서브쿼리
-
SELECT문의 내부에 정의된 또 다른 SELECT문을 서브쿼리라고 한다.
-
서브쿼리의 결과를 활용해서 기능을 수행하는, 즉, 서브쿼리를 포함하는 SELECT문을 메인쿼리라고 한다.
-
서브쿼리를 포함시킬 수 있는 절은 다음과 같다.
- WHERE절
- HAVING절
- FROM절
서브쿼리의 특징 및 주의점
-
서브쿼리는 메인쿼리보다 먼저 실행된다.
-
서브쿼리는 반드시 괄호로 묶고 조건식의 오른쪽에 위치시킨다.
-
서브쿼리의 실행결과가 단일행인지, 다중행인지에 따라 적절한 연산자를 사용해야 한다.
단일행 서브쿼리
-
SELECT문의 실행 결과로 단 하나의 행을 출력하는 서브쿼리를 의미한다.
-
단일행 연산자
- '같지 않음'을 제외한 나머지 연산자는 일반적인 비교연산자와 동일하다.
- 단일행 서브쿼리의 '같지 않음'을 의미하는 연산자는
<>, ^=, !=이다.
-- 부서아이디가 60인 직원 중에서 전체직원의 평균급여보다 급여를 많이받는 직원의 아이디, 이름, 급여, 부서이름을 조회
SELECT E.FIRST_NAME, E.SALARY, D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID
AND E.DEPARTMENT_ID = 60
AND E.SALARY < (SELECT AVG(SALARY)
FROM EMPLOYEES);
다중행 서브쿼리
-
SELECT문의 실행 결과로 여러 개의 행을 출력하는 서브쿼리를 의미한다.
-
서브쿼리의 결과가 여러 행이므로 앞서 다룬 단일행 연산자와는 다른 연산자를 사용해야 한다.
-
다중행 연산자는 다음과 같다.
IN>ANY, <ANY>ALL, <ALL
IN 연산자
다중행 연산자 중 IN 연산자는 앞서 WHERE절에서 다룬 IN 연산자와 기능이 동일하다.
-- 'Seattle'에 소재지를 두고 있는 부서에 속한 직원의 이름과 소속 부서 조회
SELECT D.DEPARTMENT_NAME, E.FIRST_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID
AND E.DEPARTMENT_ID IN (SELECT DEPARTMENT_ID
FROM DEPARTMENTS
WHERE LOCATION_ID = (SELECT LOCATION_ID
FROM LOCATIONS
WHERE CITY = 'Seattle'));우선 Seattle의 소재지 아이디를 찾고, 해당 소재지에 위치한 부서의 부서 아이디를 찾아야 한다. 그래서 서브쿼리 2개가 중첩되었다. 각각의 서브쿼리를 실행해보며 전체 SQL문을 이해해본다.
-- Seattle의 소재지 아이디 조회
SELECT LOCATION_ID
FROM LOCATIONS
WHERE CITY = 'Seattle';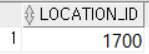 Seattle의 LOCATION_ID가 1700이고 DEPARTMENTS테이블은 LOCATION_ID컬럼을 갖고 있다. 이를 통해 Seattle에 위치한 부서를 조회할 수 있다.
Seattle의 LOCATION_ID가 1700이고 DEPARTMENTS테이블은 LOCATION_ID컬럼을 갖고 있다. 이를 통해 Seattle에 위치한 부서를 조회할 수 있다.
두 번째 서브쿼리를 다르게 작성하면 아래와 같다.
-- 소재지가 Seattle(소재지아이디가 1700)인 부서의 부서아이디 조회
SELECT DEPARTMENT_ID
FROM DEPARTMENTS
WHERE LOCATION_ID = 1700; 
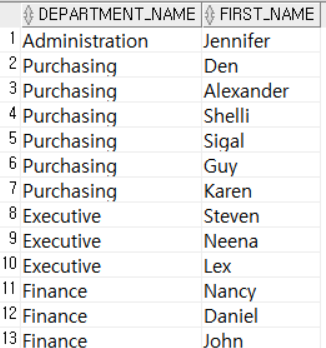
위에서 획득한 Seattle의 LOCATION_ID를 통해 Seattle에 위치한 부서의 DEPARTMENT_ID를 획득했다. 총 21개의 DEPARTMENT_ID를 획득했고, 마지막으로 이 부서에 속한 직원들의 이름과 소속 부서 이름을 조회한다. 최종 결과는 다음과 같다.
ANY 연산자
기본적으로 ANY연산자는 출력된 서브쿼리의 여러 행중 적어도 하나가 조건식을 만족하면 메인쿼리의 조건식을 true로 판정한다. 그래서 등가 비교 연산자와 함께 =ANY로 사용하면 IN 연산자와 같은 역할을 한다.
그러나 대소 비교 연사자와 함께 <ANY, >ANY 처럼 사용하는 경우는 조금 다르다. 결론부터 말하자면 A >ANY B는 A가 서브쿼리B 결과의 여러 행중에서 적어도 한 행보다 크면 해당 조건식을 true로 판정한다. 예제를 통해 알아보자.
-- 80번 부서에 소속된 직원의 급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회
-- >ANY는 80번 부서의 어느 급여보다도 크면 true. 즉, 80번 부서의 최저 급여보다 커야 함.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID != 80
AND SALARY >ANY (SELECT SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 80);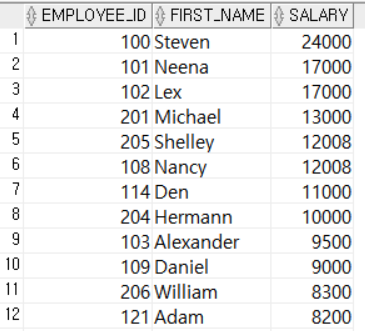 80번 부서의 직원보다 급여를 많이 받는 직원을 조회하므로 메인쿼리의 WHERE절에서 80번 부서에 소속되지 않은 직원들만 조회하는 조건을 지정했다. 서브쿼리의 결과로 80번 부서 직원들의 급여가 출력되고 이 중 가장 적은 급여보다 많은 급여를 받는 직원을 조회한다.
80번 부서의 직원보다 급여를 많이 받는 직원을 조회하므로 메인쿼리의 WHERE절에서 80번 부서에 소속되지 않은 직원들만 조회하는 조건을 지정했다. 서브쿼리의 결과로 80번 부서 직원들의 급여가 출력되고 이 중 가장 적은 급여보다 많은 급여를 받는 직원을 조회한다.
즉, 이 예제에서 WHERE SALARY >ANY (SELECT ...)는 WHERE SALARY > (SELECT MIN(SALARY) ...) 와 같다.
ALL 연산자
A >ALL B는 A가 서브쿼리B 결과의 모든 행보다 크면 해당 조건식을 true로 판정한다.
-- 80번 부서에 소속된 직원의 급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회
-- >ALL은 80번 부서의 모든 급여보다 커야 함. 즉, 80번 부서의 최대 급여보다 커야 함.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID != 80
AND SALARY >ALL (SELECT SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 80);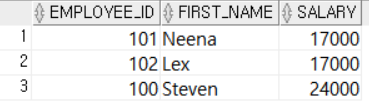
ANY의 예제와 비슷한 예제이다. 서브쿼리의 모든 행보다 큰 값만 ture판정한다는 점이 다르다.
즉, 이 예제에서 WHERE SALARY >ALL (SELECT ...)는 WHERE SALARY > (SELECT MAX(SALARY) ...) 와 같다.
HAVING절의 서브쿼리
-- 직원수가 가장 많은 부서의 아이디와 사원수 조회
SELECT DEPARTMENT_ID, COUNT(*)
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NOT NULL
GROUP BY DEPARTMENT_ID
HAVING COUNT(*) = (SELECT MAX(COUNT(*))
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NOT NULL
GROUP BY DEPARTMENT_ID);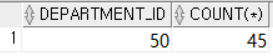 먼저 메인쿼리에서 DEPARTMENT_ID로 그룹화하고 COUNT(*)함수를 실행하면 부서 아이디 별 직원수를 조회할 수 있다. 그 후, HAVING절에서 직원수가 가장 많은 부서의 직원수를 조회하고 그 직원수와 일치하는 행을 필터링한다.
먼저 메인쿼리에서 DEPARTMENT_ID로 그룹화하고 COUNT(*)함수를 실행하면 부서 아이디 별 직원수를 조회할 수 있다. 그 후, HAVING절에서 직원수가 가장 많은 부서의 직원수를 조회하고 그 직원수와 일치하는 행을 필터링한다.
FROM절의 서브쿼리
SELECT문을 통해 테이블의 특정 데이터를 추출한 후 FROM절에서 서브쿼리로 사용하는 방법이다. 즉, 서브쿼리로 조회한 테이블을 기존 테이블과 조인하는 것이다. '인라인 뷰'라고도 한다.
SELECT E.FIRST_NAME, D.DEPARTMENT_ID, D.DEPARTMENT_NAME, J.JOB_TITLE
FROM (SELECT FIRST_NAME, DEPARTMENT_ID, JOB_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 60) E,
DEPARTMENTS D,
JOBS J
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID
AND E.JOB_ID = J.JOB_ID;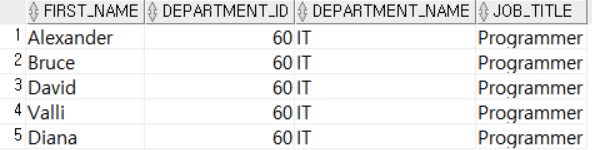 부서번호가 60인 직원들의 이름, 부서번호, 직종번호를 조회한 테이블을 서브쿼리로 작성하여 FROM절에서 다른 테이블과 조인했다.
부서번호가 60인 직원들의 이름, 부서번호, 직종번호를 조회한 테이블을 서브쿼리로 작성하여 FROM절에서 다른 테이블과 조인했다.
FROM절에 너무 많은 서브쿼리를 작성하면 가독성이나 성능이 저하될 수 있기 때문에 아래와 같이 WITH절을 사용하기도 한다.
다중열 서브쿼리
서브쿼리의 SELECT절에 비교할 컬럼을 여러 개 지정하는 방법이다. 메인쿼리에서 비교할 컬럼을 괄호로 묶고, 서브쿼리의 SELECT절에서는 괄호로 묶은 컬럼과 같은 자료형을 갖는 컬럼을 지정한다.
-- 부서별 최저급여 조회했을 때, 각 부서에서 최저급여를 받는 직원의 이름, 급여, 부서아이디 조회
SELECT DEPARTMENT_ID, FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE (DEPARTMENT_ID, SALARY) IN (SELECT DEPARTMENT_ID, MIN(SALARY)
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NOT NULL
GROUP BY DEPARTMENT_ID);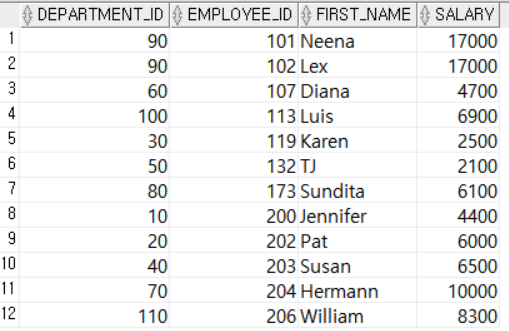 서브쿼리에서 각 부서 아이디와 그 부서의 최저급여를 조회했다. 메인쿼리의 WHERE절에서는 서브쿼리의 각 컬럼의 데이터와 일치하는 행을 필터링한다. 즉, 직원의 급여와 서브쿼리에서 조회된 급여가 일치하고 부서 아이디가 일치하는 행을 출력한다.
서브쿼리에서 각 부서 아이디와 그 부서의 최저급여를 조회했다. 메인쿼리의 WHERE절에서는 서브쿼리의 각 컬럼의 데이터와 일치하는 행을 필터링한다. 즉, 직원의 급여와 서브쿼리에서 조회된 급여가 일치하고 부서 아이디가 일치하는 행을 출력한다.
상호연관 서브쿼리
-
서브쿼리가 메인쿼리에서 사용되는 컬럼을 참조하는 방법이다.
-
서브쿼리에서 메인쿼리의 컬럼/표현식을 사용한다.
-
일반적인 서브쿼리는 메인쿼리보다 먼저 실행되고, 단 한번만 실행되지만 상호연관 서브쿼리는 그렇지 않다.
-
상호연관 서브쿼리는 메인쿼리의 모든 행에 대해서 매번 실행된다. 따라서 쿼리의 성능이 떨어지는 원인이 될 수 있다.
SELECT A.DEPARTMENT_ID, A.EMPLOYEE_ID, A.FIRST_NAME, A.SALARY
FROM EMPLOYEES A
WHERE A.SALARY = (SELECT MIN(B.SALARY)
FROM EMPLOYEES B
WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID
GROUP BY B.DEPARTMENT_ID)
ORDER BY A.DEPARTMENT_ID ASC;메인쿼리에서 EMPLOYEES테이블이 사용되고 서브쿼리에서도 EMPLOYEES테이블의 컬럼이 사용된다. 서브쿼리에서 EMPLOYEES테이블을 DEPARTMENT_ID로 그룹화하고 각 부서의 최저급여를 찾는다. 그리고 메인쿼리에서 그 최저급여와 같은 값을 갖고있는 행을 찾아 출력한다. 이 과정이 모든 행에대해 매번 실행된다. 이러한 이유로 쿼리 성능을 저하시키는 원인이 될 수있다.
스칼라 서브쿼리
-
SELECT절에 적는 서브쿼리이다.
-
스칼라 서브쿼리의 결과는 반드시 1행 1열이어야 한다.
-
메인쿼리의 결과만큼 반복수행된다.
SELECT A.DEPARTMENT_ID, A.DEPARTMENT_NAME, (SELECT COUNT(*)
FROM EMPLOYEES B
WHERE B.DEPARTMENT_ID = A.DEPARTMENT_ID) AS CNT
FROM DEPARTMENTS A;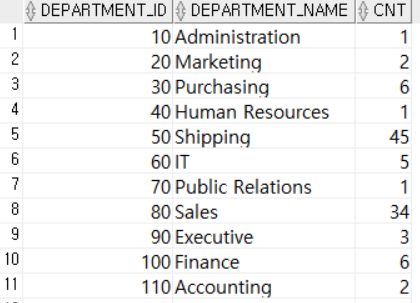 먼저 메인쿼리가 실행되어 DEPARTMENTS테이블의 DEPARTMENT_ID와 DEPARTMENT_NAEM을 출력한다. 그 후 서브쿼리에서 메인쿼리의 DEPARTMENT_ID와 일치하는 부서의 직원수 총합을 출력한다. 이 과정이 메인쿼리가 종료될 때까지 반복수행한다.
먼저 메인쿼리가 실행되어 DEPARTMENTS테이블의 DEPARTMENT_ID와 DEPARTMENT_NAEM을 출력한다. 그 후 서브쿼리에서 메인쿼리의 DEPARTMENT_ID와 일치하는 부서의 직원수 총합을 출력한다. 이 과정이 메인쿼리가 종료될 때까지 반복수행한다.