1달이라는 시간을 들여 "서브웨이 꿀조합 추천 커뮤니티-왔썹"을 개발했습니다. 결론적으로 CRA와 같은 보일러 플레이트 없이 초기 세팅부터 최적화까지 직접 경험 할 수 있었던 의미있는 프로젝트였습니다.
React를 사용하여 진행한 프로젝트 첫번째 프로젝트 였지만 많은 것을 학습할 수 있던 귀중한 경험이되었습니다.
제로베이스 오프라인 수강을 끝내고 약 1달간 React와 TypeScript에 대해 학습했습니다. React는 Udemy 강의를 수강 했고 TypeScript는 함께 공부하는 친구들과 문서를 보고 토론하고 간단한 실습을 해보면서 익혔습니다.
이전 프로젝트를 같이 진행했던 친구들과 같이 공부했던 또 다른 친구 한 명과 함께 FE개발자 5명으로 프로젝트를 시작했습니다.
🥅 프로젝트 목표
이론을 익히는 것도 중요하지만 실습을 통해 익혀야 본인 것이 된다는 확신 아래 프로젝트를 시작했습니다.
제가 이번 프로젝트로 달성하고자 목표 다음과 같았습니다.
- 문서와 간단한 프로젝트를 진행했을 때 느껴지지 않았던 TypeScript의 장단점을 직접 경험해보자
- React hook과 상태관리에 익숙해지고 react-router-dom@6.4를 통해 최신 문법을 활용해보자
- CRA를 사용하지 않고 직접 webpack setting 및 최적화를 해보자
- 프로젝트를 배포하고 최적화까지 해보자
프로젝트가 끝난 지금 4가지 달성 목표를 정량적으로 평가한다면 100점 만점에 80점 정도 줄 수 있을 것 같습니다. 프로젝트를 하면서 몰랐던 문제를 시원하게 해결했다고 하기 어렵고, 아직 정말 능숙하게 React를 다룬다고 당당하게 말할 수는 없기 때문에 아쉬움의 정도 만큼 20점을 깎았습니다.
🏗️ 초기 기획
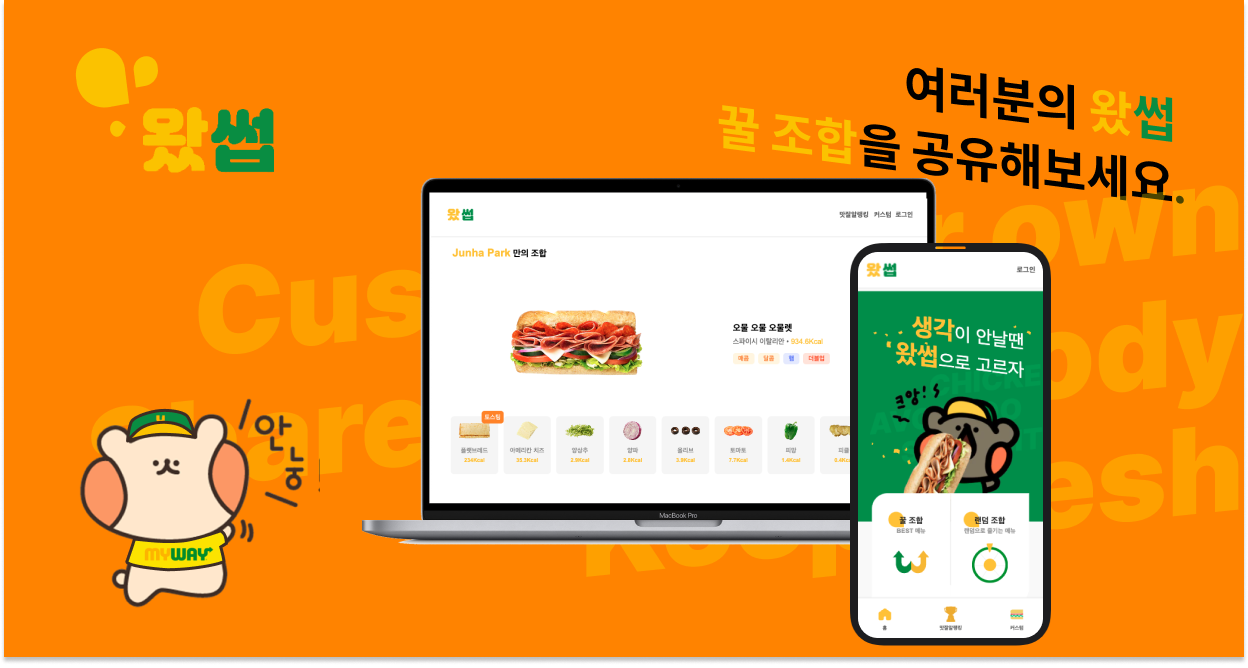
초기 기획 과정을 회고 하기 이전에 먼저 "왔썹"이 탄생한 배경과 어떤 서비스인지에 대해 설명드리겠습니다.
왜 이 주제를 선정하게 되었는가?
공공데이터를 활용한 프로젝트를 진행하려고 했습니다. 그러나 끌리는 주제에 맞게 데이터를 활용하려면 규모가 너무 커지게 될 것으로 예상되어 기간내에서 프로젝트를 완성하기 힘들고 본래 프로젝트의 목표을 잃고 공공데이터 활용에 더 많은 시간을 쏟게 될 것 같았습니다.
만들면서도 재미있고 생활에 쓸법한 캐쥬얼한 아이디어를 선정하기로 결정했습니다. 스터디를 하면서 스터디룸에서 쓰레기를 최소화할 수 있는 서브웨이를 자주 주문해 먹던 것에서 착안해 서브웨이 꿀조합을 만들어주는 서비스를 생각하게 되었습니다. 매번 서브웨이 꿀조합을 검색하지 않고 인기있는 꿀조합을 랭킹 순으로 볼 수 있고 랜덤으로 꿀조합을 제공하는 서비스를 만들어서 제공하고 의견을 나눌 수 있는 기능도 추가하기로 했습니다.
그래서 왔썹은 어떤 기능이 있는가?
크게 5가지 기능으로 나눌 수 있습니다.
- 원하는 카테고리에 맞는 꿀조합 찾기
- 랜덤 꿀조합 만들기
- 나만의 꿀조합 만들기
- 좋아요/최신 순 꿀조합 보기
- 꿀조합 커뮤니티 기능
이 중에서 저는 꿀조합 커뮤니티 기능에 해당하는 꿀조합 상세페이지, 댓글 기능, Auth 등을 담당했습니다.
기술 스택 선정
프로젝트에서 사용된 주요 기술은 다음과 같습니다.
- react@18.2.0
- react-router-dom@6.4.4
- recoil@0.7.6
- emotion/react@11.10.5
- firebase@9.14.0
우리가 만들 서비스가 캐쥬얼하고 짧을 시간안에 완성을 목표로 했기때문에 사용할 기술도 그에 따라 정해졌습니다. 또한 기술 변화가 빠른 프론트엔드 업계의 환경을 고려하여 최신 버전의 제품에 대응할 수 있는 역량을 기르고자 했습니다.
제품(라이브러리)별 선정 배경
React18
1달간 공부했던 React 사용법을 익히고 다양한 상황에서 hook 사용법을 익히기 위해 사용했습니다. 또한 React 최신 문법 사용법을 익히고 에러를 디버깅하며 직접적으로 학습하기 위해 선정했습니다.
react-router-dom@6.4
새로추가된 loader, action, errorElement 등 기능을 활용해 컴포넌트 구현부의 코드를 clean하게 만들기 위해 react-router-dom의 최신 버전을 도입했습니다. 하지만 이로 인해 최적화 단계에서 문제가 생겼습니다. 시행 착오에 대해서는 다음 단에서 설명 드리겠습니다.
Recoil
상태관리 tool의 근본이자 동영상 강의로 학습한 Redux를 사용하려고 했으나, 세팅해야할 것이 많고 부수적인 라이브러리 사용이 만하지는 Redux 사용이 꺼려졌습니다.
가벼운 상태관리 tool을 경험하고 싶었고 React를 개발한 Meta에서 개발한 Recoil을 사용하기로 결정했습니다.
Recoil은 비동기 처리를 위한 추가적인 라이브러리도 필요없으므로 가벼고 사용하기 쉽다는 저희의 니즈와 맞아 떨어졌습니다.
React-Query 사용을 고민해보았지만 비동기 처리가 많지 않았고 React-Query의 또 다른 기능인 캐싱을 활용하기 어렵다고 판단되어 Recoil을 최종적으로 결정했습니다.
Emotion
이전 프로젝트 동안 SaSS를 활용해서 개발을 해왔기 때문에 실제 기업에서 활용하는 CSS-in-JS 라이브러리를 활용하고자 했습니다. styled-component 보다 가볍고 작은 번들 사이즈를 가지고 있고 styled-component와의 차이점을 직접 경험해보고자 선택했습니다.
Firebase
FE개발자로만 이루어진 프로젝트였기 때문에 serverless 제품을 선정했고 동영상 강의로 학습한 경험이 있는 Firebase를 활용하기로 결정했습니다. 사용자가 쉽게 접근할 수 있는 OAuth 기능을 쉽게 제공해주며 이미지 저장소도 제공해주므로 저희가 처한 환경에서 가장 적합한 serverless 제품이었습니다.
BDD & SDD 프로젝트 설게 방법론
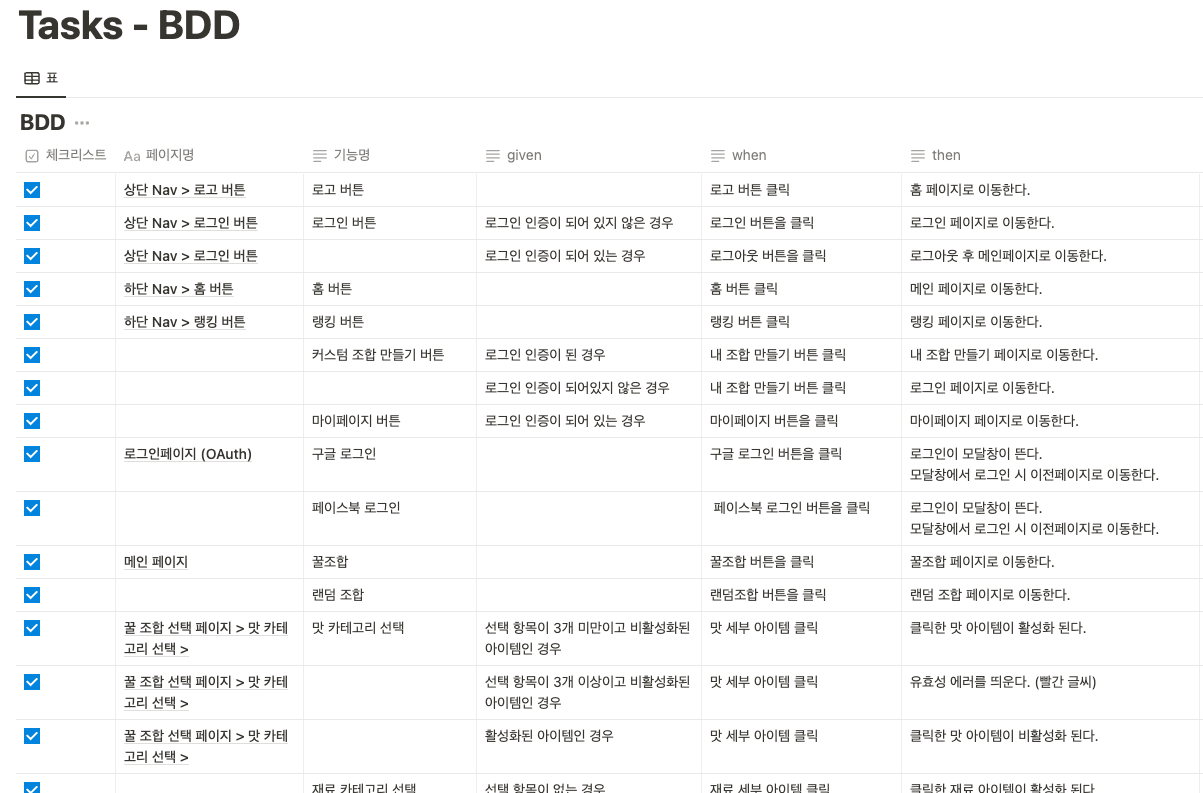
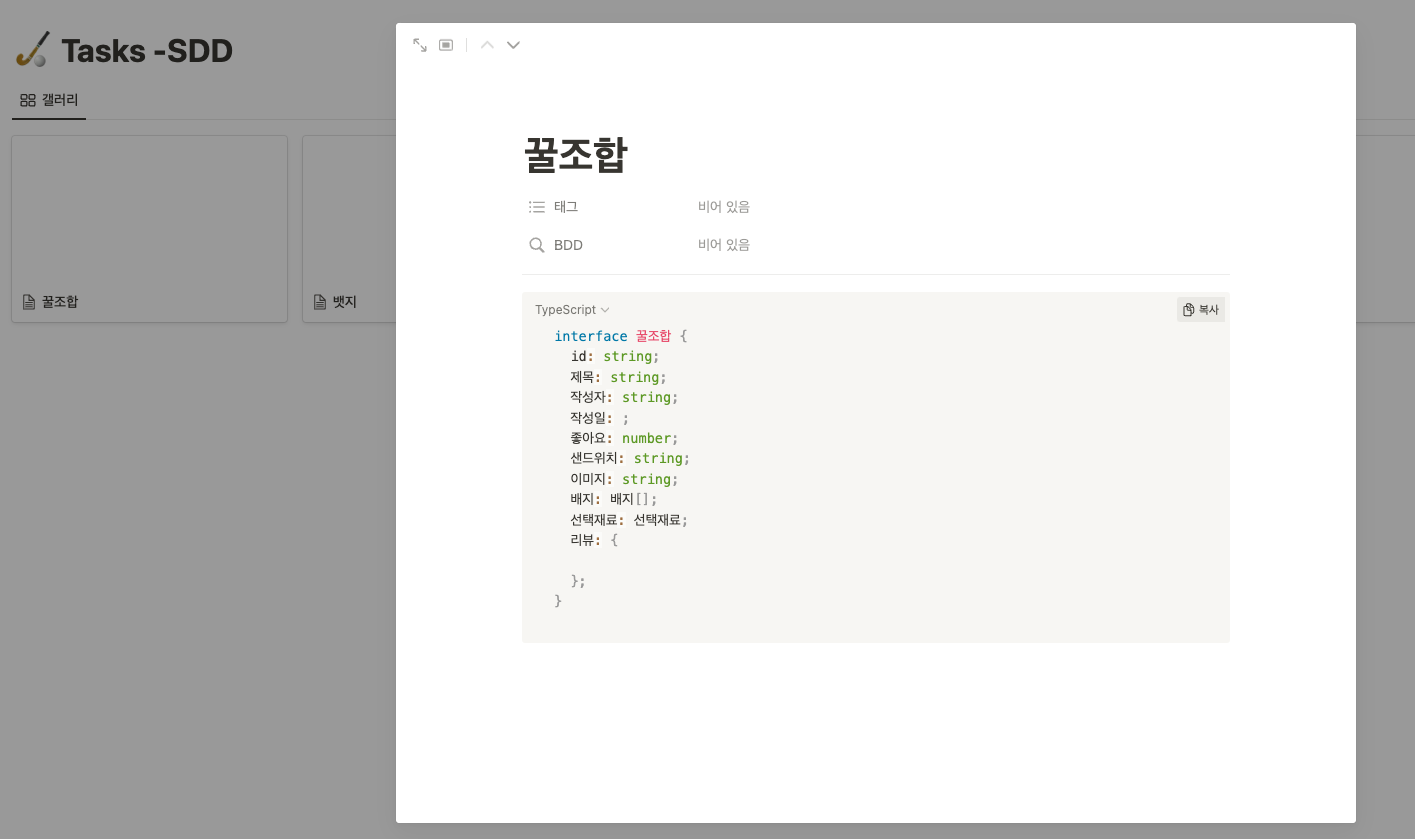
각 화면과 그에 따른 task들을 명확하게 파악하는 것이 프론트엔드에서 정확한 커뮤니케이션의 목표일 것입니다. 이번 프로젝트에서는 BDD & SDD 개발 방법론을 기반으로 화면별 task와 schema 별 데이터를 만들었습니다.
BDD에 입각하여 먼저 피그마로 작업한 화면을 기준으로 모든 동작의 경우의 수를 나누어 기능을 명확히 했습니다. 개발 중 기획 단계에서 잘 못된 점들이 있어 수정하긴 했지만 개발을 함에 있어서 task들을 파악하고 진행도를 파악할 수 있는 좋은 지표가 되었습니다.
SDD에 입각해여 화면별 데이터에 대하여 정리했습니다. SDD를 만들면서 각 화면에 들어갈 데이터의 type들을 설정했고 server와 통신할 데이터 여부와 NoSQL 구조를 만들 수 있는 의미있는 작업이 되었습니다. 이 작업을 통해 협업을 하면서 데이터 스키마가 상이하여 발생하는 문제를 크게 해결 할 수 있었고 네이밍도 통일할 수 있었습니다.
BDD: 화면 별 테스트를 파악할 수 있다.
SDD: 데이터 네이밍 문제를 해결하고 데이터 스키마를 통일 할 수 있다.
😅 고민과 시행 착오, 그리고 배운 것
Webpack 설정과 최적화
온라인에 많은 초기 설정 방법이 있지만 기본적인 webpack 구조를 알기위해 팀원 각각 우리가 선정한 라이브러리들을 사용할 수 있도록 setting 하는 시간을 가졌습니다. 그 중 가장 어려웠던 것은 typeScript 설정이었습니다. tsconfig 설정과 babel설정과 webpack설정이 서로 묶여있어 어려움이 있었습니다. 또한, Webpack 버전이 올라가면서 내장된 plugin도 많았습니다. 생산성을 높이기 위해 tsconfig의 다양한 컴파일 옵션을 파악하는 습관을 기르고 유용한 plugin들을 찾고 적절하게 사용할 수 있는 능력이 중요하다는 것을 배웠습니다.
Webpack 최적화
code splitting
기능 개발을 마치고 lighthouse 검사를 했을 때 결과는 충격적이었습니다. performance 부분에서 18점이라는 저조한 점수가 나왔기 때문입니다. Metrics를 살펴보니 js 파일이 너무 큰 것이 원인 중 하나였다. 그리하여 우리는 본격적으로 code splitting을 하기로 결정했습니다.
webpack-bundle-analyzer로 파악한 결과 firebase와 react에서 매우 큰 용량을 차지하는 것을 확인 했습니다.
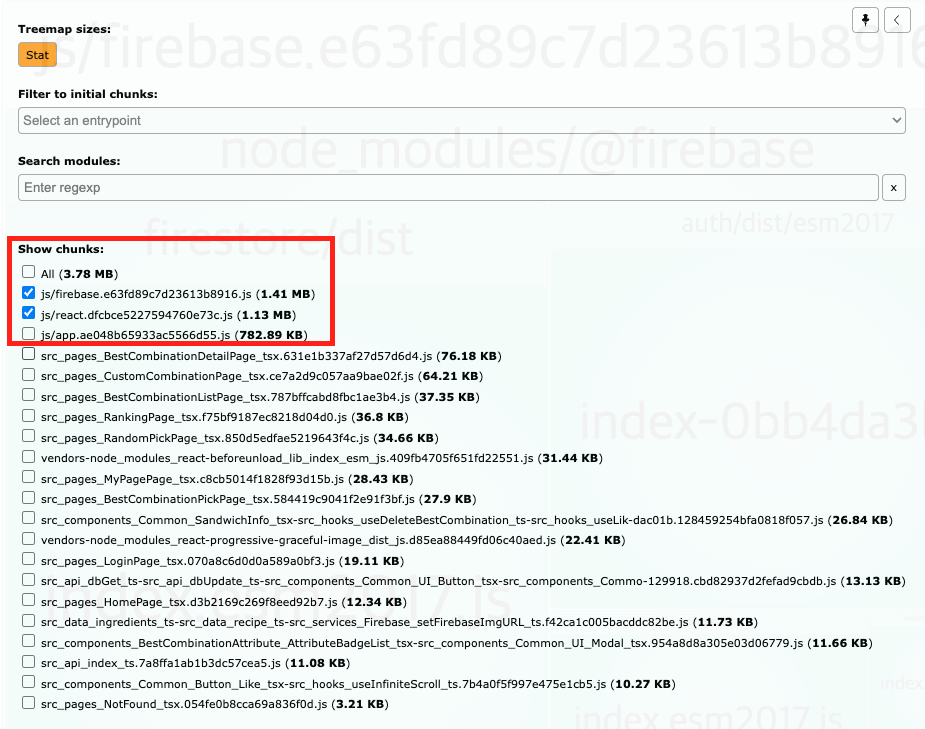
총 3.78MB 중 Firebase가 1.41MB, React관련 라이브러리가 1.13MB를 차지하는 것을 확인 할 수 있었습니다.

위와 같이 optimization을 활용하여 가장 배보다 배꼽이 큰 Firebase와 React 코드를 splite 했습니다. 이렇게 간단한 설정만으로 Performance 점수가 크게 올라갔고 React 관련 최적화 작업 이후에 18점에서 91점으로 performance 점수가 5배 이상 상승한 것을 확인 할 수 있었습니다.
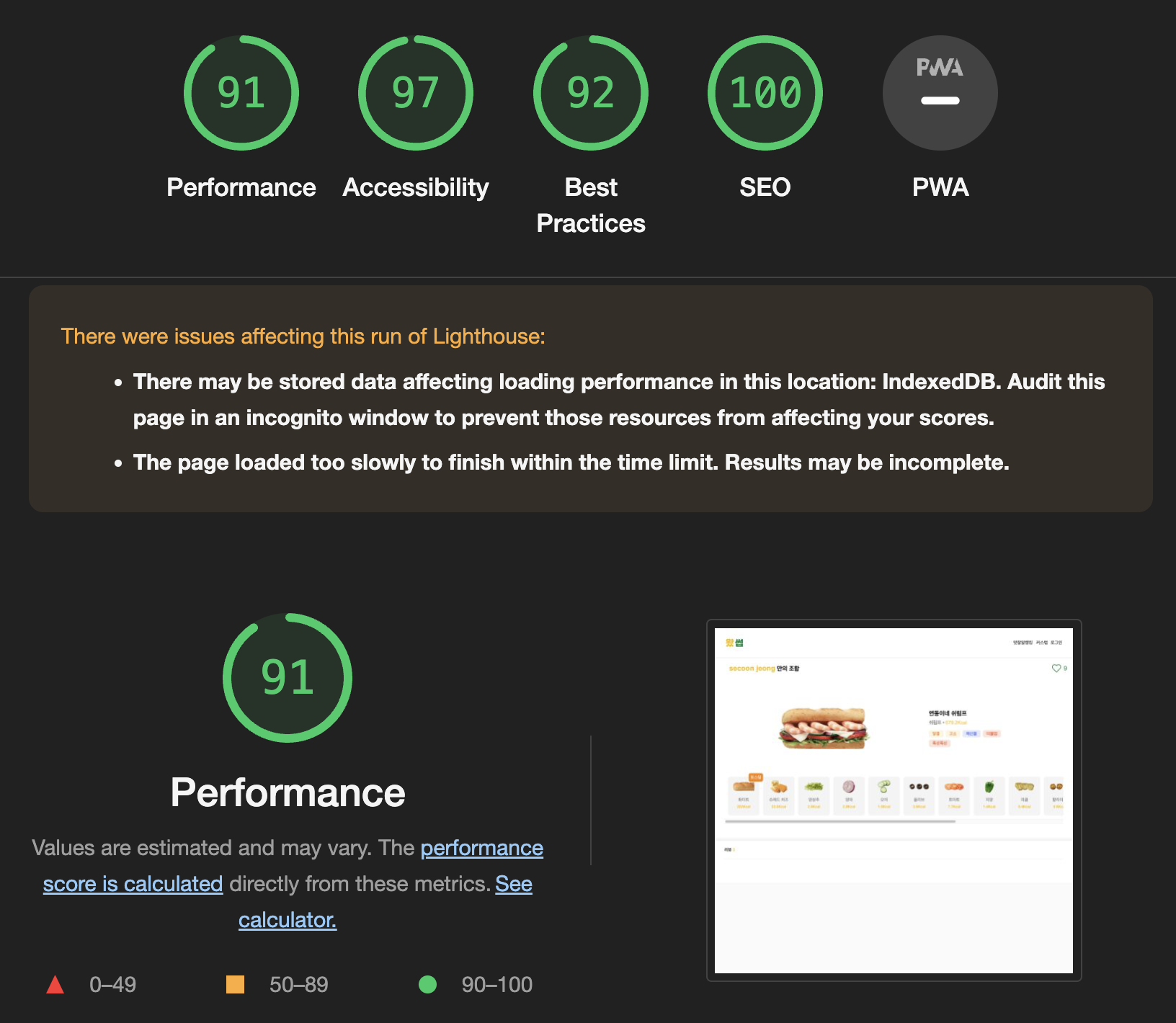
(현재 가장 많은 감점 요인은 이미지 로딩 시 CDN 네트워크 속도에 따른 Largest Contentful Paint 문제입니다.)
webpack merge
배포 테스트를 실시하면서 실행 mode에 따라 웹팩의 설정이 상이하게 되었습니다. dotenv, webpack-bundle-analyzer, CopyPlugin, MiniCssExtractPlugin 사용여부와 속성이 상이 했기 때문에 빌드시에는 주석처리를 하는 등 코드가 우아하지 못해지는 문제가 있었습니다.
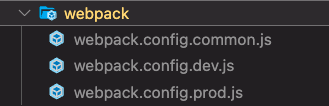
이러한 문제를 해결하는 webpack merge를 내장하고 있다는 사실을 알았고 위와 같이 webpack 디렉토리를 만들어 mode 별 webpack 설정을 분리했습니다.
webpack을 설정하면서 유용한 플러그인이 정말 많다는 것을 느꼈고 다양한 프로젝트를 살펴보면서 생산성 향상을 위해 webpack 설정에 대한 꾸준한 관심을 가져야겠다는 생각이 들었다.
한글 코딩 컨벤션 - 집현전 프로젝트
이전 프로젝트에서 비즈니스 로직부의 네이밍 규칙이 어그러지고 명확성이 떨어지는 경우를 경험했습니다. 이번 프로젝트에서는 비즈니스 로직 부에서 사용하는 용어를 쉽게 통일하고 가독성있게 활용하기 위한 방법을 찾아보던 중 '토스페이먼트에서 사용하고 있는 한글 코딩 컨벤션'을 활용했습니다.
번역으로 처리하기 애매한 '꿀조합'과 같은 단어를 자연스럽게 처리할 수 있었고 영어 네이밍을 하는 것보다 명확한 네이밍을 할 수 있다는 장점이 있었지만 여러가지 시행착오가 가장 많았던 문제이기도 했습니다.
컨벤션 규칙상 가독성을 위해 한글과 알파벳을 혼용하지 않기로 결정했는데 'id'와 같이 한글보다 영어가 더 명확한 경우에는 오히려 더 가독성이 좋기도 했습니다. 또한 useState를 활용하면서도 어색해지는 문제가 있었습니다.
const [꿀조합id, 꿀조합id_수정] = useState<string|null>(null)위와 같이 코드를 작성하게 되는데 익숙해지는데 시간이 걸렸습니다.
또한, FireStore Collection을 sort를 하기위해 index를 설정하는 부분에서 영문만 지원하는 문제가 있어 결국 영문으로 일부 변수명을 수정하는 경우도 생겼습니다.
위와 같은 문제들이 자주 발생 했기 때문에 주기적으로 회의를 통해 컨벤션 문제를 공유하고 고민하고 통일하는 시간을 가졌습니다. 시간이 지나면서 점차 정리되었고 식별자 네이밍에 더 집중할 수 있는 계기가 되었습니다.
TypeScript
type과 interface 사이
type과 interface 중에 어떤 것을 사용해야하는지 선택에 고민이 있었습니다. 개발 초기에는 type과 interface 사용에 대한 컨벤션을 명확히 만들어 두지 않아 type과 interface를 각자 혼동해서 사용하고 있었습니다. 기능 개발을 어느 정도 마치고 팀원들과 프로젝트 중간 점검을 하면서 많은 타입이 중복된다는 것을 파악했고 중복을 제거하기위한 필요성을 느꼈습니다. 이 시점에서 인터페이스 확장을 적극적으로 활용했습니다. 이후 interface를 사용하여 타입 지정을 하기로 결정했고 props와 같이 일시적으로 쓰이는 부분에서는 type을 사용하기로 컨벤션을 정했습니다.

라이브러리를 사용하면서 type 지키기
TypeScript를 활용하면서 첫번쨰로 부딧힌 문제 중 하나가 라이브러리의 객체에 대한 타입 지정이었습니다. 처음에는 무슨 문제인지 몰라 당황하기도하고 object 타입이나 function 타입을 꺼림직하게 지정하기도 했습니다. 프로젝트를 점차 진행하면서 vscode hint를 보면서 라이브러리가 사용하는 declare를 확인하여 어떤 객체로 타입이 지정되어 있는지 어떤 객체에서 확장 받고 있는지를 확인 할 수 있게 되었습니다. TypeScript를 활용하면서 라이브러리의 구조를 더 정확히 파악할 수 있게 된 경험이었습니다.
type assertion을 해야하나
TypeScript 이론을 공부하면서 공감할 수 있었던 것 중 한 가지가 타입 단언을 피하라는 것이었었습니다. 하지만 계속해서 발생하는 타입 오류를 해결하기 위해서는 타입 단언이 필수적인 부분이 많았습니다. 특히, 서버에서 데이터를 내려받는 부분, params를 받는 부분에서 타입 단언을 쓰게 되었습니다. 비동기 처리 실패가 되었을 경우에는 error 페이지로 이동하게 되므로 무조건적으로 data를 받는 부분에서는 타입 단언을 사용해야 했습니다.

무조건 적으로 정상적인 params가 존재하므로 타입 단언 사용
TypeScript를 더 잘 사용하기 위해서 다양한 상황을 많이 접하는 것이 중요하다고 느꼈습니다. 또한, 다양한 상황에서 비교적 정답에 가까운 선택을 하기위해 'Effective TypeScript'와 같은 책을 보며 시야를 넓여야 한다는 것을 깨닳았습니다.
댓글 무한스크롤 컨트롤
댓글 기능을 개발하면서 custom hook과 useState, useEffect, useRef를 복합적으로 활용할 수 있는 경험이 되었습니다. 특히 기억에 남는 것은 useState와 useRef의 활용법입니다.
댓글 무한스크롤를 적용하여 firebase에서 댓글 목록을 순차적으로 가져오기 위해서는 가져온 댓글 목록의 마지막 querySnapshot의 마지막 문서를 저장할 필요가 있었습니다. 초기 useState로 댓글 정보를 저장했으나 useState가 비동기적으로 처리되기 때문에 firebase 작업과 데이터 sync를 맞추는데 문제가 있었습니다. 계속해서 null이 담겨져 무한 스크롤 기능이 동작하지 않았습니다.
이러한 고민을 동료들에게 공유했고 useRef를 통해 해결 할 수 있었습니다.
const lastDocument = useRef<DocumentData | null>(null);
...
lastDocument.current = 쿼리스냅샷.docs[쿼리스냅샷.docs.length - 1] ?? null;
댓글_목록_수정(prev => [...prev, ...댓글_목록]);위 코드와 같이 useRef로 쿼리스냅샷의 마지막 문서를 저장하고 댓글 목록을 수정해서 view를 re-rendering하도록 코드를 수정했습니다.
추가적으로 알아본 내용은 다음과 같습니다.
useRef는 일반적인 JS객체이므로 heap 영역에 저장됩니다. 그러므로 애플리케이션이 종료되거나 GC 될 때까지 같은 메모리 주소를 유지하게되고, === 연산이 true 값을 반환할 수 있습니다. 또한 값이 바뀌어도 re-rendering이 발생하기 않습니다.
컴포넌트 내부에 변수를 선언하는 경우는 rendering이 될때 마다 값이 초기화되는 문제점이 있으므로 위와 같이 유지되어야할 변수로 사용하는 경우에는 useRef를 사용하는 방법으로 문제를 해결할 수 있다는 것을 알게 되었습니다.
아직React hook을 사용법을 더 명확히 알아야 된다는 사실을 인지했고, 다시 한 번 겸손하게 공부할 수 있는 계기가 되었다.
Firebase의 한계
Realtime Database와 FireStore Query 다루기
동영상 강의에서 활용해 보았고 Realtime Database는 간단한 query를 제공하고 있다는 사실을 파악하여 초기 개발 시에 Realtime Database를 활용하기로 결정했습니다. 그러나 댓글 목록을 불러오는 과정에서 문제가 발생 했습니다.
특정 꿀조합id를 기준으로 작성일 내림차순으로 데이터를 뽑을 수가 없었습니다. where 조건과 ordering 조건을 함께 사용할 수 없다는 것이었습니다. 그리하여 Realtime Database에서 FireStore로 데이터 베이스를 전환했습니다.
그러나 또 다른 문제가 있었습니다. FireStore에서 where조건과 ordering 조건을 함께 사용하려면 where 조건에서 사용한 속성과 ordering 절에서 사용한 속성이 일치해야한다는 점이었습니다. 검색결과 FireStore로 index를 사용해서 이러한 문제를 해결 할 수 있다는 것을 알 수 있었습니다.
하지만 또 다른 문제가 발생했습니다.

FireStore에서 index는 영문자와 _, 숫자로 제한한다는 것이었습니다. 한글 코딩 컨벤션을 사용하는 저희 프로젝트에서는 부득히하게 비즈니스 로직에 영문이 들어가야되는 걸림돌이 되었습니다.
또한 FireStore가 제공하는 where 절의 조건에도 한계가 있었습니다. array-contains를 활용해 선택한 꿀조합 조건 카테고리 별로 데이터를 and 조건으로 가져오려고 했으나 array-contains는 한가지 값만 배열에서 찾을 수 있었기 때문에 한 번의 요청으로 처리를 할 수 없다는 제약이 있었습니다. 이후 ===을 사용해보기도 했지만 동일 속성에 대한 연속적인 처리가 불가능하다는 제약도 있었습니다. 결국 모든 데이터를 받고 local에서 조건을 filtering하는 방법을 선택했습니다.
느린 CDN Storage의 네트워크 속도로 인한 이미지 로딩 문제
Firebase Storage 제품을 활용하여 이미지 저장소로 활용할 계획을 세웠습니다. 외부 이미지가 추가적으로 업로드 되지 않기 때문에 정적파일로 제공할 수 있었지만 사용자가 많은 정적파일을 받는 것보다는 CDN에서 이미지를 불러오는것이 합당하다고 느꼈다.
하지만 이는 잘 못된 판단이었다. Firebase Storage는 너무 느린 네트워크 performance를 보였고 lighthouse 점수도 낮을 뿐 아니라 사용자의 사용성 측면에서도 매끄럽지 못했다. 이 문제를 해결하기 위해 스켈레톤UI를 도입할지 고민했지만 이미지 이외의 모든 영역은 빠르게 동작하므로 Progressive image를 적용하기로 결정했다.
이후 생각해보면 이런 이미지 파일들을 sprite image로 제공하고 처리하고 이미지 사이즈를 줄이는 것이 가장 좋은 방법이 아니었을까라는 아쉬움이 남는다.
적합한 제품 도입을 위해서는 우리 프로젝트가 필요로하는 기능과 그에 따른 기술적 해결법과 제품의 지원 범위를 명확히 파악해야한다.
Tree Shaking
webpack-bundle-analyzer 플러그인을 사용해 최적화가 필요한 부분을 체크해보니 debouce만 사용하는 lodash의 크기가 매우 크다는 것을 확인할 수 있었습니다.
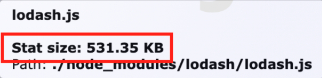
debouce만 사용하지만 531.35KB라는 리소스를 잡아먹고 있었습니다.
webpack이 점차 버전업 되면서 사용하지 않는 모듈의 export를 감지하는등 tree shaking에 대한 정보를 제공하고 있다는 사실을 알고 있었는데 lodash에서는 정상적으로 동작하지 않는다는 것을 발견할 수 있었습니다. (관련내용)
import { debounce } from 'lodash';위와 같이 distructring을 통해 export하고 있지만 동작하지 않는 이유는 lodash의 모듈 방식 때문이었습니다.
lodash는 UMD module이라는 방식을 사용하고 있는데 이 방식이 ESModule과 호환 되지 않는 문제가 있었습니다.
import debounce from 'lodash/debounce';그리하여 위와 같이 import 시에 모듈에서 메서드까지 한 번에 import하는 방법을 채택했습니다.
531.35KB에서 13.85KB까지 약 20배가량 가벼워진 것을 확인 할 수 있었습니다.
import { debounce } from 'lodash-es';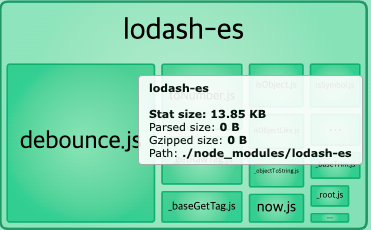
lodash_github에서 ESModule 사용시 lodash-es를 권장하기에 lodash-es를 사용한 방식을 최종적으로 결정 했습니다.
번들링 사이즈를 줄이는 방법에 대해 고민 할 수 있었다.
또한 Tree Shaking이라는 방법을 알 수 있었고 모듈 방식을 복습하고 라이브러리 별로 주의점이 따로 있다는 사실도 알 수 있었다.
Code splitting
react-router-dom@6.4에서 code splitting이 되지 않는 문제
page 내부에서 컴포넌트 단위로는 code splitting이 잘 되었지만, 페이지 단위로 dynamic import를 적용하기위해 router 단 lazy 기능이 동작하지 않았습니다. react-lazy가 문제인가 해서 loadable-component도 적용했지만 dynamic-import 기능은 여전히 지원되지 않았습니다.
이러한 문제 때문에 createBrowerRouter를 사용하는 방식에서 <Routes>를 사용하는 컴포넌트 방식으로 바꿨습니다. 기존에 사용하고 있던 6.4버전에서 제공하는 loader, errorboundary, ScrollRestoration 등을 사용할 수 없었고 이에 맞는 동일한 기능을 제공하기 위해 별도의 작업을 추가적으로 하게 되었습니다.
최신 버전은 레퍼런스가 많이 없을 뿐아니라 공식문서에서 제공하는 정보도 누락되어있을 수도 있다. 기업에서 안정화된 버전을 사용하는 이유를 알게 되었다.
그 밖에 고민한 것
- 웹접근성: 명도차이를 해결하기위해 BI색상을 바꿔야하는가?
- 모달: 기본 alert 창을 사용하는것이 나은가? 모든 알림 창을 모달을 활용해야 하는가?
- 좋아요 기능: 좋아요 수를 서버와 실시간으로 동기화해서 보여줄 것인가? 누를 때마다 서버에 요청할 것인가?
- 네트워크 성능 문제에 따른 이미지 로딩: 스켈레톤 UI를 도입할 것인가? 프로그래시브 이미지를 도입할 것인가?
- 의존성 배열: vscode에서 추천하는 의존성 배열을 모두 적용해야하는가? 주의 표시(노란줄)를 없애기 위해 코드를 수정해야하는가?
- Recoil: selector를 사용하지 않고 있지 않다. 개발 이후 기능이 명확해지고 보니 로그인 정보, 유저정보, 유저가 좋아요한 꿀조합 정보를 selector를 활용해 처리할 수 있다는 사실 발견
🧭 아쉬운 점과 앞으로 학습 계획
복잡한 컴포넌트를 만들 수 있는 개인 프로젝트
복잡한 컴포넌트와 페이지를 담당하지 않아 로직적으로 고민하면서 hook을 사용하고 전역 변수를 사용해야 할까하 고민하는 과정이 많지 않았다는 것이 아쉽습니다. 더 도전적인 컴포넌트를 만들면서 고민의 depth를 높일 수 있어야 함을 느꼈습니다. 이전에 진행 했던 HelloWorld 프로젝트를 Next로 마이그래이션하면서 개인 기향을 향상시켜야겠습니다.
다른 상태관리 라이브러리 익히기
- Redux
- React-Qeury
상태관리 툴의 기초인 redux를 더 탐구해보고 전역상태관리에대한 지식을 더 강화해야할 필요성을 느꼈습니다. 또한, 현 시점에서 비동기 작업 처리시 가장 유용하다고 평가받는 React-Query도 사용해보면서 다양한 tool에 대응할 수 있는 개발자로 성장하기 위해 노력이 필요하다고 느꼈습니다.
더 유연한 컴포넌트를 만들어 재사용성을 높여보기
지속가능한 코드, 추상화된 코드를 더 잘 만들어서 생산성을 높이는 것이 중요하다고 느낄 수 있었습니다.
재사용이 가능한 컴포넌트를 만들 수 있도록 고민하면서 개발을 해야겠다는 도전과제가 생겼습니다.
Type 활용을 더 잘하기 위해 Effective TypeScript 읽고 정리하기
TypeScript 에러 해결을 위해 쏟는 시간이 너무 많았습니다. 앞으로 더 많은 프로젝트애서 타입 설정과 관리를 효과적으로 할 수 있도록 best practice를 익히는 작업이 필요하다고 느꼈습니다.
