1. 데이터 모델링의 이해
1.1. 데이터 모델링의 이해
1.1.1. 데이터 모델의 이해
1.1.2. Entity
: 업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것(Thing)
1.1.2.1. 특징
- Unique Identifier에 의해 식별이 가능
- 영속적으로 존재하는 2개 이상의 Instance의 집합
- 반드시 2개 이상의 Attributes가 존재
- 다른 Entity와 최소 1개 이상의 관계가 존재
- 해당 업무에서 필요하고 관리하고자 하는 정보임
- 업무 프로세스에 의해 이용됨
1.1.2.2. 분류
1.1.2.2.1. 유무형에 따른 분류
- 유형(Tangible) Entity : 물리적 형태 (Ex: 인적 정보, 물품 정보)
- 개념(Conceptual) Entity : 개념적 정보 (Ex: 서비스)
- 사건(Event) Entity : 업무 수행 중 발생 (history(ex: 방문기록))
1.1.2.2.2. 발생 시점에 따른 분류
- 기본/키(Fundamental/Key) Entity
: 그 업무에 원래 존재하는 정보. 다른 Entity의 관계로 생성되지 않고 독립적으로 생성가능한 Entity (ex: 인적 정보, 물품 정보)
※ 보통 다른 Entity의 부모 Entity
※ 자신의 Unique Identifier을 가짐. - 중심(Main) Entity
: 기본 Entity로 부터 발생되어 업무에 있어 중심역할을 하는 Entity
(ex: 계약, 청구, 주문, 매출 등)
※ 다른 Entity와의 관계로 많은 행위 Entity를 생성 - 행위(Active) Entity
: 2개 이상의 부모 Entity의 관계로 발생.
※ 자주 바뀌거나 양이 증가
(ex: 주문 목록, 사원 변경 이력)
1.1.2.3. Entity 명명
- 가능하면 현업업무에서 사용하는 용어 사용
- 약어는 되도록 사용 X
- 단수명사 사용
- Entity의 생성 의미대로 부여
1.1.3. 속성 (Attribute)
: 업무에서 필요로 하고 의미상 더 이상 분리되지 않는 Entity를 설명하는 인스턴스의 구성요소.
1.1.3.1. 특징
- 한 개의 속성은 반드시 한 개의 속성값 만을 가짐
- 정규화 이론에 근간하여 정해진 main Identifier에 함수적 종속성을 가져야 함.
- 해당 업무에서 필요로하고 관리하고자 하는 정보임.
1.1.3.2. 분류
1.1.3.2.1. 특성에 따라
- 기본(Basic) 속성
: 코드성 데이터, 식별자, 그리고 다른 속성을 계산하거나 영향을 받아 생성된 속성을 제외한 모든 속성
※ 업무로부터 추출한 모든 속성이 여기에 해당하며 엔터티에 가장 일반적이고 많음. - 설계(Designed) 속성
: 업무상 필요한 데이터 이외에 데이터 모델링을 위해, 업무를 규칙화하기 위해 속성을 새로 만들거나 변형하여 정의하는 속성
※ 보통 코드성 속성(속성 변형)이나 식별자 속성(새로 정의)이 이에 속함. - 파생(Derived) 속성
: 다른 속성에 영향을 받아 발생하는 속성
※ 흔히 계산된 값들이 해당
※ 다른 속성에 영향을 받기 때문에 프로세스 설계 시 데이터 정합성을 유지하기 위해 유의해야 할 점이 많음
※ 가급적 적게 정의하는 것이 좋음
1.1.3.2.2. Entity 구성 방식에 따라
- PK(Primary Key) : 자신의 Entity 식별자를 부여하는 속성
- FK(Foreign Key) : 다른 Entity 식별자를 부여하는 속성
- 일반 속성: PK, FK를 제외한 속성
1.1.3.2.3. 세부 의미를 쪼갤 수 있는지에 따라
- 복합(Composite) 속성
: 속성값에서 여러가지로 쪼갤 수 있는 속성
ex) 주소(나라, 도, 시, 등등으로 쪼갤 수 있음), 시간(년도, 월, 일, 등등으로 쪼갤 수 있음) - 단순(Simple) 속성
: 속성값에서 세부 의미를 쪼갤 수 없는 속성
ex) 나이, 성별 등등
1.1.3.2.4. 동일한 성질의 값의 갯수에 따라
- 단일값(Single-Valued) 속성
: 속성값이 1개인 경우 (Ex: 주민번호) - 다중값(Multi-Valued) 속성
: 속성값이 여러개일 경우 (Ex: 전화번호, 주소 등)
※ 1차 정규화를 하거나 별도의 Entity를 만들어 관계로 연결해야 함.
1.1.3.3. 도메인
: 속성에 대한 데이터타입, 크기, 제약사항 지정
1.1.3.4. 속성의 명명
- 서술식 속성명 X
- 약어 사용 X
- 전체 데이터 모델에서 유일성을 확보할 수 있는 이름 O
- 해당 업무에서 사용하는 이름
1.1.4. 관계 (Relationship)
: Entity의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태, Relationship Paring의 집합
Paring: 엔터티 안에 인스턴스가 개별적으로 관계를 가지는 것
Relationship Paring: 엔터티내에 인스턴스와 인스턴스사이에 관계를 가지는 것
1.1.4.1. 분류
- 존재에 의한 관계
- 행위에 의한 관계
UML에서의 관계
Unified Modeling Language
- 연관(Association) 관계: 항상 이용하는 관계로 존재적 관계 ex) 소속
- 의존(Dependence) 관계: 상대방 행위에 의해 발생하는 관계 ex) 주문
1.1.4.2. 표기
-
관계명(Mambership)
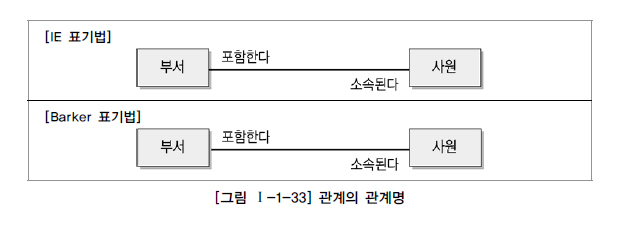
-
관계차수(Cardinality)
- 1:1

- 1:M
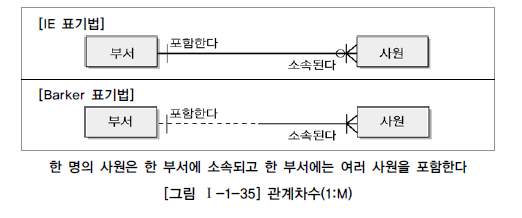
- M:N
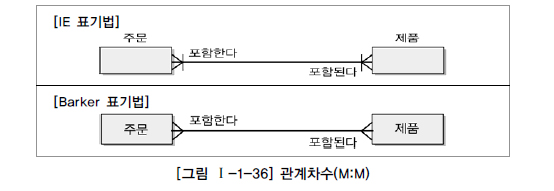
-
관계 선택 사양 (Optionality)
- 필수관계
- 선택관계
1.1.4.3 체크사항
- 2개의 Entity 사이에 관심있는 연관규칙 존재함?
- 2개의 Entity 사이에 정보의 조합 발생함?
- 업무기술서, 장표에 연결관계에 대한 규칙이 서술되어 있음?
- 업무기술서, 장표에 관계연결을 가능하게 하는 동사(Verb)가 있음?
1.1.5. 식별자 (Identifier)
1.1.5.1. 특징
- 유일성: Main Identifier에 의해 모든 Instance들이 유일하게 구분
- 최소성: Main Identifier를 구성하는 모든 속성의 수는 유일성을 만족하는 최소의 수가 되어야 함.
- 불변성: Identifier의 값은 변하면 안됨
- 존재성: Identifier은 반드시 값이 있어야 함.
1.1.5.2. 분류
대표성 여부
- 주식별자: O (다른 Entity와 연결 O)
- 보조식별자: X (다른 Entity와 연결 X)
Entity 내에서 스스로 생성?
- 내부 식별자: O
- 외부 식별자: 다른 Entity로부터 받아옴
속성의 수
- 단일 식별자
- 복합 식별자
대체 여부
- 본질 식별자: 업무에 의해 만들어지는 식별자
- 인조 식별자: 업무적으로 만들어지진 않으나 원조 식별자가 복잡한 구조라 만들어진 식별자
1.2. 데이터 모델과 성능
1.2.1. 정규화와 성능
1.2.2. 반정규화와 성능
1.2.3. 대용량 데이터에 따른 성능
1.2.4. DB구조와 성능
1.2.5. 분산 DB 데이터에 따른 성능
2. SQL 기본 및 활용
2.1. SQL 기본
2.1.1. 관계형 DB의 개요
DB: 데이터를 일정한 형태로 저장해 놓은 것
DBMS(DataBase Management System): 데이터의 효율적인 관리 및 손상 예방, 복구 등의 기능을 수행하는 시스템
2.1.1.1. SQL
:관계형 데이터베이스에서 데이터 정의, 데이터 조작, 데이터 제어를 하기 위해 사용하는 언어
2.1.1.2. table
: DB 기본 단위. 데이터를 저장하는 Object
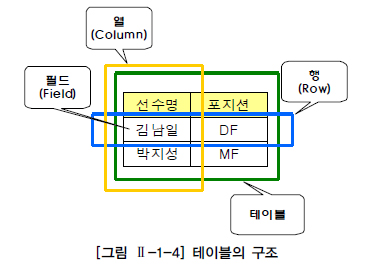
정규화(Normalization)
: 테이블을 분할하여 데이터의 불필요한 중복을 줄이는 것
※ 데이터의 정합성 확보와 데이터 입력/수정/삭제시 발생할 수 있는 이상현상(Anomaly)을 방지하기 위해 정규화는 관계형 데이터베이스 모델링에서 매우 중요한 프로세스
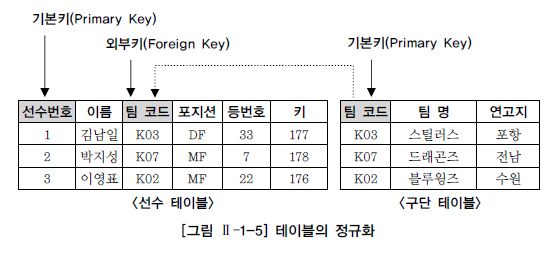
2.1.2. DDL
: Data Definition Language
2.1.2.1. Data type
- Oracle
#### NUMBER ####
#P: 소수점 이하를 포함한 전체 자릿수
#S: 소수점 자릿수
NUMBER(P, S) #가변숫자
# P: [1,38], default: 38
#S [-84, 127], default=0
#최대 22byte
FLOAT(P)
# P: [1, 128], default = 128
# 최대 22byte
BINARY_FLOAT
# 32bit 부동 소수점 수
BINARY_DOUBLE
# 64bit 부동 소수점 수
#### STRING ####
CHAR(n) #길이 n개 고정. (n개에서 빈 만큼 공백으로 다 채워버림)
VARCHAR2(n) #길이 n개 까지의 가변 길이
#### DATE ####
DATE
# year, month, day, hour, minute, second 까지
# BC 4712-01-01 ~ 9999-12-31
# 더 많이 씀
TIMESTAMP
# year, month, day, hour, minute, second, milisecond- mssql
#### Number ####
BIT
TINYINT #1byte
SMALLINT #2byte
INT #4byte
BIGINT #8byte
FLOAT(n)
# if 1<=n<=24 n= 24; else if 25<=n<=53, n=53
REAl
# FLOAT(24)랑 같음
DECIMAL(P, S) #Oracle의 NUMBER(P, S)랑 비슷
NUMERIC(P, S) #위와 동일
#### STRING ####
CHAR(n) #고정길이 (n) 문자형
VARCHAR(n) #가변길이(<=n) 문자형
#### DATETIME ####
DATETIME
SMALLDATETIME
2.1.2.2. CREATE
CREATE TABLE table_name (
column_name1 data_type [constraint],
column_name2 data_type,
CONSTRAINT constraint_name contraint_type(columns)
);(1) table_name
- 객체를 의미할 수 있는 적절한 단수형 이름을 추천
- 다른 table 이름과 겹치면 안됨.
- A-Z,a-z,0-9,_,$,# 만 가능
(2) column_name
- 다른 column과 이름이 겹치게 할 수 없음
- A-Z,a-z,0-9,_,$,# 만 가능
(3) 제약조건(Constraint)
- PRIMARY KEY
:(= UNIQUE && NOT NULL) - UNIQUE
: 중복값 금지 - NOT NULL
: Null값 금지 - CHECK(condition)
: condition이 False인 값 금지 - FOREIGN KEY
- in Oracle
REFENRENCES table(column)
- in mssql
FOREIGN KEY REFERENCES table(column) - DEFAULT value
2.1.2.3. ALTER
#add column
ALTER TABLE table ADD(new_column_name data_type); #oracle
ALTER TABLE table ADD new_column_name data_type; #mssql
#delete column
ALTER TABLE table DROP COLUMN column;
#change constraint, data type
## oracle
ALTER TABLE table MODIFY (column data_type constraint, ...);
## mssql
ALTER TABLE table ALTER (column data_type constraint, ...);
/*
주의점
- 칼럼의 범위를 늘릴 수 있지만 줄일 수는 없음
- 예외: row가 없거나 field값이 null만 있을 경우
- null값만 가지고 있으면 data type 변경 가능
- default값을 변경하면 그 이후에 발생하는 row만 적용
- 해당 column에 null이 있으면 NOT NULL 불가
*/
#change column name
## Oracle
ALTER TABLE table RENAME COLUMN column TO new_name;
## mssql
SP_RENAME column, new_name, 'COLUMN';
SP_RENAME table.column, new_name;
#delete contrains
ALTER TABLE table DROP CONSTRAINT constraint_name
#add constraint (if column haven't constraint)
ALTER TABLE table ADD CONSTRAINT constraint_name2.1.2.4. RENAME
RENAME TABLE table_name TO new_name;
SP_RENAME table_name, new_name;2.1.2.5. DROP
#table 삭제
DROP TABLE table2.1.2.6. TRUNCATE
#table record 삭제
TRUNCATE TABLE table;2.1.3. DML
: Data Manipulation Language; table의 data를 입력, 수정, 삭제, 조회하는 명령어
2.1.3.1. INSERT
#row 추가. 각 column에 해당하는 value가 들어간다.
INSERT INTO table (columns) VALUES (values);2.1.3.2. UPDATE
#condition에 해당하는 record의 field값이 value로 변경 ※ condtion이 없으면 다 변경
UPDATE table SET column=value WHERE condition;2.1.3.3. DELETE
# condition에 해당하는 record를 제거한다.
DELETE [FROM] table WHERE condtion;2.1.3.4. SELECT
어떤 목차보다 자신있어서 설명 안함 어짜피 시험 끝나면 이 포스트 삭제할거임 ㅋ
Wildcard
*, % : all
_ : one
2.1.3.5. Operation
Concat
'str1 ' || 'str2 ' || 'str3' #oracle
'str1 ' + 'str2 ' + 'str3' #mssql
#>>> 'str1 str2 str3'2.1.4. TCL
: Transaction Control Language
2.1.4.1. Transaction
: 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작
(대충 내가 이해한 대로 말해보자면 DML을 통해서 데이터를 편집하면 바로 적용이 되는게 아니라 따로 저장이 되는데 그 따로 저장되는 걸 말하는 거 같음. git인데 한번 COMMIT하면 그 전 버전들은 모두 날라가는거 생각하면 편할 듯. 아니면 save 눌러야 저장할 수 있는 게임은 save안누르고 종료하면 그냥 데이터 날라가는데 이 때 아직 save 안한 게 Transaction이라 생각해도 될듯)
특성
-
원자성(atomicity): Transaction에 있는 연산이 모두 성공적으로 실행되던지 다 안되던지
-
일관성(consistency): Transaction 실행 전에 데이터에 이상이 없다면 실행 후에도 없어야 함.
-
고립성(isolation): Transaction 실행 도중에 다른 Transaction의 영향을 받아 잘못된 결과 만드면 안됨
-
지속성(durability): Transaction이 성공적으로 수행되면
-
Oracle
AUTO COMMIT이 옵션이다. -
mssql
기본적으로 AUTO COMMIT이라 명령어를 Transaction에 넣으려면
BEGIN TRAN ~ ;
BEGIN TRANSACTION ~를 적고 MDL을 실행해야 한다.
2.1.4.2. COMMIT
DML을 통해 편집된 data들에 문제가 발생하지 않는다고 판단했을 때 확정짓는 명령어.
확정하면 그 이전 데이터로 돌아갈 수 없음
COMMIT [TRANSACTION]※ mssql은 AUTO COMMIT이라 명령어가 성공하면 COMMIT되고 실패하면 ROLLBACK함
2.1.4.3. ROLLBACK
: Transaction 없애기
게임으로 치면 save 안하고 그냥 종료하기 같은거
ROLLBACK [TRANSACTION]2.1.4.4. SAVEPOINT
: 이미 COMMIT 된 부분부터 Transaction부분 중에서 ROLLBACK 했을 때 돌아갈 지점 정하는거
※ 일부 tool에서는 지원 X
SAVEPOINT save_point_name; #Oracle
SAVE TRANSACTION save_point; #mssql
SAVE TRAN save_point; #mssql
#ROLLBACK할 떄
ROLLBACK TO save_point; #oracle
ROLLBACK TRANSACTION save_point; #mssql
ROLLBACK TRAN save_point; #mssql
※ COMMIT 하기 전에 DDL 실행하면 Transaction 전으로 자동 COMMIT
2.1.5. WHERE

2.1.6. FUNCTION



※ ''는 Oracle과 mssql이 같다는 것
| 분류 | Oracle | mssql | 의미 or 예시 |
|---|---|---|---|
| STRING | LOWER(str) | '' | 대문자->소문자 |
| UPPER(str) | '' | 소문자->대문자 | |
| ASCII(str) | '' | 문자->ASCII code | |
| CHR(ASCII code) | CHAR(ASCII code) | ASCII code -> 문자 | |
| CONCAT(str1, str2) | '' | 문자열 붙이기 | |
| SUBSTR(str, n, m) | SUBSTRING(str, n, m) | str n번째 문자부터 m글자 추출(m 생략시 끝까지) | |
| LENGTH(str) | LEN(str) | 문자열 길이 | |
| LTRIM(str[, c]) | '' | 왼쪽부터 연속되는 c(default=' ') 제거 | |
| RTRIM(str[, c]) | '' | LTRIM 반대 방향으로 | |
| TRIM(str |
2.1.7. GROUP BY, HAVING
2.1.8. ORDER BY
2.1.9. JOIN
EQUI JOIN
SELECT table1.columns, table2.columns FROM table1, table2 WHERE table1.fk=table.pkNONEQUI JOIN
pk fk가 아니라 범위나 부등식으로 조건 따져서 JOIN하는거
2.2. SQL 활용
2.2.1. 표준 JOIN
2.2.2. 집합 연산자
2.2.3. 계층형 질의
2.2.4. 서브쿼리
2.2.5. 그룹함수
2.2.6. 윈도우 함수
2.2.7. DCL
: Data Control Language
2.1.+.1. GRANT
2.1.+.2. REVOKE
2.2.8. 절차형 SQL
2.3. SQL 최적화 기본 원리
2.3.1. 옵티마이저와 실행 계획
2.3.2. Index 기본
2.3.3. JOIN 수행 원리
참고
https://dataonair.or.kr/db-tech-reference/d-guide/sql/
https://selgii.tistory.com/44
