분석함수란?
테이블의 데이터를 특정 컬럼을 기준으로 행들을 그룹화하여 결과를 조회하는 함수이다. 분석함수에는 순위함수(RANK, DENSE_RANK, ROW_NUMBER)와 집계함수(SUM, MIN, MAX, AVG, COUNT)가 있다.
순위함수
SELECT 순위함수() OVER (PARTITION BY 컬럼명 ORDER BY 컬럼명 정렬옵션) AS 컬럼1,
컬럼2,
컬럼3,
. . .
FROM 테이블명
-- PARTITION BY절은 생략 가능하다.ORDER BY절에 기준이되는 컬럼과 정렬옵션을 지정하고 PARTITION BY절에 그룹화할 컬럼을 지정한다. PARTITION BY절은 생략이 가능한데, 이러한 경우 테이블 전체를 대상으로 순위를 조회한다.
-- 급여를 기준으로 직원들을 정렬했을 때 급여 순위가 1~3위에 해당하는 직원 3명 조회
SELECT RANK, FIRST_NAME, SALARY
FROM (SELECT RANK() OVER (ORDER BY SALARY DESC) AS RANK, FIRST_NAME, SALARY
FROM EMPLOYEES)
WHERE RANK >=1 AND RANK <=3;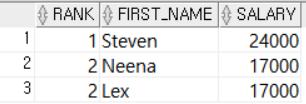
RANK()함수는 동점자를 같은 순위로 간주한다. 그래서 SALARY가 17000인 직원 두명을 2위로 출력했다.
-- 직원들의 부서별 급여 순위 조회
SELECT DENSE_RANK() OVER (PARTITION BY E.DEPARTMENT_ID ORDER BY E.SALARY DESC) AS DENSE_RANK,
E.FIRST_NAME,
D.DEPARTMENT_NAME,
E.SALARY
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID;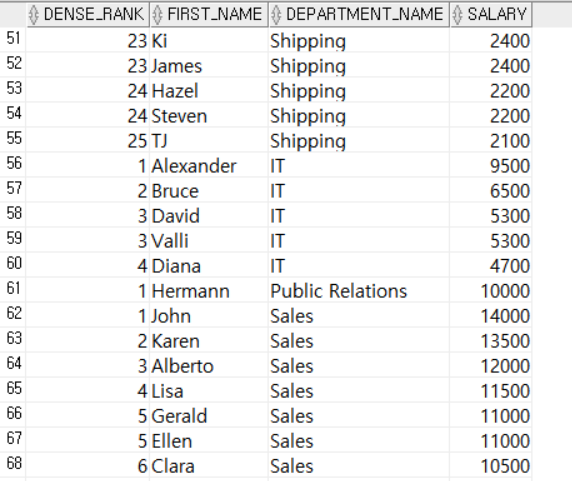
먼저 DEPARTMENT_ID별로 행을 그룹화한 후, SALARY에 따라 내림차순으로 순위를 부여했다. RANK()와 마찬가지로 동점자는 같은 순위로 간주한다.
-- 직원들의 직군별 급여 순위 조회
SELECT ROW_NUMBER() OVER (PARTITION BY E.JOB_ID ORDER BY E.SALARY DESC) AS ROWNUMBER,
E.FIRST_NAME,
J.JOB_TITLE,
E.SALARY
FROM EMPLOYEES E, JOBS J
WHERE E.JOB_ID = J.JOB_ID;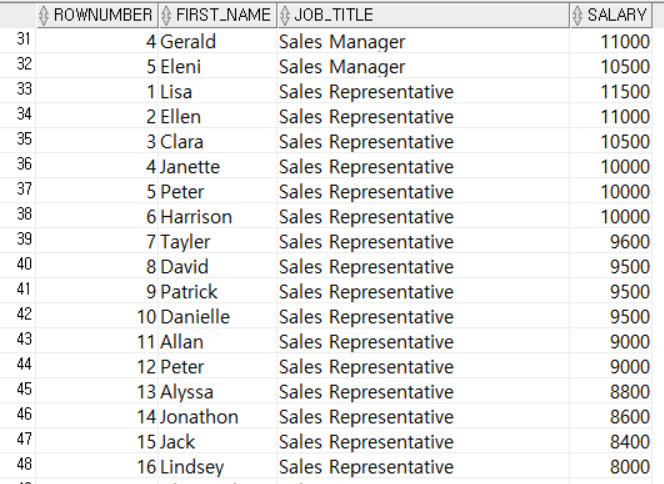
JOB_ID별로 행을 그룹화한 후, SALARY에 따라 내림차순으로 순위를 부여했다. 앞의 RANK(), DENSE_RANK()와는 다르게 ROW_NUMBER()는 같은 값이어도 다른 순위를 부여한다.
RANK, DENSE_RANK, ROW_NUMBER의 차이
-- 직원들을 급여가 높은 순으로 순위를 부여해서 조회
-- RANK(), DENSE_RANK(), ROW_NUMBER의 차이
SELECT RANK() OVER (ORDER BY SALARY DESC) AS SALARY_RAKING,
DENSE_RANK() OVER (ORDER BY SALARY DESC) AS SALARY_DENSE_RANKING,
ROW_NUMBER() OVER (ORDER BY SALARY DESC) AS SALARY_ROW_NUMBER,
FIRST_NAME,
SALARY
FROM EMPLOYEES;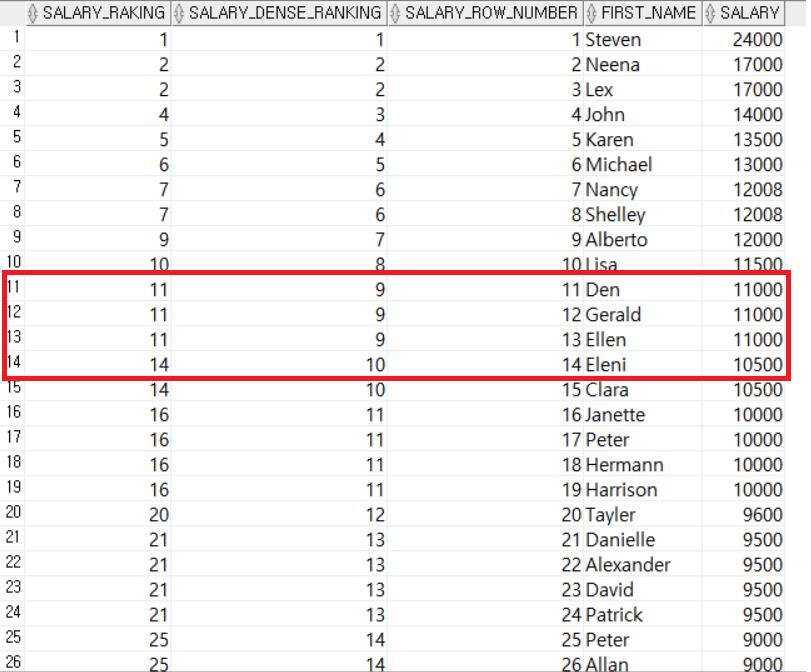
그림에서 볼 수 있듯이 ROW_NUMBER()는 데이터가 같은 값이어도 다른 순위를 매긴다. 그러나 RANK()와 DENSE_RANK()는 같은 값이면 같은 순위를 매긴다. 그리고 RANK()는 차순위를 동순위의 개수만큼 더한 값으로 매기지만, DENSE_RANK()는 동순위 다음 바로 다음 값을 차순위로 매긴다.
집계함수
SELECT 집계함수(컬럼명) OVER (PARTITION BY 컬럼명) AS 컬럼1,
컬럼2,
컬럼3,
. . .
FROM 테이블명
-- PARTITION BY절은 생략 가능하다.
-- PARTITION BY절이 다중행 함수의 GROUP BY절의 역할을 대신한다. PARTITION BY절에 그룹화할 컬럼을 지정하고 집계함수의 괄호 안에 분석하고자 하는 컬럼을 지정한다. 다중행 함수에서 GROUP BY절로 그룹화했다면
분석함수에서는 PARTITION BY절이 그 역할을 대신한다.
-- 직원 이름, 급여, 부서 평균급여, 직원급여와 부서평균급여 차이 조회
-- 분석함수 활용
SELECT FIRST_NAME,
SALARY,
TRUNC(AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID)) AS AVG_SALARY,
SALARY - TRUNC(AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID)) AS SALARY_GAP
FROM EMPLOYEES
ORDER BY EMPLOYEE_ID;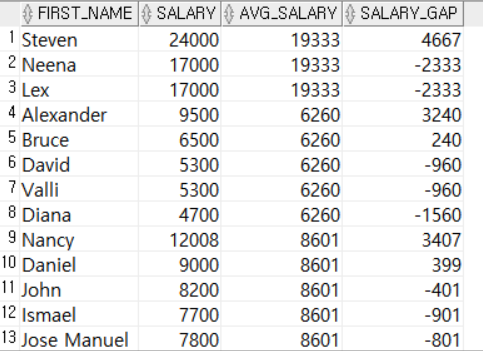
DEPARTMENT_ID로 행을 그룹화한 후, SALARY의 평균을 계산했다. 이 결과를 이용해 부서 평균급여, 직원급여와 부서 평균급여의 차이를 출력한다.
-- 다중행함수(그룹함수) 활용
SELECT B.FIRST_NAME,
B.SALARY,
A.AVG_SALARY,
B.SALARY - A.AVG_SALARY AS SALARY_GAP
FROM (SELECT DEPARTMENT_ID, TRUNC(AVG(SALARY)) AS AVG_SALARY
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID) A,
EMPLOYEES B
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID
ORDER BY B.EMPLOYEE_ID;위 집계함수의 예제를 다중행함수를 이용해서 조회하는 쿼리다. 다중행 함수를 이용하면 GROUP BY절에 지정된 컬럼만 SELECT절에서 조회할 수 있으므로 DEPARTMENT_ID를 제외한 다른 컬럼을 조회하려면 서브쿼리로 작성해야 한다. 집계함수는 GROUP BY절을 사용하지 않기 때문에 쿼리를 보다 간결하게 작성할 수 있다.
