웹앱서버란
puma는 web application server이다. 앱서버는 소켓에서 연결을 수락한 다음, http request를 우리 레일즈 서버로 서브하는 역할을 한다.
이러한 과정에서 (루비 진영의)웹앱서버는 유저경험에 악영향을 끼칠 수 있는 아래 3가지 문제를 최대한 효율적으로 대응하는 방향으로 발전해 왔다.
-
Slow Clients
말 그대로 느린 클라이언트 요청이다. 3g 폰을 가진 유저가 산 꼭대기에서 이미지 업로드를 한다고 생각해보면 된다. 이러한 유저 요청이 바로 slow client 요청이다. puma와 Passenger와 같은 웹앱서버는 리퀘스트 버퍼링 방식으로 이를 해결한다. puma에서는 reactor 스레드가 이러한 역할을 수행한다. request의 모든 패킷이 수신되었는지 확인하고, 수신 완료되었을 때, 즉 버퍼링이 끝났을 때 reactor가 스레드풀의 스레드로 request를 넘겨 요청을 처리하도록 한다. 이러한 처리 방식은 Ddos 공격을 예방하는데에 도움이 된다.
반면 unicorn은 이러한 slow clients를 대처 못하므로 반드시 nginx와 같은 리버스 프록시와 함께 사용해야 한다. -
Slow Apps
루비는 스레드 기반이 아니다. 정확히는 스레드를 통해 병렬처리가 가능하나 MRI 기반의 루비는 GVL로 인해 한 번에 하나의 스레드만 애플리케이션 코드를 실행할 수 있다. 이러한 이유로 여러 요청을 동시에 처리하기 위해 웹앱서버에서는 클러스터링을 지원해야 한다. 즉 여러 프로세스를 spawn할 수 있어야 하며 puma, passenger, unicorn 모두 이러한 기능을 지원한다. -
Slow I/O
예를 들어 10만개의 DB 행을 불러오는 쿼리가 있다면, 해당 I/O 결과 값을 반환받기까지 그냥 대기하는 것은 비효율적이다. 클러스터링, 즉 멀티프로세싱은 이러한 slow i/o 대응에 도움은 되지만, 효율적인 방법은 아니다. 왜냐하면 멀티프로세싱은 무한정 수를 늘릴 수도 없고(컨텍스트 스위칭 비용 발생), 메모리 역시 한정적이기 때문이다.
이러한 slow i/o는 멀티스레딩으로 대응해야 한다. puma에서는 스레드가 I/O 대기에 들어가면 GVL을 자동으로 반환한다. 즉 다른 스레드가 요청을 받아 애플리케이션 코드를 실행할 수 있다는 것이다. 이럼으로써 RAM limit 안에서 최대한 CPU를 바쁘게 돌릴 수 있게 된다.
how puma works
puma는 레일즈 진영에서 가장 많이 쓰이는 웹앱서버 중 하나이다. 위에서 말했듯이 puma는 소켓을 listen하여 request를 받아 우리의 레일즈 앱으로 보내고, 응답을 클라이언트에 반환하는 역할을 한다. 이러한 과정 속에서 puma가 내부적으로 어떻게 해당 작업을 처리하는 알아보자.
puma의 구조
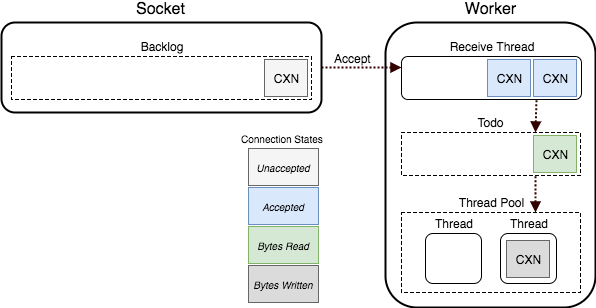
puma는 Socket Backlog queue라는 OS 레벨 queue에서 connection을 listen 한다. connection을 accept 하고 해당 소켓에서 HTTP request를 꺼내 우리의 레일즈 앱으로 보낸다. puma는 바로 스레드 워커로 해당 request를 던질까? 당연히 아니다. 위에서도 말했지만, 먼저 request를 버퍼링한다.
request가 완전히 버퍼링되면, 이를 Todo queue로 push 한다. puma의 ThreadPool은 이 queue를 consume한다. 해당 queue에서 request를 꺼내 우리의 레일즈 앱을 실행시키는 것이다.
(출처: https://github.com/puma/puma/blob/master/docs/architecture.md)
좀 더 자세히 들여다보자.
puma internals
위에서 말한 '우리의 레일즈 앱을 실행시킨다'는 말그대로 우리의 레일즈 앱을 call 하는 것이다. 아래와 같이 말이다.
@app.call(env)위의 코드를 보면, 바로 깨달아야 하는 점이 있다. 바로 Rack app을 호출하고 있구나, 혹은 Rack app 호환 웹서버이구나, 라는 것이다.
Rack에 대해 모른다면 먼저 아래 링크의 글을 읽고 오길 바란다.
Rack 프로토콜을 준수하기 위한 조건 중 하나는 바로 env hash를 인자로 넘겨야 하는 것이다.
눈치챘겠지만, 이 작업 역시 puma가 해야할 일 중 하나이다. 즉 http request를 Rack app을 위한 env hash로 변환하는 작업을 수행해야 한다.
socket에서 http request를 버퍼링 및 읽고 이를 rack env로 변환 후 우리의 rack app으로 넘기는 것이다.
Socket -> HTTP -> Rack env -> Rack app이러한 작업은 Reactor가 담당한다. Reactor는 위 이지미에서의 Receive Thread를 만들어 request를 버퍼링하고, 버퍼링이 완료되면 해당 request를 rack env로 변환한 후, Todo queue로 push하는 역할을 한다.
puma의 ThreadPool에서 Todo queue를 consume하고 있다. 이용 가능한 thread가 해당 request를 pick하여 @app.call(env)를 호출한다. 이를 통해 우리의 레일즈 코드를 실행시키고 HTTP response를 만들도록 한다. 해당 response를 반환 받아 이를 클라이언트에 넘기고 나면, 해당 thread는 다시 사용가능 상태로 돌아온다.
single 모드 vs cluster 모드
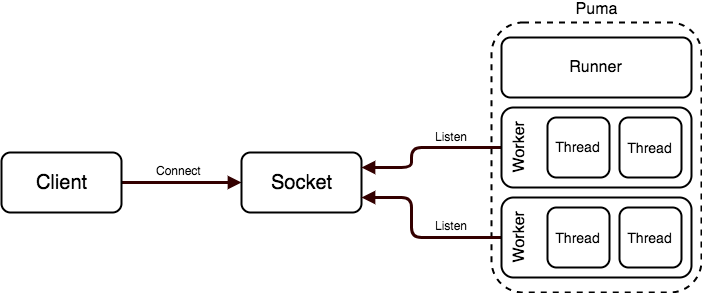
puma는 2가지 모드가 있다. single 모드와 cluster 모드이다. single 모드는 이름 그대로 하나의 프로세스가 소켓을 리슨하고, 위에서 말한 작업들을 처리하게 된다.
cluster 모드에서 puma는 여러 프로세스를 통해 request를 처리한다. 먼저 parent 프로세스를 boot시키고 설정파일에서 지정한 숫자대로 child 프로세스를 forking 한다.
다시 말하지만 이러한 cluster 모드를 지원하는 이유는, 병렬처리의 효율 및 성능을 극대화 시키기 위함이다.
parent 혹은 마스터 프로세스는 socket을 수신하거나 request를 직접 처리하지 않는다. 마스터 프로세스는 UNIX signal을 수신하고 자식 프로세스를 boot하거나 kill 하는 역할을 한다. 즉 workers(자식 프로세스)를 관리하는 역할을 한다. 아래 그림에서 Runner라 적혀있는 프로세스가 바로 마스터 프로세스이다.
(출처: https://github.com/puma/puma/blob/master/docs/architecture.md)
puma를 cluster 모드로 변경하기 위해선 아래와 같이 설정해주면 된다.
# config/puma.rb
max_threads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }
min_threads_count = ENV.fetch("RAILS_MIN_THREADS") { max_threads_count }
threads min_threads_count, max_threads_count
# 중략
# Specifies the number of `workers` to boot in clustered mode.
# Workers are forked web server processes. If using threads and workers together
# the concurrency of the application would be max `threads` * `workers`.
workers ENV.fetch("WEB_CONCURRENCY") { 2 }
# Use the `preload_app!` method when specifying a `workers` number.
# This directive tells Puma to first boot the application and load code
# before forking the application. This takes advantage of Copy On Write
# process behavior so workers use less memory.
#
preload_app!WEB_CONCURRENCY의 주석을 풀고 원하는 워커 숫자를 적어준다면, 주석에도 적혀있는 것처럼, puma는 cluster 모드로 돌아가게 된다. 위에서는 WEB_CONCURRENCY가 2로 설정되어 있으므로 마스터 프로세스가 boot되고 workers를 2개 띄우게 된다.
preload_app! 메서드는 위 주석에 적혀있는 것 처럼, 자식 프로세스(workers)를 fork하기 전에 코드를 미리 로드하게 하는 메서드이다. 이러한 방식으로 인해 puma는 CoW, Copy-on-Write 방식으로 자식 프로세스를 forking할 수 있게 된다. CoW는 메모리 최적화 기법 중 하나로 자식 프로세스에서 실제로 메모리를 쓰기 전까지 메모리 할당을 최대한 딜레이 시키는 것이다. 즉 자식 프로세스가 새 메모리 영역을 쓰기 전까지는 부모 프로세스와 자식 프로세스가 메모리 영역을 공유하게 된다.
worker와 thread의 적정 수
WEB_CONCURRENCY를 무작정 늘려서 많은 workers를 돌리는 건 오히려 성능에 좋지 않을 수 있다. 당연한 말이지만 멀티 프로세싱은 컨텍스트 스위칭 비용이 많이 들기 때문이다.
puma 문서에 따르면 CPU Core의 1.5배로 worker 수를 조정하라 나와 있다.
하지만 이는 애플리케이션 코드의 상황이나 서버 사양에 따라 충분히 달라질 수 있다. 그러니 직접 worker와 thread 수를 조정해가며 자신의 앱에 가장 최적화된 숫자를 직접 탐색해 보는 것이 중요하다.
퓨마 설정 파일 튜닝한 과정을 여기에 공유하였다. 참고하길 바란다.
참고자료
https://github.com/puma/puma/blob/master/docs/architecture.md
https://www.youtube.com/watch?v=SquGNt4FhY0
https://medium.com/@CGA1123/reducing-rails-memory-usage-by-15-56090b6294bd
https://scoutapm.com/blog/which-ruby-app-server-is-right-for-you
