
huggingface_sagemaker_pipeline
K-항공사의 고객 설문 데이터를 이용하여 감정분석 모델을 HuggingFace를 이용해 개발했습니다.
MLOps가 다들 좋다고 얘기하지만 정작 이를 실제 서비스에 배포하려면 정보가 매우 적습니다.
이 모델을 이용하여 MLOps Pipeline을 구축하였고 이 과정에서 겪은 시행착오를 공유하겠습니다.
현재 구축한 상태는 크게 전처리-학습-모델 업로드이며 실제 모델을 Serving 하는 방법은 추후에 공유하겠습니다.
Overview
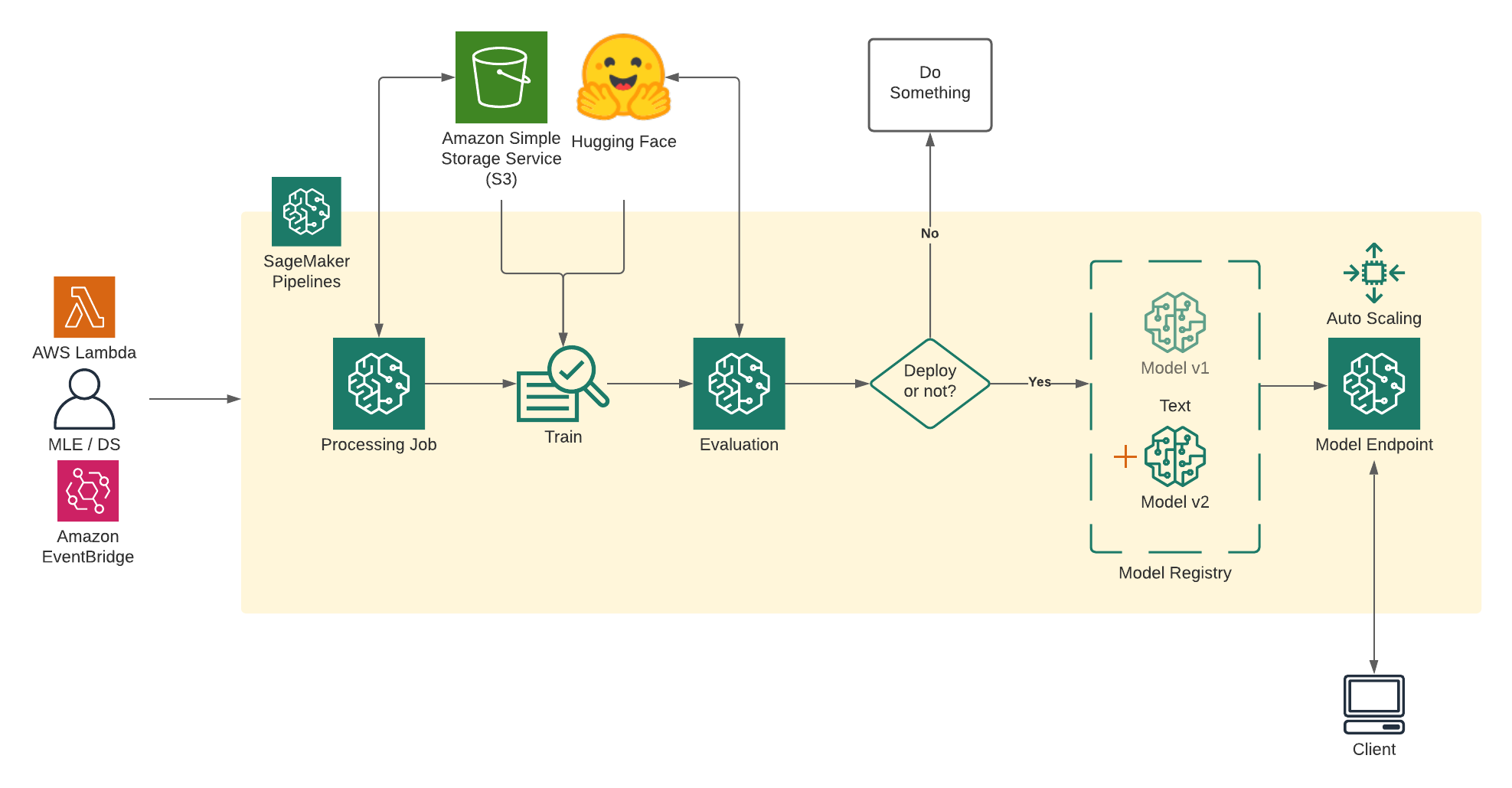
Pipeline
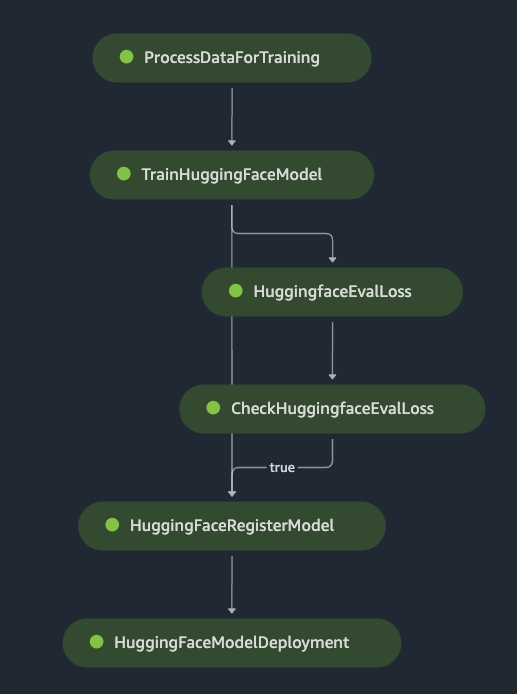
Prepare
- Preprocess dockerfile
- Inference dockerfile(cpu or cuda) sagemaker-pytorch-inference-toolkit
- Python Script (train.py, evaluation.py, inference.py)
Sagemaker Notebook
Sagemaker Environment variables
Some tips (To understand the path)
in ProcessingStep
- inputs (List type)
source(S3) -> destination(container instance)- outputs (List type)
source(container instance) -> destination(S3)in TrainingStep
- inputs (Dict type)
Only suport train, test variables
source(Your sagemaker S3 URI, made at the processing step) -> destination(container instance)Also, When the save the model, Use it trainer.save_model(os.environ["SM_MODEL_DIR"])
then you can check the model saved at sagemaker s3
Custom script processing step
from sagemaker.processing import ScriptProcessor
processing_output_destination = 'YOUR S3 PATH'
custom_processor = ScriptProcessor(
image_uri='YOUR ECR URI',
instance_type='ml.c5.2xlarge',
instance_count=1,
base_job_name=base_job_prefix + "/preprocessing",
sagemaker_session=sagemaker_session,
role=role,
command = ["python3"])
step_process = ProcessingStep(
name="ProcessDataForTraining",
cache_config=cache_config,
processor=custom_processor,
job_arguments=["--bucket",'hg.sage',
"--file_name", 'train/train.csv'],
inputs=[
ProcessingInput(
input_name="train.csv",
source=f"{processing_output_destination}/train",
destination="/opt/ml/processing/input/train"
),
ProcessingInput(
input_name="test.csv",
source=f"{processing_output_destination}/test",
destination="/opt/ml/processing/input/test"
),
],
outputs=[
ProcessingOutput(
output_name="train",
destination=f"{processing_output_destination}/train",
source="/opt/ml/processing/train",
),
ProcessingOutput(
output_name="test",
destination=f"{processing_output_destination}/test",
source="/opt/ml/processing/test",
),
],
code=f'{YOUR SOURCE PATH}/Preprocess.py',
)Custom script inference step
To use the custom inference, You must follow the rules.
Sagemaker inference follow the model.tar.gz
model.tar.gz
├── /code
│ └── inference.py
├── tokenizer.json
├── tokenizer_config.json
├── config.json
├── vocab.txt
└── pytorch_model.binS3 Directory
S3
├── /code
│ └── inference.py
├── /train
│ ├── train.csv
│ ├── model.bin(optional)
│ ├── vocab.txt(optional)
│ └── config(optional)
└── /test
└── test.csv
일단 해보자 !