프로그래머스/과일 장수
https://school.programmers.co.kr/learn/courses/30/lessons/135808
자료구조의 이해와 탐색, 삽입의 시간복잡도 이해
서론
나는 LinkedList도 C언어로 직접 구현해봐서 LinkedList와 ArrayList의 차이점을 잘 알고있다고 생각했다.
LinkedList는 Node가 다음 노드의 주소를 갖고있어서
삽입 삭제와 같은경우 node의 주소값만 변경하면 돼서 삽입 삭제에 걸리는 시간은 의 시간복잡도를 갖지만,
탐색은 순차적으로 탐색하고, 운이 안좋으면 찾으려는 데이터가 맨 마지막에 위치해서 의 시간을 갖는다.
반면 ArrayList는 배열을 기반으로 구현돼서 삽입 삭제의 경우 배열을 통째로 새로 복사해서 삽입 또는 삭제를 하고, 그래서 인데, index가 존재해서 탐색은 이라고 알고있었다.
풀이 과정
- score를 list에 담고, sort한다.
- 그 후 score의 길이를 m으로 나누어 상자의 갯수를 구한다.
- 상자의 갯수만큼 상자의 최하 품질의 값을 구해 상자의 총 가격( 최하 품질의 값 * 상자당 과일의 갯수)을 구한다.
3-1. 이걸 상자의 갯수만큼 반복하며 총 가격을 누적해 더한다.
처음엔 LinkedList를 사용했다.
ArrayList를 사용하려다 LinkedList를 사용한 이유는 조건이 다음과 같이 주어졌는데,
3 ≤ k ≤ 9
3 ≤ m ≤ 10
7 ≤ score의 길이 ≤ 1,000,000
add를 최대 1,000,000번 해주어야 한다면
ArrayList를 이용해서 구현하면 수많은 데이터 복사가 이루어 질거라 예측했기 때문이다.
물론 list.get 부분은 빠르겠지만.
public static int solution(int k, int m, int[] score) {
int answer = 0;
LinkedList<Integer> list = new LinkedList<>();
for(int i = 0; i < score.length; i++) {
list.add(score[i]);
}
Collections.sort(list, (o1, o2) -> o2 - o1);
for(int i = 1; i <= score.length / m; i++) {
answer += m * list.get(i * m - 1);
}
return answer;
}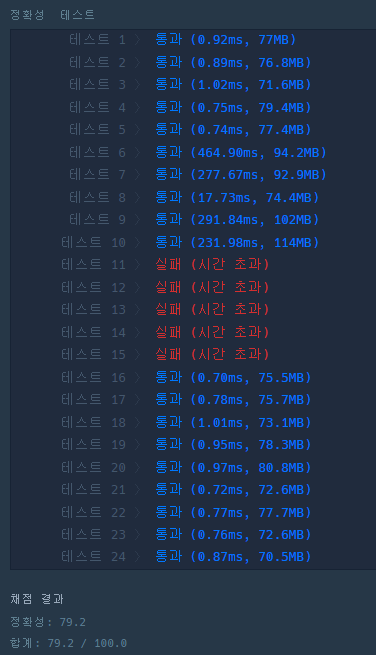
하지만 예상과는 달리 시간초과로 실패한 테스트 케이스가 발생했다.
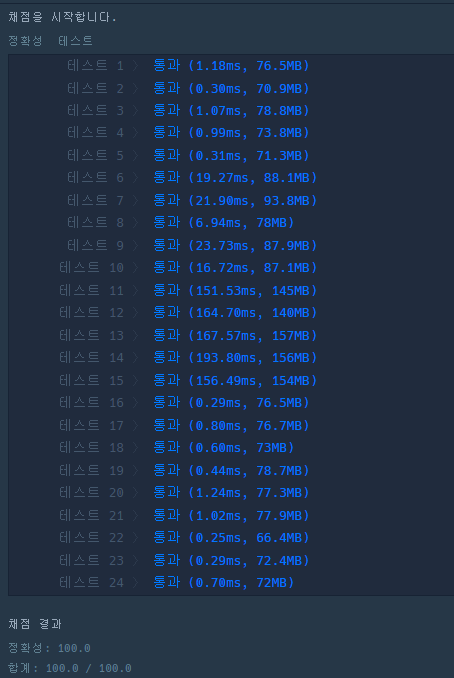
원래 사용하려했던 ArrayList를 사용해 코드를 다시 짰는데 테스트에 통과했다.
public static int solution(int k, int m, int[] score) {
int answer = 0;
ArrayList<Integer> list = new ArrayList<>();
for(int i = 0; i < score.length; i++) {
list.add(score[i]);
}
list.sort(Comparator.reverseOrder());
for(int i = 1; i <= score.length / m; i++) {
answer += m * list.get(i * m - 1);
}
return answer;
}
이유를 알고싶어 ArrayList에 대해 공부하던 중 알게된 사실이 있다.
ArrayList는 Capacity가 존재한다.
초기값은 10이며

ArrayList 객체는 크기를 증가시킬때 기존 capicity의 1.5배의 크기로 증가시킨다.
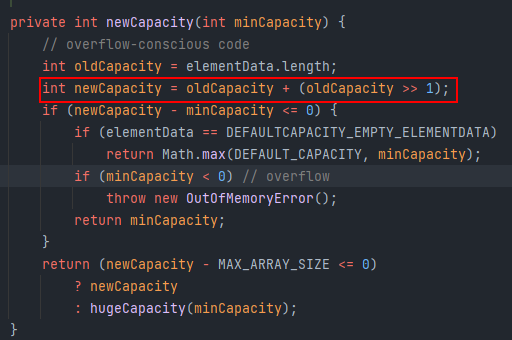
결국 문제 조건에 1,000,000의 과일 갯수로 1,000,000번 삽입에 의한 데이터 복사가 이루어지지 않을까 싶었던 내 예측은 틀렸고, 계산해보니 1,000,000번의 삽입으로는 30번의 배열 복사가 이루어진다.
단편적인 특징으로 자료구조를 이해해서 사용하다 이렇게 오류를 겪어보니, 자료구조를 정독해야 할 필요성을 느꼈다.
