멀티 스레드 개념
운영체제는 실행 중인 프로그램을 프로세스(Process)로 관리한다. 멀티 태스킹(Multi tasking)은 두 가지 이상의 작업을 동시에 처리하는 것을 말하는데, 이때 운영체제는 멀티 프로세스를 생성해서 처리한다.
하지만 멀티 태스킹이 꼭 멀티 프로세스를 뜻하지는 않는다.
하나의 프로세스가 두 가지 이상의 작업을 처리할 수 있는 이유는 멀티 스레드(Multi thread)가 있기 때문이다.
스레드(Thread)는 코드의 실행 흐름을 말하는데, 프로세스 내에 스레드가 두 개라면 두 개의 코드 실행 흐름이 생긴다는 의미이다.
멀티 프로세스가 프로그램 단위의 멀티 태스킹이라면 멀티 스레드는 프로그램 내부에서의 멀티 태스킹이라고 볼 수 있다.
다음 그림은 멀티 프로세스와 멀티 스레드의 차이점을 보여준다.
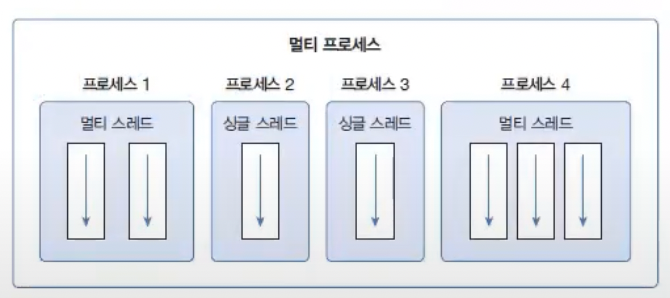
멀티 프로세스들은 서로 독립적이므로 하나의 프로세스에서 오류가 발생해도 다른 프로세스에게 영향을 미치지 않는다.
하지만 멀티 스레드는 프로세스 내부에서 생성되기 때문에 하나의 스레드가 예외를 발생시키면 프로세스가 종료되므로 다른 스레드에게 영향을 미친다.
메인 스레드
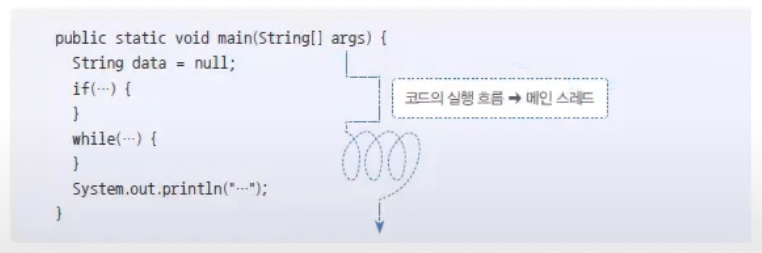
모든 자바 프로그램은 메인 스레드(Main Thread)가 main() 메소드를 실행하면서 시작된다. 메인 스레드는 main() 메소드의 첫 코드부터 순차적으로 실행하고, main() 메소드의 마지막 코드를 실행하거나 return 문을 만나면 실행을 종료한다.
메인 스레드는 필요에 따라 추가 작업 스레드들을 만들어서 실행시킬 수 있다. 다음 그림에서 오른쪽의 멀티 스레드를 보면 메인 스레드가 작업 스레드1을 생성하고 실행시킨 다음, 곧이어 작업 스레드2를 생성하고 실행시키는 것을 볼 수 있다.
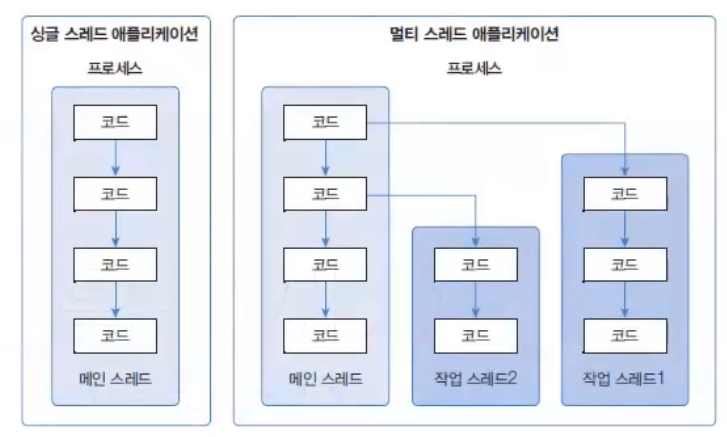
싱글 스레드에서는 메인 스레드가 종료되면 프로세스도 종료된다. 하지만 멀티 스레드에서는 실행 중인 스레드가 하나라도 있다면 프로세스는 종료되지 않는다. 메인 스레드가 작업 스레드보다 먼저 종료되더라도 작업 스레드가 계속 실행중이라면 프로세스는 종료되지 않는다.
작업 스레드 생성과 실행
멀티 스레드로 실행하는 프로그램을 개발하려면 먼저 몇 개의 작업을 병렬로 실행할지 결정하고 각 작업별로 스레드를 생성해야 한다.
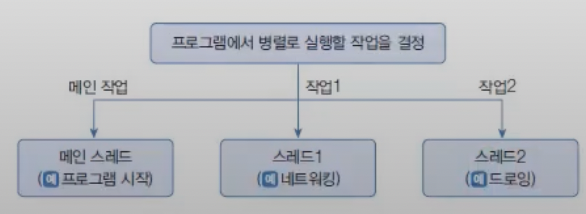
자바 프로그램은 메인 스레드가 반드시 존재하기 때문에 메인 작업 이외에 추가적인 작업 수만큼 스레드를 생성하면 된다. 자바는 작업 스레드도 객체로 관리하므로 클래스가 필요하다. Thread 클래스로 직접 객체를 생성해도 되지만, 하위 클래스를 만들어 생성할 수도 있다.
Thread 클래스로 직접 생성
java.lang 패키지에 있는 Thread 클래스로부터 작업 스레드 객체를 직접 생성하려면 다음과 같이 Runnable 구현 객체를 매개값으로 갖는 생성자를 호출하면 된다.
Thread thread = new Thread(Runnable target);Runnable은 스레드가 작업을 실행할 때 사용하는 인터페이스이다. Runnable에는 run() 메소드가 정의되어 있는데, 구현 클래스는 run()을 재정의해서 스레드가 실행할 코드를 가지고 있어야 한다.
다음은 Runnable 구현 클래스를 작성하는 방법이다.
class Task implements Runnable {
@Override
public void run() {
// 스레드가 실행할 코드
}
}Runnable 구현 클래스는 작업 내용을 정의한 것이므로, 스레드에게 전달해야 한다.
Runnable 구현 객체를 생성한 후 Thread 생성자 매개값으로 Runnable 객체를 다음과 같이 전달하면 된다.
Runnable task = new Task();
Thread thread = new Thread(task);명시적인 Runnable 구현 클래스를 작성하지 않고 Thread 생성자를 호출할 때 Runnable 익명 구현 객체를 매개값으로 사용할 수 있다.
오하려 이 방법이 더 많이 사용된다.
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 스레드가 실행할 코드
}
});작업 스레드 객체가 생성되었다고 해서 바로 작업 스레드가 실행되지는 않는다. 작업 스레드를 실행하려면 스레드 객체의 start() 메소드를 다음과 같이 호출해야 한다.
thread.start();start() 메소드가 호출되면, 작업 스레드는 매개값으로 받은 Runnable의 run() 메소드를 실행하면서 작업을 처리한다.
다음은 작업 스레드가 생성되고 실행되기까지의 순서를 보여준다.
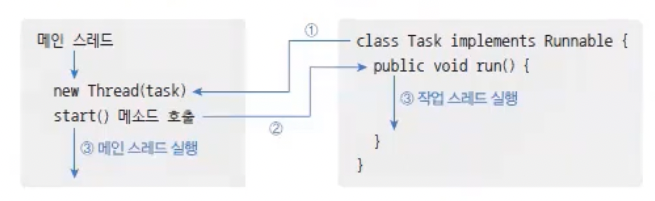
Thread 자식 클래스로 생성
작업 스레드 객체를 생성하는 또 다른 방법은 Thread의 자식 객체를 만드는 것이다. Thread 클래스를 장속한 다음 run() 메소드를 재정의해서 스레드가 실행할 코드를 작성하고 객체를 생성하면 된다.
public class WorkerThread extends Thread {
@Override
public void run() {
// 스레드가 실행할 코드
}
}
Thread thread = new WorkerThread();작업 스레드를 실행하는 방법은 동일하다. start() 메소드를 호출하면 작업 스레드는 재정의된 run()을 실행시킨다.
thread.start();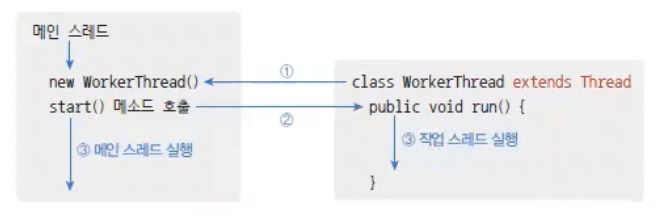
명시적인 자식 클래스를 정의하지 않고, 다음과 같이 Thread 익명 객체를 사용할 수도 있다.
오히려 이 방법이 더 많이 사용된다.
Thread thread = new Thread() {
@Override
public void run() {
// 스레드가 실행할 코드
}
};스레드 이름
스레드는 자신의 이름을 가지고 있다. 메인 스레드는
main이라는 이름을 가지고 있고, 작업 스레드는 자동적으로Thread-n이라는 이름을 가진다.
작업 스레드의 이름을 Thread-n 대신 다른 이름으로 설정하고 싶다면 Thread 클래스의 setName() 메소드를 사용하면 된다.
thread.setName("스레드 이름");스레드 이름은 디버깅할 때 어떤 스레드가 작업을 하는지 조사할 목적으로 주로 사용된다.
현재 코드를 어떤 스레드가 실행하고 있는지 확인하려면 정적 메소드는 currentThread()로 스레드 객체의 참조를 얻은 다음 getName() 메소드로 이름을 출력해보면 된다.
Thread thread = Thread.currentThread();
System.out.println(thread.getName());스레드 상태
스레드는 생성(NEW), 실행 대기(RUNNABLE), 실행(RUNNING), 종료(TERMINATED) 상태를 가진다.
스레드 객체를 생성(NEW)하고, start() 메소드를 호출하면 곧바로 스레드가 실행되는 것이 아니라 실행 대기 상태(RUNNABLE)가 된다. 실행 대기 상태란 실행을 기다리고 있는 상태를 말한다. 실행 대기하는 스레드는 CPU 스케줄링에 따라 CPU를 점유하고 run() 메소드를 실행한다. 이때를 실행(RUNNING) 상태라고 한다. 실행 스레드는 run() 메소드를 모두 실행하기 전에 스케줄링에 의해 다시 실행 대기 상태로 돌아갈 수 있다. 그리고 다른 스레드가 실행 상태가 된다.
이렇게 스레드는 실행 대기 상태와 실행 상태를 번갈아 가면서 자신의 run() 메소드를 조금씩 실행한다.
실행 상태에서 run() 메소드가 종료되면 더 이상 실행할 코드가 없기 때문에 스레드의 실행은 멈추게 된다.
이 상태를 종료 상태(TERMINATED)라고 한다.
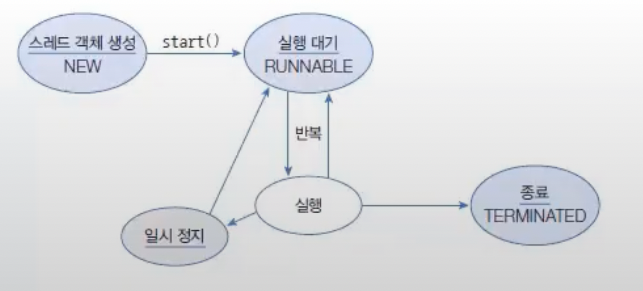
실행 상태에서 일시 정지 상태로 가기도 하는데, 일시 정지 상태는 스레드가 실행할 수 없는 상태를 말한다.
스레드가 다시 실행 상태로 가기 위해서는 일시 정지 상태에서 실행 대기 상태로 가야만 한다.
다음은 일시 정지로 가기 위한 메소드와 벗어나기 위한 메소드들을 보여준다.
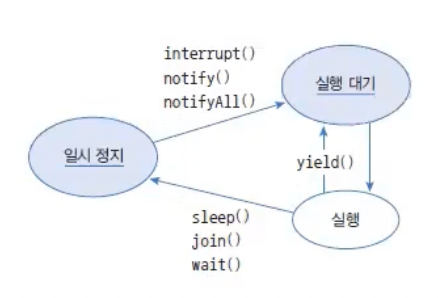
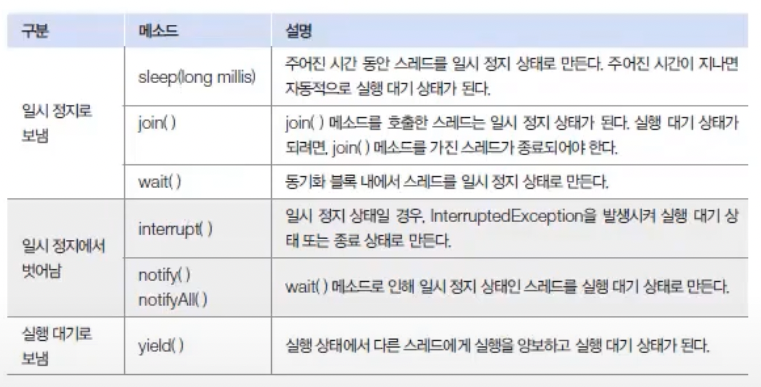
위 표에서 wait()과 notify(), notifyAll()은 Object 클래스의 메소드이고 그 외는 Thread 클래스의 메소드이다.
주어진 시간 동안 일시 정지
실행 중인 스레드를 일정 시간 멈추게 하고 싶다면 Thread 클래스의 정적 메소드인 sleep()을 이용하면 된다.
매개값에는 얼마 동안 일시 정지 상태로 있을 것인지 밀리세컨드(1/1000) 단위로 시간을 주면 된다.
다음 코드는 1초 동안 일시 정지 상태를 만든다.
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// interrupt() 메소드가 호출되면 실행
}다른 스레드의 종료를 기다림
스레드는 다른 스레드와 독립적으로 실행하지만 다른 스레드가 종료될 때까지 기다렸다가 실행을 해야 하는 경우도 있다.
예를 들어 계산 스레드의 작업이 종료된 후 그 결과값을 받아 처리하는 경우이다.
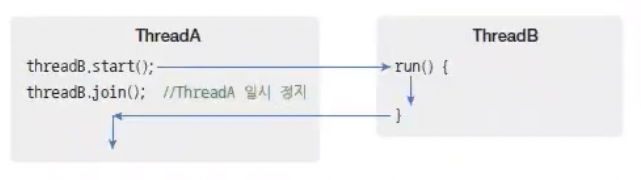
이를 위해 스레드는 join() 메소드를 제공한다.
다음 그림에서 ThreadA가 ThreadB의 join() 메소드를 호출하면 ThreadA는 ThreadB가 종료할 때까지 일시 정지 상태가 된다.
ThreadB의 run() 메소드가 종료되고 나서야 비로소 ThreadA는 일시 정지에서 풀려 다음 코드를 실행한다.
다른 스레드에게 실행 양보
스레드가 처리하는 작업은 반복적인 실행을 위해 for 문이나 while 문을 포함하는 경우가 많은데, 가끔 반복문이 무의미한 반복을 하는 경우가 있다.
다음 코드를 보자. work의 값이 false라면 while 문은 어떠한 실행문도 실행하지 않고 무의미한 반복을 한다.
public void run() {
while (true) {
if (work) {
System.out.println("ThreadA 작업 내용");
}
}
}이때는 다른 스레드에게 실행을 양보하고 자신은 실행 대기 상태로 가는 것이 프로그램 성능에 도움이 된다.
이런 기능을 위해 Thread는 yield() 메소드를 제공한다.
yield()를 호출한 스레드는 실행 대기 상태로 돌아가고, 다른 스레드가 실행 상태가 된다.
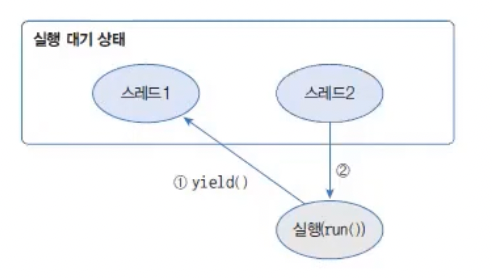
다음은 무의미한 반복을 하지 않고 다른 스레드에게 실행을 양보하도록 이전 코드를 수정한 것이다.
public void run() {
while (true) {
if (work) {
System.out.println("ThreadA 작업 내용");
} else {
Thread.yield();
}
}
}스레드 동기화
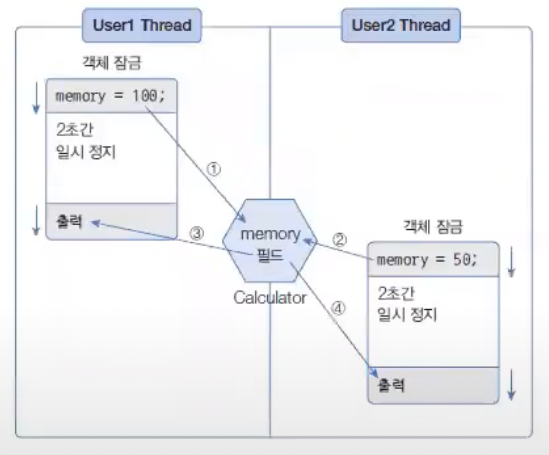
멀티 스레드는 하나의 객체를 공유해서 작업할 수도 있다. 이 경우, 다른 스레드에 의해 객체 내부 데이터가 쉽게 변경될 수 있기 때문에 의도했던 것과는 다른 결과가 나올 수 있다. 다음 그림을 보자.
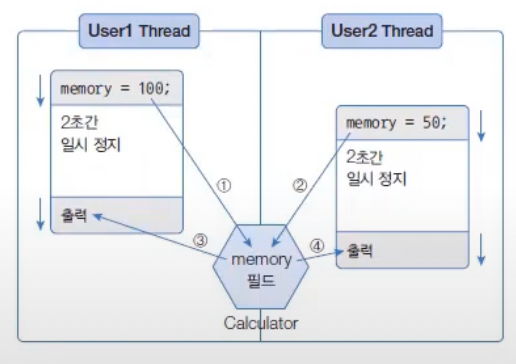
User1Thread는 Calculator 객체의 memory 필드에 100을 먼저 저장하고 2초간 일시 정지 상태가 된다.
그동안 User2Thread가 memory 필드값을 50으로 변경한다. 2초가 지나 User1Thread가 다시 실행 상태가 되어 memory 필드의 값을 출력하면 User2Thread가 저장한 50이 나온다.
그런데 이렇게 하면 User1Thread에 저장된 데이터가 날아가버린다. 스레드가 사용 중인 객체를 다른 스레드가 변경할 수 없도록 하려면 스레드 작업이 끝날 때까지 객체에 잠금을 걸면 된다. 이를 위해 자바는 동기화(Synchronized) 메소드와 블록을 제공한다.
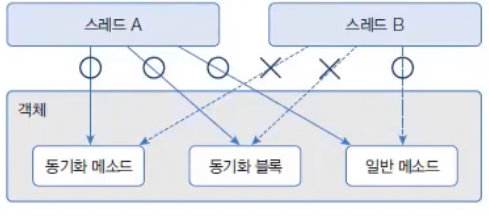
객체 내부에 동기화 메소드와 동기화 블록이 여러 개가 있다면 스레드가 이들 중 하나를 실행할 때 다른 스레드는 해당 메소드는 물론이고 다른 동기화 메소드 및 블록도 실행할 수 없다. 하지만 일반 메소드는 실행이 가능하다.
동기화 메소드 및 블록 선언
동기화 메소드를 선언하는 방법은 다음과 같이 synchronized 키워드를 붙이면 된다.
synchronized 키워드는 인스턴스와 정적 메소드 어디든 붙일 수 있다.
public synchronized void method() {
// 단 하나의 스레드만 실행하는 영역
}스레드가 동기화 메소드를 실행하는 즉시 객체는 잠금이 일어나고, 메소드 실행이 끝나면 잠금이 풀린다.
메소드 전체가 아닌 일부 영역을 실행할 때만 객체 잠금을 걸고 싶다면 다음과 같이 동기화 블록을 만들면 된다.
public void method() {
// 여러 스레드가 실행할 수 있는 영역
synchronized(공유객체) {
// 단 하나의 스레드만 실행하는 영역
}
// 여러 스레드가 실행할 수 있는 영역
}예제를 보자
package ch14.sec06.exam01;
public class Calculator {
private int memory;
public int getMemory() {
return memory;
}
public synchronized void setMemory1(int memory) {
this.memory = memory;
try {
Thread.sleep(2000);
} catch(InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
}
public void setMemory2(int memory) {
synchronized(this) {
this.memory = memory;
try {
Thread.sleep(2000);
} catch(InterruptedException e) {}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
}
}
}package ch14.sec06.exam01;
public class User1Thread extends Thread {
private Calculator calculator;
public User1Thread() {
setName("User1Thread");
}
public void setCalculator(Calculator calculator) {
this.calculator = calculator;
}
@Override
public void run() {
calculator.setMemory1(100);
}
}package ch14.sec06.exam01;
public class User2Thread extends Thread {
private Calculator calculator;
public User2Thread() {
setName("User2Thread");
}
public void setCalculator(Calculator calculator) {
this.calculator = calculator;
}
@Override
public void run() {
calculator.setMemory2(50);
}
}package ch14.sec06.exam01;
public class SynchronizedExample {
public static void main(String[] args) {
Calculator calculator = new Calculator();
User1Thread user1Thread = new User1Thread();
user1Thread.setCalculator(calculator);
user1Thread.start();
User2Thread user2Thread = new User2Thread();
user2Thread.setCalculator(calculator);
user2Thread.start();
}
}User1Thread: 100
User2Thread: 50위 예제는 Calculator를 생성해서 User1Thread와 User2Thread에서 사용하도록 setCalculator() 메소드를 호출하고, 두 스레드를 시작시킨다.
정확히 User1Thread가 저장된 값 100이 출력되었고, User2Thread가 저장한 값 50이 출력되었다.
다음 그림을 보면 왜 이런 값이 나왔는지 이해할 수 있다.
wait()과 notify()를 이용한 스레드 제어
경우에 따라서는 두 개의 스레드를 교대로 번갈아 가며 실행할 때도 있다. 정확한 교대 작업이 필요할 경우, 자신의 작업이 끝나면 상대방 스레드를 일시 정지 상태에서 푸렁주고 자신은 일시 정지 상태로 만들면 된다.
이 방법의 핵심은 공유 객체에 있다. 공유 객체는 두 스레드가 작업할 내용을 각각 동기화 메소드로 정해 놓는다.
한 스레드가 작업을 완료하면 notify() 메소드를 호출해서 일시 정지 상태에 있는 다른 스레드를 실행 대기 상태로 만들고, 자신은 두 번 작업을 하지 않도록 wait() 메소드를 호출하여 일시 정지 상태로 만든다.
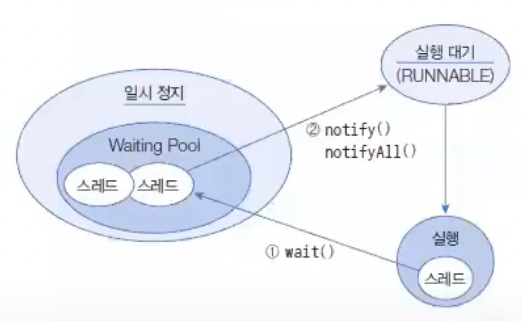
notify()는 wait()에 의해 일시 정지된 스레드 중 한 개를 실행 대기 상태로 만들고, notifyAll()은 wait()에 의해 일시 정지된 모든 스레드를 실행 대기 상태로 만든다.
주의할 점은 이 두 메소드는 동기화 메소드 또는 동기화 블록 내에서만 사용할 수 있다는 것이다.
스레드 안전 종료
스레드는 자신의 run() 메소드가 모두 실행되면 자동적으로 종료되지만, 경우에 따라서는 실행 중인 스레드를 즉시 종료할 필요가 있다. 스레드를 안전하게 종료하는 방법은 사용하던 리소스들을 정리하고 run() 메소드를 빨리 종료하는 것이다. 주로 조건 이용 방법과 interrupt() 메소드 이용 방법을 사용한다.
조건 이용
스레드가 while 문으로 반복 실행할 경우, 조건을 이용해서 run() 메소드의 종료를 유도할 수 있다.
public class XXXThread extends Thread {
private boolean stop;
public void run() {
while (!stop) {
// 스레드가 반복 실행하는 코드;
}
// 스레드가 사용한 리소스 정리
}
}interrupt() 메소드 이용
interrupt() 메소드는 스레드가 일시 정지 상태에 있을 때 InterruptedException 예외를 발생시키는 역할을 한다.
이것을 이용하면 예외 처리를 통해 run() 메소드를 정상 종료시킬 수 있다.
다음 그림을 보자.

XThread를 생성해서 start() 메소드를 실행한 후에 XThread의 interrupt() 메소드를 실행하면 XThread가 일시 정지 상태가 될 때 InterruptedException이 발생하여 예외 처리 블록으로 이동한다.
이것인 결국 while 문을 빠져나와 자원을 정리하고 스레드가 종료되는 효과를 가져온다.
데몬 스레드
데몬(Daemon) 스레드는 주 스레드의 작업을 돕는 보조적인 역할을 수행하는 스레드이다. 주 스레드가 종료되면 데몬 스레드도 따라서 자동으로 종료된다.
워드 프로세서의 자동 저장, 자바의 가바지 컬렉터 등이 데몬 스레드의 예시이다.
스레드를 데몬으로 만들기 위해서는 주 스레드가 데몬이 될 스레드의 setDaemon(true)를 호출하면 된다.
public static void main(String[] args) {
AutoSaveThread thread = new AutoSaveThread();
thread.setDaemon(true);
thread.start();
}스레드풀
병렬 작업 처리가 많아지면 스레드의 개수가 폭증하여 CPU 및 메모리 사용량이 늘어난다.
이에 따라 애플리케이션의 성능 또한 급격히 저하된다. 이렇게 병렬 작업 증가로 인한 스레드의 폭증을 막으려면 스레드풀(ThreadPool)을 사용하는 것이 좋다.
스레드풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고 작업 큐(Queue)에 들어오는 작업들을 스레드가 하나씩 맡아 처리하는 방식이다.
작업 처리가 끝난 스레드는 다시 작업 큐에서 새로운 작업을 가져와 처리한다.
이렇게 하면 작업량이 증가해도 스레드의 개수가 늘어나지 않아 애플리케이션의 성능이 급격히 저하되지 않는다.
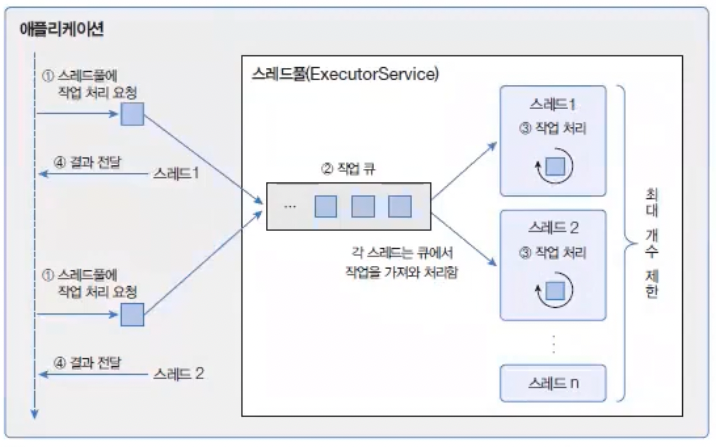
스레드풀 생성
자바는 스레드풀을 생성하고 사용할 수 있도록 java.util.concurrent 패키지에서 ExecutorService 인터페이스와 Executors 클래스를 제공하고 있다.
Executors의 다음 두 정적 메소드를 이용하면 간단하게 스레드풀인 ExecutorService 구현 객체를 만들 수 있다.
| 메소드명(매개변수) | 초기 수 | 코어 수 | 최대 수 |
|---|---|---|---|
| newCachedThreadPool() | 0 | 0 | Integer.MAX_VALUE |
| newFixedThreadPool(int nThreads) | 0 | 생성된 수 | nThreads |
초기 수는 스레드풀이 생성될 때 기본적으로 생성되는 스레드 수를 말하고, 코어 수는 스레드가 증가된 후 사용되지 않는 스레드를 제거할 때 최소한 풀에서 유지하는 스레드 수를 말한다.
그리고 최대 수는 증가되는 스레드의 한도 수이다.
다음과 같이 newCachedThreadPool() 메소드로 생성된 스레드풀의 초기 수와 코어 수는 0개이고, 작업 개수가 많아지면 새 스레드를 생성시켜 작업을 처리한다.
60초 동안 스레드가 아무 작업을 하지 않으면 스레드를 풀에서 제거한다.
ExecutorService executorService = Executors.newCachedThreadPool();다음과 같이 newFixedThreadPool()로 생성된 스레드풀의 초기 수는 0개이고, 작업 개수가 많아지면 최대 5개까지 스레드를 생성시켜 작업을 처리한다.
이 스레드풀의 특징은 생성된 스레드를 제거하지 않는다는 것이다.
ExecutorService executorService = Executors.newFixedThreadPool();위 두 메소드를 사용하지 않고 직접 ThreadPoolExecutor로 스레드풀을 생성할 수도 있다.
다음에서는 초기 수 0개, 코어 수 3개, 최대 수 100개인 스레드풀을 생성하는 코드이다.
그리고 추가도니 스레드가 120초 동안 놀고 있을 경우 해당 스레드를 풀에서 제거한다.
ExecutorService threadPool = new ThreadPoolExecutor {
3, // 코어 스레드 개수
100, // 최대 스레드 개수
120L, // 놀고 있는 시간
TimeUnit.SeCONDS, // 놀고 있는 시간 단위
new SynchronousQueue<Runnable>() // 작업 큐
}스레드풀 종료
스레드풀의 스레드는 기본적으로 데몬 스레드가 아니기 때문에 main 스레드가 종료되더라도 작업을 처리하기 위해 계속 실행 상태로 남아 있다.
스레드풀의 모든 스레드를 종료하려면 ExecutorService의 다음 두 메소드 중 하나를 실행해야 한다.
| 리턴 타입 | 메소드명(매개변수) | 설명 |
|---|---|---|
| void | shutdown() | 현재 처리 중인 작업뿐만 아니라 작업 큐에 대기하고 있는 모든 작업을 처리한 뒤에 스레드풀을 종료시킨다. |
| List<Runnable> | shutdownNow() | 현재 작업 처리중인 스레드를 interrupt해서 작업을 중지시키고 스레드풀을 종료시킨다. 리턴값은 작업 큐에 있는 미처리된 작업(Runnable)의 목록이다. |
작업 생성과 처리 요청
하나의 작업은 Runnable 또는 Callable 구현 클래스로 표현한다. Runnable과 Callable의 차이점은 작업 처리 완료 후 리턴값이 있느냐 없느냐이다.
다음은 Runnable과 Callable 구현 클래스를 작성하는 방법을 보여준다.
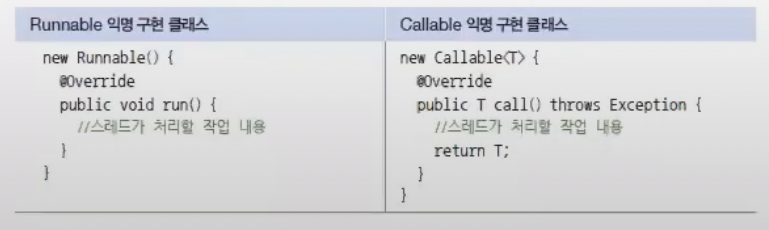
Runnable의 run() 메소드는 리턴값이 없고, Callable의 call() 메소드는 리턴값이 없다.
call()의 리턴값은 Callable<T>에서 지정한 T 타입 파라미터와 동일한 타입이어야 한다.
작업 처리 요청이란 ExecutorService의 작업 큐에 Runnable 또는 Callable 객체를 넣는 행위를 말한다.
작업 처리 요청을 위해 ExecutorService는 당므 두 가지 메소드를 제공한다.
| 리턴 타입 | 메소드명(매개변수) | 설명 |
|---|---|---|
| void | execute(Runnable command) | - Runnable을 작업 큐에 저장 - 작업 처리 결과를 리턴하지 않음 |
| Future<T> | submit(Callable<T> task) | - Callable을 작업 큐에 저장 - 작업 처리 결과를 얻을 수 있도록 Future를 리턴 |
Runnable 또는 Callable 객체가 ExecutorService의 작업 큐에 들어가면 ExecutorService는 처리할 스레드가 있는지 보고, 없다면 스레드를 새로 생성시킨다.
스레드는 작업 큐에서 Runnable 또는 Callable 객체를 꺼내와 run() 또는 call() 메소드를 실행하면서 작업을 처리한다.
