
1. 데이터 전처리
1) 집합(Aggregation)
- 여러개의 속성(또는 개체)을 단일 속성(또는 개체)으로 결합
- 목적
- 데이터 감소 - 속성 또는 개체의 수를 줄인다.
- 스케일 변경
- 지역, 주, 국가 등으로 집계된 도시
- 주, 월 또는 년으로 집계된 일
- 더 "안정적인" 데이터
- 집계된 데이터는 변동성이 적은 경향이 있다.
- 예: 호주의 강수량
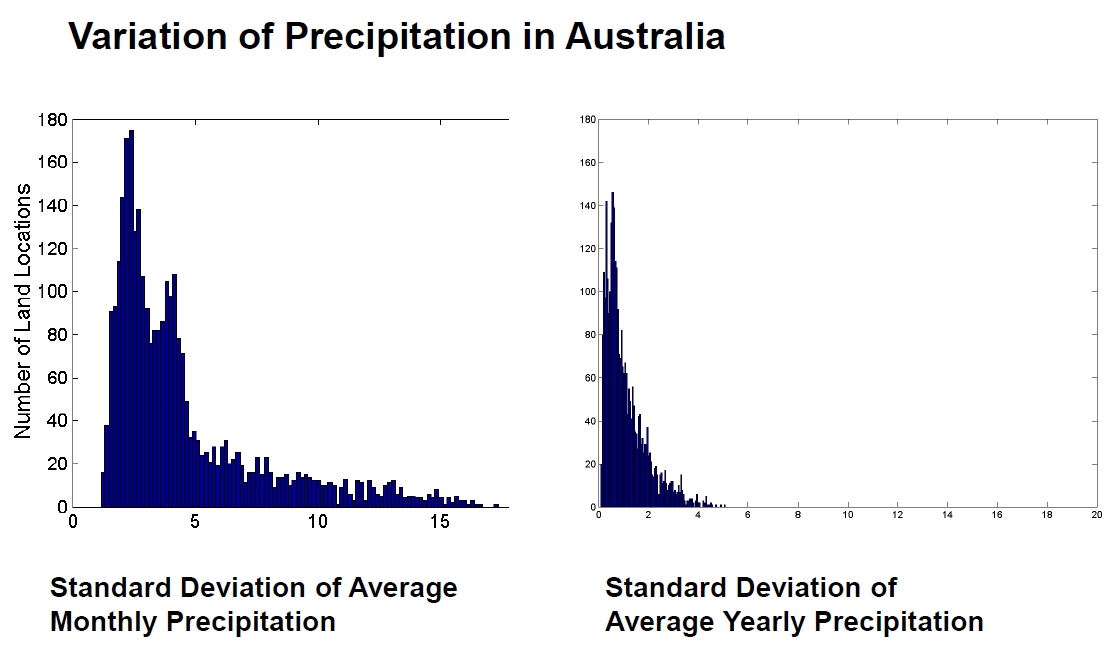
- 이 예는 1982년부터 1993년까지 호주의 강수량을 기반으로 한다. - 연평균 강수량은 평균 월간 강수량보다 변동성이 작습니다. - 모든 강수량 측정값(및 해당 표준 편차)은 센티미터 단위입니다. - 호주의 0.5º x 0.5º 그리드 셀 3,030개에 대한 월평균 강수량의 표준편차에 대한 히스토그램 - 동일한 위치에 대한 평균 연간 강수량의 표준 편차에 대한 히스토그램.
2) 견본 추출(Sampling)
-
샘플링은 데이터 축소에 사용되는 주요 기술
- 데이터의 사전 조사와 최종 데이터 분석 모두에 자주 사용
-
통계학자는 관심 있는 전체 데이터 세트를 얻는 것이 너무 비싸거나 시간이 많이 걸리기 때문에 표본을 추출하는 경우가 많다.
-
샘플링은 일반적으로 관심 있는 전체 데이터 집합을 처리하는 데 너무 비싸거나 시간이 많이 걸리기 때문에 데이터 마이닝에 사용된다.
-
효과적인 샘플링의 핵심 원칙
- 샘플을 사용하는 것은 샘플이 대표적인 경우 전체 데이터 세트를 사용하는 것만큼 잘 작동
- 표본이 원래 데이터 집합과 거의 동일한 속성(관심 있는)을 갖는 경우 표본이 된다.
-
샘플링 크기
- 샘플링 크기가 너무 작으면 정보의 손실이 크다.

- 10개의 동일한 크기의 그룹 각각에서 적어도 하나의 개체를 가져오는 데 필요한 표본 크기.
- 10개의 그룹이 있을 때 가정
- 60개를 추출해야 100% 로 특징을 추출 해낼 수 있다.

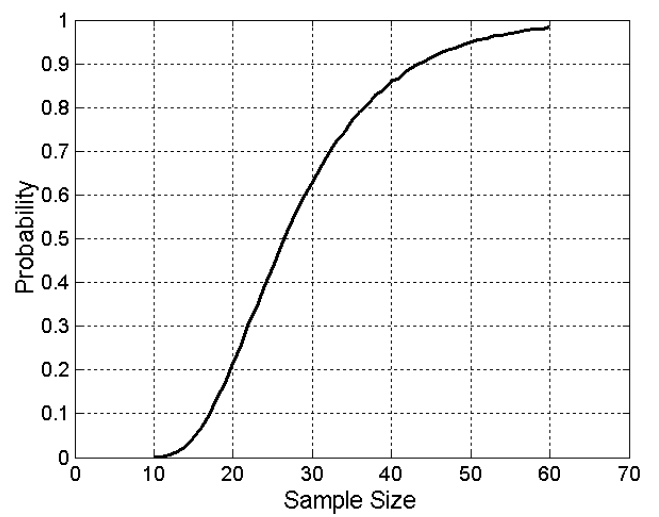
- 샘플링 크기가 너무 작으면 정보의 손실이 크다.
-
샘플링 타입
- 단순 랜덤 샘플링
- 특정 항목을 선택할 확률은 동일
- 교체 없는 샘플링
- 각 항목이 선택될 때마다 모집단에서 제거
- 대체 샘플링
- 개체가 샘플에 대해 선택될 때 개체가 모집단에서 제거되지 않는다.
- 교체 샘플링에서 동일한 개체를 두 번 이상 선택할 수 있다.
- 계층화된(stratified) 샘플링
- 데이터를 여러 파티션으로 분할하고 각 파티션에서 무작위 샘플을 추출
- 단순 랜덤 샘플링
3) 이산화(Discretization)
-
이산화는 연속 속성(analog)을 순서 속성으로 변환하는 프로세스
- 잠재적으로 무한한 수의 값이 소수의 범주에 매핑
- 이산화는 지도(supervised) 설정과 비지도(unsupervised) 설정 모두에서 사용
-
비지도 이산화 (Unsupervised Discretization)
-
예
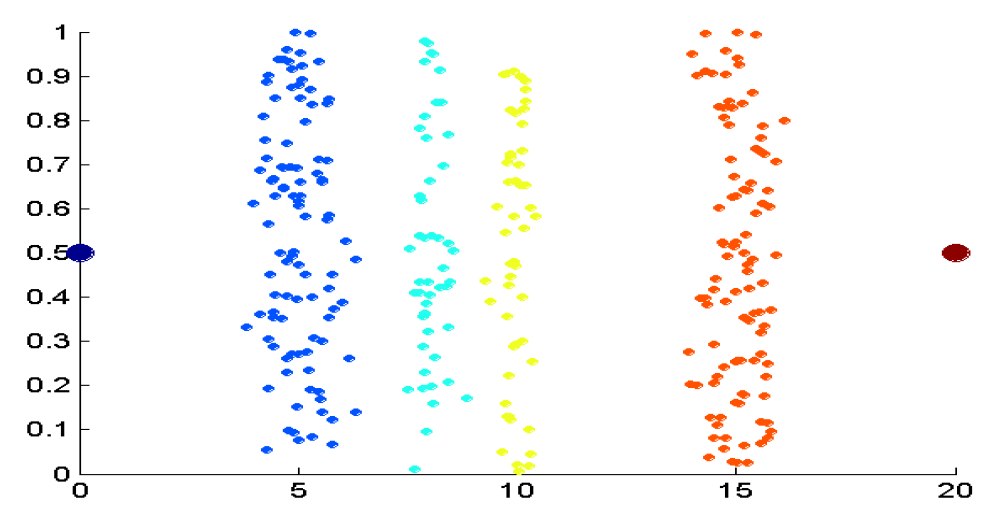
- 데이터는 4개의 포인트 그룹과 2개의 이상값으로 구성
- 데이터는 1차원이지만 중복을 줄이기 위해 임의의 y 구성 요소가 추가됩니다.
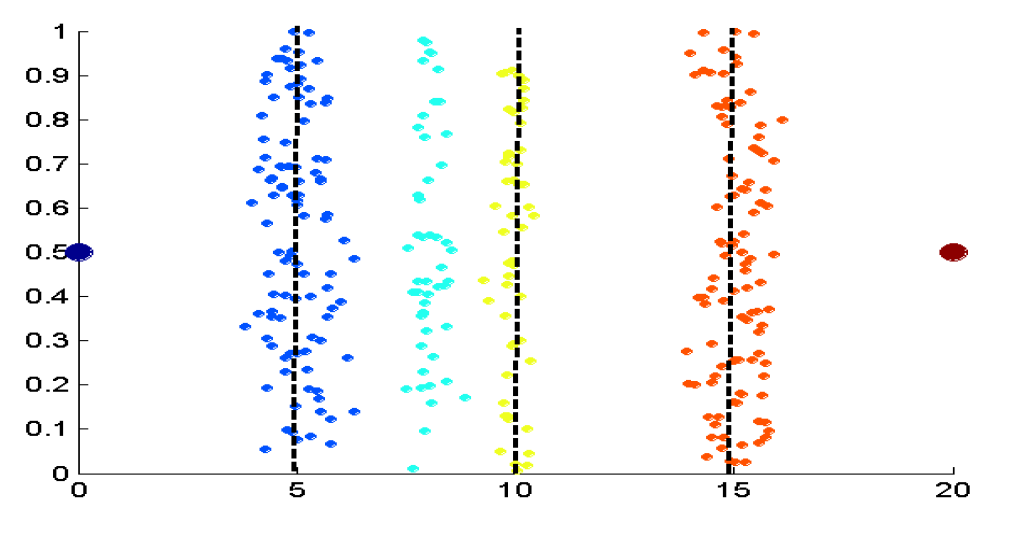
- 4개의 값을 구하는 데 같은 간격으로 확인 (Equal Interval width)
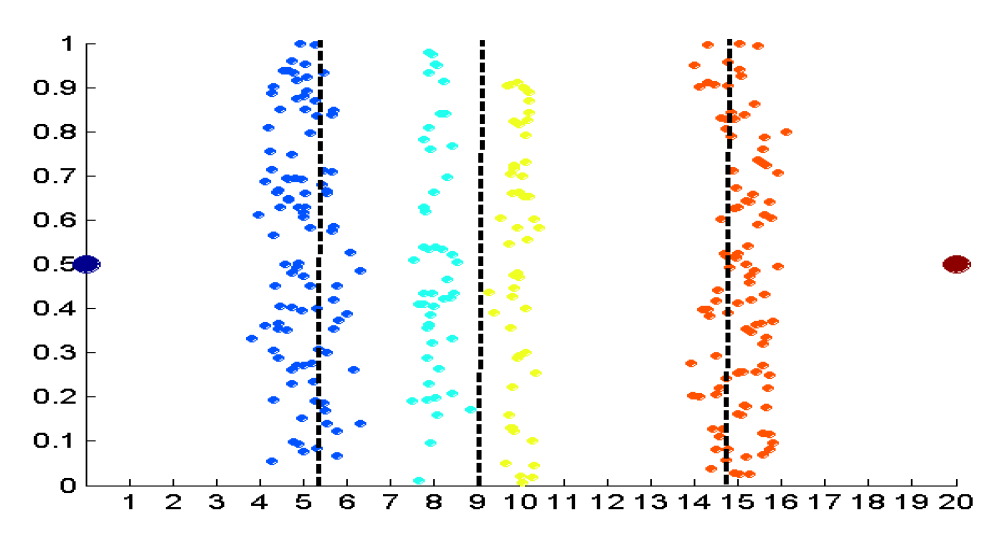
- 4개의 값을 구하는 데 같은 개수로 확인 (Equal Frequency)
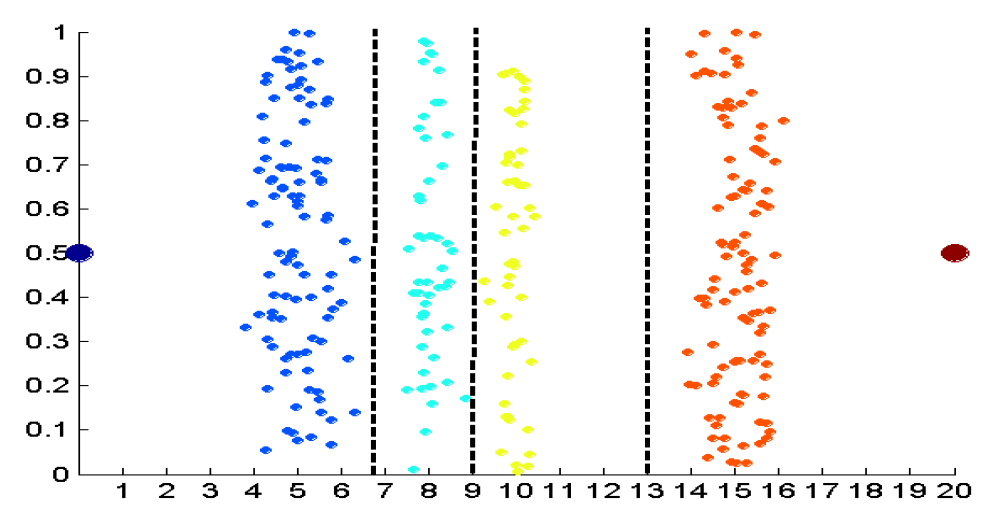
- 4개의 값을 구하는 데 K-means 사용 ← 성능 제일 좋음
-
-
지도 이산화 (Supervised Discretization)
- 많은 분류 알고리즘은 독립 변수와 종속 변수가 소수의 값만 가질 때 가장 잘 작동
- 다음 예를 사용하여 이산화의 유용성을 설명
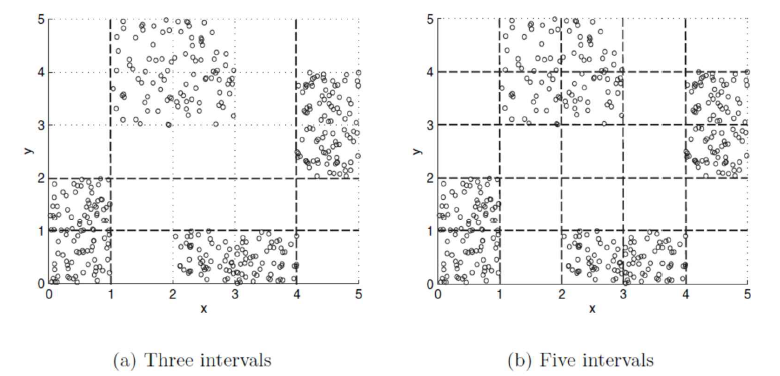
- 4개의 포인트 그룹(클래스)에 대해 x 및 y 속성을 이산화
- 3 간격 보다 5 간격이 카테고리화 성능이 좋지만, 간격이 늘어난다고 꼭 좋아지는 것은 아니다.
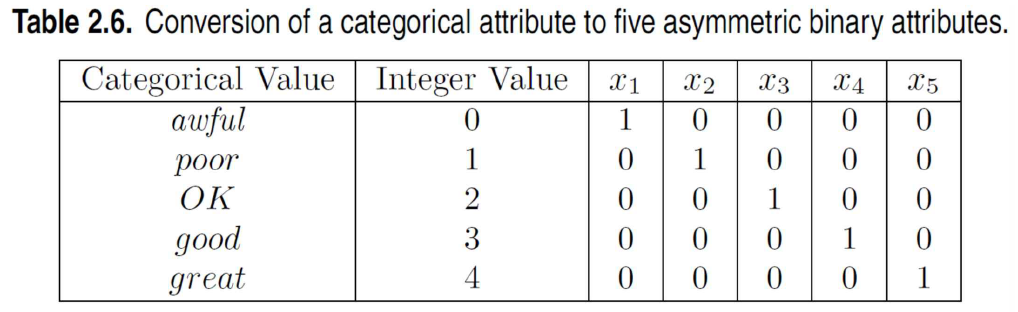
4) 이진화(Binarization)
-
이진화는 연속 또는 범주 속성을 하나 이상의 이진 변수로 매핑
5) 속성 변환(Attribute Transformation)
- 속성 변환은 각 이전 값이 새 값 중 하나로 식별될 수 있도록 지정된 속성의 전체 값 집합을 새롭게 대체하는 값 집합에 매핑하는 기능
- Simple functions
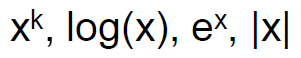
- 정규화
- 발생 빈도, 평균, 분산, 범위 측면에서 속성 간의 차이를 조정하는 다양한 기술을 나타냅니다.
- 원치 않는 공통 신호(예: 계절성) 제거
- 통계에서 표준화란 평균을 빼고 표준편차로 나누는 것을 말한다.
- Simple functions
6) 차원 축소(Dimensionality Reduction)
- 차원 축소
- 목적
- 차원의 저주를 피하기
- 차원의 저주(Curse of Dimensionality)
- 차원이 높아지면 데이터가 차지하는 공간에 점점 더 희박해집니다
- 클러스터링 및 이상값 감지에 중요한, 점 간의 밀도 및 거리 정의는 의미가 없어짐
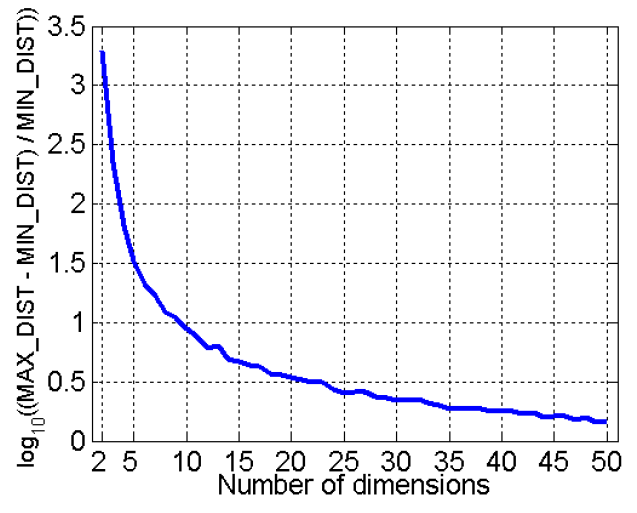
- 무작위로 500 포인트 생성하여 두 점의 최대 거리와 최소 거리의 차이를 계산
- 데이터 마이닝 알고리즘에 필요한 시간 및 메모리 양 감소
- 데이터를 보다 쉽게 시각화 (4차원이 넘어가면 사람이 인식하기 힘듦)
- 관련 없는 기능을 제거하거나 노이즈를 줄이는 데 도움
- 차원의 저주를 피하기
- 기법
- 주성분 분석(PCA)
- 목표는 데이터의 가장 큰 변동을 포착하는 예측을 찾는 것
- 윤곽선 분석이 효율적이다
- 특이값 분해(SVD)
- 기타: 지도 및 비선형 기술
- 주성분 분석(PCA)
- 목적
7) 속성 부분 집합 선택(Feature Subset Selection)
- 데이터의 차원 축소의 다른 방법
- 중복 속성 (Redundant features)
- 하나 이상의 다른 속성에 포함된 정보의 대부분 또는 전체를 복제
- 예: 제품의 구매 가격 및 납부한 판매세 금액
- 관련 없는 속성 (Irrelevant features)
- 현재 데이터 마이닝 작업에 유용한 정보를 포함하지 않음
- 예: 학생의 ID는 종종 학생의 GPA 예측 작업과 관련이 없습니다.
- 특히 분류를 위해 많은 기술이 개발되었다.
8) 속성 생성(Feature Creation)
- 원래 속성보다 훨씬 더 효율적으로 데이터 세트의 중요한 정보를 캡처할 수 있는 새 속성 생성
- 세 가지 일반적인 방법론:
- 특징 추출
- 예: 이미지에서 가장자리 추출
- 기능 구성
- 예: 질량을 부피로 나누어 밀도 구하기
- 새로운 공간에 데이터 매핑
- 예: 푸리에 및 웨이블릿 분석
- 특징 추출
2. 근접도 측정(Proximity)
1) 유사도(Similarity)와 비유사도(Dissimilarity) 측정
- 유사도 측정
- 두 객체 간에 얼마나 유사한 지를 수치적으로 측정한 것
- 객체가 더 비슷할 때 더 수치 값이 높다.
- 범위는 0 ~ 1 (1일 때 유사도가 높다)
- 비유사도 측정
- 두 데이터 객체가 얼마나 다른지를 수치적으로 측정
- 오브젝트들이 유사할 수록 낮은 값
- 보통은 0 ~ 1의 값을 가지지만 종종 0 ~ 무한대의 값을 가지기도 함
- 근접도(Proximity)
- 유사도와 비유사도 모두 지칭하기 위해 사용된다.
- 이러한 척도에는 시계열이나 2차원 점과 같은 밀집데이터에 유용한 상관관계와 유클리드 거리같은 척도, 문서 같은 시소 데이터에 유용한 자카드와 코사인 유사도 척도등을 포함한다.
2) 유사도/비유사도 단순 속성
-
보통 객체는 다중 속성을 가지고 있다.
- 객체간의 근접도를 구할 때 다중속성일 때는 각각의 속성을 결합해서 전체의 근접도를 구한다.

- 순서형(ordinal) 예시
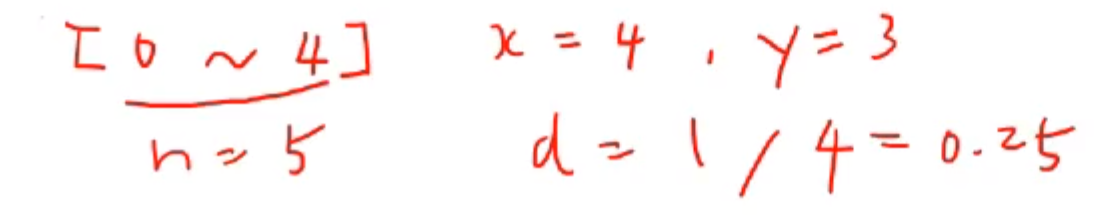
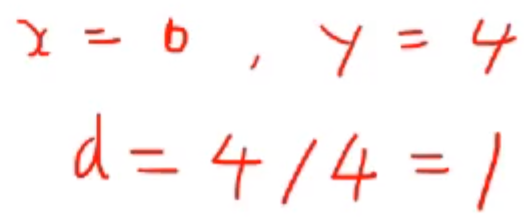
- 간격 또는 비율(interval or ratio) 예시

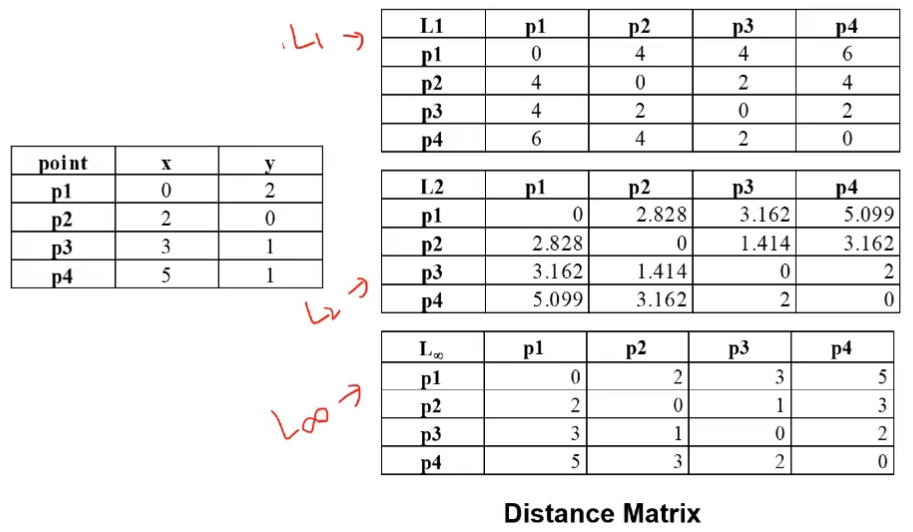
3) 유클리드 거리
-
유클리드 거리
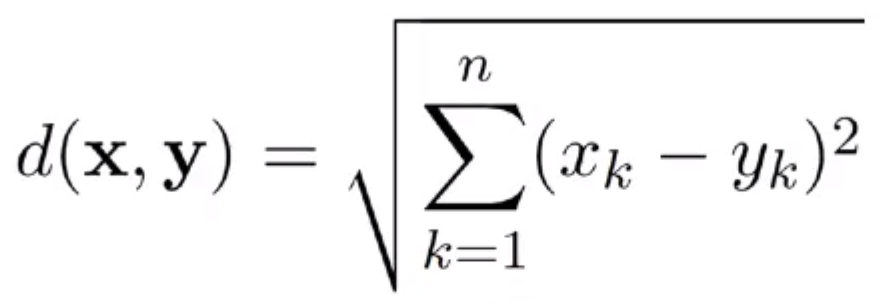
- k 는 차원(attirbute)
-
예시
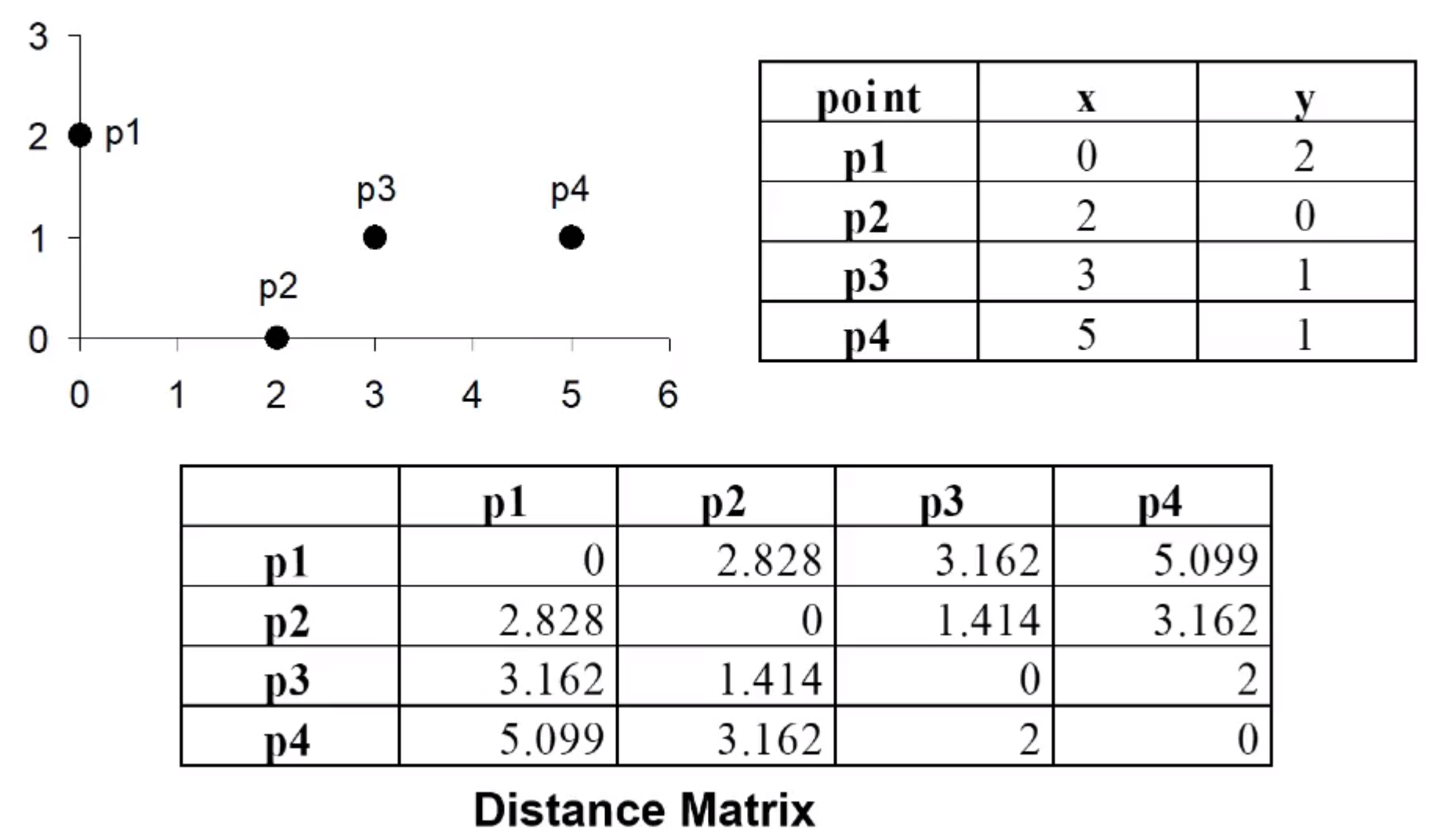
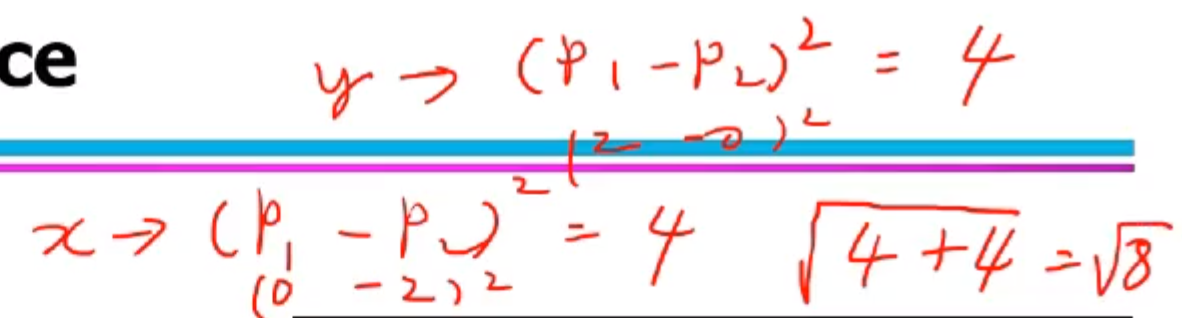
4) 민코스키(Minkowski) 거리
-
유클리디언 디스턴스 일반화
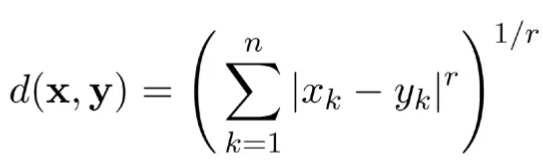
- k는 차원 r은 매개변수
- 예시
-
r = 1인 경우, City block (Manhattan, taxicab, L1 norm) 거리
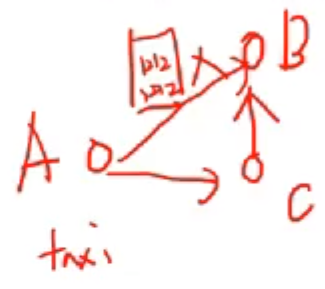
- A 에서 B 지점까지 가는데 택시를 이용할 수 있다.
- A와 B 지역간에 빌딩이 가로막고 있다.
- 이랬을 때 A에서 B로 바로가지 못하고 C를 통해 돌아서 가야할 때
- 이 때를 r = 1 이라고 한다.
-
r = 2 인 경우, 유클리디언 디스턴스
-
r → ∞, 벡터 구성원들 간의 차이 중 최대값이 된다.
-
5) 마할라노비스(Mahalanobis) 거리
-
인도의 통계학자 마할라노비스가 만든 비유사도 측정방법
-
표준편차를 사용해서 척도의 차이, 분산의 차이로 발생하는 왜곡을 피할 수 있는 방법
-
표준편차를 사용하는 통계적 거리와 두 객체 간의 상관성을 고려한 측정방법
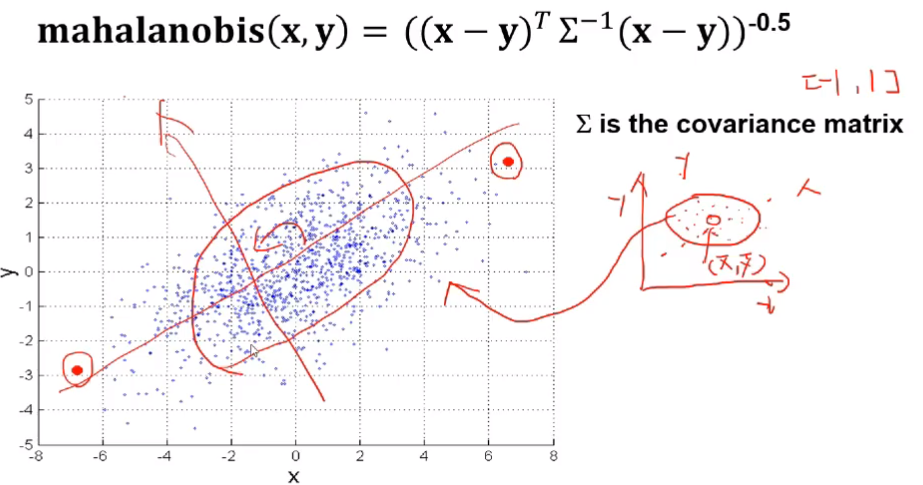
- 두 객체 간의 표준화 거리를 구하면 타원형의 집합을 구할 수 있다.
- 한 점에서 거리가 같은 점들의 집합을 타원형 형태로 구할 수 있다.
- 타원의 중심은 각 변수의 평균값이 위치하는 곳이다.
- 변수 X’, Y’ 의 평균값
- 변수가 2개인 경우 두 객체 간의 표준화 거리가 된다.
- 여기서 두 객체(X, Y)간의 상관관계를 추가한다.
- 기울기에 해당된다.
- 축을 회전하면 구할 수 있다.
- 시그마로 표현되는 것은 공분산 행렬이다.
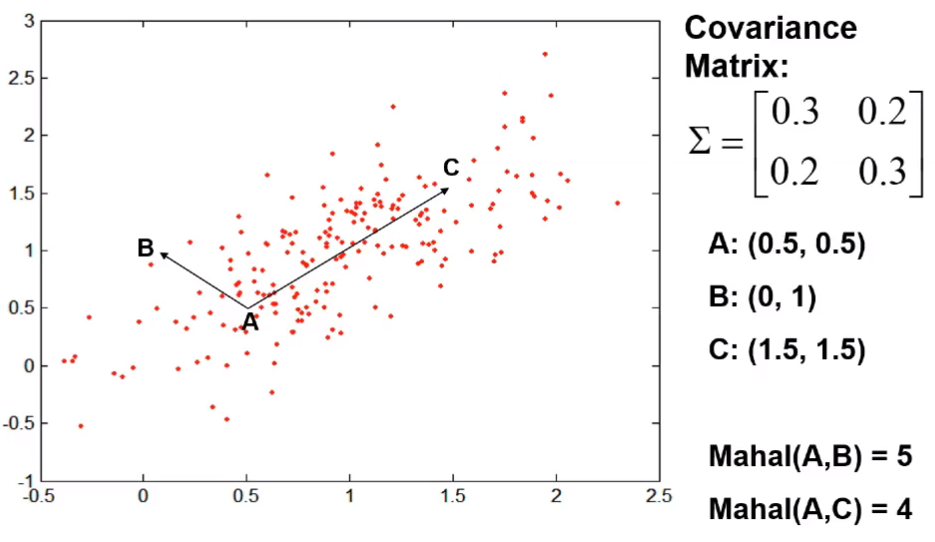
- 타원형을 그린다면, A→C 가 A→B보다 중앙을 가리킨다.
- A→B는 벗어나고 있다.
- 눈으로 보는 거리는 AC가 더 길지만 비 유사도를 측정해보면 AB가 타원형에 벗어나고 있기 때문에 훨씬 거리상으로 먼 유사하지 않은 객체간의 관계가 된다.
6) 일반적인 거리의 특징
-
특징 1
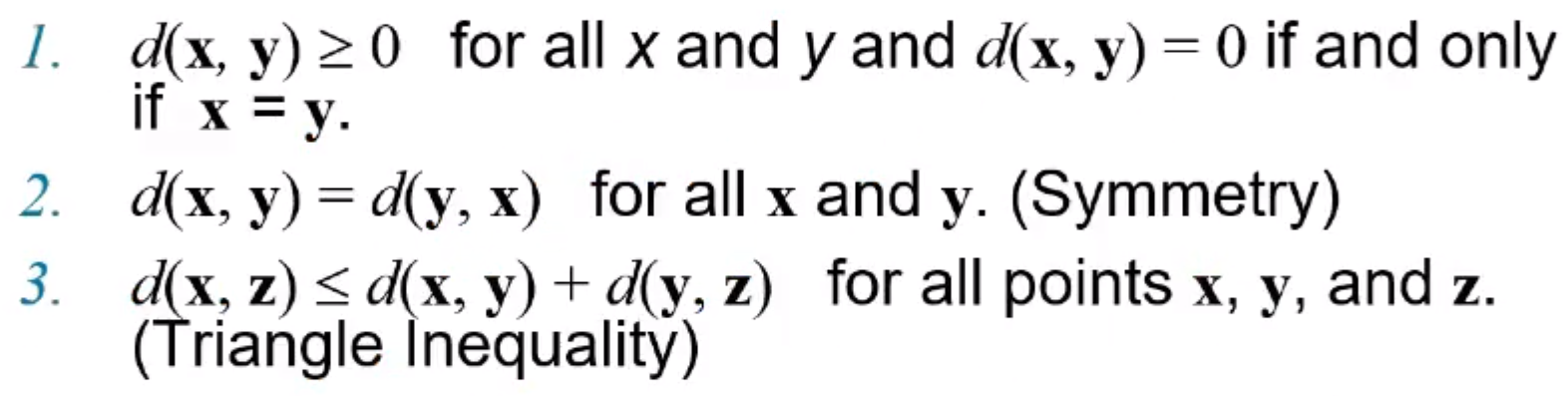
- x, y의 거리는 0보다 크거나 같다.
- 거리는 양수
- x, y의 거리와 y, x의 거리는 같다.
- x, z의 거리는 x, y 거리 + y, z의 거리 보다 작거나 같다.
- x, y의 거리는 0보다 크거나 같다.
-
특징 1을 만족하는 거리를 metric이라고 한다.
7) 일반적인 유사도의 특징
-
x, y가 데이터의 객체라고 했을 때, x, y는 2가지 특징을 가진다.
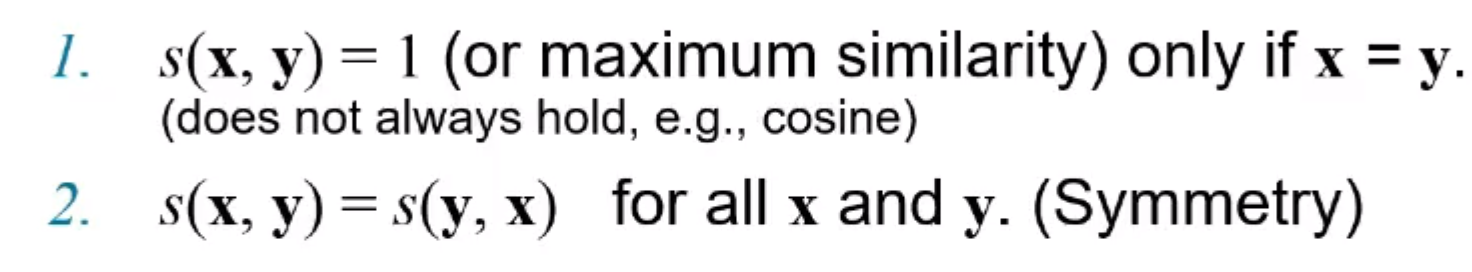
- x와 y의 유사도는 유사도가 가장 높을 때, 1 (x == y) , 코사인이면 다른 값을 가질 수 있다.
- x, y의 유사도는 y, x의 유사도와 같다.
- 거리의 특징과 비슷하지만 삼각부등성을 가지지 않는다.
8) 이진(Binary) 벡터 사이의 유사도
-
x와 y 객체가 binary attribute로만 구성이 되어 있을 때, 벡터들의 유사도를 구할 수 있다.
-
4가지의 attribute가 있다.

-
심플 매칭 계수와 자카드 계수
- SMC
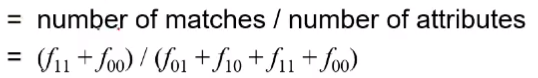
- J
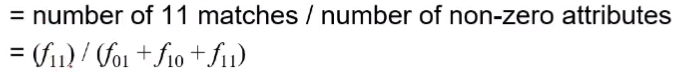
- SMC
9) SMC vs Jaccard
-
예시

- SMC는 유사하지 않지만 f00이 많아서 값이 유사하다고 나온다.
- Jaccard 계수는 같은 값이 없기 때문에 유사도가 0이 나온다.
10) 코사인 유사도
-
보통 두 개의 document 벡터의 유사도를 측정할 때 사용한다.

-
예시

11) 오브젝트가 선형 관계일 때, 상관계수 측정
- 이진 또는 연속형 변수를 가지는 두 데이터 객체간의 상관관계는 객체들의 속성들 간의 선형관계에 대한 척도를 나타낸다.
- 이러한 상관계수에는 여러종류가 있다.
- 피어슨 상관계수
- 이런게 있다. 증명은 하지 않는다.
- 해석만 할 수 있도록 하자.
12) 상관관계 시각화
-
x, y 객체가 있을 때 두 객체 attribute의 관계, 30개 정도의 attribute가 있을 때,
-
상관관계 범위가 -1 ~ 1 까지의 산점도 (변화를 보여줌)
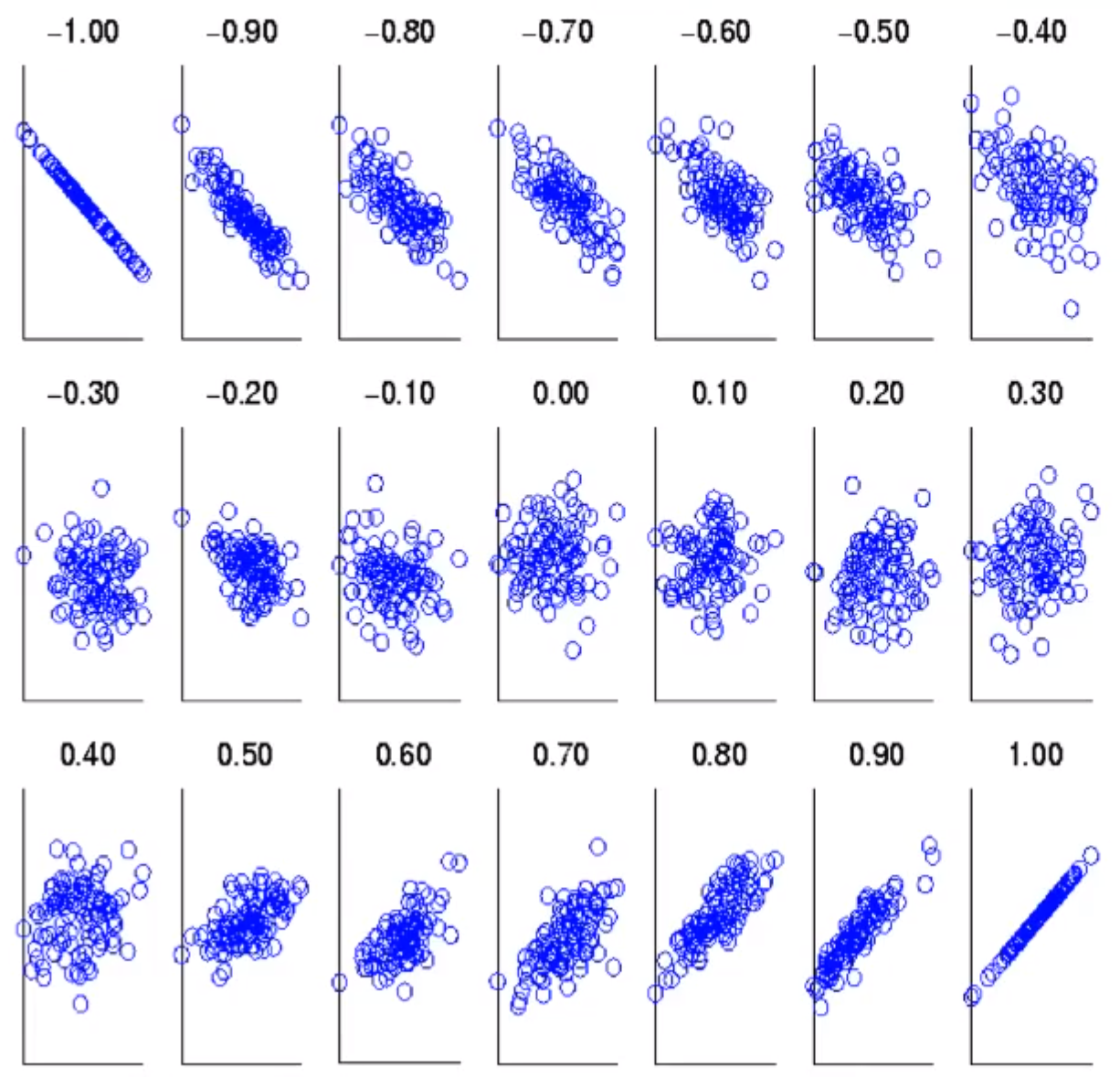
13) 상관관계 vs 코사인 vs 유클리디언 거리
-
설명
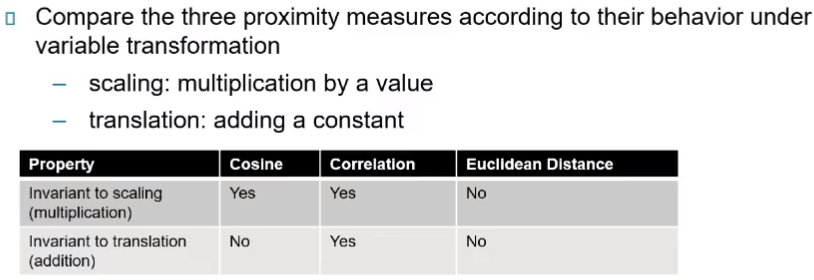
- 스케일링 : 값으로 곱해준다.
- 변형(translation) : 상수를 더해준다.
-
예시
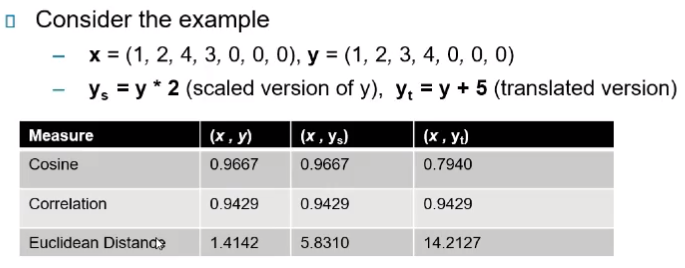
- 코사인의 경우 스케일링을 한 데이터는 값이 같지만, 변형한 값은 달라져서 사용 불가능
- 상관계수의 경우 다 동일해서 다 쓸 수 있다.
- 유클리디언 거리는 다 달라서 쓸 수 없다.
-
올바른 유사성 측정은 도메인에 의존해서 선택이 된다.
- 두 문서의 유사성 측정은 단어의 빈도를 가지고 했다.
- 이것은 두 문서에서 동일한 단어가 많이 있게 되면 두 문서가 비슷하다고 볼 수 있다.
- 두 지역의 섭씨를 측정했을 때, 같거나 비슷한 온도라면 같은 지역이라고 할 수 있다.
- 크기이기 때문에 유클리디언 거리 사용
- 온도가 크기가 아니고 시간에 따른 변화일 때 비교, 4계절이 있고 시간에 따라서 기온이 변한다.
- 이러한 시간 변화에 따른 특성관의 관계는 상관계수 분석을 할 수 있다.
- 두 문서의 유사성 측정은 단어의 빈도를 가지고 했다.
14)근접도 측정의 비교
- 도메인
- 레코드 데이터, 이미지, 그래프, 시퀀스, 3d 단백질 구조, 등 이러한 것들은 측정 값이 다른 값을 갖는 경향이 있다.
- 그래서 속성이라던가 데이터의 타입에 따라서 유사도 측정이 달라지는 경향이 있다.
- 측정은 데이터를 가지고 해야한다.
- 측정은 도메인 지식과 일치하는 그러한 결과를 생성해야한다.
- 도메인과 별개로 측정되는 데이터들은 큰 의미가 없다.
