인덱스란?
데이터 검색 성능의 향상을 위해 테이블의 컬럼에 사용하는 데이터베이스 객체이다. 테이블에 저장된 특정 행의 주소를 책의 목록처럼 만든 것이다. 인덱스를 사용해서 원하는 데이터를 검색하는 방법이 Index Scan이고, 인덱스를 사용하지 않고 데이터의 처음부터 끝까지 검색하는 방법이 Table Full Scan이다.
B-tree
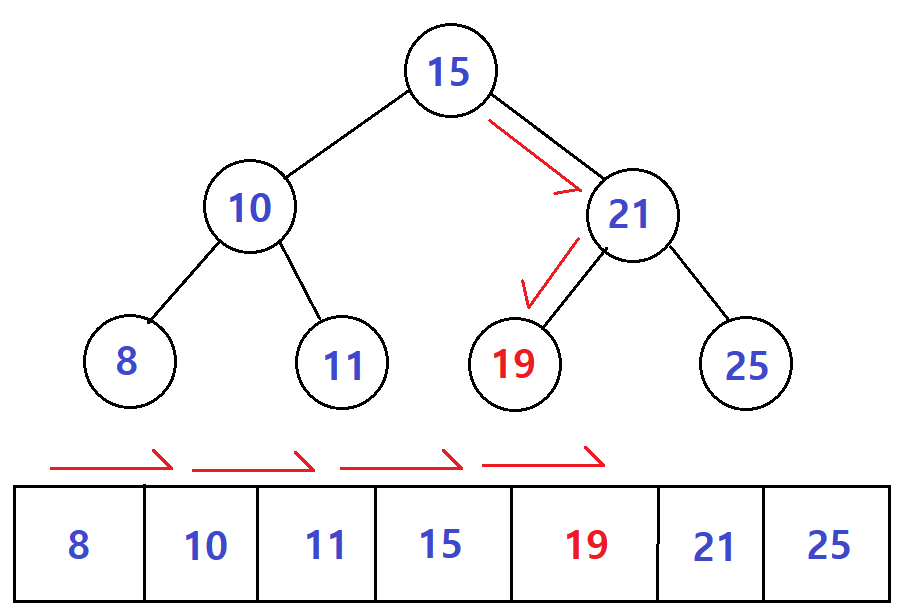
B-tree는 아래 그림의 첫 번째와 같이 데이터가 트리형태로 저장되어 있다. 숫자가 있는 원을 '노드'라고 하고, 최상단에 있는 노드를 루트 노드(Root Node)라고 한다. 루트 노드를 기준으로 좌우가 균형을 이루고 있기 때문에 Balanced Tree를 줄여서 B-tree라고 한다. (사람들이 그렇게 추측한다.)
검색하고자 하는 값이 현재 검색한 값보다 작으면 왼쪽으로, 크면 오른쪽으로 검색한다. 이러한 B-트리가 RDBMS에서 주로 사용하는 인덱스의 구조다.
그림에서 볼 수 있듯이 19를 검색하려고 할 때, 일반적인 오름차순 배열은 4번을 검색해야하지만, B-tree구조라면 2번만에 검색할 수 있다.
인덱스 생성 및 삭제
기본키 혹은 고유키로 지정된 컬럼은 자동으로 인덱스가 생성된다. 그 외의 컬럼에 인덱스를 생성하기 위해서는 CREATE문을 사용해야 한다. 사용방법은 다음과 같다.
-- 인덱스 생성
CREATE INDEX 인덱스명
ON 테이블명 (컬럼명1 정렬옵션
컬럼명2 정렬옵션
... );
-- 인덱스 삭제
DROP INDEX 인덱스명;인덱스 사용이 무조건 좋을까?
그렇지는 않다. B-tree로 구성된 인덱스를 '탐색'하려면 우선 B-tree구조로 '정렬'이 되어야 한다. 그래서 인덱스를 사용하면 데이터 조회는 보다 빠르게 완료할 수 있지만, 데이터 생성 및 수정은 데이터를 정렬해서 저장해야 하기 때문에 오히려 느려질 수 있다. 즉, 인덱스 사용은 생성/수정 작업의 성능을 희생하고 조회작업의 성능을 개선하는 것이다.
또한, 인덱스를 통해 데이터를 탐색할 때 'key'라는 값을 통해 원하는 값을 찾아나간다. 이 값을 저장하기 위한 공간도 따로 할당해야 하기 때문에 무분별한 인덱스 사용은 전체 쿼리 성능을 비효율적으로 만들 수 있다.
