꼭 필요한 자료구조 기초
탐색: 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정
DFS와 BFS를 제대로 이해하려면 기본 자료구조인 스택과 큐에 대한 이해가 전제 되어야 한다.
스택, 큐의 핵심적인 함수
- 삽입(Push) : 데이터를 삽입한다.
- 삭제(Pop) : 데이터를 삭제한다.
스택, 큐 사용 시 고려할 점
- 오버플로 : 자료구조가 수용할 수 있는 데이터의 크기를 이미 가득 찬 상태에서 삽입 연산을 수행할 때 발생한다.
- 언더플로 : 데이터가 전혀 들어 있지 않은 상태에서 삭제 연산을 수행할 때 발생한다.
스택
- 선입후출 구조 or 후입선출 구조
- 입구와 출구가 동일한 형태
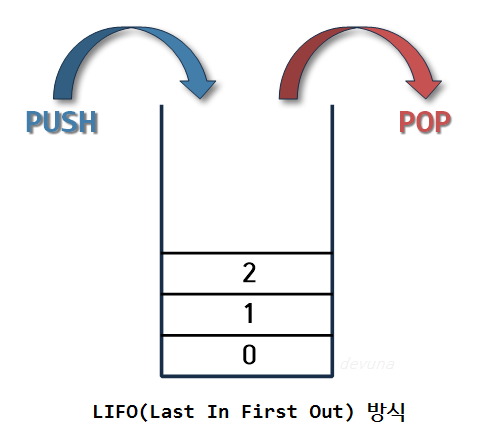
Stack<Integer> s = new Stack<>();
s.push(5); //삽입
s.push(2);
s.pop(); //삭제
while (!s.empty()) {
System.out.println(s.peek()); //마지막 요소 반환
s.pop();
}
큐
- 선입선출 구조
- 입구와 출구가 뚫린 터널 같다
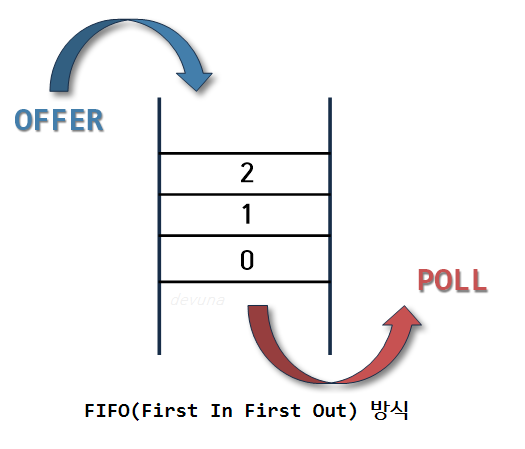
Queue<Integer> q = new LinkedList<>();
q.offer(5); //삽입
q.offer(2);
q.poll(); //반환값: 삭제된 value재귀함수
- 자기 자신을 호출하는 함수
- 종료 조건을 꼭 명시해야 한다
public static void recursiveFunction(int i) {
// 100번째 호출을 했을 때 종료되도록 종료 조건 명시
if (i == 100) return;
System.out.println(i + "번째 재귀 함수에서 " + (i + 1) + "번째 재귀함수를 호출합니다.");
recursiveFunction(i + 1);
System.out.println(i + "번째 재귀 함수를 종료합니다.");
}
public static void main(String[] args) {
recursiveFunction(1);
}탐색 알고리즘 DFS/BFS
그래프의 기본 구조
- 노드(Node) = 정점(Vertex)
- 간선(Edge)
- 그래프의 탐색 이란, 하나의 노드를 시작으로 다수의 노드를 방문하는 것
- 두 노드가 간선으로 연결되어 있다 = 두 노드는 인접하다
그래프 표현방법 2가지
인접 리스트
리스트로 그래프의 연결 관계를 표현하는 방식
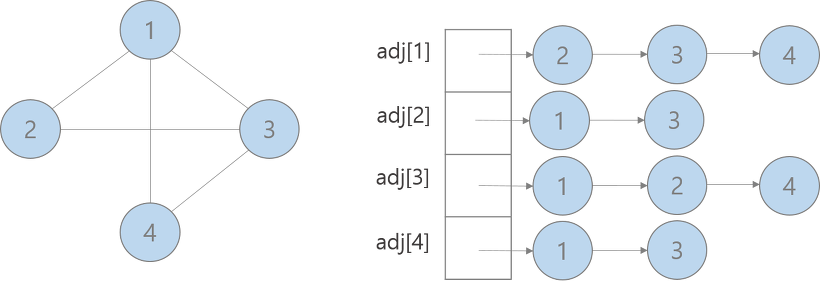
모든 노드에 연결된 노드에 대한 정보를 차례대로 연결하여 저장한다.
class Node {
private int index;
private int distance;
public Node(int index, int distance) {
this.index = index;
this.distance = distance;
}
public class Main {
// 행(Row)이 3개인 인접 리스트 표현
public static ArrayList<ArrayList<Node>> graph = new ArrayList<ArrayList<Node>>();
public static void main(String[] args) {
// 그래프 초기화
for (int i = 0; i < 3; i++) {
graph.add(new ArrayList<Node>());
}
// 노드 0에 연결된 노드 정보 저장 (노드, 거리)
graph.get(0).add(new Node(1, 7));
graph.get(0).add(new Node(2, 5));
// 노드 1에 연결된 노드 정보 저장 (노드, 거리)
graph.get(1).add(new Node(0, 7));
// 노드 2에 연결된 노드 정보 저장 (노드, 거리)
graph.get(2).add(new Node(0, 5));
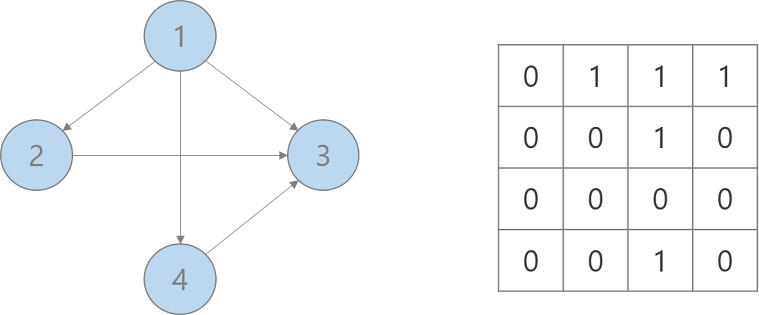
}인접 행렬
2차원 배열로 그래프의 연결 관계를 표현하는 방식
연결 되어 있지 않은 노드끼리는 무한의 비용이라고 작성한다. 아래와 같이 초기화 한다.
public static final int INF = 999999999;
// 2차원 리스트를 이용해 인접 행렬 표현
public static int[][] graph = {
{0, 7, 5},
{7, 0, INF},
{5, INF, 0}
};💡두 방식의 차이는 무엇일까?
- 메모리 측면에서는 인접 행렬보다 인접 리스트가 좋다.
- 인접 행렬 방식은 모든 관계를 저장하므로 노드 개수가 많을 수록 메모리가 불필요하게 낭비된다.
- 인접 리스트 방식은 연결된 정보만을 저장하기 때문에 메모리를 효율적으로 사용한다.
- 하지만, 인접 리스트는 정보를 얻는 속도가 느리다.
DFS(Depth-First Search)
- 깊이 우선 탐색, 즉 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
- 시간복잡도: O(V+E) // V: 노드의 개수, E: 에지 개수
- 실제로는 스택을 쓰지 않아도 되다.
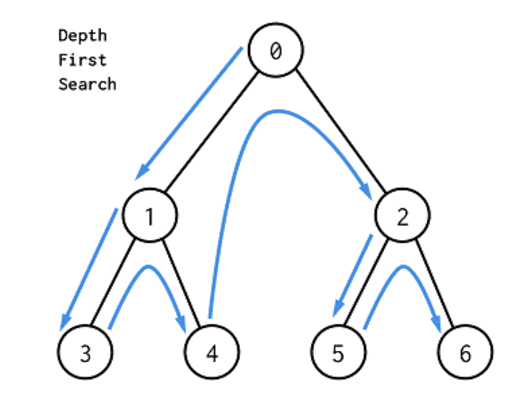
[스택]을 이용한 동작과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 2번 과정을 더 이상 수행할 수 없을 때까지 반복한다.
코드(java)
// DFS 함수 정의
public static void dfs(int x) {
// 현재 노드를 방문 처리
visited[x] = true;
System.out.print(x + " ");
// 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for (int i = 0; i < graph.get(x).size(); i++) {
int y = graph.get(x).get(i);
if (!visited[y]) dfs(y);
}
}
BFS(Breath First Search)
- 너비 우선 탐색, 즉 가까운 노드부터 탐색하는 알고리즘이다.
- O(N)의 시간 소요
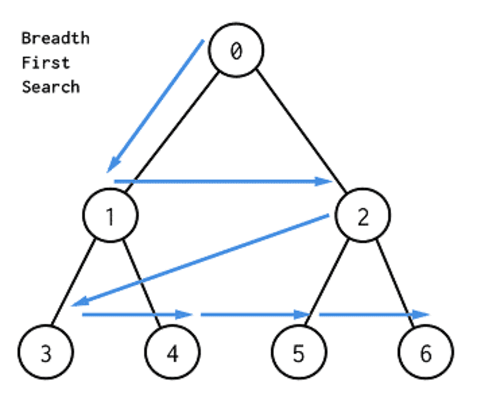
[큐]를 이용한 동작과정
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
- deque 라이브러리를 사용하는 것이 좋다.
- 일반적인 경우 실제 수행 시간은 DFS보다 좋은 편이다.
코드(java)
// BFS 함수 정의
public static void bfs(int start) {
Queue<Integer> q = new LinkedList<>();
q.offer(start);
// 현재 노드를 방문 처리
visited[start] = true;
// 큐가 빌 때까지 반복
while(!q.isEmpty()) {
// 큐에서 하나의 원소를 뽑아 출력
int x = q.poll();
System.out.print(x + " ");
// 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for(int i = 0; i < graph.get(x).size(); i++) {
int y = graph.get(x).get(i);
if(!visited[y]) {
q.offer(y);
visited[y] = true;
}
}
}
}
간단 요약!
| DFS | BFS | |
|---|---|---|
| 동작 원리 | 스택 | 큐 |
| 구현 방법 | 재귀 함수 이용 | 큐 자료구조 이용 |

열심히 달리는 개발자