이 가이드는 RSS 피드(Spring 블로그)에서 데이터를 검색하고 데이터를 조작한 다음 파일에 쓰는 간단한 애플리케이션을 만들기 위해 Spring Integration을 사용하는 프로세스를 안내합니다. 이 가이드에서는 전통적인 Spring 통합 XML 구성을 사용합니다. 다른 가이드에서는 Lambda 표현식을 포함하거나 포함하지 않고 Java 구성 및 DSL을 사용하는 방법을 보여줍니다.
Spring Integration의 특징과 장점
-
엔터프라이즈 메시지 기반 통합 지원:
- 다양한 시스템, 프로토콜, 데이터 형식 간 메시지 교환을 지원합니다.
-
엔터프라이즈 시스템 관리 및 처리:
- 다양한 이벤트, 데이터, 작업 등을 효율적으로 관리하고 처리할 수 있습니다.
-
다양한 소스와의 통합:
- 메시지 큐, 웹 서비스, 파일 시스템, 데이터베이스 등 다양한 소스와의 통합을 지원합니다.
-
비동기적이고 효율적인 통합:
- 비동기적 방식으로 시스템을 구축하여 효율적인 데이터 처리가 가능합니다.
-
통합 패턴 지원:
- 메시지 라우팅, 필터링, 변환, 분배, 집계 등 다양한 통합 패턴을 지원하여 복잡한 시나리오를 간단하게 다룰 수 있습니다.
-
XML과 JavaConfig 지원:
- 과거에는 XML을 주로 사용했지만 최신 버전에서는 Java 기반의 구성을 선호하며, XML과 JavaConfig 두 가지 방식을 모두 지원합니다.
-
JavaConfig의 장점:
- 타입 안정성, IDE 지원으로 코드의 가독성과 유지보수성을 향상시킵니다.
- 프로그래밍 언어인 자바로 작성되기 때문에 리팩토링 및 디버깅이 용이합니다.
-
선택의 유연성:
- XML과 JavaConfig를 모두 지원하므로 개발자들은 선호하는 방식을 선택하여 사용할 수 있습니다.
Spring Integration의 구성 요소
폴링 (Polling)
정기적으로 외부 시스템에서 데이터를 조회하고 메시지를 생성하여 통합 플로우에 제공합니다. 주기적으로 데이터를 수집하거나 외부 시스템의 변경 사항을 감지하는 데 사용됩니다.
채널 (Channel)
메시지의 발신자와 수신자 간의 통신을 위한 경로로, 메시지가 여러 컴포넌트를 통해 전달됩니다. 다양한 컴포넌트 간에 비동기적으로 데이터를 전송하고 결합도를 줄입니다.
어댑터 (Adapter)
외부 시스템과의 통합을 담당하며, Spring Integration의 플로우에 외부 데이터를 가져오거나 내보내는 역할을 합니다. 폴링 어댑터, 메시지 변환기, 파일이나 데이터베이스와의 상호작용을 담당할 수 있습니다.
게이트웨이 (Gateway)
메시지를 받아들이고 외부 시스템과의 통신을 담당합니다. 자바 인터페이스로 정의되어, 외부 시스템과의 상호작용을 캡슐화하여 사용자가 간편하게 사용할 수 있도록 합니다.
엔드포인트 (Endpoint)
통합 플로우의 시작 지점이나 최종 처리 지점으로 사용되며, 메시지가 시작되거나 종료되는 위치를 나타냅니다. 특정 작업을 수행하는 데 사용됩니다.
변환기 (Transformer)
메시지를 받아들여 내용을 변경하거나 새로운 형식으로 변환합니다. 메시지의 데이터를 다른 형식으로 매핑하거나 가공하여 필요한 형태로 변환합니다.
필터 (Filter)
메시지를 받아서 조건을 적용하고, 조건을 충족하지 않는 메시지를 걸러냅니다. 특정 조건에 따라 메시지를 처리하거나 무시할 수 있습니다.
라우터 (Router)
메시지의 특정 속성이나 조건에 따라 다른 채널로 메시지를 전달합니다. 이를 통해 메시지가 여러 처리자에게 전달되거나 특정 처리자에게만 전달될 수 있습니다.
분배자 (Splitter)
하나의 메시지를 여러 개의 작은 메시지로 분할하고 각각을 다른 채널로 보냅니다. 주로 컬렉션을 분해하여 각 항목을 별도로 처리하는 데 사용됩니다.
어그리게이터 (Aggregator)
여러 메시지를 수집하고 그룹핑하여 하나의 메시지로 만들거나, 일정 조건을 충족할 때까지 여러 메시지를 모아서 하나로 합칩니다.
서비스 액티베이터 (Service Activator)
외부 서비스를 호출하거나 비즈니스 로직을 실행하여 메시지를 처리하고 결과를 생성합니다. 외부 시스템과의 통합을 담당하는 역할을 합니다.
Spring Integration과 Spring Batch의 차이
(1) Spring-Batch는 job을 실행하고, batch-processing 어플리케이션을 작성하는데 사용돼요. Spring-Integration은 lightweight messaging(경량 메시징)을 지원하기 위해서 고수준으로 추상화된 다양한 Adaptor를 제공하고, 이러한 Adaptor들을 이용해서 외부 시스템과 지속적으로 통합을 가능하게 합니다.
(2) 기본적으로, 두개는 전혀 다른 프로젝트에요.
Spring-Integration은 이미 잘 알려진 Enterprise Integration Patterns를 스프링에서 지원하도록 개발되었고, Spring-Batch는 하나의 작업을 작은 단위(submission)으로 분할하여 처리하는 것에 중점을 두고 개발되었어요. 애초에 목적 자체가 전혀 다른 프로젝트인거죠.
가령, Spring-Integration은 Producer/Queue/Consumer의 가장 기본적인 형태로 큐시스템을 운영할 때 사용할 수 있을테고요. Spring-Batchs는 Lambda Architecture의 Batch Layer, Serving Layer를 구성하는데 훨씬 적합해요.
Message Channel
Lambda Architecture(What Is Lambda Architecture?)

Spring Initializr에서 확인해보면, Spring Integration은 Messaging, Spring Batch는 I/O가 태깅되어있다.
Spring Integration과 Batch, RabbitMQ, JMS 의 차이
비즈니스 레벨이란 특정 비즈니스 도메인이나 비즈니스 프로세스에 직접적으로 관련된 작업이나 로직을 의미합니다. 이는 회사나 조직의 핵심적인 부분으로, 실제로 제품이나 서비스를 개발하고 운영하는 데 필요한 로직과 프로세스를 포함합니다.
Spring Integration은 비즈니스 레벨의 통합을 제공합니다. 이는 시스템 간의 상호작용을 중심으로, 비즈니스 로직의 흐름과 관련된 통합을 다룹니다. 예를 들어, 주문 처리, 결제 시스템, 배송 관리 등과 같은 비즈니스 프로세스에서 다양한 시스템 간의 통신을 관리하고 통합하는 데 사용됩니다.
그에 비해 JMS는 애플리케이션 간의 메시지 전달을 위한 표준 API입니다. 이것은 더 일반적인 수준의 메시징 시스템 간 통신을 지원하며, 특정 비즈니스 로직이나 프로세스와 직접적으로 연결되어 있는 것은 아닙니다. JMS는 단순히 메시지를 보내고 받는 기능을 제공하며, 이는 비즈니스 로직이나 프로세스와는 별개로 동작합니다.
Spring Batch는 대용량 데이터의 일괄 처리를 위한 프레임워크로, 데이터 처리에 초점을 맞추어 비즈니스 데이터를 가공하고 처리하는데 사용됩니다. 이는 일괄 작업을 수행하기 위한 과정을 관리하고, 데이터 처리와 관련된 비즈니스 로직을 수행합니다.
Spring RabbitMQ는 RabbitMQ와 Spring을 연동하여 메시지 큐를 사용한 안정적인 통신을 지원하는 프레임워크로, 메시지 기반의 비동기 통신을 제공합니다. 이는 비즈니스 로직과 직접적으로 연결되어 있을 수 있지만, 주로 메시지 큐를 통한 안정적인 통신에 중점을 둡니다.
이처럼 각 기술들은 서로 다른 레벨에서 작동하며, Spring Integration은 비즈니스 레벨의 통합을 다루는 반면, 다른 기술들은 주로 시스템 간 통신, 데이터 처리, 메시지 전달 등의 다른 측면에서 작동합니다. 비즈니스 레벨과의 연관성은 있지만, 각각이 서로 다른 측면에서 작업하기 때문에 차이가 있습니다.
Spring Integration 네임스페이스
Spring Integration에서 네임스페이스는 XML 구성 파일에서 Spring Integration 구성 요소를 정의하기 위해 사용되는 것입니다. 네임스페이스를 사용하면 Spring XML 파일에서 Spring Integration 모듈의 구성 요소를 선언할 때 해당 모듈의 기능을 지원하는 요소들을 사용할 수 있습니다.
- integration: 기본 네임스페이스로, Spring Integration의 주요 기능을 정의합니다.
- file: 파일 시스템과 관련된 기능을 정의하는 네임스페이스입니다. 파일을 읽거나 쓰는 데 사용됩니다.
- feed: RSS나 Atom과 같은 피드를 처리하는 기능을 정의하는 네임스페이스입니다.
file과 feed의 차이
-
파일(File):
- 파일 시스템과 관련된 작업을 수행하는 데 사용됩니다.
- 주로 파일을 읽고 쓰는 작업에 관련된 Spring Integration의 컴포넌트들을 나타냅니다.
- 파일을 읽어들여서 메시지로 변환하거나, 메시지를 파일로 쓰는 등의 작업을 수행합니다.
- 파일 시스템에서의 입출력 작업을 통해 데이터를 처리하고 관리합니다.
-
피드(Feed):
- 일반적으로 RSS나 Atom과 같은 웹 피드(웹 사이트에서 새로운 콘텐츠가 업데이트될 때마다 제공되는 정보)를 다루는 데 사용됩니다.
- 특정 웹사이트의 새로운 콘텐츠를 주기적으로 읽어와서 해당 데이터를 처리하거나 변환하는 데 사용됩니다.
- 주로 웹사이트에서의 업데이트된 정보를 감지하고, 해당 정보를 시스템에 통합하는 데 활용됩니다.
즉, 파일은 로컬 파일 시스템에서 데이터를 읽거나 쓰는 데 사용되고, 피드는 웹상의 특정 웹사이트에서의 업데이트된 정보를 가져오고 처리하는 데 사용됩니다. Spring Integration에서는 이러한 두 가지 유형의 데이터 소스를 처리하기 위한 컴포넌트들을 제공합니다.
RSS와 Atom
RSS(Really Simple Syndication)와 Atom은 모두 웹 피드 포맷으로, 웹사이트의 업데이트된 내용을 구독자에게 전달하는데 사용됩니다.
-
RSS (Really Simple Syndication):
- 웹사이트의 콘텐츠를 정기적으로 업데이트하는 방법으로 사용되는 피드 포맷입니다.
- XML 기반의 포맷으로, 웹사이트의 새로운 글, 기사, 뉴스, 블로그 등의 콘텐츠를 쉽게 구독할 수 있도록 해줍니다.
- 주로
<item>요소를 사용하여 각각의 항목을 정의하고, 이러한 항목들이 모여 피드를 형성합니다. - 주로
<title>,<link>,<description>,<pubDate>등의 요소로 이루어져 있습니다.
-
Atom:
- 또 다른 웹 피드 포맷으로, RSS와 유사하지만 보다 엄격하고 일관된 구조를 갖추고 있습니다.
- 더욱 엄격한 규격을 준수하며 XML 기반의 피드 포맷입니다.
- XML 네임스페이스를 사용하여 명시적으로 정의되어 있어 확장성이 뛰어나며, 좀 더 일관된 구조를 제공합니다.
<entry>요소를 사용하여 각 항목을 정의하고, 각 항목은<title>,<link>,<summary>,<published>등의 요소들을 포함합니다.
RSS와 Atom은 모두 웹사이트의 최신 콘텐츠를 구독하고 업데이트된 정보를 제공하는 데 사용되며, 대부분의 RSS 리더나 피드 읽기 앱에서 둘 다 지원됩니다.
What You Will Build
전통적인 XML 구성을 사용하여 Spring Integration으로 흐름을 생성합니다.
build.gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.0'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'guides'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '17'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-integration'
implementation 'org.springframework.integration:spring-integration-feed'
implementation 'org.springframework.integration:spring-integration-file'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.integration:spring-integration-test'
}
tasks.named('test') {
useJUnitPlatform()
}Define an Integration Flow
이 가이드의 샘플 애플리케이션에서는 다음과 같은 Spring 통합 흐름을 정의합니다.
- spring.io의 RSS 피드에서 블로그 게시물을 읽습니다.
- 게시물 제목과 게시물 URL로 구성된 쉽게 읽을 수 있는
String로 변환합니다. - 해당
String을 파일 끝에 추가합니다(/tmp/si/SpringBlog).
통합 흐름을 정의하려면 Spring Integration의 XML 네임스페이스에서 몇 가지 요소를 사용하여 Spring XML 구성(Configuration)을 생성할 수 있습니다. 특히 원하는 통합(Integration) 흐름을 위해 코어(core), 피드(feed) 및 파일(file)과 같은 Spring 통합 네임스페이스의 요소를 사용하여 작업합니다. (feed, file을 추가하기 위해 이니셜라이저에서 제공하는 build 파일을 직접 수정해야 합니다.)
다음 XML 구성 파일(src/main/resources/integration/integration.xml)은 통합 흐름을 정의합니다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:int="http://www.springframework.org/schema/integration"
xmlns:file="http://www.springframework.org/schema/integration/file"
xmlns:feed="http://www.springframework.org/schema/integration/feed"
xsi:schemaLocation="http://www.springframework.org/schema/integration/feed https://www.springframework.org/schema/integration/feed/spring-integration-feed.xsd
http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration/file https://www.springframework.org/schema/integration/file/spring-integration-file.xsd
http://www.springframework.org/schema/integration https://www.springframework.org/schema/integration/spring-integration.xsd">
<feed:inbound-channel-adapter id="news" url="https://spring.io/blog.atom" auto-startup="${auto.startup:true}">
<int:poller fixed-rate="5000"/>
</feed:inbound-channel-adapter>
<int:transformer
input-channel="news"
expression="payload.title + ' @ ' + payload.link + '#{systemProperties['line.separator']}'"
output-channel="file"/>
<file:outbound-channel-adapter id="file"
mode="APPEND"
charset="UTF-8"
directory="/tmp/si"
filename-generator-expression="'${feed.file.name:SpringBlog}'"/>
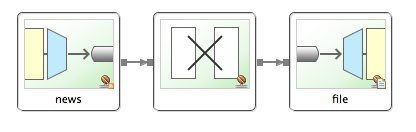
</beans>여기에는 세 가지 통합 요소가 작용합니다.
-
<feed:inbound-channel-adapter>: 폴링당 하나씩 게시물을 검색하는 인바운드 어댑터입니다. 여기에서 구성한 대로 5초마다 폴링합니다. 게시물은news(어댑터 ID에 해당)라는 채널에 배치됩니다. -
<int:transformer>: 뉴스 채널의 항목(com.rometools.rome.feed.synd.SyndEntry)을 변환하여 항목 제목(payload.title)과 링크(payload.link)를 추출하고 이를 읽을 수 있는String( 줄 바꿈을 추가합니다). 그런 다음String은file이라는 출력 채널로 전송됩니다. -
<file:outbound-channel-adapter>: 채널(이름이 지정된file)의 콘텐츠를 파일에 쓰는 아웃바운드 채널 어댑터입니다. 특히 여기에 구성된 대로file채널의 모든 항목을/tmp/si/SpringBlog의 파일에 추가합니다.이 통합 흐름에서 사용된 Spring Integration의 핵심 개념인 폴링, 채널, 어댑터에 대해 설명할게요.
폴링(Polling)
폴링은 주기적으로 외부 리소스를 확인하고 데이터를 가져오는 방법 중 하나입니다. 이 흐름에서 <feed:inbound-channel-adapter> 요소는 외부의 RSS 피드(https://spring.io/blog.atom)에서 새로운 블로그 게시물을 가져오기 위해 폴링을 수행합니다.
<feed:inbound-channel-adapter>: 외부 리소스를 주기적으로 확인하며, 설정된 주기(여기서는fixed-rate="5000"으로 5초마다)마다 해당 피드에서 새로운 내용을 가져옵니다. 이를 통해news라는 채널에 새로운 게시물을 전송합니다.
채널(Channel)
채널은 Spring Integration에서 메시지 전송을 위한 매개체로 사용됩니다. 이 흐름에서는 두 개의 채널을 사용합니다.
news채널:<feed:inbound-channel-adapter>가 가져온 새로운 게시물을 전달받는 채널입니다.file채널:<int:transformer>를 거쳐 생성된 문자열을 전송하는 채널로, 이 내용을 파일에 작성하는 데 사용됩니다.
어댑터(Adapter)
어댑터는 Spring Integration의 엔드포인트로써, 채널과 외부 시스템 사이에서 데이터를 전송합니다.
<feed:inbound-channel-adapter>: 외부 리소스(여기서는 RSS 피드)를 가져와 새로운 데이터를news채널로 전송합니다.<int:transformer>:news채널에서 메시지를 가져와 제목과 링크를 추출한 후, 이를 읽을 수 있는 형태의 문자열로 변환하여file채널로 전송합니다.<file:outbound-channel-adapter>:file채널에 도착한 데이터를 파일 시스템에 씁니다. 이 흐름에서는/tmp/si/SpringBlog파일에 데이터를 추가하는 아웃바운드 어댑터가 사용됩니다.
다음 이미지는 이 간단한 흐름을 보여줍니다.
지금은 auto-startup 속성을 무시하십시오. 나중에 테스트를 논의할 때 이에 대해 다시 논의하겠습니다. 지금은 기본적으로 true입니다. 즉, 애플리케이션이 시작될 때 게시물을 가져옵니다. 또한 filename-generator-expression의 속성 자리 표시자(placeholder)를 기록해 두세요. 이는 기본값이 SpringBlog이지만 속성으로 재정의될 수 있음을 의미합니다.
애플리케이션을 실행 가능하게 만들기
더 큰 애플리케이션(아마도 웹 애플리케이션) 내에서 Spring 통합 흐름을 구성하는 것이 일반적이지만 더 간단한 독립형 애플리케이션에서 정의하지 말라는 법은 없습니다. 이것이 다음으로 수행할 작업입니다. 통합 흐름을 시작하고 통합 흐름을 지원하기 위한 소수의 Bean을 선언하는 기본 클래스를 생성합니다. 또한 애플리케이션을 독립 실행형 JAR 파일로 빌드합니다. 우리는 Spring Boot의 @SpringBootApplication 주석을 사용하여 애플리케이션 컨텍스트를 생성합니다. 이 가이드에서는 통합 흐름에 XML 네임스페이스를 사용하므로 이를 애플리케이션 컨텍스트에 로드하려면 @ImportResource 주석을 사용해야 합니다. 다음 목록(src/main/java/guides/integration/IntegrationApplication.java)은 애플리케이션 파일을 보여줍니다.
package guides.intigration;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.annotation.ImportResource;
@SpringBootApplication
@ImportResource("/integration/integration.xml")
public class IntegrationApplication {
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext ctx = new SpringApplication(IntegrationApplication.class).run(args);
System.out.println("Hit Enter to terminate");
System.in.read();
ctx.close();
}
}1.@ImportResource("/integration/integration.xml"): 이 애노테이션은 XML 구성 파일을 가져와서 사용하는 데 사용되는데, /integration/integration.xml 경로에 있는 XML 파일을 이 애플리케이션에 import하여 사용하겠다는 것을 의미해.
2.ConfigurableApplicationContext ctx = new SpringApplication(IntegrationApplication.class).run(args);: Spring Boot 애플리케이션을 실행하여 애플리케이션 컨텍스트를 가져오고 있어.
3.System.in.read();: 사용자의 입력을 기다리는 코드로, Enter 키 입력을 기다리며 애플리케이션이 실행되어 있는 상태를 유지함.
4.ctx.close();: 애플리케이션 실행이 종료되면 애플리케이션 컨텍스트를 닫아 자원을 해제함.
Run the application
이제 다음 명령을 실행하여 jar에서 애플리케이션을 실행할 수 있습니다.
java -jar build/libs/{project_id}-0.1.0.jar
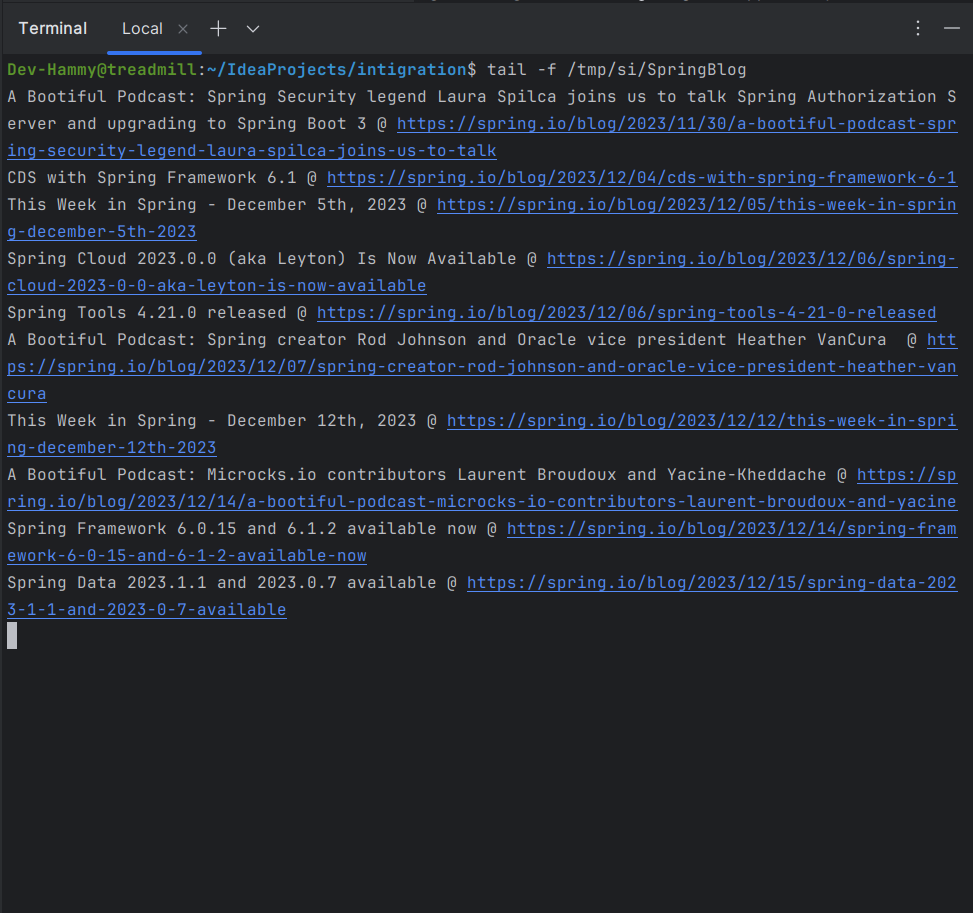
... app starts up ...애플리케이션이 시작되면 RSS 피드에 연결되어 블로그 게시물을 가져오기 시작합니다. 애플리케이션은 정의한 통합 흐름을 통해 해당 게시물을 처리하고 궁극적으로 게시물 정보를 /tmp/si/SpringBlog의 파일에 추가합니다.
애플리케이션이 한동안 실행된 후 /tmp/si/SpringBlog에서 파일을 보고 몇 가지 게시물의 데이터를 볼 수 있습니다. UNIX 기반 운영 체제에서는 다음 명령을 실행하여 파일을 추적(tail)하여 작성된 결과를 확인할 수도 있습니다.
Testing
package guides.integration;
import com.rometools.rome.feed.synd.SyndEntryImpl;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.integration.endpoint.SourcePollingChannelAdapter;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.MessageBuilder;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import static org.assertj.core.api.Assertions.assertThat;
@SpringBootTest({"auto.startup=false", "feed.file.name=Test"})
public class FlowTests {
@Autowired
private SourcePollingChannelAdapter newsAdapter;
@Autowired
private MessageChannel news;
@Test
public void test() throws Exception {
assertThat(this.newsAdapter.isRunning()).isFalse();
SyndEntryImpl syndEntry = new SyndEntryImpl();
syndEntry.setTitle("Test Title");
syndEntry.setLink("http://characters/frodo");
File out = new File("/tmp/si/Test");
out.delete();
assertThat(out.exists()).isFalse();
this.news.send(MessageBuilder.withPayload(syndEntry).build());
assertThat(out.exists()).isTrue();
BufferedReader br = new BufferedReader(new FileReader(out));
String line = br.readLine();
assertThat(line).isEqualTo("Test Title @ http://characters/frodo");
br.close();
out.delete();
}
}newsAdapter에서 Autowired가 잘못되었다며 IDE에서 경고하긴 하지만 테스트는 성공적으로 실행된다.
SyndEntry는 일반적으로 RSS 또는 Atom과 같은 웹 피드에서 사용되는 항목(entry)을 나타내는 클래스입니다. 이는 Rome 프로젝트(Rome Syndication)에서 제공하는 API 중 하나입니다.
Rome Syndication은 RSS 및 Atom과 같은 웹 피드를 생성, 파싱 및 처리하기 위한 Java 라이브러리입니다. SyndEntry는 이러한 웹 피드에서 가져온 개별 항목을 나타내며, 제목(title), 링크(link), 요약(summary) 등의 정보를 포함할 수 있습니다.
Spring Integration의 예제 코드에서 SyndEntryImpl을 사용하여 테스트에서 가상의 SyndEntry 객체를 생성하고, 이 객체에 제목과 링크를 설정한 후, 이를 이용하여 테스트 데이터를 생성하고 있습니다.
이 테스트에서는 Spring Boot의 테스트 지원을 사용하여 auto.startup이라는 속성을 false로 설정합니다. 특히 CI 환경에서 테스트를 위해 네트워크 연결에 의존하는 것은 일반적으로 좋은 생각이 아닙니다. 대신, 피드 어댑터가 시작되는 것을 방지하고 나머지 흐름에서 처리할 수 있도록 뉴스 채널에 SyndEntry를 삽입합니다. 또한 테스트에서는 다른 파일에 쓸 수 있도록 Feed.file.name을 설정합니다. 그런 다음:
- 어댑터가 중지되었는지 확인합니다.
- 테스트
SyndEntry를 만듭니다. - 테스트 출력 파일을 삭제합니다(있는 경우).
- 메시지를 보냅니다.
- 파일이 존재하는지 확인합니다.
- 파일을 읽고 데이터가 예상한 대로인지 확인합니다.