Apache Spark를 사용해오면서 느낀 건 Spark Application은 매우 간단한 코드로 구현이 가능하지만 Low Level에서 어떤 로직으로 동작하는지 이해하기 어려웠다.
따라서 Spark의 기능과 내부구조를 더 정확히 공부하여 정리하고자 블로그를 시작하게 되었다.
Spark란?
Spark는 범용 고속 분산 컴퓨팅 프레임워크로 인메모리 데이터 프로세싱을 다양한 영역에 활용 가능하다.
Spark 주요 특징
Spark 공식 홈페이지에서 소개하는 주요 특징은 아래와 같다.
| 주요 특징 | 설명 |
|---|---|
| Speed | 말 그대로 속도가 빠르다! Spark측의 주장에 따르면 Hadoop MR 대비 약 100배의 속도 향상이 있다고 한다. |
| Ease of Use | 데이터 프로세싱에 일반적으로 사용되는 Java, Scala, Python, R, SQL등의 언어를 활용해 어플리케이션 작성이 가능하다. |
| Generality | SQL, 스트리밍, 머신러닝, 그래프 프로세싱 등 다양한 영역에서 활용 가능하다. 실제로 SQL과 스트리밍, 머신러닝은 활용 사례를 많이 보았으며 그래프의 경우는 아직 분야가 한정적인 듯 하다. |
| Runs Everywhere | Spark 단독으로도 실행이 가능하나 YARN, Mesos, Kubernetes 등 다양한 환경에서 동작한다고 한다. |
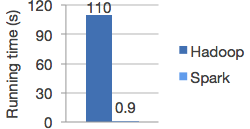
Spark의 가장 큰 특징 - Performance
Spark 홈페이지에서 Logistic Regression을 대상으로 Hadoop과 비교 테스트한 그래프이다.
이러니 Spark를 쓸수밖에 없다
그렇다면 Spark는 왜 빠를까?
그 이유는 Spark의 저레벨에서 사용하는 데이터 형식인 RDD(Resilent Distributed Dataset)에서 찾을 수 있다.
Hadoop MapReduce의 경우엔 데이터를 HDFS에서 Read/Write하는 과정을 데이터를 처리할 때마다 반복하게 되는데, 이 과정에서 많은 I/O Cost가 발생한다.
그러나 Spark의 경우 처음 데이터셋을 HDFS에서 읽어와서 메모리에서 작업을 하게 된다. 당연히 속도의 차이가 날 수밖에 없다.
그럼 다음 포스트에서 RDD에 대하여 더 자세히 정리하도록 하겠다.
