으로 좁힌다.
2. B 또는 C의 경우 검색 대상이 없어질 때까지 처리를 반복한다.
필요한 변수
- 검색 대상 배열
- 찾아낼 값이 저장된 변수
- 찾은 요소의 인덱스를 저장하는 변수 (발견되지 않았으면 -1 저장)
- 검색 대상의 왼쪽 끝 요소의 인덱스를 저장한 변수(left)
- 검색 대상의 오른쪽 끝 요소의 인덱스를 저장한 변수(right)
- 배열 중앙 요소의 인덱스를 저장한 변수(middle) = (left + right) / 2
ㄴ> 요소 수가 짝수일 때 정중앙은 존재하지 않는다. -> ex) (0 + 9) / 2 = 4가 중앙이 된다.
예시
실행
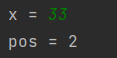
선형 검색과 이진 검색은 모두 데이터 검색을 목적으로 사용하는 알고리즘이다.
배열의 처음부터 끝까지 요소를 순차적으로 확인하는 선형 검색보다 배열을 2개로 나누면서 검색 범위를 좁히는 이진 검색이 더 효율적이다.
선형 검색의 시간 복잡도는 원소의 갯수만큼 O(N)이다.
(요소 수가 100개라면 100번, 1000개라면 1000번)
이진 검색의 시간 복잡도는 N개의 데이터를 계속 분할하여 마지막 하나가 될 때까지 처리한 횟수이기 때문에
O(log2N) 이다.

웹 개발 공부 기록
저 이거 어제 정처기 책에서 봤어여 ㅋ