어제 SSAFYnity 동문회에서 여러 분들과 이야기를 나누다가,
한 분께서 최근 면접에서 RAID 관련 질문을 정말 많이 받는다는 이야기를 들려주셨다.
그 얘기를 들으면서 문득,
“레이드… 아, 저장소 디스크를 여러 개 묶어서 관리하는 그거!”
라고만 알고 있었지,
정작 각 RAID 방식이 어떤 원리로 동작하는지는 명확하게 이해하지 못하고 있었다는 걸 깨달았다.
그래서 오늘은 RAID 개념을 처음부터 다시 공부했고,
앞으로는 직접 RAID를 구성해보면서
각 방식이 제공하는 성능·안정성의 차이를 실제로 체감하며 정리해보려고 한다.
1. RAID(Redundant Array of Independent Disks)란?
RAID는 여러 개의 디스크 드라이브를 배열(Array) 형태로 묶어
스트라이핑(striping) 또는 미러링(mirroring) 방식으로 데이터를 운영하는 저장장치 구성 기술이다.
이를 통해 다음과 같은 이점이 있다:
- 성능 향상
- 장애 허용 능력(오류 내성) 향상
- 더 많은 저장 용량 확보
- 비용 효율적인 스토리지 구성
RAID는 서버나 스토리지 시스템에서
안정성과 성능을 높이기 위한 대표적 기술로 널리 사용된다.
2. RAID에서 사용되는 운영 방식
RAID는 크게 두 가지 기본 동작 방식을 조합하여 구성된다.
- 스트라이핑(Striping)
데이터를 여러 블록으로 나누고 그 블록들을 여러 드라이브에 분산 저장하는 방식
성능 향상 목적 (읽기/쓰기 속도 증가)
- 미러링(Mirroring)
동일한 데이터를 두 개 이상의 디스크에 복제하여 저장
장애 대응 목적
RAID는 위 두 방법을 어떻게 조합하느냐에 따라 서로 다른 RAID 레벨로 구분된다.
1) RAID 0
2개 이상의 디스크에 데이터를 번갈아 저장하여 최고의 성능을 낼 수 있다.
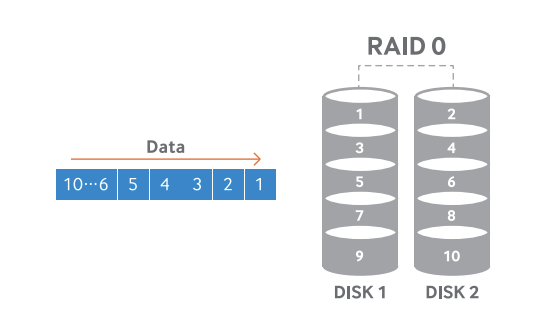
패리티가 없어 디스크 1개라도 고장나면 데이터 손실이 발생한다. 데이터를 여러 디스크에 저장하기 때문에 하나의 디스크라도 고장이 나면 프로그램을 실행할 수 없다.
SSD 캐시 등 속도만 필요한 경우에 제한적으로 사용한다.
2) RAID 1
동일한 데이터의 완전한 복제본을 저장하여 디스크 1개 고장 시에도 데이터 손실이 없다.
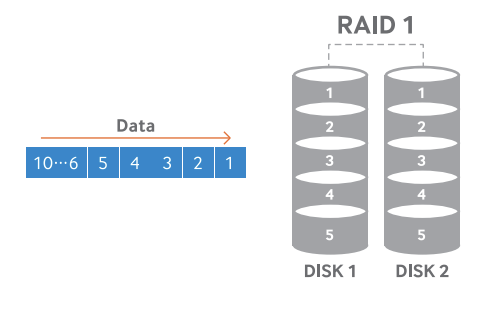
용량은 가장 작은 디스크 용량 기준으로 제한된다.
데이터를 두 번 써야 하므로 쓰기 성능은 RAID0보다 떨어진다.
비용이 높지만 안정성이 높다.
3) RAID 5
스트라이핑 + 패리티 1개
3개 이상의 디스크가 필요하다.
패리티는 항상 데이터가 있는 디스크와는 다른 디스크에 저장된다.
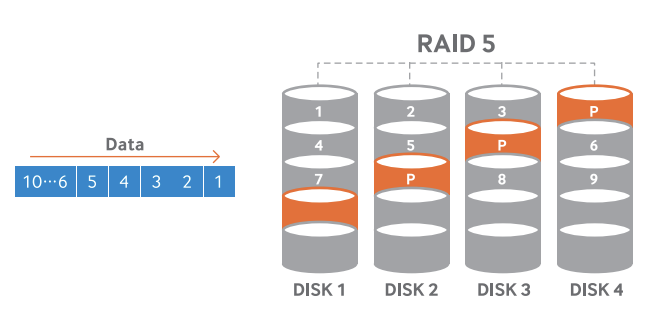
디스크 1개 고장 시 패리티 기반으로 데이터 복구 가능하다.
읽기 성능은 높고 용량 효율도 좋다.
하지만 쓰기 속도가 느리고 디스크 재구성(Rebuild) 시간이 길다.
패리티란?
패리티는 여러 데이터 조각을 XOR 연산으로 더해 놓은 값이다.
이 패리티만 있으면 디스크 1개가 고장 나도 그 데이터를 다시 만들어 낼 수 있다.
패리티 예시
RAID5 (3개의 디스크)
Disk1: 데이터 A1 A2 A3
Disk2: 데이터 B1 B2 B3
Disk3: 패리티 P1 P2 P3 (A1+B1, A2+B2 … XOR)
Disk2가 고장 나면:
B1 = A1 XOR P1
B2 = A2 XOR P2
B3 = A3 XOR P3
→ 계산으로 B를 다시 만들어서 RAID가 살아남음.
만약 패리티를 2개 만들어 놓으면 디스크가 2개가 고장나도 복구할 수 있다. (RAID 6)
P 패리티: XOR 연산 사용
Q 패리티: 갈루아 필드(GF(2^8)) 연산 사용
쉽게 얘기하면 2개의 변수가 있는 문제는 2개의 방정식으로 풀 수 있는 원리와 같다.
리빌드(Rebuild)란?
RAID 구성에서 고장난 디스크를 새 디스크로 교체한 후,
실종된 데이터를 다시 ‘재생성’해서 RAID를 정상 상태로 회복시키는 과정.
디스크가 하나 고장나면 RAID가 degraded(경고 상태)가 된다.
새 디스크를 꽂으면 RAID가 남은 디스크와 패리티 정보를 이용해 사라진 데이터를 다시 계산해서 새 디스크에 채워 넣는 작업을 진행하는데 이 과정을 “리빌드”라고 한다.
4) RAID 10 (1+0)
RAID 1(미러링) + RAID 0(스트라이핑) 결합하여 최소 4개의 디스크 필요하다.
짝수 개의 디스크만 추가 가능하다.
1단계: 디스크를 미러 쌍으로 구성
2단계: 각 미러링 쌍을 스트라이핑하여 논리 볼륨 생성
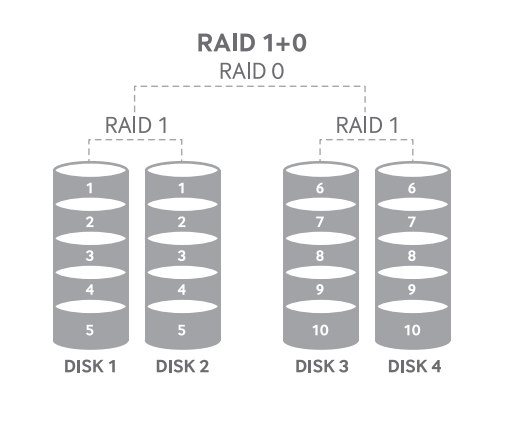
쓰기 성능이 매우 뛰어나며, 높은 안정성과 성능을 동시에 확보할 수 있다.
용량의 50%만 사용할 수 있어 비용이 높다.
3. RAID 사용 방법
RAID는 운영 방식에 따라 소프트웨어 RAID와 하드웨어 RAID 두 가지로 나뉜다.
소프트웨어 RAID
운영체제(OS)가 CPU를 사용하여 RAID를 관리한다.
리눅스는 RAID0, 1, 5, 6 등 대부분을 지원
윈도우도 RAID0, 1, 5 일부 지원
예: mdadm 기반 RAID 구성
→ 일반 PC에서도 바로 구성 가능
하드웨어 RAID
RAID를 지원하는 HBA(Host Bus Adapter) 카드나 RAID 컨트롤러가 관리한다.
RoC(RAID on Chip) 기반으로 CPU 부하가 적다.
RAID 레벨 지원 범위는 각 카드 사양에 따라 다르다.
서버/스토리지 전문 환경에서 주로 사용
RAID별 특성 정리
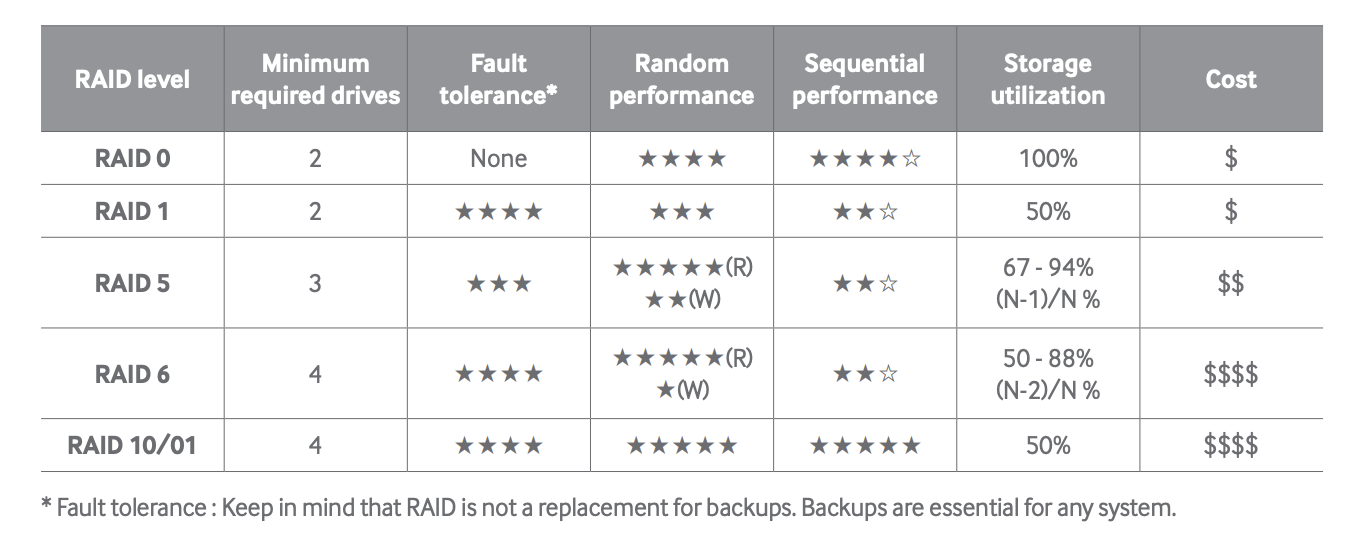
※ RAID는 백업의 대체제가 아니다는 점을 항상 명심해야 한다.
(출처: 삼성전자 데이터센터 Samsung_SSD_845DC_07_Redundant_Array_of_Independent_Disks_RAID.pdf)
보통 학습을 진행해도 실습을 진행해보지 않으면 금방 잊혀진다. 따라서 HDD 4대를 직접 데스크탑에 레이드 연결해보고 각각의 레이드 환경에 따라 성능과 리빌드 과정을 확인하는 작업을 진행하려고 한다. SATA HDD 4대를 주문해놨고 도착하면 차례로 실습한 후에 실습 결과를 포스팅하겠다.
앞으로 진행할 실습 계획
RAID0 구성 → 성능 측정
RAID1 구성 → 안정성 테스트
RAID5 구성 → 디스크 고장 시나리오 실험
RAID6 구성 → 2개 고장 대응 확인
RAID10 구성 → 미러링 + 스트라이핑 성능 비교
Hot Spare 구성 → 자동 복구 동작 확인
- fio로 성능 측정
- SMART로 디스크 상태 확인
마무리
단순히 일 때문에 참석했던 행사였지만, 오히려 개발과 관련된 새로운 키워드들을 얻게 되었고, 그 과정에서 다시 호기심이 살아나는 계기가 되었다. 다양한 개발자들을 만나 이야기 나누면서 기술뿐 아니라 사람과 경험을 통해 성장할 수 있음을 다시 느꼈다.
특히 RAID라는 주제를 접하게 되면서, 평소 깊게 다루지 않았던 스토리지 구조나 데이터 보호 방식에 대해 스스로 공부해보는 기회까지 이어졌다. 단순히 “디스크 여러 개 묶는 기술” 정도로 알던 RAID가, 성능, 안정성, 데이터 구조까지 연결된 깊이 있는 개념이라는 걸 배우면서 개발자로서 시야가 더 넓어진 느낌이다.
앞으로도 이렇게 예상치 못한 곳에서 새로운 지식을 얻고, 커뮤니티 활동을 통해 성장하는 경험을 계속 이어가고 싶다. 작은 호기심 하나가 또 어떤 배움을 만들어낼지 기대된다.
