정렬 알고리즘 개요
정렬 : 데이터를 특정한 기준에 따라서 순서대로 나열
데이터를 정렬하면 이진 탐색이 가능해진다.
정렬 알고리즘은 다양하지만 여기서는 선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬 만 설명한다.
또한 오름차순 정렬을 수행한다고 가정한다.
내림차순 정렬은 오름차순 정렬을 수행한 뒤에 결과를 뒤집기 하면 만들 수 있다 (O(N)).
선택 정렬
가장 원시적인 방법으로, 가장 작은 것을 선택해서 앞으로 보내는 과정을 반복하는 알고리즘 이다.
- 시간복잡도: O(n2)
- 선택 정렬은 기본 정렬 라이브러리를 포함해 뒤에서 다룰 알고리즘과 비교했을 때 매우 비효율적이다.
- 다만, 특정한 리스트에서 가장 작은 데이터를 찾는 일이 잦으므로 소스코드 형태에 익숙해질 필요가 있다.
과정
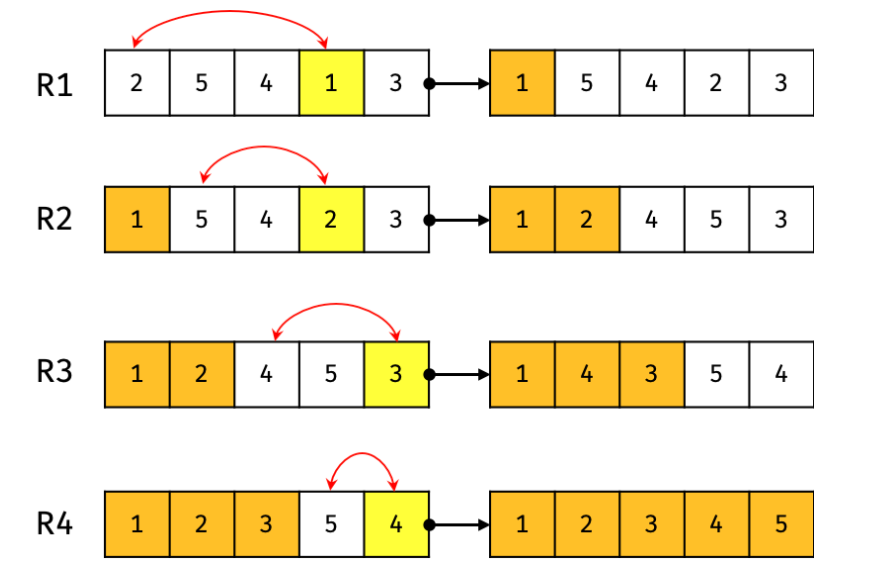
1. 전체 중에서 가장 작은 데이터(1)를 선택한 후, 맨 앞에 있는 데이터(2)와 바꾼다.
2. 정렬된 첫 번째는 제외하고 이후 데이터 중 가장 작은 데이터(2)를 선택해 처리되지 않은 데이터 중 가장 앞에 있는 데이터(5)와 바꾼다.
3. 이 과정을 반복한다.
코드
int n = 10;
int[] arr = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
for (int i = 0; i < n; i++) {
int min_index = i; // 가장 작은 원소의 인덱스
for (int j = i + 1; j < n; j++) {
if (arr[min_index] > arr[j]) {
min_index = j;
}
}
// 스와프
int temp = arr[i];
arr[i] = arr[min_index];
arr[min_index] = temp;
}💡 스와프란? 특정한 리스트가 주어졌을 때 두 변수의 위치를 변경하는 작업니다.
삽입 정렬
선택 정렬은 알고리즘 문제 풀이에 사용하기에는 느린 편이다. 그렇다면 삽입 정렬은 어떨까.
데이터를 하나씩 확인하여, 각 데이터를 적절한 위치에 삽입하는 알고리즘이다.
- 시간복잡도: O(n2), 최선의 경우 O(n)
- 선택 정렬과 흡사한 시간이 소요된다.- 삽입 정렬이 비효율적이나 정렬이 거의 되어 있는 상황에서는 퀵 정렬 알고리즘보다 더 강력하다.
- 특정한 데이터가 적절한 위치에 들어가기 이전에, 그 앞까지의 데이터는 이미 정렬되어 있다고 가정한다.
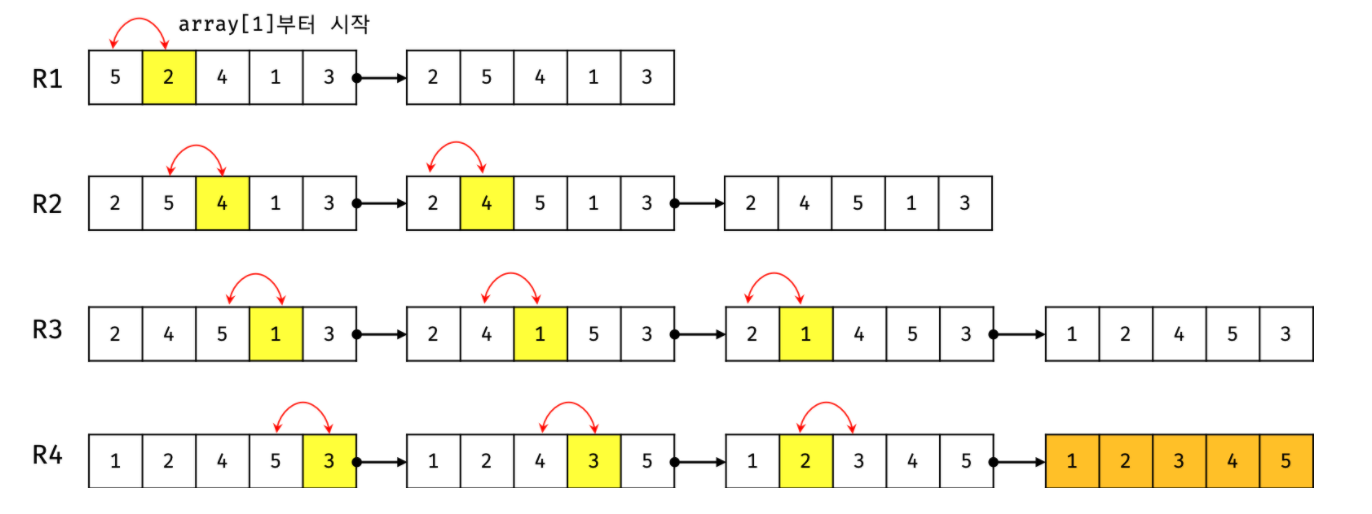
1. 삽입 정렬은 두 번째 데이터부터 시작한다. 왜냐하면 첫 번째 데이터는 그 자체로 정렬되어 있다고 판단하기 때문이다.
2. 두 번째 데이터(2)가 어떤 위치로 들어갈지 판단한다. 첫 번째 데이터(5)의 왼쪽으로 들어가거나 오른쪽으로 들어가는 두 경우만 존재한다. 이번 경우 왼쪽에 삽입한다.
3. 이어서 4가 어떤 위치에 들어갈지 판단한다. 삽입될 수 있는 위치는 총 3가지이며, 삽입될 데이터보다 작은 데이터를 만나 2의 오른쪽에 들어간다.
4. 적절한 위치에 삽입하는 과정을 N-1번 반복하게 되면 모든 데이터가 정렬된다.
코드
int n = 10;
int[] arr = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
for (int i = 1; i < n; i++) {
// 인덱스 i부터 1까지 감소하며 반복하는 문법
for (int j = i; j > 0; j--) {
// 한 칸씩 왼쪽으로 이동
if (arr[j] < arr[j - 1]) {
// 스와프(Swap)
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}
// 자기보다 작은 데이터를 만나면 그 위치에서 멈춤
else break;
}
}퀵 정렬
정렬 알고리즘 중에 가장 많이 사용되는 알고리즘이다.
기준(피벗)을 설정한 다음 큰 수와 작은 수를 교환한 후 리스트를 반으로 나누는 방식으로 동작하는 알고리즘이다.
- 시간복잡도: O(nlogn), 최악의 경우 O(n2)
- 데이터가 무작위로 입력되는 경우 퀵 정렬은 빠르게 동작할 확률이 높다.
- 그러나, 이미 데이터가 정렬되어 있는 경우에는 매우 느리게 동작한다.- 퀵 정렬을 수행하기 전에는 피벗을 어떻게 설정할 것인지 미리 명시해야한다. 그 방법에 따라 여러 가지 방식으로 퀵 정렬을 구분할 수 있다.
- 재귀함수와 동작 원리가 같다. 재귀함수에서는 종료조건이 필수적인데, 퀵 정렬에서는 현재 리스트의 개수가 1개인 경우이다.
여기서는 대표적인 호어 분할 방식을 기준으로 퀵 정렬을 설명한다.
- pivot은 3이고 왼쪽에서 부터 pivot보다 큰 데이터를 찾고, 오른쪽에서부터 pivot보다 작은 데이터를 찾는다. 그다음 큰 데이터와 작은 데이터의 위치를 서로 교환해준다.
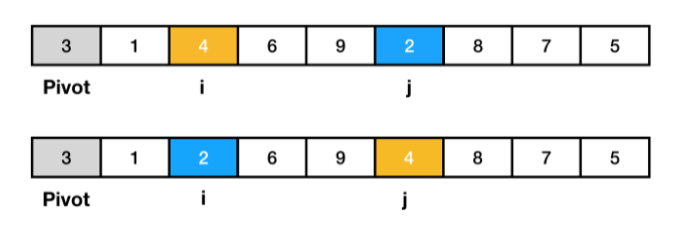
- 그 다음 다시 피벗보다 큰 데이터와 작은 데이터를 찾는다. 단, 현재 왼쪽에서부터 찾는 값과 오른쪽에서부터 찾는 값의 위치가 서로 엇갈리게 된다면, '작은 데이터'와 'pivot'의 위치를 서로 변경한다. 즉, 2와 3을 변경한다.
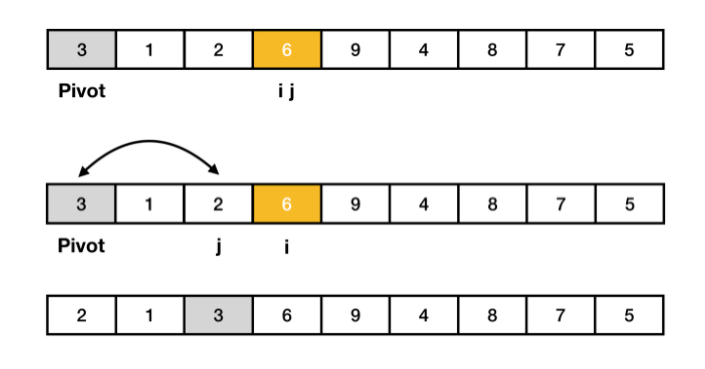
- pivot의 왼쪽에는 pivot보다 작은 데이터가 위치하고, 오른쪽에는 큰 데이터가 위치하게 된다. 이 작업을 분할 혹은 파티션 이라고 한다.
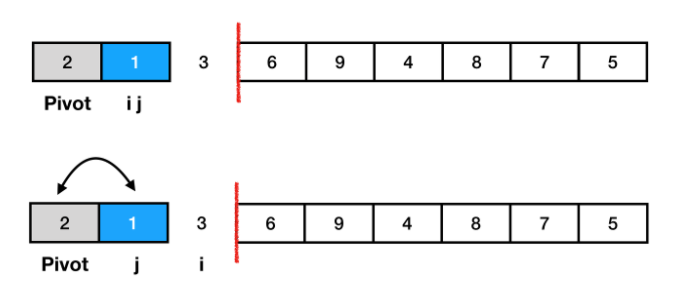
- 그 후 pivot을 기준으로 왼쪽과 오른쪽 리스트에서 각각 다시 정렬을 수행한다. 그러면 아래와 같이 정렬된 리스트가 나온다.

코드
public static void quickSort(int[] arr, int start, int end) {
if (start >= end) return; // 원소가 1개인 경우 종료
int pivot = start; // 피벗은 첫 번째 원소
int left = start + 1;
int right = end;
while (left <= right) {
// 피벗보다 큰 데이터를 찾을 때까지 반복
while (left <= end && arr[left] <= arr[pivot]) left++;
// 피벗보다 작은 데이터를 찾을 때까지 반복
while (right > start && arr[right] >= arr[pivot]) right--;
// 엇갈렸다면 작은 데이터와 피벗을 교체
if (left > right) {
int temp = arr[pivot];
arr[pivot] = arr[right];
arr[right] = temp;
}
// 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
else {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
// 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quickSort(arr, start, right - 1);
quickSort(arr, right + 1, end);
}계수 정렬
앞서 다룬 3가지 정렬 알고리즘처럼 직접 데이터의 값을 비교한 뒤에 위치를 변경하며 정렬하는 방식(비교 기반의 정렬 알고리즘)이 아니다.
계수 정렬은 반드시 어떠한 범위안에 존재하는 데이터들로 이루어진 데이터 배열에 한하여 데이터의 크기를 기준으로 카운트하여 정렬하는 알고리즘입니다.
- 시간복잡도: O(n+k), 최악의 경우도 동일하다.
- 공간복잡도: O(n+k)
- 계수 정렬은 때에 따라서 심각한 비효율성을 초래할 수 있다. 예를 들어 데이터가 0과 999999, 단 2개만 존재한다고 가정한다면 이럴 경우에도 리스트의 크기가 100만이 되어야한다.- 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠른 정렬 알고리즘이다.
- 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때만 사용할 수 있다.
- 일반적으로 가장 큰 데이터와 가장 작은 데이터의 차이가 100만을 넘지 않을 때 효과적이다.- 동일한 값을 가지는 데이터가 여러 개 등장할 때 적합하다.
- 별도의 리스트를 선언하고 그 안에 정렬에 대한 정보를 담는다는 특징이 있다.
과정
- 먼저 가장 큰 데이터와 가장 작은 데이터의 범위가 모두 담길 수 있도록 하나의 리스트를 생성한다. 크기가 10인 리스트를 선언했다.
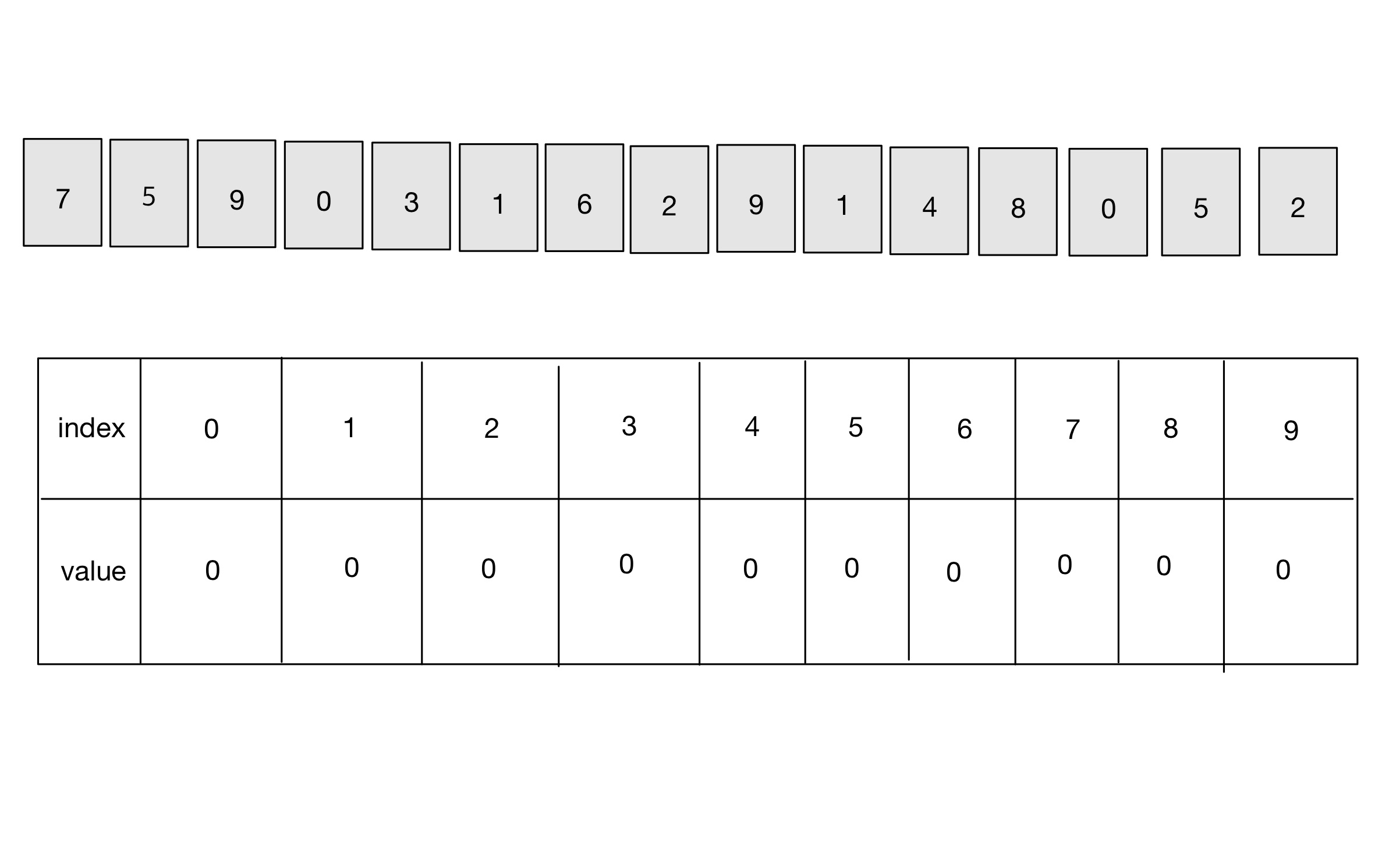
- 그 다음 데이터를 하나씩 확인하며, 데이터의 값과 동일한 인덱스의 데이터를 1씩 증가시키면 계수 정렬이 완료된다.
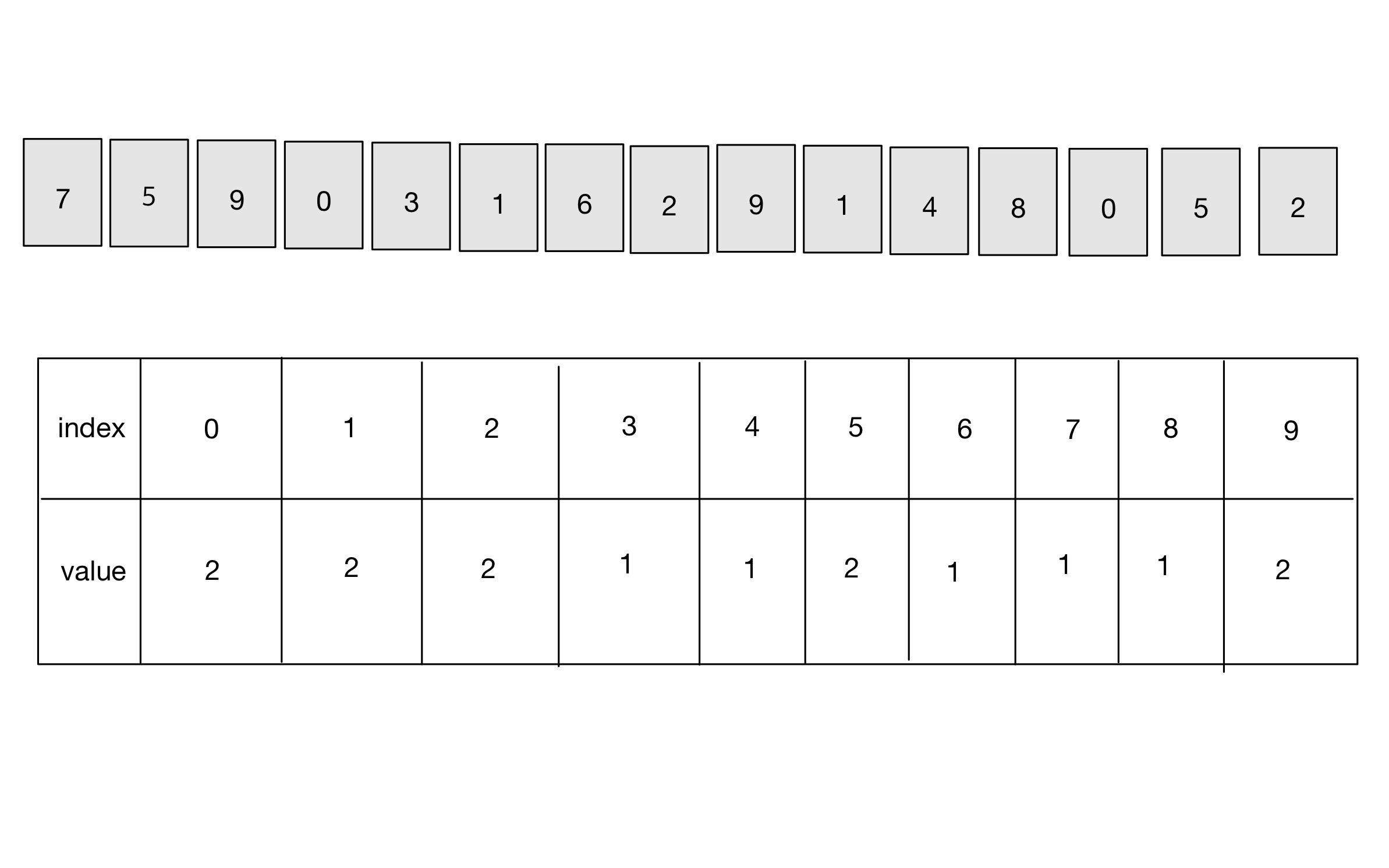
- 그 후, 리스트의 첫 번째 데이터부터 하나씩 그 값만큼 인덱스를 출력하면 된다.
0 -> 0 -> 1 -> 1 -> 2 -> 2 -> 3 -> 4 -> 5 -> 5 -> 6 -> 7 -> 8 -> 9 -> 9
코드(Java)
int n = 15;
// 모든 원소의 값이 0보다 크거나 같다고 가정
int[] arr = {7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2};
// 모든 범위를 포함하는 배열 선언(모든 값은 0으로 초기화)
int[] cnt = new int[MAX_VALUE + 1];
for (int i = 0; i < n; i++) {
cnt[arr[i]] += 1; // 각 데이터에 해당하는 인덱스의 값 증가
}
for (int i = 0; i <= MAX_VALUE; i++) { // 배열에 기록된 정렬 정보 확인
for (int j = 0; j < cnt[i]; j++) {
System.out.print(i + " "); // 띄어쓰기를 기준으로 등장한 횟수만큼 인덱스 출력
}
}Java 정렬 라이브러리
Array.sort(arr);- 내부적으로 DualPivotQuickSort.sort() 호출한다. 최악의 시간 복잡도를 갖게하는 많은 데이터 셋들에 대해서도 O(nlogn)을 제공한다.
💡그렇다면 언제 무엇을 써야할까?
코딩테스트에는 정렬 알고리즘이 사용되는 경우를 일반적으로 3가지로 나타낼 수 있다.
1. 정렬 라이브러리로 풀 수 있는 문제 : 단순히 정렬 기법을 알고 있는지 물어보는 문제로 기본 정렬 라이브러리의 사용 방법을 숙지하고 있으면 어렵지 않게 풀 수 있다.
2. 정렬 알고리즘의 원리에 대해서 물어보는 문제 : 선택 정렬, 삽입 정렬, 퀵 정렬 등의 원리를 알고 있어야 풀 수 있다.
3. 더 빠른 정렬이 필요한 문제 : 퀵 정렬 기반의 정렬 기법으로는 풀 수 없으며 계수 정렬 등의 다른 정렬 알고리즘을 이용하거나 문제에서 기존에 알려진 알고리즘의 구조적인 개선을 거쳐야 풀 수 있다.
문제에서 별도의 요구가 없다면 단순히 정렬해야하는 상황에서는 기본 정렬 라이브러리를 사용하고, 데이터의 범위가 한정되어 있으면 더 빠르게 동작해야 할 떄는 계수 정렬을 사용하자.
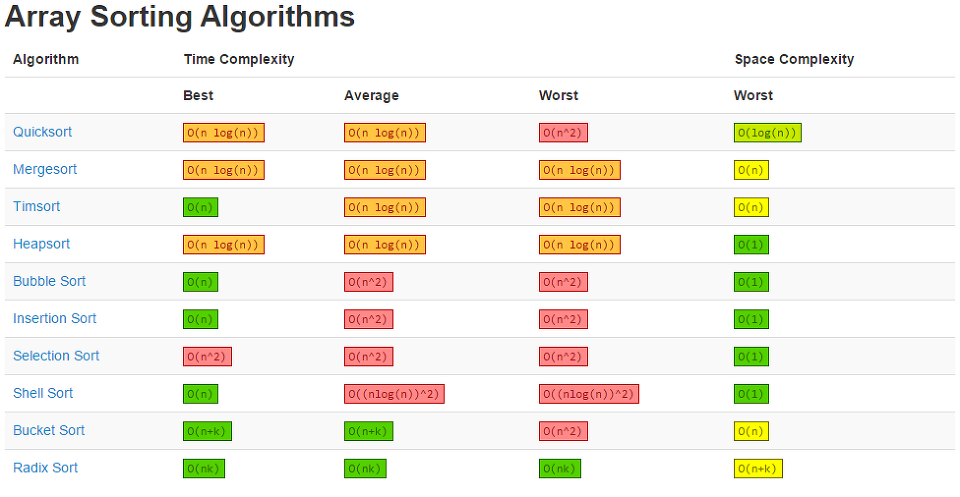
정렬 시간 복잡도 한눈에 보기