이 가이드는 기본 배치 기반 솔루션을 만드는 과정을 안내합니다.
Spring Batch는 대규모 데이터 처리 작업을 효율적으로 수행하기 위한 프레임워크입니다. 대량의 데이터를 처리하고, 이를 원하는 형식으로 가공하며, 데이터베이스에 저장하거나 외부 시스템에 전달하는 등의 배치(일괄 처리) 작업을 지원합니다. 대용량의 데이터를 효율적으로 처리하고 에러 핸들링, 트랜잭션 관리 등을 제공하여 안정적인 배치 작업을 수행할 수 있게 해줍니다.
What You Will Build
CSV 스프레드시트에서 데이터를 가져오고 이를 사용자 정의 코드로 변환하고 최종 결과를 데이터베이스에 저장하는 서비스를 구축합니다.
Starting with Spring Initializr
Business Data
일반적으로 고객이나 비즈니스 분석가가 스프레드시트를 제공합니다. 이 간단한 예에서는 src/main/resources/sample-data.csv에서 일부 구성 데이터를 찾을 수 있습니다.
Jill,Doe
Joe,Doe
Justin,Doe
Jane,Doe
John,Doe이 스프레드시트에는 각 행에 이름과 성이 쉼표로 구분되어 포함되어 있습니다. 이는 Spring이 사용자 정의 없이 처리할 수 있는 매우 일반적인 패턴입니다.
다음으로, 데이터를 저장할 테이블을 생성하는 SQL 스크립트를 작성해야 합니다. src/main/resources/schema-all.sql에서 이러한 스크립트를 찾을 수 있습니다.
DROP TABLE people IF EXISTS;
CREATE TABLE people (
person_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);Spring Boot는 시작 중에 자동으로
Schema-@@platform@@.sql을 실행합니다.-all은 모든 플랫폼의 기본값입니다.
Create a Business Class
이제 데이터 입력 및 출력의 형식을 볼 수 있으므로 다음 예제(src/main/java/guides/batchprocessing/Person.java에서)에 표시된 대로 데이터 행을 나타내는 코드를 작성할 수 있습니다.
package guides.batchprocessing;
public record Person(String firstName, String lastName) {
}생성자를 통해 이름과 성으로 Person 레코드를 인스턴스화할 수 있습니다.
Create an Intermediate Processor
일괄 처리(batch processing)의 일반적인 패러다임은 데이터를 수집하고 변환한 다음 다른 곳으로 파이프하는 것입니다. 여기서는 이름을 대문자로 변환하는 간단한 변환기를 작성해야 합니다. 다음 목록(src/main/java/guides/batchprocessing/PersonItemProcessor.java)에서는 이를 수행하는 방법을 보여줍니다.
package guides.batchprocessing;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
private static final Logger log = LoggerFactory.getLogger(PersonItemProcessor.class);
@Override
public Person process(final Person person){
final String firstName = person.firstName().toUpperCase();
final String lastName = person.lastName().toUpperCase();
final Person transformedPerson = new Person(firstName, lastName);
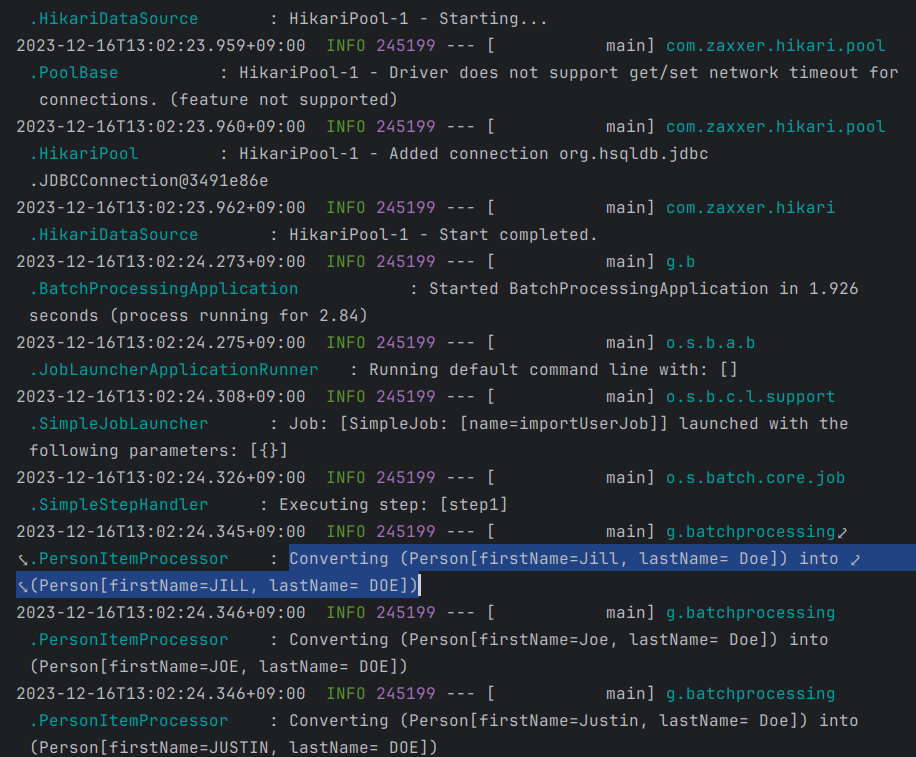
log.info("Converting ("+person+") into ("+transformedPerson+")");
return transformedPerson;
}
}PersonItemProcessor는 Spring Batch의 ItemProcessor 인터페이스를 구현합니다. 이렇게 하면 이 가이드의 뒷부분에서 정의할 배치 작업에 코드를 쉽게 연결할 수 있습니다. 인터페이스에 따르면 들어오는 Person 객체를 받은 후 이를 대문자 Person으로 변환합니다.
입력 및 출력 유형이 동일할 필요는 없습니다. 실제로 하나의 데이터 소스를 읽은 후 애플리케이션의 데이터 흐름에 다른 데이터 유형이 필요한 경우가 있습니다.
final키워드를 Processor에 사용한 이유
-
불변성 유지:
final키워드를 사용하면 변수가 한 번 초기화되고 나면 재할당할 수 없기 때문에, 코드의 의도치 않은 변경을 방지하고 예기치 않은 버그를 줄일 수 있습니다. -
스레드 안전성:
final로 표시된 변수는 다른 스레드에서 값이 변경되는 것을 방지하여 예기치 않은 상태를 방지할 수 있으므로 멀티스레드 환겨엥서 안전하게 사용될 수 있습니다. -
가독성 및 증대:
final키워드를 사용하면 값이 변경되지 않을 것이라는 것을 읽는 사람이 빠르게 파악할 수 있습니다.
위 코드에서 final 키워드가 매개변수와 필드값에 사용된 이유는 이러한 이점을 취하기 위함입니다.
process()메서드의 매개변수person은 메서드 내에서 변경되지 않을 것임을 명시적으로 표현하기 위해final키워드가 사용되었습니다.- 마찬가지로
firstName과lastName변수도 변경되지 않고 최종적으로 새로운transformedPerson객체를 생성하기 위해final키워드가 사용되었습니다.
Put Together a Batch Job
이제 실제 배치 작업을 구성해야 합니다. Spring Batch는 사용자 정의 코드 작성 필요성을 줄이는 많은 유틸리티 클래스를 제공합니다. 대신 비즈니스 로직에 집중할 수 있습니다.
작업을 구성하려면 먼저 src/main/java/guides/batchprocessing/BatchConfiguration.java에서 다음 예제와 같은 Spring @Configuration 클래스를 생성해야 합니다. 이 예에서는 메모리 기반 데이터베이스를 사용합니다. 즉, 작업이 완료되면 데이터가 사라집니다. 이제 BatchConfiguration 클래스에 다음 Bean을 추가하여 판독기(reader), 프로세서(processor) 및 기록기(writer)를 정의합니다.
package guides.batchprocessing;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import javax.sql.DataSource;
@Configuration
public class BatchConfiguration {
@Bean
public FlatFileItemReader<Person> reader() {
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(new ClassPathResource("sample-data.csv"))
.delimited()
.names("firstName", "lastName")
.targetType(Person.class)
.build();
}
@Bean
public PersonItemProcessor processor() {
return new PersonItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Person>()
.sql("INSERT INTO people (first_name, last_name) VALUES (:fistName, :lastName)")
.dataSource(dataSource)
.beanMapped()
.build();
}
}코드의 첫 번째 덩어리는 입력, 프로세서 및 출력을 정의합니다.
reader()는ItemReader를 생성합니다.sample-data.csv라는 파일을 찾고 이를Person으로 변환하는 데 충분한 정보가 포함된 각 항목을 구문 분석(parse)합니다.processor()는 이전에 정의한PersonItemProcessor의 인스턴스를 생성하여 데이터를 대문자로 변환합니다.writer(DataSource)는ItemWriter를 생성합니다. 이는 JDBC 대상을 목표로 하며 Spring Boot에서 생성된 dataSource의 복사본을 자동으로 가져옵니다. 여기에는 Java 레코드 구성 요소에 의해 구동되는 단일Person을 삽입하는 데 필요한 SQL 문이 포함됩니다.
1.ItemProcessor 인터페이스 : Spring Batch에서 사용되며, 입력 데이터를 받아 비즈니스 로직에 따라 가공하거나 변환하여 출력으로 전달합니다.
- Item은 Spring Batch에서 처리되는 개별 단위의 데이터입니다. 이것은 일반적으로 파일에서 읽어온 레코드, 데이터베이스 테이블의 레코드, 또는 다른 데이터 소스의 한 단위를 나타냅니다.
2.FlatFileItemReader는 Spring Batch에서 제공하는 파일을 읽어들이는데 사용되는 구성 요소입니다. 주로 텍스트 기반의 파일을 읽어들여 각 라인을 아이템으로 변환합니다.
- Flat 파일은 데이터를 저장하는 데 사용되는 텍스트 파일 형식 중 하나입니다. 이 파일 형식은 간단하게 구조화된 텍스트 파일로, 각 라인이 레코드를 나타내며, 필드는 구분자(delimiter)로 구분되어 있습니다. CSV(Comma-Separated Values) 파일은 가장 흔한 flat 파일 형식 중 하나입니다.
.name("personItemReader"): 생성되는 Reader의 이름을 지정합니다..resource(new ClassPathResource("sample-data.csv")): Reader가 읽을 파일의 위치를 지정합니다..delimited(): 파일이 구분자(delimiter)로 구분된 텍스트 파일임을 명시합니다..names("firstName", "lastName"): 파일의 각 열(column)에 해당하는 필드 이름을 지정합니다..targetType(Person.class): 각 라인을 어떤 클래스로 매핑할지 지정합니다. 여기서는Person클래스로 매핑합니다.
4.JdbcBatchItemWriter는 Spring Batch에서 사용되며, JDBC를 통해 데이터베이스에 대량의 데이터를 쓰는 작업을 처리하는 데에 사용됩니다. 이는 일괄 처리된 데이터를 데이터베이스에 효율적으로 삽입, 업데이트 또는 삭제하는 등의 작업을 수행할 때 활용됩니다.
.sql("INSERT INTO people (first_name, last_name) VALUES (:fistName, :lastName)"): 쿼리를 설정하여 데이터베이스에 어떻게 쓸지를 지정합니다.:fistName과:lastName는 나중에 바인딩할 파라미터입니다..dataSource(dataSource):Writer가 데이터를 저장할 데이터베이스의 DataSource를 설정합니다..beanMapped():Person객체의 필드를 쿼리의 파라미터와 매핑할 수 있도록 설정합니다.
마지막 청크(src/main/java/guides/batchprocessing/BatchConfiguration.java)는 실제 작업 구성을 보여줍니다.
@Bean
public Job importUserJob(JobRepository jobRepository, Step step1, JobCompletionNotificationListener listener) {
return new JobBuilder("importUserJob", jobRepository)
.listener(listener)
.start(step1)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, DataSourceTransactionManager transactionManager,
FlatFileItemReader<Person> reader,
PersonItemProcessor processor,
JdbcBatchItemWriter<Person> writer) {
return new StepBuilder("step1", jobRepository)
.<Person, Person> chunk(3, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}첫 번째 방법은 작업(job)을 정의하고 두 번째 방법은 단일 단계(step)를 정의합니다. job은 각 step에 reader, processor 및 writer가 포함될 수 있는 단계로 구성됩니다.
그런 다음 각 단계(step)를 나열합니다(이 작업에는 단계가 하나만 있음). 작업(job)이 종료되고 Java API가 완벽하게 구성된(configured) 작업을 생성합니다.
단계(step) 정의에서는 한 번에 쓸 데이터의 양을 정의합니다. 이 경우 한 번에 최대 3개의 레코드를 씁니다. 다음으로 앞서 주입한 Bean을 사용하여 reader, preocessor, writer를 구성합니다.
chunk()는 제네릭 메서드이기 때문에<Person,Person>접두사가 붙습니다. 이는 처리의 각 "청크"의 입력 및 출력 유형을 나타내며ItemReader<Person>및ItemWriter<Person>과 정렬됩니다.
-
JobRepository는 Spring Batch의 내부에서 사용되는 인터페이스로, 배치 작업(Job)의 메타데이터와 상태를 관리합니다. 배치 작업이나 스텝의 실행 상태, 실행 내역, 실패한 작업들의 복구 등을 관리하며, 이 정보들을 데이터베이스에 저장합니다. 주로 배치 작업의 상태를 추적하고 관리하는 데 사용됩니다. -
Listener는 배치 작업(Job)이나 Step의 시작, 완료 등의 이벤트를 감지하고 처리하기 위해 사용됩니다. 이를 통해 작업의 성공, 실패, 혹은 진행 상태 등을 모니터링하고 추가적인 작업을 수행할 수 있습니다. 예를 들어, 배치 작업이 성공적으로 완료되면 알림을 보내거나 로그를 남기는 등의 작업을 수행할 수 있습니다. -
DataSourceTransactionManager는 스프링에서 데이터베이스 트랜잭션을 관리하기 위한 클래스 중 하나입니다. 데이터베이스 트랜잭션을 시작하고 커밋 또는 롤백하는 데 사용됩니다. Spring Batch에서는 배치 작업의 트랜잭션 관리를 위해DataSourceTransactionManager를 사용하여 데이터베이스 트랜잭션을 시작하고 관리합니다. 각 스텝(chunk)의 커밋 단위(chunk size)를 정의하거나, 데이터를 처리하는 동안에 트랜잭션을 롤백하거나 커밋하는 등의 작업을 이 클래스를 통해 수행할 수 있습니다. 이것은 안정적인 데이터 처리와 데이터 일관성을 보장하는 데 중요한 역할을 합니다. -
예를 들어, Chunk의 커밋 단위가 3으로 설정되어 있다면, 스프링 Batch는 데이터를 읽어와서 처리할 때 3개의 아이템을 읽어와서 하나의 트랜잭션으로 묶어 처리하고, 그 후에 커밋을 수행합니다. 이때의 아이템은 엔티티나 레코드가 아니라, 데이터 처리 작업에서 사용되는 처리 단위입니다.
배치 구성의 마지막 비트는 작업이 완료될 때 알림을 받는 방법입니다. 다음 예제(src/main/java/guides/batchprocessing/JobCompletionNotificationListener.java)에서는 이러한 클래스를 보여줍니다.
package guides.batchprocessing;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.jdbc.core.DataClassRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}
@Override
public void afterJob(JobExecution jobExecution) {
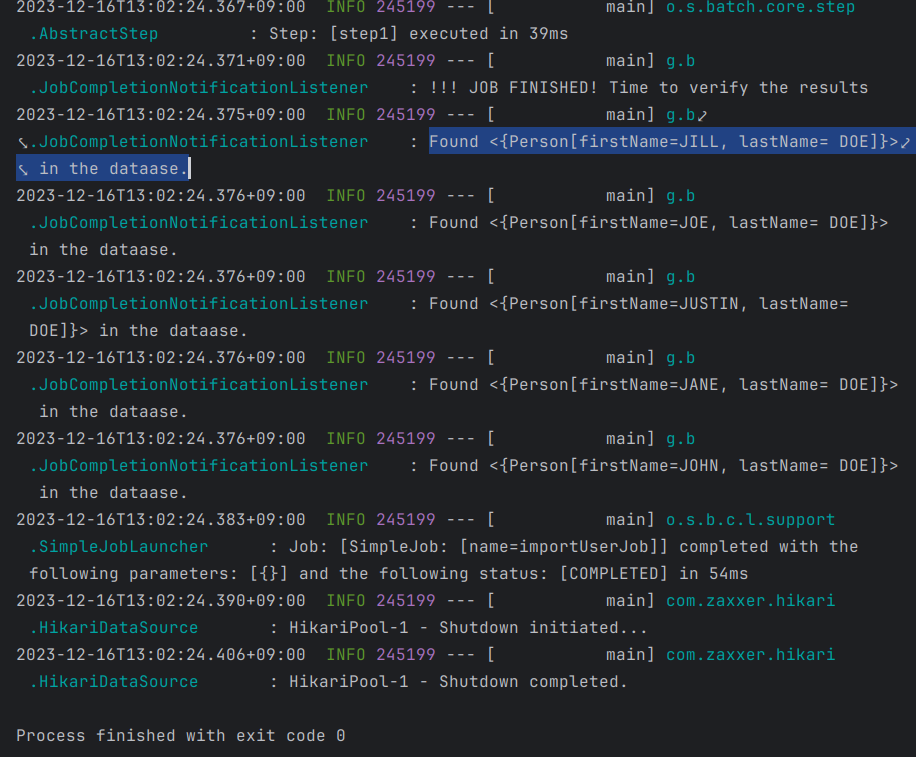
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate
.query("SELECT first_name, last_name FROM people", new DataClassRowMapper<>(Person.class))
.forEach(person -> log.info("Found <{{}}> in the dataase.", person));
}
}
}- 스프링 배치에서 Entity 클래스는 일반적인 POJO(Plain Old Java Object)이며, 데이터베이스 테이블의 열과 매핑되는 필드들을 포함합니다. 이러한 Entity 클래스는 배치 작업에서 데이터를 읽어들이고, 가공한 뒤 데이터를 저장하는 데 사용됩니다. 예를 들어, 스프링 배치에서 사용되는 JPA를 이용하여 Entity 클래스와 데이터베이스 테이블 간의 매핑을 설정할 수 있습니다.
-
Job, JobExecution, JobExecutionListener의 차이
-
Job: 스프링 배치에서 실행되는 배치 작업 단위를 나타냅니다. Job은 여러 스텝(Steps)으로 구성되어 있고, 배치 작업의 실행 흐름을 제어합니다.
-
JobExecution: Job의 실행을 나타내며, 배치 작업이 실행될 때 생성됩니다. JobExecution은 배치 작업의 상태와 메타데이터를 포함하고 있으며, 해당 작업의 진행 상태를 추적하고 관리합니다.
-
JobExecutionListener: 스프링 배치의 리스너 인터페이스 중 하나로, Job의 실행 상태 변화를 감지하고 리스너 메서드를 호출합니다.
beforeJob()과afterJob()메서드를 구현하여 Job의 시작 전과 끝난 후에 원하는 작업을 수행할 수 있습니다.
-
-
BatchStatus의 종류
BatchStatus는 스프링 배치에서 배치 작업(Job 또는 Step)의 상태를 나타내는 열거형(Enum)입니다. 몇 가지 주요한BatchStatus의 값은 다음과 같습니다:- COMPLETED: 배치 작업이 성공적으로 완료됨을 나타냅니다.
- FAILED: 배치 작업이 실패함을 나타냅니다.
- STARTING: 배치 작업이 시작되었지만 아직 완료되지 않았음을 나타냅니다.
- STARTED: 배치 작업이 시작되었고 진행 중임을 나타냅니다.
-
chunk의 커밋단위가 afterJob 함수에 미치는 영향
chunk의 커밋 단위가afterJob()에 직접적인 영향을 주는 것은 아니지만, 스텝 실행 도중afterJob()이 호출될 수 있다는 점을 고려해야 합니다.
JobCompletionNotificationListener는 작업이 BatchStatus.COMPLETED일 때를 수신한 다음 JdbcTemplate을 사용하여 결과를 검사합니다.
애플리케이션을 실행 가능하게 만들기
일괄 처리는 웹 앱 및 WAR 파일에 포함될 수 있지만 아래에 설명된 더 간단한 접근 방식을 사용하면 독립 실행형 애플리케이션이 생성됩니다. 좋은 오래된 Java main() 메소드에 의해 구동되는 단일 실행 가능한 JAR 파일에 모든 것을 패키지합니다.
Spring 이니셜라이저는 당신을 위해 애플리케이션 클래스를 생성했습니다. 이 간단한 예에서는 추가 수정 없이 작동합니다. 다음 목록(src/main/java/guides/batchprocessing/BatchProcessingApplication.java)은 애플리케이션 클래스를 보여줍니다.
package guides.batchprocessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BatchProcessingApplication {
public static void main(String[] args) {
System.exit(SpringApplication.exit(SpringApplication.run(BatchProcessingApplication.class, args)));
}
}SpringApplication.exit() 및 System.exit()는 작업 완료 시 JVM이 종료되는지 확인합니다. 자세한 내용은 Spring Boot 참조 문서의 애플리케이션 종료 섹션을 참조하세요.
데모 목적으로 JdbcTemplate을 생성하고, 데이터베이스를 쿼리하고, 일괄 작업이 삽입하는 사람들의 이름을 인쇄하는 코드가 있습니다.
애플리케이션이 어떻게
@EnableBatchProcessing주석을 사용하지 않는지 확인하세요. 이전에는@EnableBatchProcessing을 사용하여 Spring Boot의 Spring Batch 자동 구성을 활성화할 수 있었습니다. Spring Boot v3.0부터 이 주석은 더 이상 필요하지 않으며 Spring Boot의 자동 구성을 사용하려는 애플리케이션에서 제거해야 합니다.@EnableBatchProcessing으로 주석이 추가되거나 Spring Batch의DefaultBatchConfiguration을 확장하는 Bean을 정의하여 자동 구성을 취소하도록 정의할 수 있으므로 애플리케이션이 Spring Batch 구성 방법을 완전히 제어할 수 있습니다.