웹 크롤링
1. 웹 크롤러란?
-
구글은 '구글봇'이라고 하는 일련의 컴퓨터 프로그램이 있다. 구글봇은 매일 끊임없이 웹상에 존재하는 수심만 개의 페이지를 방문한다. 이 과정을 크롤링(crawling)이라고 하는데 모두 정교한 알고리즘으로 짜여있다. 다시 말해 어떤 사이트를 크롤할 지, 얼마나 자주 할지 또 각 사이트에서 얼마나 많은 페이지를 방문할 것인가에 대한 프로그램이 짜여 있다.
-
크롤러, 프론티어, 스파이더라는 여러 가지 이름을 갖고 있다.
다만, scraper라는 용어는 크롤러와 달리 특정 목적을 위해 몇몇 사이트를 수집하는 개념으로 언급 된다.
2. 크롤러의 과제
2-1) 넓은 www의 세계
- 웹은 끊임없이 팽창하고 컨텐츠의 개수는 날로 늘어간다.
- 웹은 끊임없이 변하고 수많은 페이지가 수정된다.
2-2) 페이지 퀄리티
- 모든 페이지가 좋은 정보를 담고 있지 않다.
광고 + 스팸 포스팅 + 적은 정보의 글 + 어뷰징 - 검색 서비스는 좋은 키워드나 이미지를 가진 포스트에 높은 점수를 준다.
- 검색 엔진의 랭킹 알고리즘에 알맞게 노출 되기 위한 최적화를 검색 엔진 최적화(SEO)라고 한다.
이에 따라 검색 서비스마다 어떻게 하면 SEO를 잘 할 수 있는지 가이드라인을 제시하고 있다.
Google 검색 센터 - 검색 엔진 최적화 우수+성공사례
2-3) robots.txt
- robots.txt는 서비스를 개발 할 때 어떤 정보를 중심으로 노출하고 크롤링 되지 않게 할 것인가에 대해 결정할 수 있는 중요한 개념이다.
3. 크롤러 아키텍처
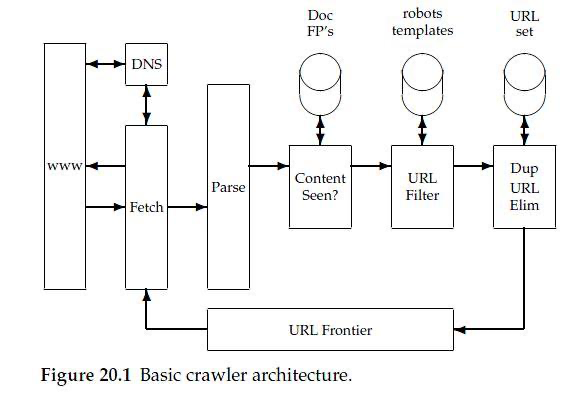
3-1) Fetch
- fetch는 다음에 방문할 url을 가져와서 페이지를 방문한다.
http 요청을 보내 response body를 가져오는 과정이라 할 수 있다.
3-2) Parse
- 가져온 페이지 내의 다른 하이퍼링크를 추출하는 과정이라고 해서 url extraction이라고도 말한다.
- DOM 데이터를 해석하는 입장에서는 태그의 오타와 닫힘만 없어도 에러가 발생한다.
3-3) Dup URL Elim
- 이미 방문했던 url을 다시 방문하지 않도록 중복 url을 제거하는 단계다.
3-4) Freshness, revisiting
- schedulaer라고 부르는 이 과정은 크롤러가 페이지를 언제 다시 방문할 지에 대해 관한 것이다.
(상품의 이미지와 가격 업데이트가 이루어질 경우 필요)
- uniform : 유니폼 스케줄링은 페이지의 성격이나 업데이트 주기에 관계 없이 일정 간격으로 페이지를 재방문하는 전략이다.
- lambda crawl : 자주 변화하는 페이지의 방문 간격을 점점 줄여나가지만 너무 많이 변화하면 오히려 점수를 깎아버리는 크롤 방식
3-5) Content Seen
- 중복 문서를 피하기 위한 과정으로 크롤링 결과가 똑같은 내용의 문서가 나타나는 것을 막고자 하는 것이다.
4. Paralle Crawler
- 웹을 탐색하는데 있어서 여러 대의 크롤러는 필수이다.
4-1) Firewall mode
- 가장 단순한 모델로 각각의 크롤러가 inter-link를 신경쓰지 않는 방식이다.
- 각 크롤러가 담당한 사이트를 벗어나는 링크는 무시하고 내부의 컨텐츠만 탐색하는 방식이다.
- 하지만 링크를 통해서만 갈 수 있는 페이지가 있다면 크롤링 하는 과정에서 유실되는 페이지가 생기게 된다는 단점이 있다.
4-2) Exchange mode
- exchange mode는 url을 크롤러끼리 교환하는 방법으로 서로에게 필요한 정보의 링크를 던져준다.
- firewall mode의 단점을 보완할 수 있지만 계속 정보를 주고 받아야 하므로 과도한 네트워크의 트래픽이 발생한다.
이를 보완하기 위해 Batch communication이라는 방법을 사용하는데 url set을 한 번에 주고 받는 방법이다. 배치 단위로 url을 교환하기 때문에 네트워크 트래픽이 줄어드는 이점이 있다.
5. 스크래핑
- 검색 엔진 서비스를 하려는 것이 아니고 단순 날씨 정보, 체크 알림 같은 정보를 가져올 경우 웹 스크래퍼를 만들면 된다.
!! 이것을 크롤러와 혼동하여 통합된 단어로 '크롤러'라고 부르면 안된다.
5-1) 스크래핑의 문제점
- 토스나 뱅크 샐러드가 각 은행, 카드사를 스크래핑하여 유저 대신 로그인과 송금 등을 대행하는 경우가 있다. 기업과 기업간의 정보 스크래핑 전쟁이 이루어지고 있는 것이다.
- 구글도 개인 정보의 수집으로 문제 지적을 당하고 있는데 DuckDuckGo라는 검색 서비스는 개인정보를 수집하지 않는 서비스로 오직 검색에만 집중하기 위한 서비스이다.

Hello World!