
CPU 스케줄링
운영체제는 백그라운드에서 실행되는 특별한 프로그램이라고 생각할 수 있다. 운영체제의 목적은 프로세스간 원활하게 동작할 수 있도록 지원해주는 것이다. 프로그램이 실행되면 스레드가 CPU 자원을 선점하게 되어있다. 그렇다면 OS에서 스레드의 작업 분배를 해주기 위해 스케줄링을 한다. 스레드에 대한 스케줄링은 저수준 스케줄링에 해당하게 된다.

중간 수준 스케줄링은 작업 스케줄링이라고도 하는데 여기서 작업은 Job의 단위로 볼 수 있다. Job이란 여러개의 스레드를 하나로 묶은 작업단위다.
고수준 스케줄링은 전체적인 시스템의 부하 상태를 스케줄링한다. 어플리케이션 또는 운영체제와 같은 큰 단위를 기준으로 스케줄링한다고 생각하면 된다. 선점형(Preemtive)/비선점형(Non-Preemtive) 스케줄링이라는 용어를 잘 익혀보자. OS가 CPU를 뺏어서 사용하는 방식을 선점형 스케줄링이라고 한다. 비선점은 정반대 상황이다, 하나의 프로세스가 CPU를 점유하면 다른 프로세스는 CPU를 뻇을 수 없다. 보통은 선점형으로 사용이 되고, 특수한 상황에서만 비선점형으로 스케줄링을 실행한다.
프로세스 / 스레드 별로 우선순위를 정할 수 있는데, 보통은 5단계로 분류된다. 재밌는 점은, 리액트의 스케줄러 작업 우선순위도 5단계로 나뉜다는 것이다. 순위가 높은 프로세스로는 미디어 관련 작업이 있고(GUI), 순위가 낮은 프로세스로는 백그라운드 프로그램이 있다(압축해제). 느린 I/O를 사용할 땐 주의해야하는데, wait와 같은 방식으로 CPU를 오랫동안 선점을 하고있어서, 성능에 차질이 일어날 수 있다. 그래서 비동기 처리를 잘 해야한다.
서버는 대표적인 I/O가 기본적으로 많은 작업 프로세스다. 대기하는 시간이 많기에, 백그라운드로 진행되는 경우가 일반적이다.
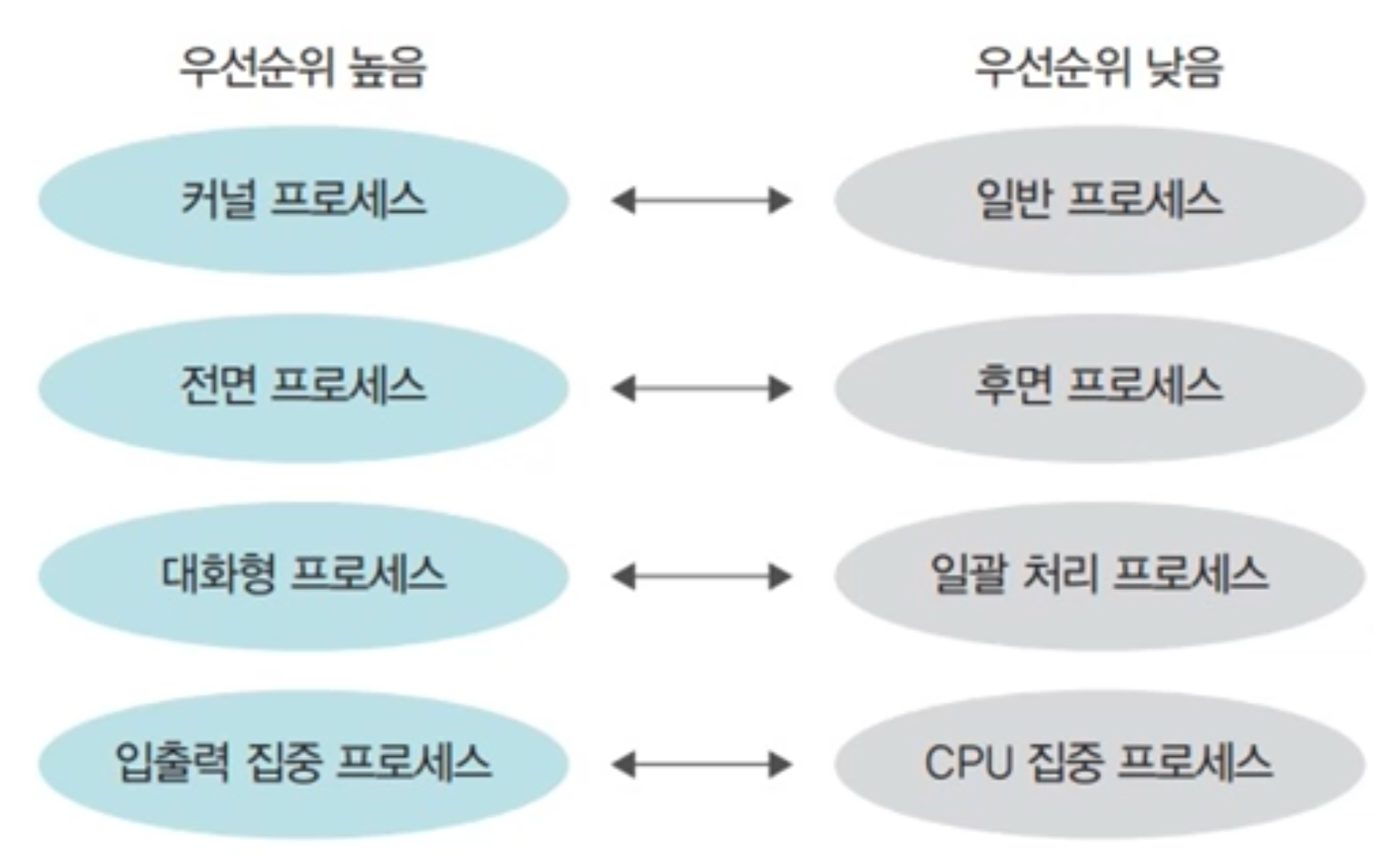
IOCP -> Kernel I/O이기에, 우선순위가 가장 높은 프로세스로 처리가되어, 유저입장의 모든 I/O의 빠른성능을 보장해준다.
Process 간 통신
IPC(inter process communication)은 운영체제에서 매우 중요한 내용이고, 면접에서도 잘 나오는 문제다. 프로세스는 독립적인 메모리 공간이 주어진다. 경계가 있다는 건 다른 프로세스의 접근에 대해 차단할 수 있다는 것이다. 접근 차단은 OS가 보장해주는데, 이는 외부에서 특정 프로세스의 메모리 내역을 변경하는 상황을 방지해준다. 만일 OS를 뚫어서 특정 공간에 대해 접근할 수 있다면, 그건 고급 해킹영역이다.
메모리는 RAM+File(2차)의 형태로 사용이 되는데, File은 Stream과 밀접한 관계가 있다. FIle은 보통 HDD에 저장되어있는데, Head부분의 메모리 size가 0이다. 그 위에 write를 하면, 메모리 공간이 증가한다. 그에 반면에 Memory형식은 OS가 매우 엄격하게 메모리 크기 할당을 관리하게된다.
IPC가 네트워크 단위로 확장하게 된다면 그걸 소켓과 같은 방식이라고 생각하면 된다. RPC(Remote Processer Call)이라는 기술은 HTTP3 덕분에 최근들어 다시 급상하고 있다.
전역변수 또한 RAM 메모리를 사용한다는 것이라 Shared Memory 영역에 들어가있다. 두 프로세스가 어떠한 값에 대한 데이터를 특정 주소값을 참조하는 식으로 들고있는 상황에서, 두 주소값이 서로 일치할 때 Shared Memory라고 부른다.
프로세스A가 Shared 메모리에 값을 변동하고(RW) wait하고 있는 프로세스 B에게 Signal을 보내면 프로세스 B가 다시한번 주소 값을 따라 RW을 시도한다.
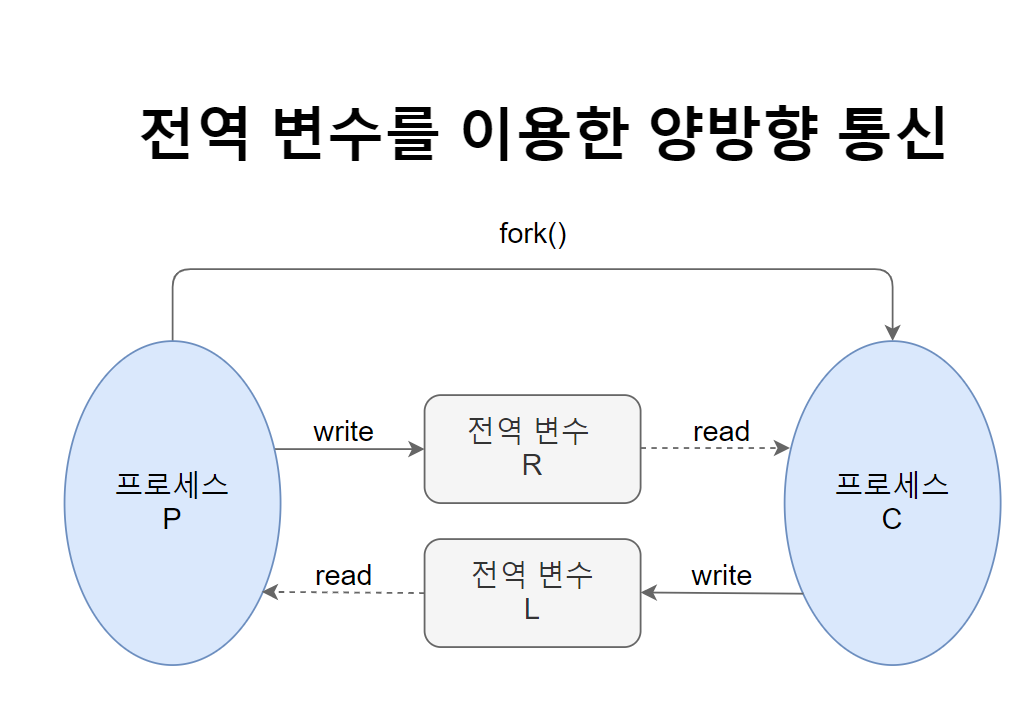
이때 프로세스와 Shared Memory의 메모리 공간은 고정되어있다. 이는 File과 반대되는 방식이다.
정리를 해보자면, IPC를 하는 방법은 아래와 같다:
Memory
Pipe (File)
Socket
RPC
Registry (윈도우 한정)공유 자원과 임계구역
여러개의 스레드가 동시에 하나의 프로세스 자원에 접근하는 것 처럼, 여러개를 동시에 실행 할 땐 경쟁조건을 고려해야한다. 코드 한 구문이 CPU의 관점에선 1개의 명령이 아닐 수 있다. 한줄 연산에서도 여러가지 연산이 포함되어 있기에, 한 구문에 한개의 명령을 보장받을 수 있는가가 원자성에 대한 내용이다.
동시적 접근에 의해 발생할 수 있는 문제(동시성)에 대해 원자성을 부여하여, 동시에 발생할 수 없는 문제로 전환하여 오류를 사전 차단할 수 있다.
코드를 실행 할 때 만약 하나의 스레드가 구문을 실행하는 도중에 다른 스레드의 연산에 의해 연산과정 사용되는 변수 값이 변동 된다면, 해당 코드는 정상적인 실행을 보장받을 수 없다. 이런 현상을 방지하기 위해 우리는 Lock이라는 방식으로 연산과정의 원자성을 보장해준다.
임계구간은 최소화를 무조건해줘야한다. 사실상 임계구간을 최대한 없에는 것이 제일 좋다, 아니면 락이 걸릴 위험이 있다.
임계구역 해결 방법
여러개의 스레드의 임계구역 문제를 해결해주기 위해서 전역변수를 사용할 수 있다. 기능구현을 할 땐 UI/Service/Data Structure로 나뉠 수 있는데, 이 때 공통적으로 사용하는 전역변수에 대해서 임계구역문제가 생길 수 있다. 네트워크의 연결은 비동기적이며 불안정하다.
어떤 기능을 조작할 때 추가하는 것보다 삭제하는 조작이 자료구조보다 약 3배 정도 복잡하게 진행된다고 한다. 특히 서버에서 DB의 삭제를 실시한다면, 클라이언트 단에서 값을 조회하다가 오류를발생 할 수 있다. 그렇기에 조회 / 검색이라는 기능을 사용할 때 동시에 추가 또는 삭제의 조작을 하지 않도록 임계구역을 설정해줘야한다. while 문으로 Lock에 대한 기능을 구현한걸 SpinLock이라고 부른다, CPU점유율이 높기에, 운영체제에서 제공하는 SpinLock은 어느정도 성능 최적화가 되어있어 CPU점유율 100%까지 가진 않는다.
결론적으로 스레드 또는 프로세스의 동기화를 이루기 위해선 Queue를 사용해야한다. Queue를 이용해서 동기성 문제를 해결할 수 있기에, 동기화 문제에는 꼭 Queue가 나올 수 밖에 없다.
브라우저의 렌더링 엔진을 생각해보면, render queue, callback queue 등 많은 종류의 queue를 만나볼 수 있는데, 이 또한 동기성 문제를 해결하기 위해 만들어 진 자료구조라는 것을 알 수 있다.
