
제 맥북은 13인치 M1 모델로 통합 메모리는 8GB입니다. 성능 제약 때문에 경량화된 로컬 언어모델(LLM)을 활용하고자 합니다.
이번에 구동해볼 모델은 Google에서 출시한 경량 언어모델인 Gemma 3입니다.
Gemma 3 모델의 요구 메모리
아래는 Gemma 3 모델의 크기별, 정밀도별 메모리 요구사항입니다.
| 모델 크기 | FP32 | BF16 | SFP8(8-bit) | Q4_0(4-bit) | INT4/QAT |
|---|---|---|---|---|---|
| Gemma 3 1B | 4 GB | 1.5 GB | 1.1 GB | 0.9 GB | 0.86 GB |
| Gemma 3 4B | 16 GB | 6.4 GB | 4.4 GB | 3.4 GB | 3.2 GB |
| Gemma 3 12B | 48 GB | 20 GB | 12.2 GB | 8.7 GB | 8.2 GB |
| Gemma 3 27B | 108 GB | 46.4 GB | 29.1 GB | 21 GB | 19.9 GB |
자세한 모델 정보는 공식 문서에서 확인할 수 있습니다.
데이터 타입 FP32, BF16 등의 개념
FP32 (Single Precision Floating Point)
FP32는 32비트 부동 소수점 데이터 타입입니다. 높은 정확성을 제공하지만 메모리와 계산 자원을 상대적으로 많이 소모합니다.
BF16 (Brain Floating Point)
BF16은 FP32의 부동 소수점 표현 방식을 절반으로 줄인 16비트 데이터 타입입니다. FP32와 유사한 동적 범위를 유지하면서 메모리 사용량과 연산 속도를 크게 개선하여 주로 딥러닝 모델 훈련 시 효율성을 높이는 데 사용됩니다.
FP16 (Half Precision Floating Point)
FP16은 16비트의 부동 소수점 데이터 타입으로 FP32 대비 메모리 사용량과 연산 속도가 개선됩니다. 하지만 표현 가능한 범위가 좁아 수치 표현에서 정확성 저하 문제가 발생할 수 있습니다.
M1 맥북에서 가능한 모델
제가 가진 8GB 메모리의 M1 맥북 프로에서는 Gemma 3 4B 모델의 4-bit(Q4_0) 또는 QAT(INT4) 버전을 테스트할 수 있을 것 같습니다.
홈브루(Homebrew)로 Ollama 설치하기
제 맥북에는 이미 홈브루가 설치되어 있지만, 설치되지 않았다면 홈브루 공식 사이트에서 먼저 설치하세요.
터미널에서 다음 명령어로 Ollama를 설치하고 서비스를 활성화합니다.
brew install ollama
brew services start ollama

Gemma 3 모델 다운로드하기
이제 Ollama를 통해 Gemma 3 모델을 다운로드합니다.
- 기본 4-bit 모델
ollama pull gemma3:4b- 더 가벼운 QAT 양자화 버전(메모리 사용량 약 1/3 감소)
ollama pull gemma3:4b-it-qat-
모델 정보:
gemma3:4b: 4B 파라미터, 128K 컨텍스트, 3.3 GBgemma3:4b-it-qat: QAT 적용 모델로 품질을 유지하며 메모리를 현저히 절감

간단한 프롬프트 실행 예시
터미널에서 간단한 예시 명령어를 실행해봅니다.
ollama run gemma3:4b-it-qat "BF16, FP16, FP32의 차이점을 설명해주세요."이 명령어를 통해 로컬에서 간편하게 Gemma 3 LLM을 활용할 수 있습니다.
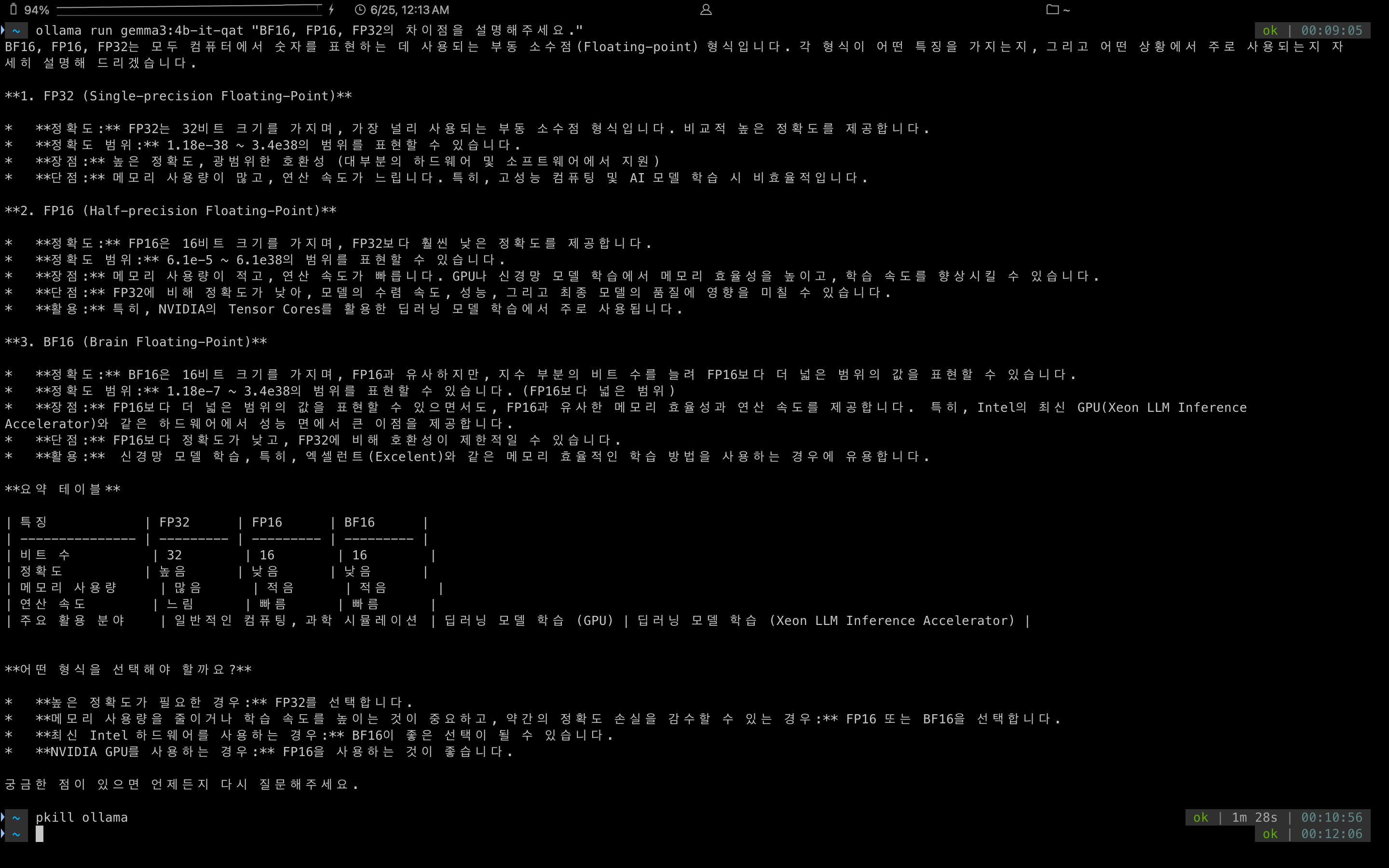
다만, 한 번 동작을 하면 램 점유율이 내려가지 않고 os가 전체적으로 느려지는 것을 확인했습니다. 이를 해결하기 위해서 pkill ollama 명령어를 활용하여 ollama 실행을 종료하였습니다.
ollama 명령어 예시
Ollama 대화 모드 내 유용한 명령어:
ollama run을 통해 모델과 상호 작용하는 동안 /로 시작하는 특수 명령을 사용할 수 있습니다.
/?: 사용 가능한 모든 슬래시 명령어 목록이 포함된 유용한 메뉴를 표시합니다./set parameter <매개변수_이름> <값>: 현재 채팅 세션에 대한 모델의 런타임 매개변수를 일시적으로 변경합니다. 예를 들어/set parameter temperature 0.9는 창의성을 높이고/set parameter num_ctx 8192는 이 세션의 컨텍스트 창을 늘립니다./show info: 현재 로드된 모델에 대한 자세한 정보(매개변수, 템플릿 구조, 라이선스 등)를 표시합니다./show modelfile: 현재 실행 중인 모델을 만드는 데 사용된Modelfile의 내용을 표시합니다. 기본 모델, 매개변수 및 프롬프트 템플릿을 이해하는 데 유용합니다./save <세션_이름>: 현재 채팅 기록을 명명된 세션 파일에 저장합니다./load <세션_이름>: 이전에 저장한 채팅 세션을 로드하여 대화 기록을 복원합니다./bye또는/exit: 대화형 채팅 세션을 정상적으로 종료하고 모델을 메모리에서 언로드합니다(다른 세션에서 사용하지 않는 경우). 일반적으로 Ctrl+D를 사용하여 종료할 수도 있습니다.
프롬프트 환경을 넘어서 좀 더 사용자 친화적인 UI를 원한다면, OpenWebUI와 같은 플랫폼을 함께 사용해보는 것도 좋을 것 같습니다.
