
- 명단공개자의 일부 또는 전부를 사용하여 특정인의 명예를 훼손할 경우에는 형사상 명예훼손죄로 처벌을 받거나 민사상 손해배상 책임을 질 수 있습니다.
국세청은 고액 상습체납자 명단을 홈페이지에 게시하여 공개하고 있습니다. 다만, 개인이 이 정보를 통해 체납자의 명예를 훼손시키는 경우 문제가 발생하니 조심하세요 !
밤에 잠이안와서 심심해서 해본 데이터 수집과 분석
1장. 크롤링
위 링크를 접속하면 개인 고액 체납자의 목록을 확인할 수 있는데,
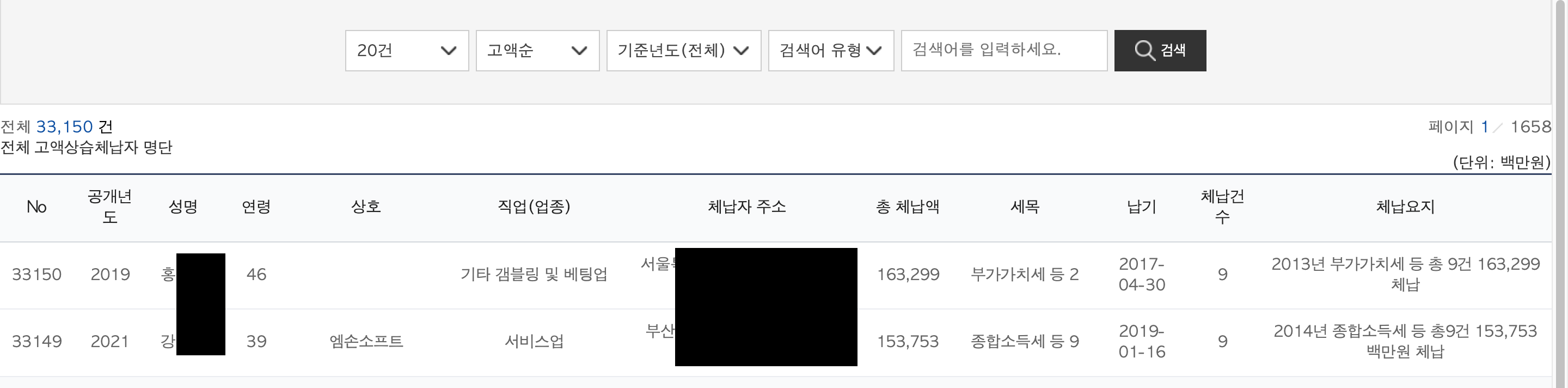
무려 20개씩 1658페이지 까지 구성되어 있어 도구의 힘을 빌려야 수집할 수 있는 정보였습니다.
사실 BS4를 활용해서 크롤링을 진행하려 했는데, 페이지 이동이 자유롭지 못하여 Selenium을 통해 클릭 이벤트를 활용하여 수집하는 방식을 활용했습니다.
df = pd.DataFrame(columns = ['No','공개년도','성명','연령',
'상호','직업(업종)','체납자 주소',
'총 체납액','세목','납기','체납건수','체납요지'])테이블의 컬럼은 총 12개로 구성되어 있어 위와 같이 데이터프레임을 할당했습니다.
for click in range(1, 1659):
for i in range(1, 20+1):
inputs = []
for j in range(1, 12+1):
inputs.append(driver.find_element_by_xpath(f'//*[@id="wrap"]/div/div[2]/table/tbody/tr[{i}]/td[{j}]').text)
df = df.append(pd.DataFrame([inputs], columns = df.columns.to_list()))
if click == 10:
driver.find_element_by_xpath(f'//*[@id="wrap"]/div/div[2]/form/div/a[4]').click()
elif click%10 == 0:
driver.find_element_by_xpath(f'//*[@id="wrap"]/div/div[2]/form/div/a[5]').click()
else:
driver.find_element_by_xpath(f'//*[@id="wrap"]/div/div[2]/form/div/div/a[{click%10}]').click()크롤링을 진행하며 불편했던 사항은 10페이지에서 다음페이지를 이동하기 위해 버튼의 클릭이벤트를 할당해야하는데 1-10번대의 클릭 이벤트 xpath와 20페이지 이상의 클릭버튼 xpath가 상이하여 문제가 발생했는데 다행히 처음 10페이지만 달랐기에 무난히 클릭이벤트를 사용했습니다.
2장. 분석
분석 내용은 사실 별거 없었습니다..
df.dtypes
---
No int64
공개년도 int64
성명 object
연령 float64
상호 object
직업(업종) object
체납자 주소 object
총 체납액 object
세목 object
납기 object
체납건수 float64
체납요지 object
dtype: object데이터 타입에서 총 체납액 부분이 연속형 변수인데 '1,000'과 같이 구분자가 포함되어 Object로 인식되어 삭제하여 int타입으로 변환해주었습니다.
df['총 체납액'].replace('[^0-9]','', regex=True, inplace=True)
df = df.astype({'총 체납액' : 'int'})
df.info()
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 33150 entries, 0 to 33149
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 No 33150 non-null int64
1 공개년도 33150 non-null int64
2 성명 33150 non-null object
3 연령 33099 non-null float64
4 상호 22791 non-null object
5 직업(업종) 26200 non-null object
6 체납자 주소 33150 non-null object
7 총 체납액 33150 non-null int64
8 세목 33150 non-null object
9 납기 33150 non-null object
10 체납건수 33145 non-null float64
11 체납요지 33150 non-null object
dtypes: float64(2), int64(3), object(7)
memory usage: 3.0+ MB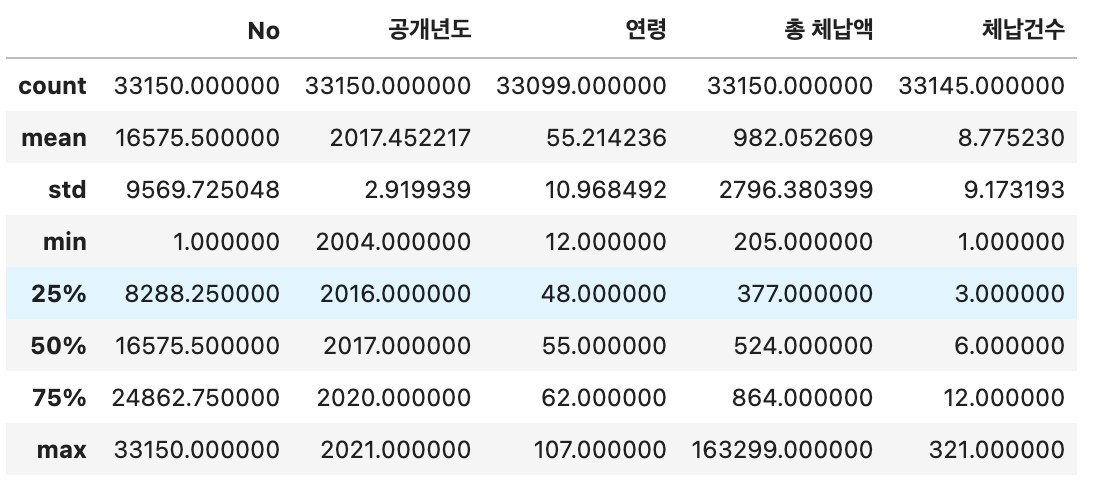
공개년도는 2004년부터, 총 체납액은 최소 205 최대 163299인데 단위가 백만원입니다.. 엄청난 체납자 놈들이라 할 수 있습니다 ..
위 자료에서 확인해보면 연령에서의 최소값이 12인데 궁금해서 확인해보았습니다
df[df.연령 < 20]
상속, 양도소득세 등이 있네요
이제 결측값을 확인합시다.
df.isna().sum()
---
No 0
공개년도 0
성명 0
연령 51
상호 10359
직업(업종) 6950
체납자 주소 0
총 체납액 0
세목 0
납기 0
체납건수 5
체납요지 0
dtype: int64상호와 직업란이 많이 비어있는데 큰 문제는 없을 것 같습니다.(개인체납자니까요)
주로 어떤 직업/직종이 많은지 확인해보겠습니다.
sorted_dict = sorted(dict.items(), key = lambda item: item[1], reverse = True)
print(sorted_dict[:20])
---
[(nan, 6950), ('건설업', 1737), ('제조업', 1611),
('서비스', 1582), ('도소매', 1536), ('제조', 1220),
('부동산', 1117), ('부동산업', 947), ('무직', 796),
('건설', 723), ('도매', 720), ('음식', 637),
('소매', 569), ('소매업', 450), ('서비스업', 369),
('도소매업', 323), ('도매업', 306), ('도매 및 소매업', 304),
('음식점업', 198), ('임대', 160)]상위 20개를 뽑아봤는데 nan이 6950으로 1위 주로 제조, 부동산, 도소매 등이 상위에 있습니다.
이중 nan값과 무직이 궁금하니 한번 20개정도씩 확인해 보겠습니다.
df[df['직업(업종)'].isna()]
df[df['직업(업종)'] == '무직'][:20]
네.. 대부분 소득세, 상속세입니다 개킹받네요
자 이제 어느 지역에 가장 많은 체납자 놈들이 거주중일지 확인해봅니다.
dict = {}
for i in df['지역']:
dict[i] = dict.get(i, 0) + 1
sorted_dict = sorted(dict.items(), key = lambda item: item[1], reverse = True)
---
[('경기', 6817),
('서울', 4653),
('경기도', 4309),
('서울특별시', 2359),
('경남', 1516),
('인천', 1417),
('충남', 1314),
('부산', 1033),
('경북', 948),
('인천광역시', 935),
('충북', 784),
('부산광역시', 736),
('전북', 577),
('전남', 574),
('강원', 560),
('대구광역시', 467),
('대구', 466),
('대전', 400),
('대전광역시', 320),
('경상남도', 306),
('강원도', 294),
('광주', 285),
('광주광역시', 267),
('울산', 259),
('울산광역시', 250),
('제주특별자치도', 215),
('경상북도', 200),
('충청남도', 198),
('제주', 188),
('전라북도', 121),
('전라남도', 115),
('충청북도', 110),
('세종', 80),
('세종특별자치시', 69),
('서울시', 5),
('제주도', 2),
('대구역시', 1)]데이터에서 경기, 경기도, 서울, 서울특별시등 일관성이 없어 보이지만
사람눈에 확인 가능한 수준으로 경기가 압도적으로 1위 서울이 2위입니다.
이제 졸리니까 자러가겠습니다.
