개요
LM Studio를 활용하면 편하게 로컬에서 최신 언어 모델을 실행하고 자신의 애플리케이션에 연동할 수 있습니다. 이번 글에서는 Gemma 4 모델을 LM Studio로 로드한 뒤, FastAPI를 이용해 간단한 REST 엔드포인트로 서빙하는 방법을 소개해보겠습니다.
준비 사항
- 운영체제: Windows 10 또는 11 (64 비트).
- 하드웨어: AVX2를 지원하는 CPU와 16 GB RAM 이상을 권장합니다. GPU는 선택 사항이지만 있으면 속도가 빨라집니다.
- 소프트웨어: LM Studio (0.4.12 이상)와 Python 3.8 이상, FastAPI, Uvicorn.
1. LM Studio 설치와 모델 로드
1.1 LM Studio 설치
- 다운로드: LM Studio 사이트에서 Windows용 설치 파일을 내려받습니다.
- 설치: 실행 파일을 열어 설치를 완료합니다.
3. 실행: 설치 후 LM Studio를 실행하면 모델 탐색 화면이 나타납니다.
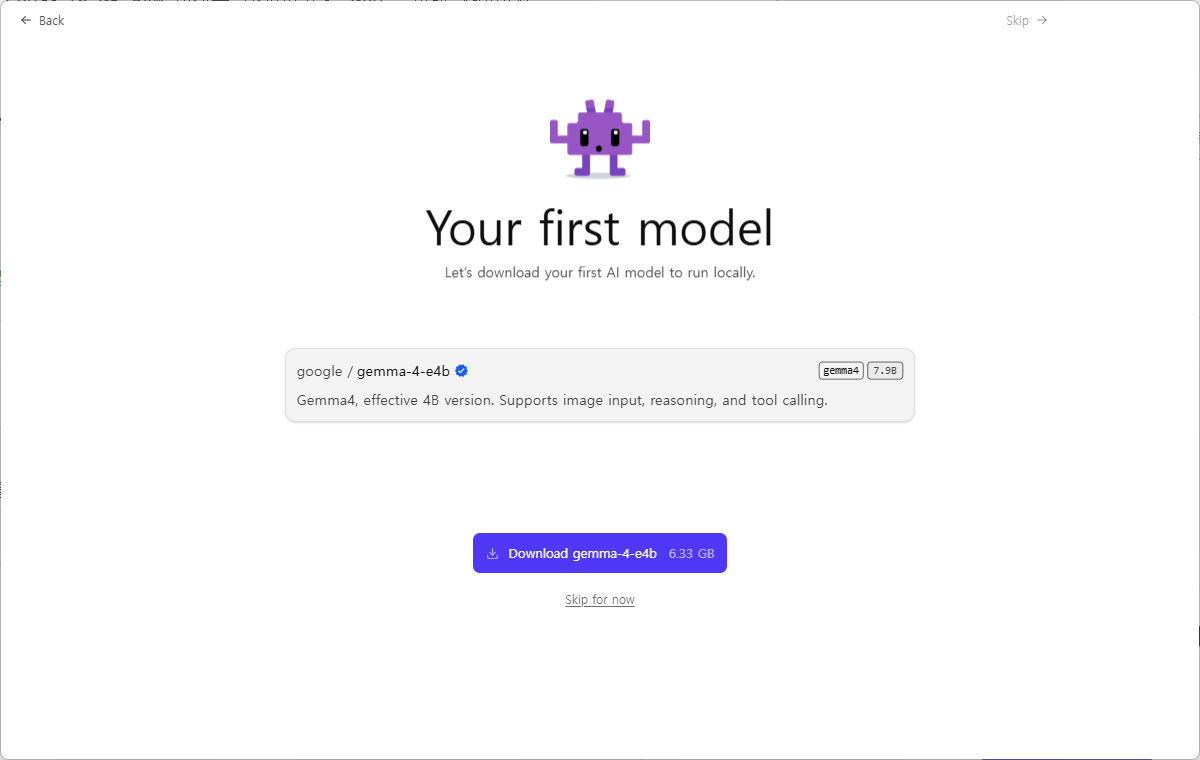
- 저는 자동으로 gemma-4-e4b 모델을 추천해주어 바로 설치했습니다. 추천해주지 않은 다른 모델을 사용하고자 할 때는 아래 1.2의 방법을 활용하면 됩니다.
- 저와 같이 사용하고자 하는 모델을 바로 다운로드 하신 경우에는, 1.3으로 바로 넘어갑니다.
1.2 모델 다운로드
- 상단의 검색창에서 Gemma 4를 검색합니다. 여러 변형(E2B, E4B, 26B A4B, 31B)이 목록에 표시됩니다.
- 시작은 가벼운 E2B 또는 E4B 모델로 해보는 것이 좋습니다.
- 해당 모델의 Get 버튼을 클릭해 다운로드합니다. 다운로드가 완료되면 My Models 섹션에서 모델을 확인할 수 있습니다.
1.3 모델 로드와 테스트
- My Models에서 원하는 Gemma 4 모델을 선택하고 Load를 클릭하면 모델이 메모리에 올라갑니다.
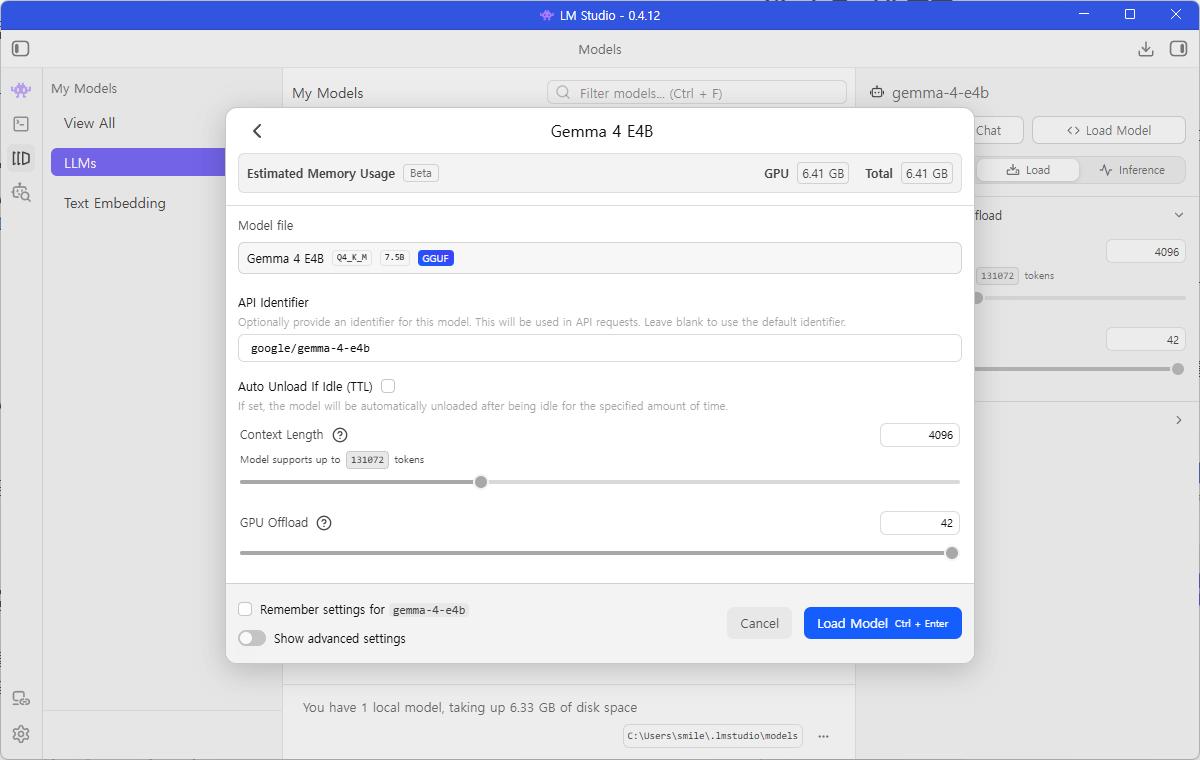
- 로드가 완료되면 좌측 메뉴의 Chat 탭에서 모델과 대화를 나눌 수 있습니다. 간단히 “안녕하세요?”와 같은 메시지를 입력해 응답을 확인해보세요.
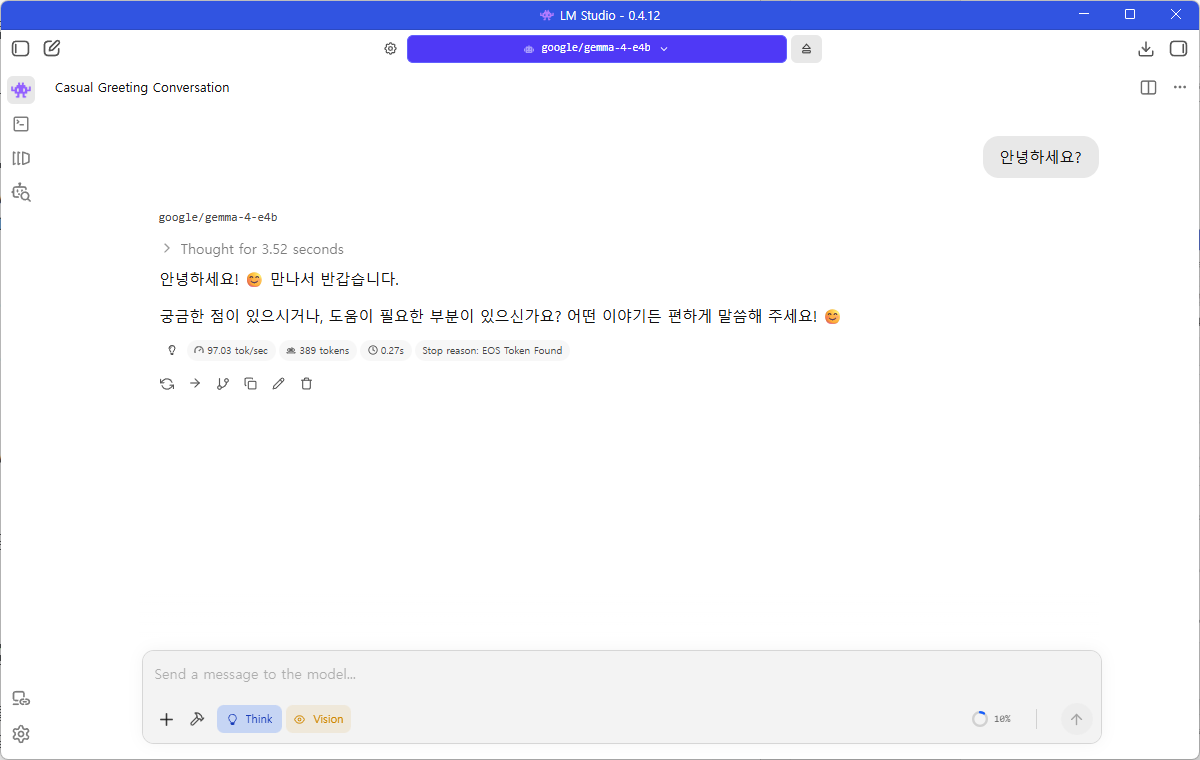
- 그리고 이후 FastAPI 테스트를 위해서 Developer 탭에서 서버를 활성화니다. 기본 포트는 1234입니다. 이 서버는 OpenAI 방식과 유사한 REST API를 제공합니다.
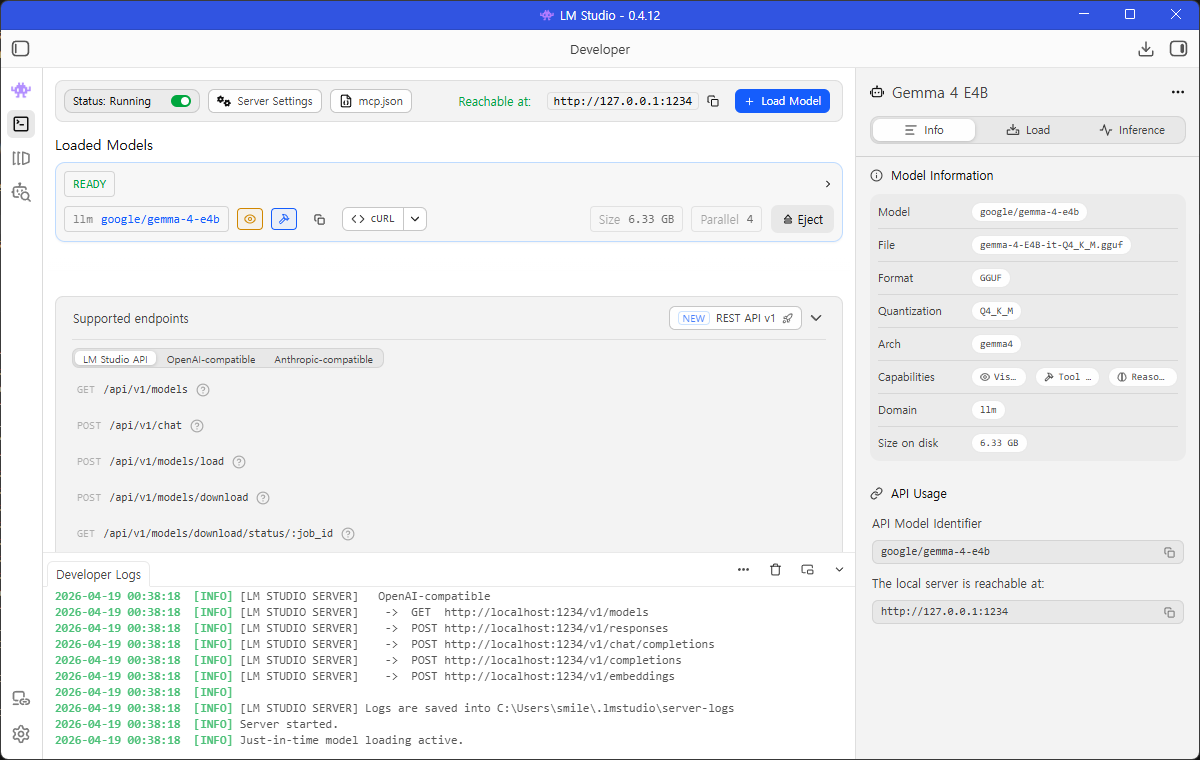
2. FastAPI로 간단한 백엔드 구축
LM Studio의 Python SDK(lmstudio-python)를 이용하면 다른 서비스에서 로컬 모델을 쉽게 호출할 수 있습니다. 공식 개발 문서의 예시처럼 pip install lmstudio로 SDK를 설치한 뒤, 모델을 불러와 응답을 받는 코드를 작성할 수 있습니다. 이를 FastAPI와 결합해 간단한 REST 서비스로 만들겠습니다.
2.1 환경 준비
-
Python 가상환경을 생성하고 활성화합니다.
-
필요한 패키지를 설치합니다.
pip install lmstudio fastapi uvicorn
- LM Studio 앱에서 모델을 로드한 상태인지 확인합니다. SDK는 이미 실행 중인 LM Studio 인스턴스에 연결합니다.
2.2 FastAPI 애플리케이션 코드
아래 코드는 FastAPI를 사용해 /chat 엔드포인트를 생성하고, 요청으로 받은 프롬프트를 LM Studio에 전달해 응답을 반환합니다. Medium 기사에서 소개한 방법을 참고했습니다.
import lmstudio as lms
from fastapi import FastAPI
app = FastAPI()
MODEL_ID = "google/gemma-4-e4b"
model = None
@app.on_event("startup")
def startup():
global model
# 첫 convenience API 호출 전에 먼저 설정
lms.configure_default_client("localhost:1234")
# 서버 확인
if not lms.Client.is_valid_api_host("localhost:1234"):
raise RuntimeError("LM Studio 서버가 localhost:1234 에서 실행 중이 아닙니다.")
model = lms.llm(MODEL_ID)
@app.get("/health")
def health():
return {"ok": True}
@app.get("/ask")
def ask(q: str):
result = model.respond(q)
return {"answer": str(result)}위 코드에서
google/gemma-4-e4b는 LM Studio에서 다운로드하고 로드한 모델의 이름입니다. 다른 모델을 사용한다면 이 부분을 변경하면 됩니다. SDK의respond메서드는 전체 응답을 한 번에 받아오며,respond_stream메서드를 사용하면 토큰 단위로 스트리밍 받을 수 있습니다.
2.3 서버 실행과 테스트
- FastAPI 서버를 실행합니다.
uvicorn main:app --host 0.0.0.0 --port 8000 --reload- 다른 터미널이나 Postman에서 다음과 같이 테스트합니다.
curl -X POST "http://localhost:8000/ask" \
-H "Content-Type: application/json" \
-d '{"prompt": "당신은 누구인가요?"}'응답으로 `{"response": "..."}` 형태의 결과가 반환되며, 내부적으로는 LM Studio에 연결되어 Gemma 4 모델이 프롬프트를 처리합니다.- 혹은 FastAPI가 자동으로 제공하는 Swagger를 통해서 테스트 해볼 수 있습니다.
http://localhost:8000/docs에 접속하여 테스트를 해봅니다.
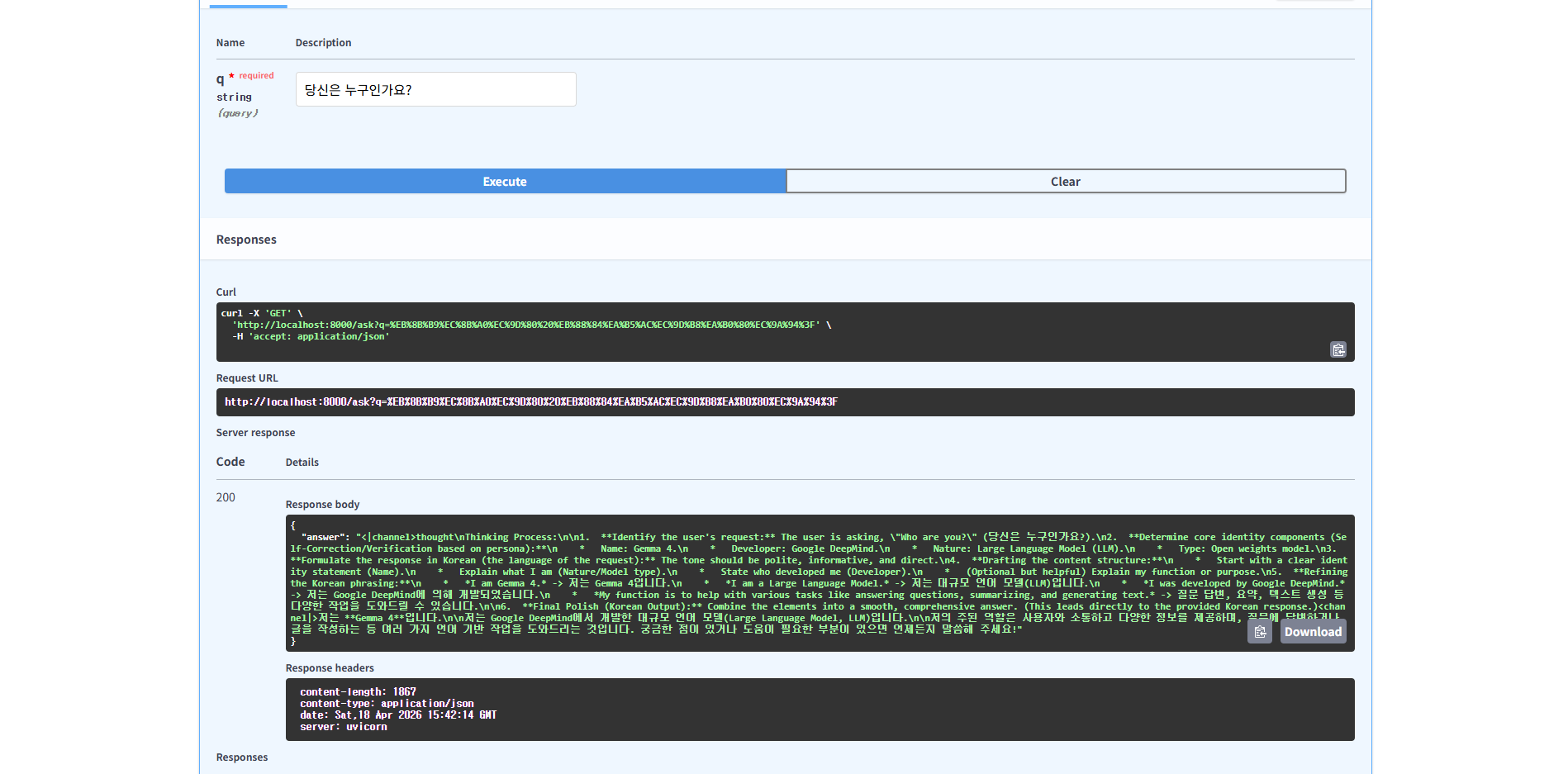
{
"answer": "<|channel>thought\nThinking Process:\n\n1. **Identify the user's request:** The user is asking, \"Who are you?\" (당신은 누구인가요?).\n2. **Determine core identity components (Self-Correction/Verification based on persona):**\n * Name: Gemma 4.\n * Developer: Google DeepMind.\n * Nature: Large Language Model (LLM).\n * Type: Open weights model.\n3. **Formulate the response in Korean (the language of the request):** The tone should be polite, informative, and direct.\n4. **Drafting the content structure:**\n * Start with a clear identity statement (Name).\n * Explain what I am (Nature/Model type).\n * State who developed me (Developer).\n * (Optional but helpful) Explain my function or purpose.\n5. **Refining the Korean phrasing:**\n * *I am Gemma 4.* -> 저는 Gemma 4입니다.\n * *I am a Large Language Model.* -> 저는 대규모 언어 모델(LLM)입니다.\n * *I was developed by Google DeepMind.* -> 저는 Google DeepMind에 의해 개발되었습니다.\n * *My function is to help with various tasks like answering questions, summarizing, and generating text.* -> 질문 답변, 요약, 텍스트 생성 등 다양한 작업을 도와드릴 수 있습니다.\n\n6. **Final Polish (Korean Output):** Combine the elements into a smooth, comprehensive answer. (This leads directly to the provided Korean response.)<channel|>저는 **Gemma 4**입니다.\n\n저는 Google DeepMind에서 개발한 대규모 언어 모델(Large Language Model, LLM)입니다.\n\n저의 주된 역할은 사용자와 소통하고 다양한 정보를 제공하며, 질문에 답변하거나 글을 작성하는 등 여러 가지 언어 기반 작업을 도와드리는 것입니다. 궁금한 점이 있거나 도움이 필요한 부분이 있으면 언제든지 말씀해 주세요!"
}-
응답의 내용을 살펴보면 정상적인 최종 답변만 나온 상태가 아니라, 모델의 중간 사고 과정(Thinking Process)과 최종 답변이 함께 노출된 형태입니다.
-
<|channel>thought
이 부분은 모델이 내부적으로 답을 만들기 위해 사용한 사고 채널처럼 보입니다. -
Thinking Process:아래의 1~6번
사용자의 질문을 어떻게 해석하고, 어떤 요소를 답변에 넣을지 정리한 중간 추론 과정입니다. -
<channel|>저는 **Gemma 4**입니다.이후
이 부분이 실제 사용자에게 보여주려던 최종 응답입니다. -
즉, 이 JSON의
answer값에는 “생각 과정 + 최종 답변”이 한 문자열에 같이 들어가 있습니다. 해석하면 이런 구조입니다.- 사용자의 질문 파악
사용자가 “당신은 누구인가요?”라고 물었다고 인식 - 답변에 넣을 핵심 정보 정리
- 이름: Gemma 4
- 개발사: Google DeepMind
- 정체: 대규모 언어 모델
- 성격: 오픈 웨이트 모델
- 답변 언어 결정
사용자가 한국어로 물었으니 한국어로 답변 - 답변 구성 초안 작성
- 나는 누구인지
- 어떤 모델인지
- 누가 만들었는지
- 무엇을 할 수 있는지
- 한국어 문장 다듬기
영어 개념을 자연스러운 한국어 문장으로 바꾸는 단계 - 최종 문장 생성
실제 사용자에게 보여줄 최종 답변 완성
- 사용자의 질문 파악
-
이 과정은 사용자에게 그대로 보이면 안 되는 경우가 많습니다. 따라서 현재의 응답 형태는 로직 구현에서는 사용하되, 답변 받은 그대로를 서빙하지는 않도록 해야겠습니다.
-
3. 마무리와 다음 단계
이번 글에서는 Windows 환경에서 LM Studio로 Gemma 4 모델을 다운로드·로드하고, Python의 FastAPI를 사용해 간단한 REST API를 만드는 방법을 살펴보았습니다.
LM Studio가 제공하는 로컬 API를 직접 호출할 수도 있지만, FastAPI를 덧씌우면 네트워크를 통한 활용이나 추가 로직을 포함한 애플리케이션 통합이 쉬워집니다. 필요에 따라 다음과 같은 확장을 시도해볼 수 있겠습니다.
- 다른 모델 사용: E4B보다 더 큰 26B A4B나 31B 모델을 로드해 성능과 응답 품질을 비교해 볼 수 있습니다.
- 스트리밍 응답 처리:
respond_stream메서드를 사용하여 웹소켓이나 SSE(Server-Sent Events) 형태로 토큰을 실시간으로 전달할 수 있습니다. - 보안 강화: FastAPI에 인증과 권한 제어를 추가하고, LM Studio 서버 자체의 인증 기능을 활성화해 데이터 노출을 방지합니다.
LM Studio와 FastAPI를 통해 로컬 LLM을 간편하게 활용해 보시면, 여러분의 프로젝트나 서비스에 맞춰 자유롭게 커스터마이징할 수 있습니다.
