Map은 키를 값에 매핑하는 객체입니다. 맵에는 중복 키가 포함될 수 없습니다. 각 키는 최대 하나의 값에 매핑될 수 있습니다. 이는 수학적 함수 추상화를 모델링합니다. Map 인터페이스에는 기본 작업(예: put, get,remove, containKey, containValue, size 및 empty), 대량 작업(예: putAll 및clear) 및 컬렉션 뷰(예: keySet, EntrySet 및 values)에 대한 메서드가 포함되어 있습니다.
Java 플랫폼에는 HashMap, TreeMap 및 LinkedHashMap이라는 세 가지 범용 맵 구현이 포함되어 있습니다. 해당 동작과 성능은 인터페이스 설정 섹션에 설명된 대로 HashSet, TreeSet 및 LinkedHashSet과 정확히 유사합니다.
이 페이지의 나머지 부분에서는 Map 인터페이스에 대해 자세히 설명합니다. 하지만 먼저 JDK 8 집계 작업(aggregate operaion)을 사용하여 지도에 수집하는 몇 가지 예를 더 살펴보겠습니다. 실제 객체를 모델링하는 것은 객체 지향 프로그래밍에서 일반적인 작업이므로 일부 프로그램은 예를 들어 직원을 부서별로 그룹화할 수 있다고 생각하는 것이 합리적입니다.
// Group employees by department
Map<Department, List<Employee>> byDeptt = employees.stream().collect(Collectors.groupingBy(Employee::getDeparttent));또는 부서별 모든 급여의 합계를 계산합니다.
// Compute sum of salaries by deaprtment
Map<Department, Integer> totalByDept = employees.stream().collect(Collectors.groupingBy(Employee::getDepartment, Collectors.summingInt(Employee::getSalary)));또는 성적을 통과하거나 실패하여 학생들을 그룹화할 수도 있습니다
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream().collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD)))도시별로 사람들을 그룹화할 수도 있습니다.
// Classify Person objects by city
Map<String, List<Person>> peopoleByCity
= personStream.collect(Collectors.groupingBy(Person::getCity));또는 주 및 도시별로 사람을 분류하기 위해 두 개의 수집기를 계단식으로 배열할 수도 있습니다.
// Cascade Collectors
Map<String, Map<String, List<Person>>> peopleByStateAndCity = personStream.collect(Collectors.groupingBy(Person::getState, Collectors.groupingBy(Person::getCity)))다시 한번 말씀드리지만 이는 새로운 JDK 8 API를 사용하는 방법에 대한 몇 가지 예일 뿐입니다. 람다 식 및 집계 작업에 대한 자세한 내용은 Aggregate Operations이라는 단원을 참조하세요.
Map Interface Basic Operation
Map의 기본 작업(put, get, containKey, containValue, size 및 isEmpty)은 Hashtable의 해당 작업과 똑같이 동작합니다. 다음 프로그램은 인수 목록에서 찾은 단어의 빈도표를 생성합니다. 빈도표는 각 단어를 인수 목록에서 나타나는 횟수에 매핑합니다.
import java.util.HashMap;
import java.util.Map;
public class Freq {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<String, Integer>();
//Initialize frequency table from command line
for (String a : args) {
Integer freq = m.get(a);
m.put(a, (freq == null) ? 1 : freq + 1);
}
System.out.println(m.size() + " distinct words:");
System.out.println(m);
}
}null 대입 가능성
기본 자료형과 참조 자료형
String str = null; // 참조 자료형인 String에는 null을 대입할 수 있음
int number = null; // 컴파일 에러, 기본 자료형(int)에는 null을 대입할 수 없음기본 자료형은 값 자체를 저장하고 참조 자료형은 객체를 가리키는 참조(reference)를 저장.
참조 자료형 Integer
int primitiveInt = 42;
Integer wrapperInteger = primitiveInt; // Autoboxing: 기본 자료형을 래퍼 클래스로 변환
int backToPrimitiveInt = wrapperInteger; // Unboxing: 래퍼 클래스를 기본 자료형으로 변환래퍼 클래스들은 객체로서의 특성을 제공하며, null을 포함한 다양한 상황에서 사용할 수 있습니다.
null 연산 방법의 차이
mutable vs immutable 클래스
클래스가 mutable 또는 immutable인지 구분하는 주요 특징은 해당 클래스의 상태(멤버 변수의 값)가 변경 가능한지 여부에 있습니다.
- Mutable 클래스 :
- 값 변경이 가능: Mutable 클래스의 인스턴스는 생성된 이후에 내부의 상태(멤버 변수)를 변경할 수 있습니다.
- 상태 변화 가능한 메서드 제공: 클래스가 제공하는 메서드 중 일부는 객체의 상태를 변경하는 역할을 합니다.
예시: StringBuilder, ArrayList
StringBuilder mutableStr = new StringBuilder("Hello");
mutableStr.append(", World!"); // mutableStr의 내용이 변경됨- Immutable 클래스:
- 값 변경이 불가능: Immutable 클래스의 인스턴스는 한 번 생성되면 내부의 상태(멤버 변수)를 변경할 수 없습니다.
- 상태 변화 메서드가 없거나 새로운 객체를 반환: 클래스가 제공하는 메서드가 객체의 상태를 변경하는 것이 아니라, 새로운 객체를 반환하거나 현재 상태를 복제(clone)하여 반환합니다.
예시: String, Integer, LocalDate
String immutableStr = "Hello";
immutableStr = immutableStr.concat(", World!"); // immutableStr의 내용이 변경되는 것이 아닌, 새로운 문자열이 생성되어 참조됨클래스가 mutable하거나 immutable한지를 결정하는 것은 프로그래머에게 달려있으며, 클래스를 설계할 때 상태를 어떻게 다룰지를 고려해야 합니다. Immutable 클래스는 주로 스레드 안전성이나 예측 가능한 동작을 위해 사용됩니다.
불변(immutalble) 클래스 Integer
Integer freq = null;
freq = freq + 1; // NullPointerException불변클래스 = 불변클래스 + 1과 같은 연산은 불가능한데, 이는 불변 클래스의 핵심 특성 때문입니다.
불변 클래스는 내부 상태를 변경할 수 없도록 설계되어 있기 때문에, 어떠한 연산도 객체의 내부 상태를 직접 수정할 수 없습니다. 대신, 불변 클래스에서 연산을 수행하면 새로운 객체가 생성되고 그 결과가 반환됩니다.
Integer freq = null;
freq = (freq == null) ? 1 : freq + 1; // 올바른 방법위와 같이 정정하여 사용합니다.
이 프로그램에서 유일하게 까다로운 점은 put 문의 두 번째 인수입니다. 해당 인수는 단어가 이전에 본 적이 없는 경우 빈도를 1로 설정하거나 단어가 이미 본 경우 현재 값보다 1 더 높게 설정하는 효과가 있는 조건식입니다. 다음 명령을 사용하여 이 프로그램을 실행해 보세요.
java Freq if it is to be it is up to me to delegate프로그램은 다음과 같은 출력을 생성합니다.
8 distinct words:
{to=3, delegate=1, be=1, it=2, up=1, if=1, me=1, is=2}빈도표를 알파벳순으로 보고 싶다고 가정해 보겠습니다. 당신이 해야 할 일은 Map의 구현 유형을 HashMap에서 TreeMap으로 변경하는 것뿐입니다. 이렇게 4 글자를 변경하면 프로그램이 동일한 명령줄에서 다음 출력을 생성합니다.
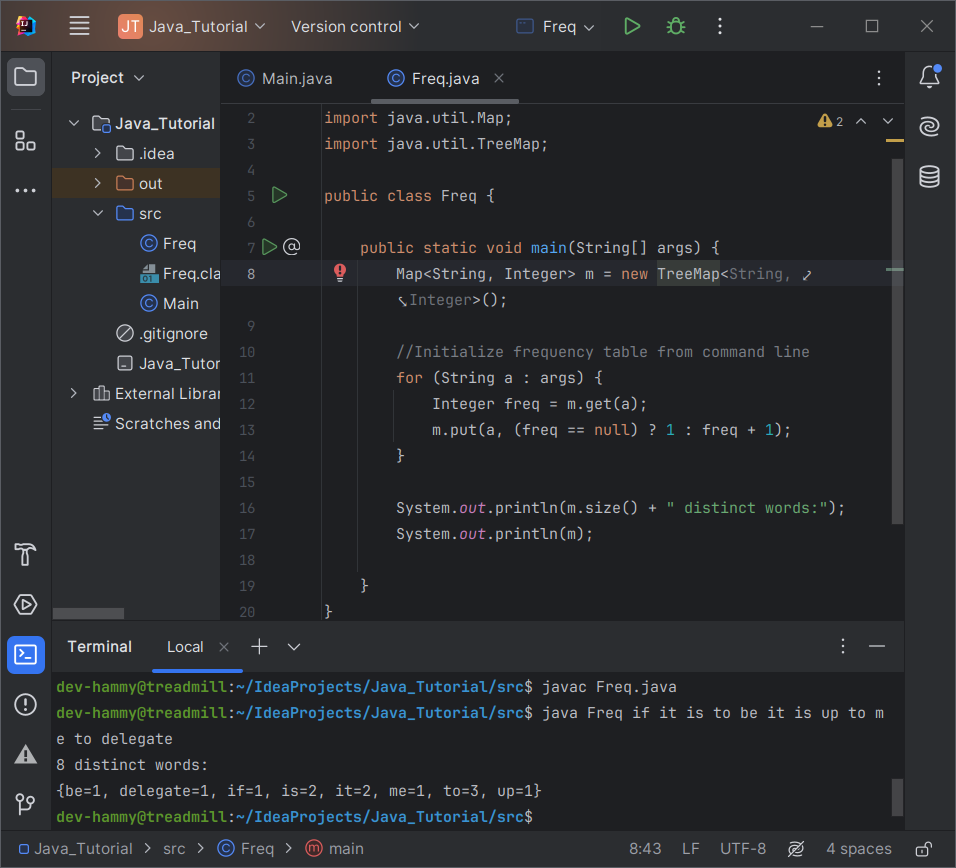
8 distinct words:
{be=1, delegate=1, if=1, is=2, it=2, me=1, to=3, up=1}마찬가지로, Map의 구현 type을 LinkedHashMap으로 변경하면 명령줄에 단어가 처음 나타나는 순서대로 프로그램이 빈도표를 인쇄하도록 할 수 있습니다. 그렇게 하면 다음과 같은 결과가 출력됩니다.
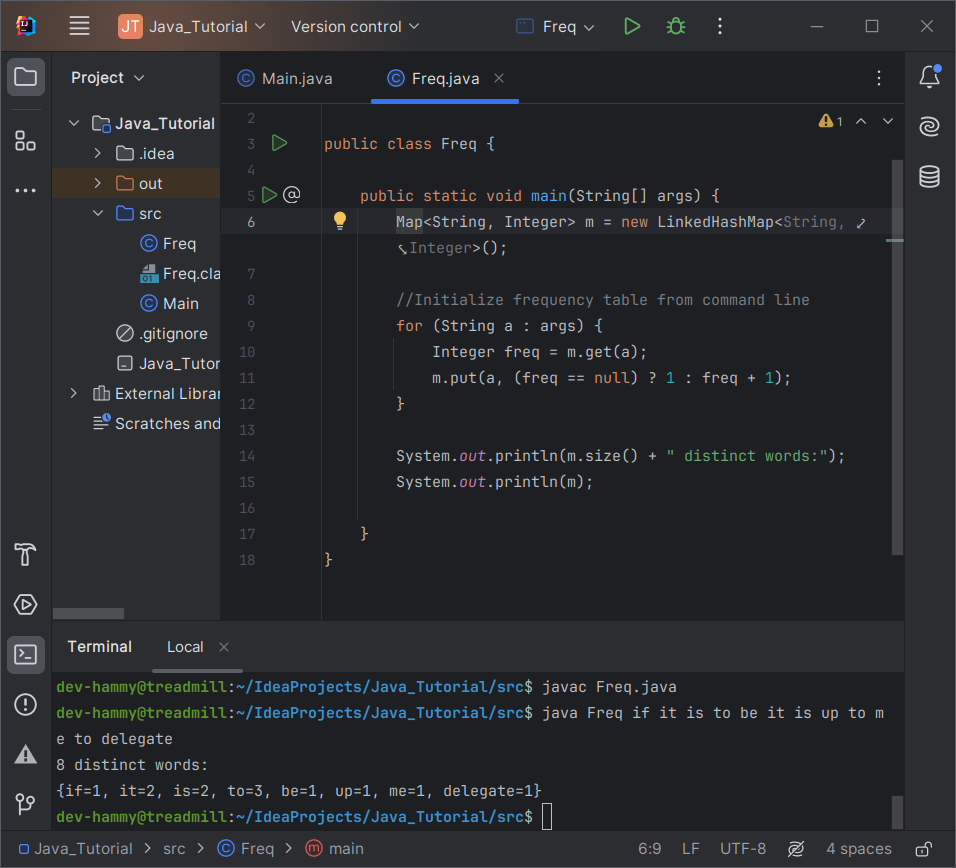
8 distinct words:
{if=1, it=2, is=2, to=3, be=1, up=1, me=1, delegate=1}이러한 유연성은 interfaced-based 프레임워크의 강력한 성능을 보여줍니다.
Set 및 List 인터페이스와 마찬가지로 Map은 구현 유형에 관계없이 두 Map 개체의 논리적 동등성을 비교할 수 있도록 equals 및 hashCode 메서드에 대한 요구 사항을 강화합니다. 두 Map 인스턴스가 동일한 키-값 매핑을 나타내는 경우 동일합니다.
관례에 따라(By convention) 모든 범용 Map 구현은 Map 객체를 취하고 지정된 Map의 모든 키-값 매핑을 포함하도록 새 Map을 초기화하는 생성자를 제공합니다. 이 표준 Map 변환 생성자는 표준 Collection 생성자와 완전히 유사합니다. 이를 통해 호출자(caller)는 다른(other) Map의 구현 유형에 관계없이 처음에 다른(another) Map의 모든 매핑을 포함하는 원하는 구현 유형의 Map을 생성할 수 있습니다. 예를 들어 m이라는 Map이 있다고 가정합니다. 다음 한 줄짜리 코드는 처음에 m과 동일한 키-값 매핑을 모두 포함하는 새 HashMap을 생성합니다.
Map<K, V> copy = new HashMap<K, V>(m);Map Interface Bulk Operations
clear 작업은 여러분이 생각하는 것과 정확히 일치하는 작업을 수행합니다. 즉, Map에서 모든 매핑을 제거합니다. putAll 작업은 Collection 인터페이스의 addAll 작업과 유사한 Map입니다. 하나의 Map을 다른 Map에 덤프(dump)하는 명백한 용도 외에도 두 번째로 더 미묘한 용도가 있습니다. Map이 속성(attribute)-값(value) 쌍의 컬렉션을 나타내는 데 사용된다고 가정합니다. Map 변환 생성자와 결합된 putAll 작업은 기본값을 사용하여 속성 맵(attribute map) 생성을 구현하는 깔끔한 방법을 제공합니다. 다음은 이 기술을 보여주는 정적 팩터리 메서드입니다.
static <K, V> Map<K, V> newAttributeMap(Map<K, V> defaults, Map<K, V> overrides) {
Map<K, V> result = new HashMap<K, V>(defaults);
result.putAll(overrides);
return result;
}Map<K, V> result = new HashMap<K, V>(defaults);:
- 새로운
HashMap객체result를 생성합니다. - 이 때,
defaults맵을 복제하여 초기화합니다. 따라서result는defaults의 모든 키-값 쌍을 가지게 됩니다.
result.putAll(overrides);:
overrides맵의 모든 키-값 쌍을result맵에 추가합니다. 이미defaults맵의 내용이 들어있으므로, 중복된 키가 있는 경우overrides의 값으로 덮어씌워집니다.
이 메서드는 주로 기본값(defaults)과 추가값(overrides)을 가지는 설정을 다루거나, 두 맵의 내용을 결합해야 할 때 사용될 수 있습니다.
Collection Views
Collection view 메소드를 사용하면 다음 세 가지 방법으로 Map를 Collection으로 view할 수 있습니다.
keySet—Map에 포함된 키Set입니다.value—Map에 포함된 값의Collection입니다. 여러 키가 동일한 값에 매핑될 수 있으므로 이 컬렉션은Set이 아닙니다.entrySet—Map에 포함된 키-값 쌍Set입니다.Map인터페이스는 이Set의 요소 type인Map.Entry라는 작은 중첩 인터페이스를 제공합니다.
Collection view는 Map를 반복(iterate)하는 유일한(only) 수단을 제공합니다. 이 예는 for-each 구문을 사용하여 Map의 키를 반복하는 표준 관용구를 보여줍니다.
for (KeyType key : m.keySet())
System.out.println(key);그리고 반복자(iterator)를 사용하면:
// Filter a map based on some
// property of its keys
for (Iterator<Type> it = m.keySet().iterator(); it.hasNext(); )
if (it.next().isBogus())
it.remove();값을 반복하는 관용어도 유사합니다. 다음은 키-값 쌍을 반복하는 관용구입니다.
for (Map.Entry<KeyType, valType> e : m.entrySet())
System.out.println(e.getKey() + ": " + e.getValue());처음에 많은 사람들은 Collection 뷰 작업이 호출될 때마다 Map이 새 Collection 인스턴스를 생성해야 하기 때문에 이러한 관용어가 느려질 수 있다고 걱정합니다. 안심하십시오. Map이 주어진 Collection 뷰에 대해 요청될 때마다 항상 동일한 객체를 반환할 수는 없습니다. 이것이 바로 java.util의 모든 Map 구현이 수행하는 작업입니다.
-
Collection뷰 작업이 호출될 때마다Map이 새로운 컬렉션 인스턴스를 생성하는 것은 아닙니다.Map인터페이스의 메서드 중keySet(),values(),entrySet()과 같은 메서드들은 해당하는 뷰를 반환하는데, 이 뷰는 원본Map의 데이터를 반영하는 동적인 뷰입니다. 따라서 새로운 인스턴스를 생성하지 않고, 원본Map의 내용을 참조합니다. -
"주어진
Collection뷰에 대해Map이 요청될 때 항상 동일한 객체를 반환할 수는 없다"는 말은 같은Map에 대해 여러 참조로부터keySet(),values(),entrySet()과 같은 뷰를 얻더라도 항상 동일한 객체가 반환되지 않을 수 있다는 의미입니다. 즉, 한 번 얻은 뷰를 수정하면 다른 참조로 얻은 뷰에도 변경 사항이 반영될 수 있습니다. 이는 뷰가 동적이고 원본Map과 연결되어 있기 때문입니다. -
이 설명은 주로
Map에 해당하지만,Collection인터페이스를 구현하는 다른 자료구조에도 비슷한 개념이 적용될 수 있습니다. 예를 들어,Set,List, 등의 다양한 컬렉션에서도 뷰를 통해 컬렉션의 요소를 조회하고 조작할 수 있습니다. 그러나 각각의 자료구조는 자신에 맞게 특화된 뷰를 제공합니다.
세 가지 Collection 뷰 모두에서 Iterator의 remove 작업을 호출하면 backing Map이 처음부터 요소 제거를 지원한다는 가정 하에 backing Map에서 관련 항목이 제거됩니다. 이는 앞의 필터링 관용구(idiom)로 설명됩니다.
entrySet 뷰를 사용하면 반복(iteration) 중에 Map.Entry의 setValue 메소드를 호출하여 키와 연관된 값을 변경할 수도 있습니다(다시 말하면 Map이 처음부터 값 수정을 지원한다고 가정). 이는 반복 중에 맵을 수정하는 유일한(only) 안전한 방법입니다. 반복이 진행되는 동안 기본 Map이 다른 방식으로 수정되면 동작이 지정되지 않습니다.
컬렉션 뷰는 Iterator.remove 작업뿐만 아니라 remove, removeAll, retainAll, clear 작업 등 다양한 형태의 요소 제거를 지원합니다. (다시 한번 말하지만, 이는 백업 맵이 요소 제거를 지원한다고 가정합니다.)
"Backing Map(지원 맵)"은 해당 컬렉션 뷰가 생성된 원본 Map을 가리키는 용어입니다.
"처음부터 요소 제거를 지원한다"는 말은 해당 컬렉션 뷰가 Iterator를 통한 요소 제거를 지원한다는 것을 의미합니다. 예를 들어, keySet(), values(), entrySet()과 같은 메서드로 얻은 뷰를 통해 Iterator를 사용하여 요소를 반복하면서 remove 메서드를 호출하면, 해당 요소가 속한 원본 Map에서도 요소가 제거됩니다. 이는 컬렉션 뷰가 원본 Map과 동기화되어 있다는 것을 의미합니다.
다만, 이러한 작업을 안전하게 수행하려면 반복 중에 맵을 다른 방식으로 수정하지 않아야 하며, 컬렉션 뷰를 통해서만 수정 작업을 수행해야 합니다.
Map 인터페이스는 구체적인 Map 구현에게 Iterator를 통한 요소 제거를 지원할 것인지 여부를 강제하지 않으므로 각 구현의 문서를 참조하여 확인하는 것이 좋습니다.
예를 들어, Collections.unmodifiableMap 메서드를 사용하여 래핑한 불변(immutable) 맵은 Iterator를 통한 요소 제거를 지원하지 않습니다.
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class UnmodifiableMapExample {
public static void main(String[] args) {
// 불변 Map 생성
Map<String, Integer> originalMap = new HashMap<>();
originalMap.put("one", 1);
originalMap.put("two", 2);
originalMap.put("three", 3);
Map<String, Integer> unmodifiableMap = Collections.unmodifiableMap(originalMap);
// Iterator를 통한 요소 제거는 UnsupportedOperationException 발생
Iterator<Map.Entry<String, Integer>> iterator = unmodifiableMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
if (entry.getValue() == 2) {
iterator.remove(); // UnsupportedOperationException 발생
}
}
}
}Collection view가 모든 상황에서 요소 추가를 지원하는 것은 아닙니다. keySet 및 values 뷰에는 의미가 없으며, backing Map의 put 및 putAll 메소드가 동일한 기능을 제공하기 때문에 entrySet 뷰에는 필요하지 않습니다.
컬렉션 뷰의 멋진 활용: Map 대수학(Algebra)
Collection 뷰에 적용하면 bulk operations(containsAll, RemoveAll, RetainAll)는 놀라울 정도로 강력한 도구가 됩니다. 우선, 한 Map이 다른 Map의 서브맵인지 여부, 즉 첫 번째 Map에 두 번째 Map의 모든 키-값 매핑이 포함되어 있는지 여부를 알고 싶다고 가정해 보겠습니다. 다음 관용구가 그 역할을 합니다.
if (m1.entrySet().containsAll(m2.entrySet())) { ... }비슷한 맥락에서, 두 Map 객체에 동일한 키 모두에 대한 매핑이 포함되어 있는지 알고 싶다고 가정해 보겠습니다.
if (m1.keySet().equals(m2.keySet())) { ... }속성-값 쌍의 컬렉션을 나타내는 Map과 필수 속성 및 허용되는(permissible) 속성을 나타내는 두 개의 Set가 있다고 가정합니다. (허용되는 속성에는 필수 속성이 포함됩니다.) 다음 코드 조각은 속성 Map이 이러한 제약 조건을 준수하는지 여부를 확인하고 그렇지 않은 경우 자세한 오류 메시지를 인쇄합니다.
static <K, V> boolean validate(Map<K, V> attrMap, Set<K> requiredAttrs, Set<K> permittedAttrs) {
boolean valid = true;
Set<K> attrs = attrMap.keySet();
if(! attrs.containsAll(requiredAttrs)) {
Set<K> missing = new HashSet<K>(requiredAttrs);
missing.removeAll(attrs);
System.out.println("Missing attributes: " + missing);
valid = false;
}
if (! permittedAttrs.containsAll(attrs)) {
Set<K> illegal = new HashSet<K>(attrs);
illegal.removeAll(permittedAttrs);
System.out.println("Illegal attributes: " + illegal);
valid = false;
}
return valid;
}두 개의 Map 객체에 공통된 모든 키를 알고 싶다고 가정해 보겠습니다.
Set<KeyType> commonKeys = new HashSet<KeyType>(m1.keySet());
commonKeys.retainAll(m2.keySet());비슷한 관용구를 사용하면 공통된 값를 얻을 수 있습니다.
지금까지 제시된 모든 관용어는 비파괴적이었습니다. 즉, 백업 맵을 수정하지 않습니다. 여기에 몇 가지가 있습니다. 한 맵이 다른 맵과 공통으로 갖고 있는 키-값 쌍을 모두 제거한다고 가정해 보겠습니다.
m1.entrySet().removeAll(m2.entrySet());한 Map에서 다른 Map에 매핑이 있는 모든 키를 제거한다고 가정해 보겠습니다.
m1.keySet().removeAll(m2.keySet());동일한 bulk 작업에서 키와 값을 혼합하기 시작하면 어떻게 되나요? 회사의 각 직원을 직원의 관리자에 매핑하는 Map, managers가 있다고 가정합니다. 우리는 키와 값 객체의 type에 대해 의도적으로(deliberately) 모호하게(vague) 만들 것입니다. 동일하다면 상관없습니다. 이제 모든 "individual contributors"(or nonmanagers)가 누구인지 알고 싶다고 가정해 보겠습니다. 다음 스니펫은 여러분이 알고 싶은 내용을 정확하게 알려줍니다.
Set<Employee> individualContributors = new HashSet<Employee>(managers.keySet());
individualContributors.removeAll(managers.values());관리자인 Simon에게 직접 보고하는 모든 직원을 해고한다고 가정해 보겠습니다.
Employee simon = ... ;
managers.values().removeAll(Collections.singleton(simon)); 이 관용구는 지정된 단일 요소를 사용하여 변경할 수 없는(immutable) Set을 반환하는 정적 팩토리 메서드인 Collections.singleton을 사용합니다.
구체적으로 managers.values()의 반환 타입은 Collection<V>입니다. 여기서 V는 맵이 값에 대한 제네릭 타입 파라미터입니다.
Collections.singleton은 컬렉션에 하나의 요소만을 포함하는 변경할 수 없는 집합(Set)을 생성하는 메서드입니다.
managers.values()는 맵의 값들을 가지고 있는 컬렉션 뷰이므로, 이 값들을 수정하면 실제 맵에 반영됩니다. 따라서 managers.values().removeAll(...)를 호출하면 맵에서 해당 값들이 삭제됩니다.
위 예시에서는 Simon에 해당하는 값을 삭제하여 해당 값들이 null로 설정됩니다. 그러나 키들은 그대로 남아있게 됩니다.
이 작업을 수행하면 관리자가 더 이상 회사에서 일하지 않는 직원이 많이 있을 수 있습니다(Simon의 직속 부하 직원 중 관리자인 경우). 다음 코드는 더 이상 회사에서 일하지 않는 관리자가 있는 직원을 알려줍니다.
Map<Employee, Employee> m = new HashMap<Employee, Employee>(managers);
m.values().removeAll(managers.keySet());
Set<Employee> slackers = m.keySet();이 예는 약간 까다롭습니다. 먼저, 맵의 임시 복사본을 만들고 value(manager)가 원본 맵의 key인 모든 항목(entries)을 임시 복사본에서 제거합니다. 원본 Map에는 각 직원에 대한 항목(entry)이 있다는 것을 기억하십시오. 따라서 임시 맵의 나머지 항목은 값(관리자)이 더 이상 직원이 아닌 원래 맵의 모든 항목(entries)으로 구성됩니다. 그러면 임시 복사본의 키는 우리가 찾고 있는 직원을 정확하게 나타냅니다.
이 섹션에 포함된 것과 같은 관용어가 더 많이 있지만 모두 나열하는 것은 비현실적이고 지루할 것입니다. 일단 익숙해지면 필요할 때 올바른 것을 찾는 것이 그리 어렵지 않습니다.
Multimaps
multimap은 맵과 비슷하지만 각 키를 여러 값에 매핑할 수 있습니다. 멀티맵은 일반적으로 흔히 사용 되지 않기 때문에 Java Collections Framework에는 멀티맵용 인터페이스가 포함되어 있지 않습니다. 값이 List 인스턴스인 Map을 멀티맵으로 사용하는 것은 매우 간단한 문제입니다. 이 기술은 한 줄에 하나의 단어(모두 소문자)가 포함된 단어 목록을 읽고 크기 기준(size criterion)을 충족하는 모든 철자 바꾸기(anagram) 그룹을 인쇄하는 다음 코드 예제에서 설명됩니다. anagram group은 단어 묶음으로, 모두 정확히 동일한 문자를 포함하지만 순서는 다릅니다. 프로그램은 명령줄에서 (1) 사전(dictionary) 파일의 이름과 (2) 인쇄할 철자 바꾸기 그룹(anagram)의 최소 크기라는 두 가지 인수를 사용합니다. 지정된 최소 단어보다 적은 단어를 포함하는 철자 바꾸기 그룹은 인쇄되지 않습니다.
철자 바꾸기 그룹을 찾는 표준 요령이 있습니다. 사전의 각 단어에 대해 단어의 문자를 알파벳순으로 정렬하고(즉, 단어의 문자를 알파벳순으로 재정렬) 항목을 멀티맵에 넣어 알파벳순의 단어를 원본에 매핑합니다. 단어. 예를 들어, bad라는 단어는 abd를 bad로 매핑하는 항목이 멀티맵에 들어가도록 합니다. 잠시 생각해 보면 주어진 키 맵에 포함된 모든 단어가 철자 바꾸기 그룹을 형성한다는 것을 알 수 있습니다. 크기 제약 조건을 충족하는 각 철자 바꾸기 그룹을 인쇄하면서 멀티맵의 키를 반복하는 것은 간단한 문제입니다.
다음 프로그램은 이 기술을 간단하게 구현한 것입니다.
public class Anagrams {
private static String alphabetize(String s) {
char[] a = s.toCharArray();
Arrays.sort(a);
return new String (a);
}
public static void main(String[] args) {
int minGroupSize = Integer.parseInt(args[1]);
// Read words from file and put into a simulated multimap
Map<String, List<String>> m = new HashMap<String, List<String>>();
try {
Scanner s = new Scanner(new File(args[0]));
while (s.hasNext()) {
String word = s.next();
String alpha = alphabetize(word);
List<String> l = m.get(alpha);
if (l == null) {
m.put(alpha, l = new ArrayList<String>());
l.add(word);
}
}
} catch (IOException e) {
System.err.println(e);
System.exit(1);
}
// Print all permutation groups above size threshold
for (List<String> l : m.values()) {
if (l.size() >= minGroupSize) {
System.out.println(l.size() + ": " + l);
}
}
}
}
Scanner 클래스는 입력을 파싱하는 데 사용되는 유연한 클래스입니다. Scanner를 사용하여 파일을 읽을 때, 파일의 내용에 대한 특별한 요구사항은 없습니다. Scanner는 파일에서 텍스트 데이터를 읽어들이는데 사용될 수 있습니다.
파일의 내용은 텍스트 파일이거나, 라인 단위로 데이터를 포함하는 텍스트 기반 파일이면 잘 작동합니다. 파일이 텍스트 파일이 아니라 이진 파일인 경우에는 Scanner를 사용하는 것이 적합하지 않습니다.
Scanner는 입력 소스에서 토큰을 읽어오는데, 토큰은 기본적으로 공백으로 분리됩니다. 파일 내용의 구조는 파일에 담긴 데이터의 형태에 따라 달라질 수 있습니다. 예를 들어, 각 줄에 하나의 단어가 있는 경우 라인 단위로 토큰을 분리할 수 있습니다.
파일 내용의 구조에 따라 Scanner를 사용하는 방법을 조정할 수 있으며, 필요에 따라 Scanner의 메서드들을 활용하여 데이터를 읽어들이고 처리할 수 있습니다.
맞습니다. m이 Map 객체이며, 키와 값이 채워진 상태가 아니라면 m.get(alpha)는 null을 반환합니다. 따라서 코드에서는 l에 null이 할당될 가능성이 있습니다.
List<String> l = m.get(alpha);위의 코드에서 alpha가 m 맵의 키로 존재하지 않거나 해당 키에 연결된 값이 null일 경우, get 메서드는 null을 반환합니다. 따라서 l은 null이 됩니다.
이러한 경우에 대한 안전성을 고려한다면, 코드에서 l이 null인지 확인한 후에 작업을 진행하는 것이 좋습니다. 아래는 예시 코드입니다:
List<String> l = m.get(alpha);
if (l == null) {
l = new ArrayList<String>();
m.put(alpha, l);
}
// 이제 l은 null이 아닌 ArrayList<String>입니다.이렇게 하면 l이 null인 경우에는 새로운 ArrayList를 생성하여 m 맵에 추가하게 되므로 후속 작업에서 l을 사용해도 안전합니다.
최소 철자 바꾸기 그룹 크기가 8인 173,000 단어 사전 파일에서 이 프로그램을 실행하면 다음과 같은 출력이 생성됩니다.
9: [estrin, inerts, insert, inters, niters, nitres, sinter,
triens, trines]
8: [lapse, leaps, pales, peals, pleas, salep, sepal, spale]
8: [aspers, parses, passer, prases, repass, spares, sparse,
spears]
10: [least, setal, slate, stale, steal, stela, taels, tales,
teals, tesla]
8: [enters, nester, renest, rentes, resent, tenser, ternes,
treens]
8: [arles, earls, lares, laser, lears, rales, reals, seral]
8: [earings, erasing, gainers, reagins, regains, reginas,
searing, seringa]
8: [peris, piers, pries, prise, ripes, speir, spier, spire]
12: [apers, apres, asper, pares, parse, pears, prase, presa,
rapes, reaps, spare, spear]
...// 생략이러한 단어 중 상당수는 약간 가짜인 것처럼 보이지만 이는 프로그램의 잘못이 아닙니다. 그것들은 사전 파일에 있어요. 여기에 우리가 사용한 사전 파일이 있습니다. 이는 Public Domain ENABLE 벤치마크 참조 단어 목록에서 파생되었습니다.
