레일즈의 여러가지 캐싱 기법 중 low-level 캐싱을 적용하여 우리 서비스의 체인점 리스트 API의 성능을 개선한 경험기를 공유하고자 한다.
백그라운드
체인점 리스트 API는 유저가 주문 과정의 막바지에서 집근처 안경점을 선택하는 데 사용되므로 굉장히 중요한 API이다. 그럼에도 불구하고 성능이 엉망이었다. 성능 뿐만이 아니었다. 약 800개의 체인점 리스트 데이터를 한 번에 내려주다보니 메모리 역시 많이 차지하였고, 이로인해 skylight(레일즈 특화 APM) 대시보드에는 해당 API 옆에 항상 메모리 alert이 떠있었다.
성능과 메모리 개선을 위해 여러가지 작업을 했고, 어느정도 준수할 정도의 개선을 이뤄냈으나, 완벽하진 않았다. 이에 캐싱을 적용하여 추가적인 성능 개선을 할 필요를 느끼게 됐다.
캐싱을 적용하고자 한 이유는 해당 데이터가 아래와 같은 특징을 갖고 있어서였다.
- 데이터의 쓰기 작업보다는 읽기 작업이 현저히 많다. 가맹점 수가 폭발적으로 늘어나는 시기는 이미 지나가기도 했고, 이미 등록된 가맹점 정보가 업데이트 되거나, 가맹점이 추가되는 일, 삭제되는 일은 상대적으로 적다(물론 그렇다고 무지성으로 캐시를 적용할 순 없다. 이와 관련해서는 아래에서 다시 언급할 예정이다).
- 여러 유저가 조회해도 언제나 동일한 데이터를 반환한다. 즉 유저 별로 데이터가 달라지지 않는다.
- 자주 조회된다. 위에서도 말했지만, 집앞 안경원을 선택하는 일은 주문을 하기 위해 반드시 거쳐야 하는 작업이다. 매 주문 건수마다 매번 조회되었다는 뜻이다.
캐싱을 적용하는 데 있어 여러 고민사항들이 있었다. 캐시 데이터를 어디에 저장할지, 캐시키는 어떻게 처리해야 할 지 등이다. 주요 고민사항은 아래와 같았다.
- 캐시 스토어로 무엇을 사용할 것인가
- eviction policy는 무엇을 선택할 것인가
- 어떠한 형태로 저장할 것인가
- 캐시키는 어떻게 생성할 것인가
1. 캐시 스토어
레일즈에서는 file, memory, memcached, redis 이렇게 4개의 캐시 스토어를 지원한다. 각각에 대한 설명에 앞서 먼저 4개의 캐시 스토어를 크게 local과 global 캐시로 나눠 설명해 보고자 한다.
local cache vs global cache
file_store와 memory_store는 local 캐시로 분류할 수 있다. 물론 file_store의 경우 한 서버 내에 여러 프로세스가 공유할 수 있는 폴더를 둔다면 global하게 사용할 수 있을 것이나, 이는 결국 다중 서버 환경이 구축되게 되면 한계가 생기므로 local 캐시로 분류해도 무방할 것이라 생각한다.
로컬 캐싱은 말 그대로 각 서버마다 캐시를 따로 저장하는 전략이다. 서버 내부에 캐싱을 하므로 외부 저장소에 연결할 필요가 없어 네트워크 비용이 들지 않는다. 즉 global 캐시보다 상대적으로 빠르게 캐싱을 하고 읽어올 수 있다.
트래픽이 적은 단일 서버 환경에서는 유리할 수 있으나 규모가 커지고 서버가 늘어나게 되면 빠른 속도라는 장점을 상쇄할만한 단점들이 생기게 된다.
먼저 메모리 문제이다. 서버에 캐시 데이터를 저장한다는 말은 즉 서버 자원을 일정 부분 캐시를 위해 사용해야 한다는 뜻이다. 트래픽이 늘어날 수록 서버자원이 부족해질 수 있으며 잦은 GC 등으로 인해 오히려 속도가 떨어질 수도 있는 것이다. 물론 캐싱에 사용할 max memory를 지정하여 관리할 수는 있겠지만 여전히 같은 서버 자원을 공유해야 한다는 점은 달라지지 않는다.
더 큰 문제는 다중 서버 환경에서 발생한다. 각 서버의 파일이나 메모리를 사용하는 것이기 때문에 서버간 공유가 힘들다. 데이터 동기화를 위해 비용이 발생하는 것은 물론, 캐시 데이터 자체도 중복되어 각 서버에 저장되게 된다. 또한 동기화 중에 요청이 들어오는 경우에는 데이터 정합성 문제가 발생하기도 한다.
글로벌 캐싱은 별도의 캐시 서버를 두고 해당 저장소에 저장하는 전략이다. memcached_store, redis_store를 사용하기 위해선 해당 서비스가 돌아가고 있는 별도의 서버를 구축해야 한다.
위에서도 잠깐 언급했지만 외부 저장소를 사용하기 때문에 속도는 로컬 캐싱보다 느릴 수 밖에 없다. 하지만 별도의 서버이기 때문에 애플리케이션 서버의 상태에 영향을 받지 않는다. 즉 애플리케이션 서버가 죽더라도 캐시 서버는 안전하다. 또한 다중 서버 환경에서도 각 서버가 동기화나 데이터 정합성 걱정없이 동일한 캐시 데이터를 반환받을 수 있다.
각각의 캐시 스토어에 대한 설명으로 들어가보자.
ActiveSupport::Cache::Store
추상 클래스이다. 모든 캐시 스토어는 해당 클래스를 상속받아 각자의 특성에 맞게 기능을 구현되게 된다.
가장 기본적인 API 메서드는 read, write, delete, exist?, fetch 이다.
다시 말해 우리가 쓰고자 하는 캐시 스토어가 있다면, 추가적인 코드 수정없이 우리가 원하는 캐시 스토어로 갈아 끼우기만 하면 된다.
또한 해당 클래스를 상속받아 자신만의 커스텀 캐시스토어를 구축하는 것도 가능하다.
FileStore
레일즈의 디폴트 캐시 저장소이다. 장단점은 아래와 같다.
- 장점
- 한 서버 내 여러 프로세스에서 공유가 가능하다. 즉 글로벌 캐싱'처럼' 사용이 가능하다.
- 디스크 공간을 사용하기 때문에 RAM 보다 저렴하다.
- 캐시 데이터가 크다면 파일 스토어를 사용하는 것이 유리할 수 있다. - 단점
- 다중 서버 환경에서는 공유가 불가능하다. 한 서버 내에서야 여러 프로세스가 공유 가능하지만, 여러 서버로 서비스를 가동 중이라면 각 서버간에 캐시 데이터 공유가 불가능하다. 즉 글로벌 캐싱이 불가능하다.
- 느리다. 디스크에 액세스하는 속도는 RAM에 액세스 하는 속도보다 느릴 수 밖에 없다. 하지만 네트워크를 통해 액세스 하는 것 보다는 빠를 수도 있다.
- eviction 정책 사용이 불가능하다. 이것이 가장 큰 단점이다. 파일 스토어에서는 캐시에 기록된 시간을 기준으로 만료를 시킨다. 예를 들어 가장 처음 캐시된 데이터가 가장 많이 사용된다 하더라도, 파일스토어는 해당 캐시키부터 만료시키게 된다.
MemoryStore
메모리 스토어는 캐시된 값을 RAM에 big hash 형태로 저장한다. 장단점은 아래와 같다.
- 장점
- 빠르다. 모든 캐시스토어 중 가장 빠른 속도를 자랑한다.
- LRU 기반으로 캐시 eviction 된다. - 단점
- 캐시 데이터 공유가 안된다. 메모리에 직접 저장되므로 각 프로세스 간에도, 다중 서버 환경에서 각 서버 간에도 캐시 데이터 공유가 안된다.
- 애플리케이션 서비스가 사용하는 RAM을 같이 사용하므로 메모리 효율이 떨어진다.
Memcached
Memcached는 in-memory db이다. 즉 데이터를 디스크가 아닌 메모리에 저장한다. 또한 위 2개 store와 달리 별도의 서버로 구축하여 글로벌 캐싱이 가능하기에 데이터 정합성 측면에서 유리하다.
-
장점
- 검색속도가 빠르다. Memcached에서는 빠른 데이터 검색을 위해 해쉬 테이블을 사용한다. 각 버킷을 배열 형태로 두고 키의 해시값을 통해 빠른 접근이 가능하다.
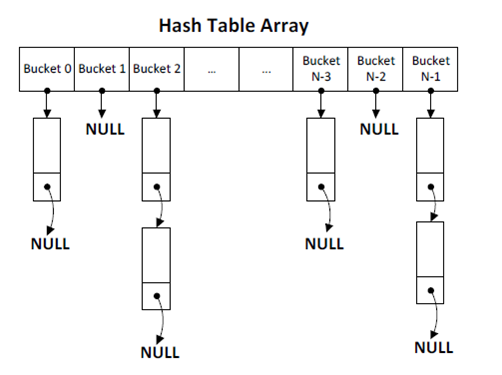
(출처: https://d2.naver.com/helloworld/151047)
- consistent hashing 알고리즘을 통해 여러 Memcached 서버에 데이터를 분산 저장할 수 있다.consistent hashing이란 서버의 개수가 변동이 될 때 해시키 재배치를 최대한 줄일 수 있는 알고리즘이다. hash ring을 만들어 해당 해시값보다 큰 값을 가진 서버에 데이터를 저장한다. 자세한 사항은 여기를 참고바란다.
- 트래픽이 많이 몰려도 redis에 비해 속도가 안정적이다. Memcached는 slab 메모리 할당자를 이용하여 내부적으로는 메모리 할당을 다시 하지 않고 관리한다. 슬랩 할당자는 메모리 풀 구조를 갖고 있어서 미리 고정된 크기의 메모리 블록들을 할당해둔다. 이렇게 미리 할당해 놓은 작은 메모리 조각(메모리 청크)을 요청한 양에 가장 가까운 메모리 조각을 반환해 주는 식으로 작동한다. 이러한 이유로 인해 시스템콜 통한 malloc/free가 일어나지 않아 이보다 빠른 할당이 가능하며 메모리 파편화가 덜 일어나게 된다.
- redis에 비해 메타 데이터를 적게 사용하여 메모리 사용량이 상대적으로 적다.
- LRU eviction 정책을 제공한다. 즉 가장 오래 쓰이지 않은 캐시키부터 삭제할 수 있다.
-
단점
- string을 제외한 다른 데이터 타입을 지원하지 않는다.
- 캐시 값이 1mb로 제한된다. 캐시 키는 250byte로 제한된다.
- redis에 비해 장애 발생 시의 대처 방법이 미흡하다. replication을 위해서는 3rd party 서비스를 이용해야 하여 해당 서비스에 의존적이게 된다. memcached는 메모리에만 데이터를 저장하므로 데이터 persistence 측면에서 불리하다. 물론 캐시용도로 사용하는 것이기에 큰 문제는 아닐 수도 있다.
- LRU eviction 정책을 지원하지만 이 외의 정책은 지원하지 않는다.
Redis
redis 역시 in-memory db이다. 마찬가지로 글로벌 캐싱을 위한 store이다.
장점은 아래와 같다.
- 다양한 collection을 제공한다. string 뿐만 아니라, list, set, sorted set, hash 등의 다양한 데이터 포맷을 지원한다. 개발환경이나 상황에 맞게 다양한 선택지를 가질 수 있다. 또한 memcached와는 달리 최대 512mb의 키와 밸류를 지원한다.
- 다양한 eviction 정책을 지원한다. LRU 뿐만 아니라 LFU 등의 다양한 eviction 정책을 지원한다. 이를 통해 시스템 성격에 따라 여러 eviction 정책을 고려해볼 수 있는 선택지가 생긴다.
- 장애 발생 시 대처가 용이하다. 즉 고가용성(HA)를 확보하기 용이하다.
- 디스크 persistence 지원. RDB snapshot, AOF 등의 방법으로 데이터를 디스크에 영구 저장할 수 있다. 장애 복구 시에 유리하다.
- replication을 지원한다. 마스터가 죽었을 시 슬레이브를 바로 마스터로 승격시켜 서비스 중단 없이 사용이 가능하게 된다. - 트랜잭션을 지원한다.
단점은 아래와 같다.
- 규모가 커질수록 메모리 관리에 많은 신경을 써야 한다.
- redis는 jemalloc을 이용하여 메모리 할당이 이루어진다. 대규모 트래픽이 발생하게 되면 malloc과 free를 통해 메모리 할당을 하므로 응답 속도에 영향을 미칠 수 있다.
- 또한 메모리가 부족할 경우 디스크에도 데이터를 저장을 하게 되고 스왑이 일어나게 된다. 스왑이 한번이라도 일어난 메모리 페이지는 그 메모리 페이지에 접근해야할 키가 있을 경우 매번 스왑이 일어나게 된다.
- jemalloc은 메모리 페이지 단위로 할당을 해야 해서 메모리 파편화 현상이 생길 수 있다. max memory를 설정하더라도 실제 더 많은 메모리를 잡고 있을 수도 있다는 것이다. - replication 과정에서 fork가 발생하므로 메모리를 최대 2배까지 더 사용하게 된다. copy-on-write 방식으로 실제 write가 발생했을 때 자식 프로세스에 메모리를 쓰게 되어있지만 캐시의 경우 write 작업도 빈번하기에 자식 프로세스가 최대 부모 프로세스의 메모리양과 동일하게 사용될 수도 있다.
cache store 선택
먼저 global 캐싱을 하기로 결정했다. 향후 다중 서버 환경으로 확장될 가능성이 크기에 local 캐싱으로는 한계가 있을 것이라 판단했다.
memcached와 redis 중에서는 redis를 선택하였다.
당장 우리 서비스 규모를 고려해봤을 때, 사실 memcached나 redis나 큰 이점을 갖는 서비스는 없다. 결국에는 나중을 생각했을 때의 개발의 생산성을 고려해야만 했다.
redis는 다양한 collection을 지원한다. 서비스가 확장해나감에 따라 캐싱도 적극적으로 사용될텐데, 이때 key-value string이라는 하나의 선택지로는 한계가 있을 것이다. 상황에 맞게 다양한 자료구조를 사용할 수 있는 redis가 더욱 매력적으로 느껴진 이유이다.
다양한 eviction 정책을 제공하는 점도 매력적이었다. LRU도 훌륭한 eviction 정책이지만, LFU가 더욱 효율적인 정책이라 생각한다.
최근에 사용되지 않은 키를 삭제하기 보단 가장 잘 쓰이지 않는 캐시키 삭제가 더 합리적이다. 현재로선 LFU 기반의 캐시 eviction 정책이 우리 서비스에 더 맞다고 생각하여 해당 정책을 지원하는 redis를 선택했다.
2. eviction policy
위에서도 말했지만 redis는 여러 eviction policy를 갖고 있다.
- noeviction
- maxmemory 제한에 도달하면 새로운 데이터를 저장하지 않고 에러를 발생시킴
- allkeys-lru
- 모든 키 중에서 가장 최근에 사용하지 않은 키를 제거
- allkeys-lfu
- 모든 키 중에서 사용 빈도 수가 가장 적은 키부터 삭제. 최근에 사용되지 않았더라도 사용 빈도 수가 많다면 삭제되지 않을 수 있고 최근에 사용되었더라도 사용 빈도 수가 낮다면 삭제될 수 있다.
- allkeys-random
- 모든 키 중에서 무작위로 키를 삭제
- volatile-lru
- expire set(만료기간 설정된 키) 내의 키 대상으로 lru 알고리즘 적용. 메모리에 데이터가 가득 차고 expire 설정이 안된 키만 남은 경우 새로운 데이터를 입력할 수 없기에 에러가 발생하거나 swap이 쓰이게 된다.
- volatile-lfu
- expire set 내의 키 대상으로 lfu 알고리즘 적용. 메모리에 데이터가 가득 차고 expire 설정이 안된 키만 남은 경우 새로운 데이터를 입력할 수 없기에 에러가 발생하거나 swap이 쓰이게 된다.
- volatile-random
- expire set 내의 키 대상으로 무작위로 키 삭제. 메모리에 데이터가 가득 차고 expire 설정이 안된 키만 남은 경우 새로운 데이터를 입력할 수 없기에 에러가 발생하거나 swap이 쓰이게 된다.
- volatile-ttl
- expire set 내의 키 대상으로 ttl이 짧은 순서로 키 삭제
redis의 lru 및 lfu eviction policy는 샘플링을 통해 알고리즘을 적용한다. maxmemory-samples 파라미터의 값을 조정하여 좀 더 정확한 lru 및 lfu 알고리즘 적용이 가능하나 메모리와 cpu가 더 많이 쓰이게 된다.
eviction policy 선택
일단 noeviction과 random은 제외했다. noeviction의 경우 maxmemory에 도달하면 에러를 발생시키는데 캐싱서버로 사용하고 있기에 maxmemory에 도달하는 상황을 에러라고 볼 수 없었기 때문이다. random 역시 무작위로 삭제할 경우 빈번히 쓰이는 캐시키가 삭제될 가능성이 있기에 제외했다.
volatile-* 역시 expire time을 설정한 키 대상으로만 삭제가 진행되므로 이 역시 제외했다.
allkeys-lru와 allkeys-lfu 중 allkeys-lfu를 선택했다. 캐싱을 하는 이유가 결국은 db i/o를 최소화 하고자 자주 쓰이는 데이터를 db 접근 없이 서브하기 위함인데 lru의 경우 빈도수가 기준이 아닌 최근 사용 여부가 기준이 되기에, 해당 키에 한 번만 접근했더라도 최근 사용되었다면 삭제 대상에서 제외되기 때문이다. lfu는 빈도수 기준으로 eviction을 진행하므로 캐싱에 좀 더 맞는 정책이라 판단했다.
3. 캐시로 저장할 데이터 포맷
먼저 아래와 같은 캐싱은 의미가 없다.
chains = Rails.cache.fetch("active_record_relation_caching", expires_in: 3.day) do
Chain.select(:id, :name, ...).where(status: 0, ...)
end캐시 블록 내 active record 쿼리는 ActiveRecord::Relation 객체를 캐싱한다. 이는 SQL 쿼리만 생성하고 실제 사용될 때 실행된다. 즉 레이지 로딩 기반이기에 위와 같이 캐싱을 한다면 의미가 없다.
위와 같은 방식을 제외하고 2가지 옵션이 있었다.
1. to_a 메서드로 배열로 변환한다. 이는 force execution, 즉 강제로 sql 쿼리를 실행시키는 방법이다. 해당 배열을 캐싱한다.
2. json 형태로 변환 후 저장한다.
배열 형태로 저장
아래와 같은 코드이다.
def chain_list
# 캐시키의 경우 편의상 "cache_array"로 했다. 캐시키를 이런 식으로 지정하면 안된다.
chains = Rails.cache.fetch("cache_array", expires_in: 3.day) do
Chain.select(:id, :name, ...).where(status: 0, ...).to_a
end
# json으로 변환 코드. 소정의 이유로 직접 json으로 변환한다.
result_in_json = convert_to_json(chains)
render json: result_in_json
endsql 쿼리를 to_a 메서드로 force execution한 후 해당 값을 캐싱했다. json으로 직접 빌드 후 렌더링 해주기에 convert_to_json 메서드를 사용해 json 변환을 해준 후 결과값을 내려준다.
json 형태로 저장
아래와 같은 코드이다.
def chain_list
# 캐시키의 경우 편의상 "json_caching_without_raw_data"로 했다. 캐시키를 이런 식으로 지정하면 안된다.
result_in_json = Rails.cache.fetch("json_caching_without_raw_data", expires_in: 3.day) do
chains = Chain.select(:id, :name, ...).where(status: 0, ...)
# json으로 변환 코드. 소정의 이유로 직접 json으로 변환한다.
convert_to_json(chains)
end
render json: result_in_json
endjson으로 변환하는 과정에서 ActiveRecord::Relation sql 쿼리가 실행되므로 to_a로 force execution해줄 필요가 없다.
json 변환 작업까지 한 후에 json 결과를 캐싱한다.
배열 형태 vs json 형태
먼저 레디스에 저장된 키-밸류 값의 메모리를 확인해 보았다. redis-cli 명령어 중 memory usage를 통해 확인했다. 결과는 byte 값으로 나온다.
배열 형태

json 형태

보다시피 배열보다 json 형태로 저장할 때 좀 더 적은 메모리를 사용하게 된다. 적은 차이일 수도 있지만, 위에서도 말했듯이 redis는 in-memory db이기 때문에 디스크가 아닌 RAM의 메모리를 사용한다. 그렇기 때문에 최대한 메모리를 최적화 하는 것이 중요할 것이라 판단했다.
아래는 캐시된 후 해당 api의 rails log이다.
배열 형태

json 형태

json 변환 작업 후 해당 값을 캐싱했기에 객체 할당이 현저히 적은 것을 알 수 있다.
현재 체인점 리스트 API는 단순히 리스트를 내려주는 역할만 하면 된다. 추가적인 데이터 가공이나 수정이 들어갈 필요가 없고 앞으로도 그럴 가능성이 희박하다. 즉 json 변환 작업까지 한 후에 캐싱을 해도 무방하며, 메모리 부분에서 더욱 효율적인 모습을 보여주고 있는 것이다.
이러한 이유로 json 형태로 캐싱을 하기로 결정했다.
Marshal
최종 결정 전 마지막으로 체크해 볼 것이 남았다. 바로 마샬링이다.
먼저 아래 코드를 봐보자.
User.create(name: 'ruby')
usr = User.last
Rails.cache.write('usr_cache_key', usr)
cache_result = Rails.cache.read('usr_cache_key')
cache_result.class # -> User
cache_result.name # -> ruby보다시피 캐싱 값을 읽어오면 캐싱하기 전과 똑같이 사용할 수 있다.
usr 데이터를 캐싱하고 갖고 올 때, 레일즈는 User 클래스 그대로 캐시 저장소에 저장하는 것일까? 당연히 아니다. Marshal 모듈을 사용해 시리얼라이징 하여 저장하게 된다.
# rails/activesupport/lib/active_support/cache.rb
def serialize_entry(entry, **options)
options = merged_options(options)
if @coder_supports_compression && options[:compress]
@coder.dump_compressed(entry, options[:compress_threshold] || DEFAULT_COMPRESS_LIMIT)
else
@coder.dump(entry)
end
end여기서의 @coder는 Marshal 모듈이다(MessagePack 포맷도 사용 가능해 보인다. 아직 코드 분석이 미흡해 어떤 식으로 적용하는지까지는 모르겠다. 더 공부해야겠다..).
캐시할 데이터를 저장할 때 Marshal.dump 메서드를 통해 시리얼라이징 하여 저장하는 것이다. 읽어올 때 역시 Marshal.load 메서드로 읽어온다.
레디스에 저장된 형태를 살펴 보자.
127.0.0.1:6379[3]> get "json_caching_without_raw_data"
"\x04\bo: ActiveSupport::Cache::Entry\n:\x0b@value\"\x02\xeb\xaax\x9c..."실제 저장된 값은 ActiveSupport::Cache::Entry이다. Entry 클래스는 압축 여부나 만료 기한 등과 관련된 기능을 구현한 Wrapper 클래스로써 캐시에 저장될 모든 데이터는 해당 Entry 클래스로 감싸지게 된다. 이를 통해 뒷 단의 메모리 스토어가 무엇이 되든 같은 인터페이스를 제공하게 된다. 추상화 및 캡슐화인 것이다.
내가 고민했던 부분은 굳이 이러한 마샬링이 필요한가 였다. 계속해서 말해왔지만, 체인점 리스트는 db에서 불러온 후 어떠한 가공 혹은 수정이 일어나지 않은 채 데이터 그대로 내려지게 된다. 어차피 json 형태로 캐시 스토어에 저장을 하고, 그대로 갖고 와서 내려주면 될텐데, 굳이 마샬링을 거칠 필요가 있을지 의문이 들었다.
아래와 같이 raw 옵션을 줘서 캐싱을 하여 데이터를 확인해 보았다.
Rails.cache.fetch("json_caching_with_raw_data", expires_in: 3.day, raw: true)

보다시피 레디스 메모리 사용량이 약 4배나 늘어난다. 반면 메모리 할당이나 응답속도는 json 포맷을 마샬링해서 저장한 것과 별반 차이가 없다.
아래와 같이 compress 옵션을 주게 돼도 레디스 메모리 사용량 결과값이 같다. 즉 제대로 처리가 안되는 것으로 보인다.
Rails.cache.fetch("json_caching_with_raw_data", expires_in: 3.day, raw: true, compress: true)마샬링을 하는 부분 보다는 마샬링을 할 때 압축이 들어가는 부분이 레디스 메모리 사용량의 큰 차이를 만들어 내는 것으로 보인다.
위 serialize_entry() 메서드의 @coder.dump_compressed(entry, options[:compress_threshold] || DEFAULT_COMPRESS_LIMIT) 이 부분에서 데이터 크기가 threshold 1kb를 넘어설 경우 압축을 하는 것으로 보인다.
여전히 마샬링이 필요한 것은 아니지만 레디스 캐시 스토어에 저장할 때 compress를 하여 저장하므로, 굳이 raw 옵션을 줘서 마샬링을 끌 필요는 없다고 판단했다.
4. 캐시키
데이터 정합성 측면에서 캐시키 설정은 굉장히 중요하다. 캐시된 데이터의 값이 변경되었을 때, 캐시된 값이 아닌 새로 업데이트 된 값이 유저에게 내려져야 할텐데, 캐시키가 제대로 설정되어 있지 않다면 stale한, 혹은 오래된, 유효하지 않은 데이터가 유저에게 내려질 가능성이 있다.
다행히 레일즈에는 캐시키를 생성해주는 메서드를 제공해준다. 코드를 살펴보자.
def chain_list
chains = Chain.select(:id, :name, ...).where(status: 0, ...)
result_in_json = Rails.cache.fetch(chains.cache_key_with_version, expires_in: 3.day) do
# json으로 변환 코드. 소정의 이유로 직접 json으로 변환한다.
convert_to_json(chains)
end
render json: result_in_json
end캐시키 부분에 chains.cache_key_with_version와 같이 캐시키를 생성해주는 메서드를 사용했다. ActivRecord::Realtion 클래스에서 제공하는 캐시키 생성 메서드이다. 당연히 ActiveRecord 클래스에서도 해당 메서드를 제공한다.
위 메서드를 호출할 경우 아래와 같이 sql 쿼리가 나가게 된다.
(1.6ms) SELECT COUNT(*) AS "size", MAX("chains"."updated_at") AS timestamp FROM "chains" WHERE ...생성된 캐시키는 "chains/query-baafe13ef0035eaf778d9d1ec507e8a4-10-20221214071839726430" 이다.
chains 부분은 어떤 종류의 레코드인지 나타낸다. 위 캐시키는 Chain 클래스의 레코드들을 갖고 있다는 것을 의미한다.
query- 부분은 하드코드된 값이다. 모든 캐시키에 동일하게 적용된다.
baafe13ef0035eaf778d9d1ec507e8a4 부분은 ActivRecord::Realtion 쿼리문이 digest된 값이다.
10 부분은 콜렉션의 사이즈이다.
20221214071839726430는 레코드에서 가장 최근에 없데이트 된 레코드의 타임스탬프이다.
위와 같은 조합을 통해, 우리의 체인점 리스트에서 데이터 변경이 일어나거나, 삭제 혹은 추가가 일어나게 되면 해당 캐시키 값이 변경되어 stale한 캐시값이 아닌 최신의 데이터를 서브할 수 있게 된다.
마무리
API에 캐시를 적용하기 위해 위와 같이 많은 고민을 했다. 이러한 고민들 덕분에 해당 API의 성능을 avg response time 기준으로 무려 95%의 성능 향상을 이뤄낼 수 있었다(물론 기존의 API 성능이 엉망이었기에 이런 드라마틱한 수치가 나온 것도 있다).
단순히 캐시 적용법을 익혀 적용하기보다는 위와 같이 여러 고민과 조사를 통해 각자의 상황에 맞게 캐시를 적용하길 바란다.
참고자료
https://guides.rubyonrails.org/caching_with_rails.html#activesupport-cache-rediscachestore
https://pawelurbanek.com/rails-active-record-caching
https://www.bigbinary.com/blog/activerecord-relation-cache-key
https://www.honeybadger.io/blog/rails-low-level-caching/
https://chagokx2.tistory.com/102
https://s-core.co.kr/insight/view/redis-%EB%82%B4%EB%B6%80-%EB%8F%99%EC%9E%91-%EC%9B%90%EB%A6%AC%EC%99%80-%EC%B5%9C%EC%A0%81%ED%99%94-%EB%B0%A9%EC%95%88/
https://pawelurbanek.com/rails-active-record-caching
https://peaonunes.com/blog/how-to-store-raw-values-with-rails-cache-1c59/
https://shopify.engineering/caching-without-marshal-part-one
