[강의] 대규모 시스템 설계 내용 정리 (3)
⚙️ 대규모 시스템 설계 강의 정리 (섹션 4~5)
인프런 강의 섹션 4~5: 어뷰징 방지, Kafka 주요 개념, 인기글 시스템, Transactional Messaging 정리
기간: 9월 2일 ~ 9월 10일
📅 9월 2일 (화) — 조회수 어뷰징 방지 설계
🔹 왜 어뷰징 방지가 필요한가
조회수는 단순한 숫자처럼 보여도 서비스 신뢰도와 직결되는 중요한 데이터다.
하지만 특정 사용자가 반복적으로 조회 요청을 보내면 조회수가 비정상적으로 증가할 수 있다.
→ 즉, 조회수 조작(어뷰징)을 방지해야 한다.
🔹 사용자 식별 방법
| 구분 | 식별 기준 |
|---|---|
| 로그인 사용자 | 사용자 ID |
| 비로그인 사용자 | IP, USER-AGENT, 쿠키, 토큰 등 |
이 정보를 조합해 사용자를 임시로 식별할 수 있다.
🔹 Redis를 활용한 어뷰징 방지 정책
Redis는 TTL(만료 시간)을 설정할 수 있고, 원자적 명령어 제공(setIfAbsent) 덕분에
조회수 증가 요청을 “락(lock)”처럼 관리할 수 있다.
✅ 정책 설계
- 사용자가 특정 게시글을 조회할 때 Redis에 다음 구조로 데이터를 저장
key: view:{articleId}:{userIdentifier}
value: 1
TTL: 10분-
이미 동일 키가 존재하면 조회수 증가를 무시한다.
- Redis 명령어: SET key value NX EX 600 (NX → 존재하지 않을 때만 저장, EX → TTL 600초)
- Redis 명령어: SET key value NX EX 600 (NX → 존재하지 않을 때만 저장, EX → TTL 600초)
🔹 Redis를 이용한 분산 락
- 조회수 서비스는 여러 서버 애플리케이션으로 구성된 분산 환경에서 동작한다.
- Redis를 중앙 저장소로 사용하면 여러 서버 간에도 중복 조회 제어 가능
- 즉, “한 사용자-게시글 조합에 대한 조회”를 전역 락처럼 관리할 수 있다.
📘 정리하면:
Redis TTL + setIfAbsent = 분산 환경에서의 어뷰징 방지 + 간단한 분산 락 구현
📅 9월 10일 (수) — Kafka를 활용한 스트림 처리 및 인기글 시스템 설계
🧩 Kafka 주요 개념 정리
| 개념 | 설명 |
|---|---|
| Producer | Kafka로 데이터를 전송하는 클라이언트. 데이터를 “생산”함 |
| Consumer | Kafka에서 데이터를 구독해 읽는 클라이언트. 데이터를 “소비”함 |
| Broker | Kafka에서 Producer와 Consumer 사이의 데이터를 중개하는 서버 단위 |
| Kafka Cluster | 여러 Broker로 구성된 분산형 시스템. 고성능, 고가용성, 복제, 장애 복구 지원 |
| Topic | 데이터가 구분되는 논리 단위. (ex. “article-view-events”) |
| Partition | Topic이 분산되는 단위. 병렬 처리 가능하지만 파티션 간 순서는 보장되지 않음 |
| Offset | 각 파티션 내 데이터의 고유 위치(시퀀스) |
| Consumer Group | 여러 Consumer를 하나의 그룹으로 묶어 병렬 처리 및 오프셋 관리 수행 |
💡 Consumer Group 개념 예시
| 그룹명 | 목적 |
|---|---|
| popular-articles-group | 인기글 점수 계산 |
| view-optimizer-group | 조회수 캐시 최적화 |
- 그룹 내 컨슈머들은 데이터를 중복 없이 분담 처리
- 그룹 간에는 서로 독립적으로 이벤트를 소비
⭐ 인기글(Hot Article) 시스템 설계
🔹 요구사항
- 일 단위로 상위 10건 인기글 선정
- 기준: 좋아요 수 + 댓글 수 + 조회수 기반 점수
- 최근 7일 인기글 내역 제공
🔹 기존 배치 처리의 한계
- 대규모 데이터에서 시간 부족 및 시스템 부하 발생
- API 기반 수집은 장애 전파 위험이 높음
→ 따라서 실시간 스트림 처리 구조가 적합하다.
🔹 Kafka 기반 스트림 처리
- 각 서비스(좋아요, 조회수, 댓글 등)는 이벤트를 Kafka로 발행
- “인기글 서비스”는 Kafka의 여러 토픽을 구독해 점수를 실시간으로 계산
- 장애 전파 없이 비동기 이벤트 스트림으로 동작
✅ 장점
- 서비스 간 결합도 낮음
- API 호출 없이 비동기 이벤트 기반 통신
- Kafka 자체의 내결함성과 확장성 활용
🔹 인기글 저장소 설계
| 구분 | 선택 | 이유 |
|---|---|---|
| 데이터 특성 | 휘발성 (최근 7일만 유지) | TTL 필요 |
| 저장소 | Redis Sorted Set | 점수 기반 정렬 지원 |
- Redis ZADD 명령을 활용해 (score, article_id) 저장
- 상위 10건 조회: ZREVRANGE popular:YYYYMMDD 0 9 WITHSCORES
- TTL 설정으로 7일 이후 자동 삭제
인기글 계산은 하루 한 번만 수행되고, 상위 10건의 PK만 유지하면 된다.
🧱 Transactional Messaging (트랜잭셔널 메시징)
🔹 문제 상황
Producer가 Kafka로 이벤트를 전송하는 과정과
내부 비즈니스 로직(DB 업데이트 등)을 하나의 트랜잭션으로 관리해야 한다.
하지만 Kafka와 DB는 별개 시스템이라,
“부분 성공” 문제가 발생할 수 있다.
→ 즉, DB는 커밋됐는데 Kafka 전송 실패 / 혹은 반대 상황이 생김.
🔹 세 가지 해결 방법
| 방법 | 설명 | 단점 |
|---|---|---|
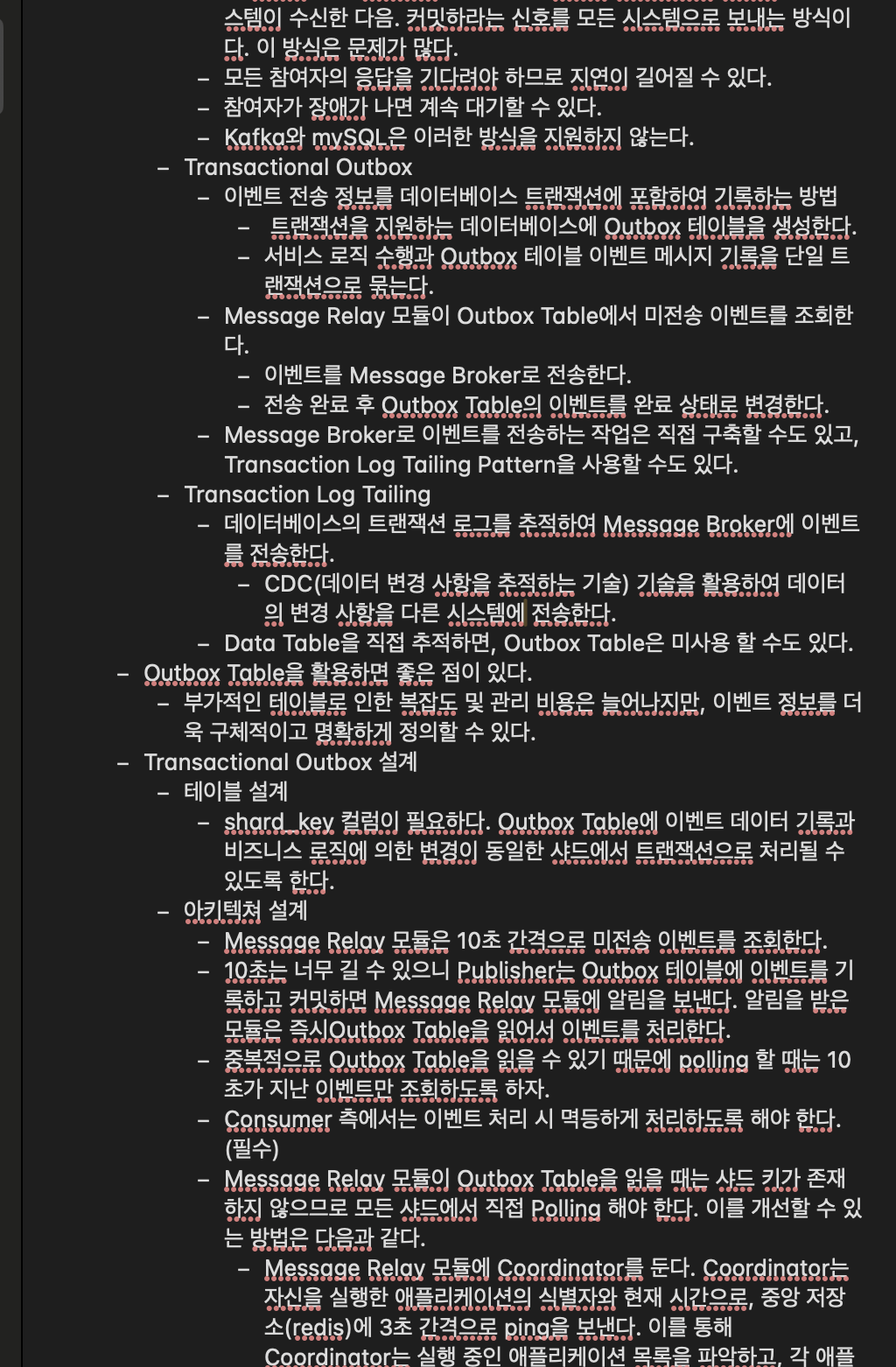
| 1. Two Phase Commit (2PC) | 모든 참여자의 응답을 모은 후 commit 신호 전송 | 지연 크고 장애 시 대기, Kafka/MySQL 미지원 |
| 2. Transactional Outbox | DB 트랜잭션에 Outbox 테이블 포함 → Message Relay가 전송 | Outbox 테이블 관리 필요 |
| 3. Transaction Log Tailing (CDC) | DB 트랜잭션 로그를 직접 추적해 이벤트 전송 | CDC 기술 필요, 구현 복잡 |
🔹 Transactional Outbox 패턴 설계
✅ 테이블 설계
- outbox 테이블은 트랜잭션을 지원하는 DB에 생성
- 주요 컬럼: event_id, event_type, payload, status, shard_key
- shard_key는 비즈니스 데이터와 동일 샤드에서 트랜잭션 처리 보장
✅ 동작 흐름
- 서비스 로직 + Outbox 이벤트 기록 → 단일 트랜잭션 커밋
- Message Relay 모듈이 10초마다 Outbox 테이블 조회
- 미전송 이벤트를 Kafka로 전송 후 상태 변경
- 중복 Polling 방지를 위해 “10초 지난 이벤트만 조회”
- Consumer는 반드시 멱등성(idempotency) 보장
🔹 Message Relay 개선 방안
- Outbox 테이블은 샤드별로 존재하므로, 모든 샤드에 접근해야 함
- 이를 개선하기 위해 Coordinator 구조 도입 가능
🧠 Coordinator 역할
- 중앙 저장소(redis 등)에 주기적으로 ping (3초 간격)
- 애플리케이션 식별자 + 타임스탬프로 실행 중인 인스턴스 파악
- 각 인스턴스에 샤드를 동적으로 분배
- 9초 이상 ping 없으면 종료된 것으로 판단하고 재분배
이 구조는 고가용성과 부하 분산을 함께 고려한 설계이며,
실제 대규모 시스템에서 Outbox Relay 모듈의 확장성 문제를 해결한다.
🧭 정리
| 주제 | 핵심 포인트 |
|---|---|
| 어뷰징 방지 | Redis TTL + NX(setIfAbsent)로 중복 조회 제어 |
| Kafka | Topic/Partition/Offset/ConsumerGroup 개념 숙지 |
| 인기글 설계 | 스트림 처리 + Redis Sorted Set으로 효율적 인기글 관리 |
| Transactional Messaging | Outbox 패턴으로 DB-이벤트 간 일관성 보장 |
| Outbox 개선 | Coordinator 기반 샤드 분산으로 확장성 확보 |
메모에 정리한 내용 GPT로 재정리함

개발 블로그