컬렉션 프레임워크
Set : 집합
- 데이터의 순서를 보장하지 않는다.
- 데이터의 중복을 허용하지 않는다.구현 클래스
HashSet
Set인터페이스를 구현한 가장 대표적인 클래스
중복되는 값을 저장하면 무시한다. 인덱스가 존재하지 않아 순서를 보장하지 않으며
ArrayList나 배열처럼 값을 가져오는게 불가능하다.
hashcode()가 반환하는 해시코드를 이용하여 데이터를 처리하며 상대적으로 빠르다.
위의 특징 때문에 값의 존재 여부를 파악할 때 사용하기 좋다.(검색)순서 부여: iterator()
순서가 없는 객체에 순서를 부여하거나, 순서가 있어도 iterator 방식의 순서로
변경하고자 할 때 사용한다.
hasNext()를 통해 다음 값이 있는 지 검사하고, next()를 사용하여 값을 가져온다.Set은 검사의 목적이 있기 때문에 순서 정보를 관리할 필요가 없어서 데이터 크기에 상관없이 검색에 걸리는 시간이 매우 짧다.
반면 ArrayList는 index를 관리해야하기 때문에 상대적으로 시간이 오래 걸린다.그러므로 기능적 차이가 없다면 Set을 사용한다.
HashSetTest.java
package hashSetTest;
import java.util.HashSet;
import java.util.Iterator;
public class HashSetTest {
public static void main(String[] args) {
HashSet<String> animalSet = new HashSet<>();
animalSet.add("강아지");
animalSet.add("고양이");
animalSet.add("토끼");
animalSet.add("까치");
animalSet.add("독수리");
animalSet.add("송아지");
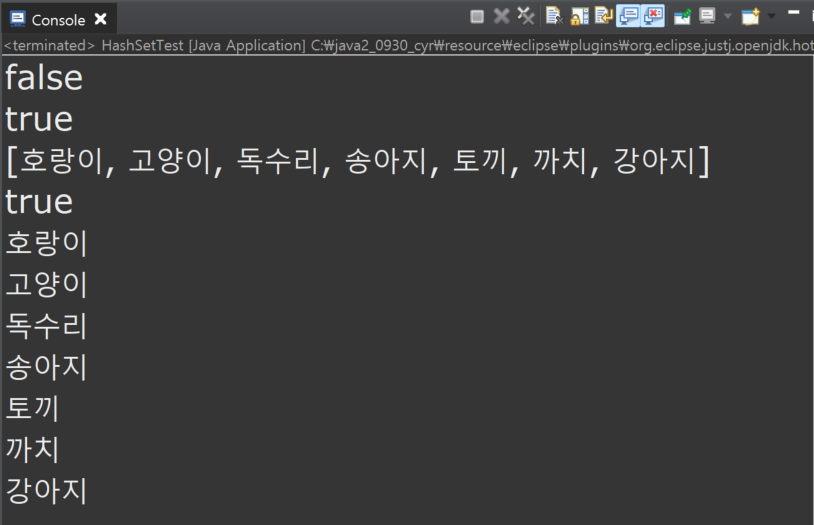
System.out.println(animalSet.add("강아지"));
System.out.println(animalSet.add("호랑이"));
System.out.println(animalSet.toString()); // iterator로 타입을 바꿔서 가져오는 것
// 내가 저장한 순서대로 값이 저장되어 있는가?
// 내가 set에서 특정 값을 가져올 수 있는가?
// HashSet은 값을 가져올 수가 없다. 그런데 어떻게 toString()으로 값을 가져오는가?
// 다른 자료구조로 변환하여 값을 가져와야한다.
Iterator<String>animalIter = animalSet.iterator();
// System.out.println(animalIter);
// System.out.println(animalIter.hasNext());
System.out.println(animalIter.next());
System.out.println(animalIter.next());
while(animalIter.hasNext()) {
System.out.println(animalIter.next()); // 위에서 이미 두개를 꺼내놨기 때문에 나머지 친구들이 출력이 된다.
}
}
}
Map
데이터의 순서를 보장하지 않는다.
데이터를 Key와 Value 한 쌍으로 저장하여 Key로 데이터에 접근할 수 있다.
그러므로 Key는 ArrayList의 index와 비슷한 역할을 하며 중복을 허용하지 않는다.
index에 중복이 없는 것과 동일하다고 생각하면 된다.구현 클래스
HashMap
hashCode()가 반환하는 해시코드를 이용하며 검색 속도가 상대적으로 빠르다.
이미 저장된 Key를 가진 한 쌍의 데이터를 넣으면 가장 마지막에 넣은 Value로 수정된다.
(Value는 수정이 가능하다.)
저장되지 않은 Key를 가진 한 쌍의 데이터를 넣으면 새롭게 추가된다.HashMapTask.java
package hashMapTest;
import java.util.HashMap;
import java.util.Scanner;
public class HashMapTask {
public static void main(String[] args) {
/*
* 카페 메뉴 아메리카노 2500 라떼 3500 모카 4500 바닐라 라떼 4500
*
* HashMap 에 저장하기
*
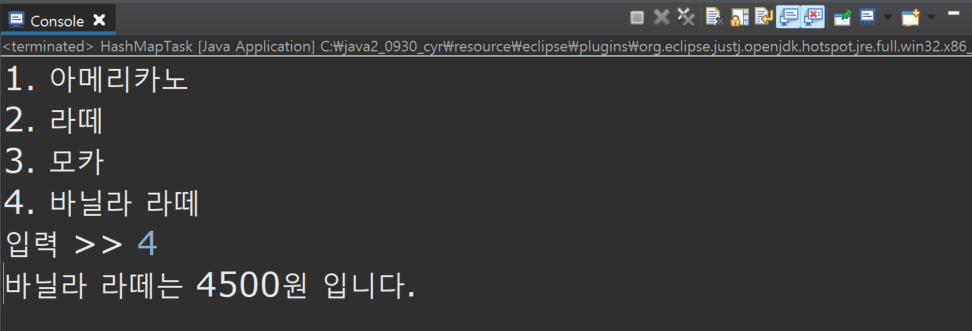
* 출력과 입력) 1. 아메리카노 2. 라떼 3. 모카 4. 바닐라 라떼 입력 >> 2
*
* 출력) 라떼는 3500원 입니다.
*/
HashMap<String, Integer> menu = new HashMap<String, Integer>();
Scanner sc = new Scanner(System.in);
int choice = 0;
String msg = "1. 아메리카노\n2. 라떼\n3. 모카\n4. 바닐라 라떼\n입력 >> ", result = null;
menu.put("아메리카노", 2500);
menu.put("라떼", 3500);
menu.put("모카", 4500);
menu.put("바닐라 라떼", 4500);
System.out.print(msg);
choice = sc.nextInt();
switch (choice) {
case 1:
result = "아메리카노는 " + menu.get("아메리카노") + "원 입니다.";
break;
case 2:
result = "라떼는 " + menu.get("라떼") + "원 입니다.";
break;
case 3:
result = "모카는 " + menu.get("모카") + "원 입니다.";
break;
case 4:
result = "바닐라 라떼는 " + menu.get("바닐라 라떼") + "원 입니다.";
break;
default:
result = "커피 먹기 싫나보네요?";
break;
}
System.out.println(result);
}
}
JSON
데이터를 표현하는 방법이다. (단순 텍스트)
데이터를 저장, 전송할 때 많이 사용되는 형식(format)이다.
기존에 XML, csv를 많이 사용했지만 이제는 이해하기도 쉽고 용량도 작은 JSON형식을 많이 사용한다.
어떤 언어를 사용하더라도 JSON형식으로 데이터를 전송할 수 있다.
Map과 유사하다.
프로그램(일반적으로 '소프트웨어' 라고도 부른다.)
- 특정 작업을 수행하는 명령어(소스코드)들의 모음
- 메모리를 할당받지 않은 상태 -> 꺼져있다.프로세스
- 실행 중인 프로그램
- 프로세스는 프로그램을 실행시키기 위한 메모리 등의 자원과 쓰레드로 구성된다.
- 즉, 하나의 프로세스는 하나 이상의 쓰레드를 가지고 있다. 쓰레드
하나의 프로세스 내에서 작업을 처리하는 흐름의 단위
(쉽게 말하면) 작업을 처리하는 것싱글 쓰레드
하나의 쓰레드가 작업을 마치면 프로그램이 종료된다.
쓰레드를 하나만 가지고 있기 때문에 작업을 순차적으로 처리하므로 상대적으로 비효율적이다.
쓰레드는 자원을 사용하는데 싱글 쓰레드는 혼자서 자원을 사용하므로 동기화를 걱정할 필요없다.
따라서 안정성이 높고 설계가 쉽다.멀티 쓰레드
메인 쓰레드가 작업을 마치더라도 다른 쓰레드의 작업이 모두 끝나야 프로그램이 종료된다.
하나의 프로세스에서 여러 작업을 동시에 처리하는 것처럼 느껴지지만 사실은 각각의 쓰레드를
매우 빠른 속도로 번갈아가며 실행시켜서 조금씩 처리한다.
쓰레드간 공유하는 자원이 있다면 충돌이 생겨 문제가 발생할 수 있으며 이런 문제를
동기화(Synchronized)를 통해 해결한다.
안정성이 떨어지고 설계가 굉장히 어렵다.멀티 쓰레드 구현 방법
1. Thread 클래스 상속
2. Runnable 인터페이스 지정받아 구현
- run 메소드에 쓰레드가 처리할 작업을 재정의한다.
- start() 메소드로 쓰레드를 실행시킨다.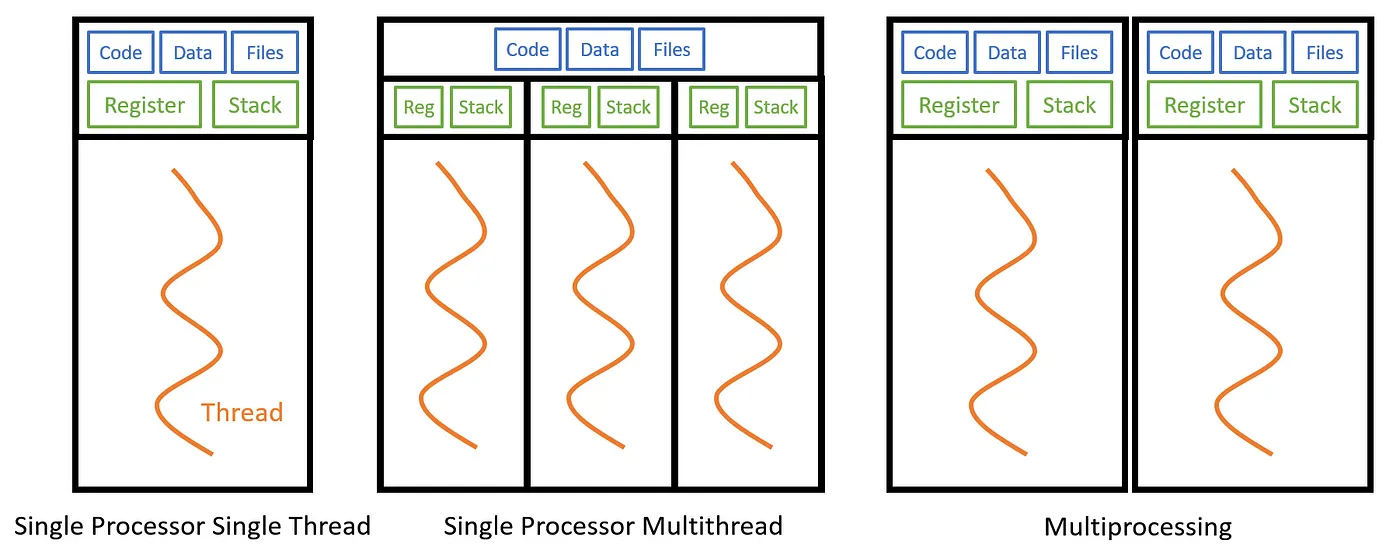

Slowly but surely

아주 유용한 정보네요!