오늘은 coroutine(이하 코루틴)에 대해 이야기해보려고 해요.
많은 앱에서 코루틴을 활용하여 service 단을 개발하고 진행하는 것을 보면서 꼭 배워야하는 기능이다! 라고 생각하고 있습니다. 물론 아직 잘하진 않지만, 개념적인 부분을 틈틈히 채워보려고 합니당!
그리고 코루틴의 양이 생각보다 방대하다고 생각합니다. kotlin에서만 코루틴을 제공하는 것은 아니며 많은 언어에서 제공하는 만큼 그 개념을 보다 자세히 알아보죠!
우선 나무위키에 있는 코루틴의 정의부터 살펴보죠!
Coroutine의 정의
코루틴은 서브 루틴을 일시 정지하고 재개할 수 있는 구성 요소를 말한다.
쉽게 말해 필요에 따라 일시 정지할 수 있는 함수를 말한다.
코루틴은 pause와 resume을 할 수 있는 함수를 의미해요! javascript를 아시는분은 바로 느낌이 오시겠지만, 비동기를 지원하는 기능이 바로 coroutine입니다!
그럼 정의를 좀 더 자세히 뜯어보죠!
서브루틴 : 여러 명령어에 이름을 부여하여 반복 호출할 수 있게 정의한 프로그램
그리고 서브루틴은 다른 말로는 함수로 이해하셔도 됩니다! 함수에 이름을 부여해서 반복 호출할 수 있도록 정의한 것을 서브루틴으로 생각하시면 됩니다.
어? 그러면 메소드나 함수도 다 서브루틴 아니야?
네. 서브루틴이 맞습니다
하지만 코루틴에서 이야기하는 서브루틴이 갖는 뉘앙스는 조금 다릅니다. 우리가 함수를 여러 개 정의하고 이를 사용하게 되면 함수간 서로 협력한다는 느낌을 받기는 어렵습니다. 여기서 협력이라는 의미는 PC또는 Mobile의 한정된 자원을 함수들이 적절히 주고 받으면서 사용한다고 생각하시면 됩니다.
그럼 이런 생각이 드실거에요
thread에서 자원을 주고 받다가 임계 영역으로 인해 예상치 못한 문제가 발생하는거 아니야?
하지만 코루틴은 문제가 발생하지 않습니다.
이제 그 이유를 말씀드릴게요.
Coroutine 비동기로 인한 문제가 발생하지 않는 이유
-
서브루틴(함수, 메소드)에 접근하는 방법은 오직 한 가지이며, 그때 마다 activation record라는 것이 stack에 할당되어 서브루틴 내부의 로컬 변수 등이 초기화 됩니다.
-
서브루틴 안에서는 return을 여러 번 사용할 수 있으며, 이를 통해 서브루틴의 실행 중단을 제어하면, 제어를 요청한 서브루틴에게 해당 자원을 돌려줍니다. 이때 제어를 요청한 서브루틴이 자원을 받는 시점은 여러개가 될 수 있습니다.
-
여기서 전 서브루틴에서 반환디고 나면 activation record가 stack에서 사라집니다. 따라서 실행 중이던 모든 상태를 잃어버립니다.
-
그 결과 서브루틴을 여러 번 반복해도 항상 같은 결과를 얻을 수 있습니다.
물론 주의할 점은 있습니다. 전역 변수나 다른 부수 효과는 없어야된다.는 가정을 해야합니다.
그리고 코루틴의 또 하나의 특징은 바로 비선점(Non preemptive)입니다. 따라서 운영제체가 강제로 서브루틴을 중지시키고 다른 서브루틴을 실행하게 만들 수 없다는 의미입니다. 그러므로 각 서브루틴들이 서로 자발적으로 협력해야만 코루틴이 제대로 작동되겠죠.
그림 출처
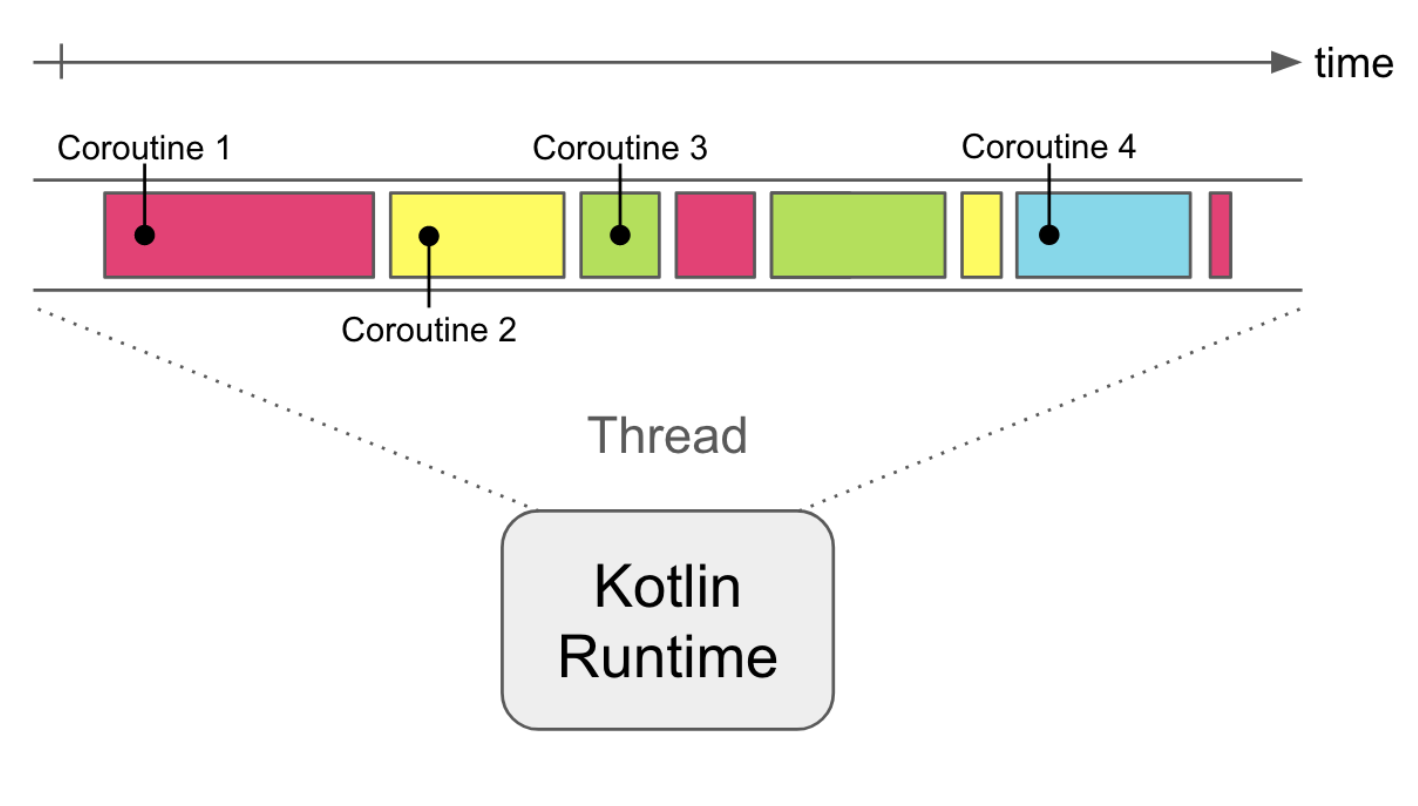
각 루틴들이 실행되다가 다시 재개되고 하는 모습을 보실 수 있을 겁니다.
결국에는 Kotlin의 루틴은 main이 되는 main routine과 coroutine이 존재합니다. 즉 별도로 진행이 가능한 작업 루틴으로 개발자가 마음대로 실행과 종료를 제어할 수 있는 단위를 coroutine이라고 합니다.
추가적으로 이러한 Coroutine이 실행되는 영역이 바로 Thread입니다.
Coroutine의 역할
개인적으로 Coroutine을 학습하면서 가장 중요한 개념이 바로 일시 중단으로 생각하고 있습니다. 무엇이 중단된다는 것일까요? 바로 함수입니다. 함수A가 실행되다가 중단되고 함수B가 실행되었다가 다시 함수A로 돌아와 해당 작업을 진행합니다. javascript를 주로 사용하셨던 분이라면 그냥 비동기네? 라고 생각이 드실겁니다. 네 Coroutine은 비동기 처리를 위한 library입니다. 당연한 것이죠.
좀 더 구체적인 예시를 들어볼게요.
-
Main Thread → 작업1 수행 중 작업3의 결과 A가 필요함.
-
IO Thread → 작업1과 다른 Thread에서 작업3을 진행 중이며 결과 A를 얻기 위한 연산 중.
-
Main Thread → 작업1은 결과 A를 얻으면 다시 시작해야 되기 때문에 중단되며 이때 Main Thread에서는 다른 연산인 작업2를 수행함.
-
Main Thread → 작업2를 완료함.
-
IO Thread → 작업3을 통해 결과 A를 작업1에 전달함.
-
Main Thread → 작업1이 재개됨.
그리고 이러한 작업을 Job이라고 부릅니다.
그러면 이러한 Coroutine의 기능은 어떻게 사용할 수 있을까요? 엄청 다양한 부분에서 사용됩니다. 특히나 Background Task가 필요한 경우에는 이러한 coroutine을 네트워크, DB 접근에 많이 이용하곤 해요.
그렇다면, Retrofit, OkHttp3, Urlconnection이나 Room, SQLite에 Coroutine이 이용될 수 있겠네요.
보다 자세한 kotlin Coroutine의 개념
coroutine을 사용할 때는 import kotlinx.coroutine.*을 import해야 합니다. 즉 모두 import해야 합니다.
import kotlinx.coroutines.* // Coroutine 사용 파일 최상단에 import 해야 합니다.coroutine은 제어범위 및 실행범위를 지정하여 제어할 수 있는 데, 이를 coroutine의 Scope라고 부릅니다. 이 역시 global scope와 coroutine scope를 지원하고 있습니다.
- global scope: 프로그램 어디에서나 제어, 동작이 가능한 범위
- coroutine scope: 특정한 목적의 Dispatcher를 지정하여 제어 및 동작이 가능한 범위
그러면 이런 생각이 드실수도 있어요.
Dispatcher는 뭐야..?
Dispatch를 변역하면 보내다라는 의미를 갖고 있습니다. 뭘 보내는걸까요? 저도 아직 무엇을 보내는지 확실할 수는 없지만,
작업을 위한 코드를 coroutine scope로 보낸다!라는 의미로 받아들이고 있습니다.
일반화된 의미의 경우에 Dispatch는 다음과 같아요!
Multi Programming System에서 후에 처리할 작업을 선택하여 실행시키는
것. 즉, 대기 열에서 기다리고 있는 Process를 선택하여 중앙 처리 장치
의 사용 권한을 부여하는 작업.
물론 저 위의 Dispatch의 의미는 상황에 따라 달라질 수도 있다고 합니다.
그러면 기본적인 개념에 대해서는 알게되었어요.
Coroutine을 사용할 때 Job이 처리되는 Scope는 Global Scope 또는 Coroutine Scope로 나뉜다는 것입니다.
그리고 Dispatcher는 다음과 같이 세부적으로 구분할 수 있습니다.
- Dispatchers.Default: 기본적인 백그라운드 동작을 제어
- Dispatchers.IO: I/O에 최적화된 동작
- Dispatchers.main: main thread에서 동작
주의 위 Dispatcher의 제어는 모든 플랫폼에서 지원되진 않습니다.
개발자의 입장에서 어떤 Dispatcher에서 처리할지 미리 알려줘야겠죠? 즉 scope를 먼저 생성해야 합니다.
val scope = CorouineScope(Dispatcher.Default)
val coroutineA = scope.launch {}
val coroutineB = scope.async {}launch 🆚 async
launch와 async는 kotlin coroutine의 대표적인 block입니다.
이 둘의 차이는 반환값의 이 무엇인가? 입니다.
- launch: 반환값이 Job 객체
- async: 반환값이 Deffered 객체
조금 더 궁금증이 있으신 분들은 Job이랑 Deffered의 구체적인 차이는 뭔데..? 라고 생각하실 수 있어요.
이 둘은 각각의 scope에서 반환되는 객체를 의미합니다. launch lambda를 쓰면 Job 객체가 반환되고 async lambda를 쓰면 Deffered 객체가 반환됩니다.
아래는 이 둘을 구성하고 있는 실제 코드입니다.
// launch
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy) {
LazyStandaloneCoroutine(newContext, block)
} else {
StandaloneCoroutine(newContext, active = true) // 여기!
}
coroutine.start(start, coroutine, block)
return coroutine
}
//async
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope. () -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy) {
LazyDeferredCoroutine(newContext, block)
} else {
DeferredCoroutine<T>(newContext, active = true) // 여기!
}
coroutine.start(start, coroutine, block)
return coroutine
}launch의 StandaloneCoroutine 그리고 async의 DeferredCoroutine<T> 그리고 함수의 출력값이 이외에는 다른 차이점은 없는 것을 볼 수 있습니다.
솔직히 아직 감은 안오셨죠? 코드에서는 이 둘의 개념적인 차이가 무엇인지 정확히 와닿지 않았을 겁니다.
그러면 이렇게 생각해보죠.
Job은 말 그대로 coroutine의 모든 작업을 의미합니다. 상황에 따라서 Job은 반환값이 없을 수도 있습니다. 또는 어떤 작업이 제대로 완료되지도 않는 경우까지 모두 포함하는 것이 바로 Job입니다. 그런 이유는 바로 함수의 인자인 block 타입을 봐주세요.
고차 함수 형태로 들어가 있는 데!
launch의 경우 CoroutineScope()가 Unit(반환값 없음)
Deferred의 경우 CoroutineScope()가 T(제네릭)
이런 차이가 있습니다.
보다 자세히 Deferred는 연기하다라는 의미를 갖고 있습니다. 무엇을 연기할까요? 그건 바로 결과값을 수신입니다. 언제인지는 모르지만, 분명한 건 미래에 있을 특정 시점에 결과값이 올거란 의미입니다.
그리고 Deferred Job의 확장 인터페이스입니다. 실제 Deferred의 코드를 뜯어보면 이렇게 생겼어요.
public interface Deferred<T: out> : Job {
public suspend fun await(): T
public val onAwait: SelectClause1<T>
}위 코드를 통해 Deferred interface는 Job을 상속한 것을 알 수 있습니다. Deferred는 job으로 볼 수 있으며, 따라서 Deferred는 job의 속성으 모두 가져갑니다.
이후 launch 및 각 코드별 사용방법에 대해 내용이 추가될 예정
