집계 작업 섹션에서는 컬렉션 roster에 있는 모든 남성 구성원의 평균 연령을 계산하는 다음 작업 파이프라인을 설명합니다.
double average = roster.stream().filter(p -> p.getGender() == Person.Sex.MALE).mapToInt(Person::getAge).average().getAsDouble();
JDK에는 스트림의 내용을 결합하여 하나의 값을 반환하는 많은 터미널 작업(예: average, sum, min, max 및 count)이 포함되어 있습니다. 이러한 작업을 축소 작업(reduction operation)이라고 합니다. JDK에는 단일 값 대신 컬렉션을 반환하는 축소 작업(reduction operation)도 포함되어 있습니다. 많은 축소 작업은 값의 평균을 찾거나 요소를 범주(categories)로 그룹화하는 등의 특정 작업을 수행합니다. 그러나 JDK는 이 섹션에서 자세히 설명하는 범용 축소 작업인 reduce 및 collect를 제공합니다.
이 섹션에서는 다음 주제를 다룹니다.
Stream.reduce메서드Stream.collect메서드
ReductionExamples예제에서 이 섹션에 설명된 코드 발췌문을 찾을 수 있습니다.
Stream.reduce 메서드
Stream.reduce 메서드는 범용 축소 작업입니다. 컬렉션 roster에 있는 남성 회원의 연령 합계를 계산하는 다음 파이프라인을 고려하세요. Stream.sum 축소 작업(reduction operation)을 사용합니다.
Integer totalAge = roster.stream().mapToInt(Person::getAge).sum();이를 Stream.reduce 작업을 사용하여 동일한 값을 계산하는 다음 파이프라인과 비교해 보세요.
Integer totalAgeReduce = roster.stream().map(Person::getAge).reduce(0, (a,b) -> a+b);이 예제의 축소 작업은 두 가지 인수를 사용합니다.
-
identity: Identity 요소는 reduction의 초기 값이자 스트림에 요소가 없는 경우 기본 결과입니다. 이 예에서 Identity 요소는0입니다. 이는 연령 합계의 초기 값이며 컬렉션roster에 구성원이 없는 경우 기본값입니다. -
accumulator: accumulator 함수는 두 가지 매개변수, 즉 reduction의 부분 결과(partial result)(이 예에서는 지금까지 처리된 모든 정수의 합계)와 스트림의 다음 요소(이 예에서는 정수)를 사용합니다. 새로운 부분 결과를 반환합니다. 이 예에서 accumulator 함수는 두 개의Integer값을 더하고Integer값을 반환하는 람다 식입니다.
(a, b) -> a + b축소 작업(reduce operation)은 항상 새 값을 반환합니다. 그러나 accumulator 함수는 스트림 요소를 처리할 때마다 새 값을 반환하기도 합니다. 스트림의 요소를 컬렉션과 같은 더 복잡한 개체로 reduce 하고 싶다고 가정해 보겠습니다. 이로 인해 애플리케이션 성능이 저하(hinder)될 수 있습니다. reduce 작업에, 요소를 컬렉션에 추가하는 작업이 포함된 경우 accumulator(누산기) 함수가 요소를 처리할 때마다 해당 요소를 포함하는 새 컬렉션을 생성하므로 이는 비효율적(inefficeint)입니다. 대신 기존 컬렉션을 업데이트하는 것이 더 효율적입니다. 다음 섹션에서 설명하는 Stream.collect 메서드를 사용하여 이 작업을 수행할 수 있습니다.
Stream.collect 메서드
요소를 처리할 때 항상 새 값을 생성하는 reduce 메서드와 달리 collect 메서드는 기존 값을 수정하거나 변경합니다.
스트림에서 값의 평균을 찾는 방법을 고려하십시오. 총 값 수(total number of values)와 해당 값의 합계(sum of those values)라는 두 가지 데이터가 필요합니다. 그러나 reduce 메서드 및 기타 모든 축소 메서드와 마찬가지로 collect 메서드는 하나의 값만 반환합니다. 다음 클래스인 Averager와 같이 총 값 수와 해당 값의 합계를 추적하는 멤버 변수가 포함된 새 데이터 형식을 만들 수 있습니다.
public class Averager implements IntConsumer {
private int total = 0;
private int count = 0;
public double average() {
return count > 0 ? ((double) total)/count : 0;
}
public void accept(int i) { total += i; count++; }
public void combine(Averager other) {
total += other.total;
count += other.count;
}
}다음 파이프라인은 Averager 클래스와 collect 메서드를 사용하여 모든 남성 구성원의 평균 연령을 계산합니다.
Averager averageCollect = roster.stream().filter(p -> p.getGender() == Person.Sex.MALE).map(Person::getAge).collect(Averager::new, Averager::accept, Average::combine);
System.out.println("Average age of male members: " + averageCollect.average());이 예제의 collect 작업은 세 가지 인수를 사용합니다.
-
supplier공급자:supplier는 factory 함수입니다. 새로운 인스턴스를 생성합니다.collect작업의 경우 결과 컨테이너의 인스턴스를 생성합니다. 이 예에서는Averager클래스의 새 인스턴스입니다. -
accumulator누산기:accumulator함수는 스트림 요소를 결과 컨테이너에 통합(incorporate)합니다. 이 예에서는count변수를 1만큼 증가시키고total멤버 변수에 스트림 요소 값(남성 구성원의 나이를 나타내는 정수)을 추가하여Averager결과 컨테이너를 수정합니다. -
combiner결합기:combiner함수는 두 개의 결과 컨테이너를 가져와서 그 내용을 병합합니다. 이 예에서는 다른Averager인스턴스의count멤버 변수만큼count변수를 증가시키고 다른Averager인스턴스의total멤버 변수 값을total멤버 변수에 추가하여Averager결과 컨테이너를 수정합니다.
다음 사항에 유의하세요.
supplier(공급자)는 reduce operation의 Identity 요소와는 반대로(as opposed to), 값이 아닌 람다 식(또는 메서드 참조)입니다.accumulator(누산기) 및combiner(결합기) 함수는 값을 반환하지 않습니다.- 병렬 스트림과 함께
collect작업을 사용할 수 있습니다. 자세한 내용은 병렬성(Parallelism) 섹션을 참조하세요. (병렬 스트림과 함께collect메소드를 실행하면 JDK는combiner함수가 이 예제의Averager객체와 같은 새 객체를 생성할 때마다 새 스레드를 생성합니다. 결과적으로 동기화(synchronization)에 대해 걱정할 필요가 없습니다.)
JDK는 스트림에 있는 요소의 평균 값을 계산하기 위한 average 연산을 제공하지만 스트림의 요소에서 여러 값을 계산해야 하는 경우 collect 연산과 사용자 정의 클래스를 사용할 수 있습니다.
collect 작업은 컬렉션에 가장 적합합니다. 다음 예에서는 collect 작업을 통해 남성 구성원의 이름을 컬렉션에 넣습니다.
List<String> nameOfMaleMembersCollect = roster.stream().filter(p -> p.getGender() == Person.Sex.MALE).map(p -> p.getName()).collect(Collectors.toList());이 버전의 collect 작업은 Collector 유형의 매개변수 하나를 사용합니다. 이 클래스는 세 개의 인수(supplier, accumulator, 및 combiner 함수)가 필요한 collect 작업에서 인수로 사용되는 함수를 캡슐화합니다.
Collectors 클래스에는 요소를 컬렉션으로 누적하고 다양한 기준에 따라 요소를 요약하는 등 유용한 reduction 작업이 많이 포함되어 있습니다. 이러한 reduction 작업은 Collector 클래스의 인스턴스를 반환하므로 이를 collect 작업의 매개 변수로 사용할 수 있습니다.
이 예에서는 스트림 요소를 List의 새 인스턴스에 누적하는 Collectors.toList 작업을 사용합니다. Collectors 클래스의 대부분의 작업과 마찬가지로 toList 연산자는 컬렉션이 아닌 Collector의 인스턴스를 반환합니다.
다음 예에서는 컬렉션 roster의 구성원을 성별로 그룹화합니다.
Map<Person.Sex, List<Person>> byGender = roster.stream().collect(Collectors.groupBy(Person::getGender));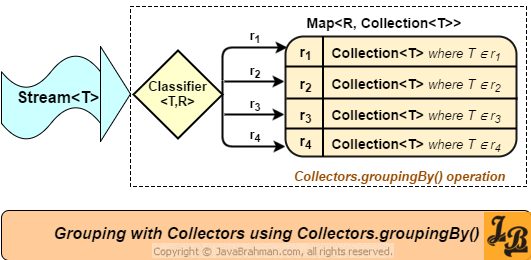
groupingBy 작업은 매개 변수(classification 분류 함수라고 함)로 지정된 람다 식을 적용한 결과 값이 키인 맵을 반환합니다. 이 예에서 반환된 맵에는 Person.Sex.MALE 및 Person.Sex.FEMALE이라는 두 개의 키가 포함되어 있습니다. 키의 해당 값은 분류 함수에 의해 처리될 때 키 값에 해당하는 스트림 요소를 포함하는 List의 인스턴스입니다. 예를 들어, Person.Sex.MALE 키에 해당하는 값은 모든 남성 구성원을 포함하는 List의 인스턴스입니다.
다음 예에서는 컬렉션 roster에 있는 각 구성원의 이름을 검색하고 성별을 기준으로 그룹화합니다.
Map<Person.Sex, List<String>> namesByGender = roster.stream().collect( Collectors.groupingBy(Person::getGender, Collectors.mapping(Person::getName, Collectors.toList())));
이 예제의 groupingBy 작업은 classification 함수와 Collector 인스턴스라는 두 개의 매개 변수를 사용합니다. Collector 매개변수를 downstream collector라고 합니다. 이는 Java 런타임이 다른 collector의 결과에 적용하는 collector입니다. 결과적으로 이 groupingBy 작업을 사용하면 groupingBy 연산자로 생성된 List 값에 collect 메서드를 적용할 수 있습니다. 이 예에서는 스트림의 각 요소에 매핑 함수 Person::getName을 적용하는 collector mapping을 적용합니다. 결과적으로 결과 스트림은 멤버 이름만으로 구성됩니다. 이 예와 같이 하나 이상의 downstream collector를 포함하는 파이프라인을 multilevel reduction라고 합니다.
다음 예에서는 각 성별 구성원의 총 연령을 검색합니다.
Map<Person.Sex, Integer> totalAgeByGender = roster.stream().collect(Collectors.groupingBy(Person::getGender, Collectors.reducing(0, Person::getAge, Integer::sum)));reducing 작업에는 세 개의 매개변수가 사용됩니다.
- identity:
Stream.reduce작업과 마찬가지로 Identity 요소는 reduction의 초기 값이자 스트림에 요소가 없는 경우 기본 결과입니다. 이 예에서 Identity 요소는 0입니다. 이는 연령 합계의 초기 값이며 구성원이 없는 경우 기본값입니다. - mapper : reducing 작업은 이 mapper 함수를 모든 스트림 요소에 적용합니다. 이 예에서 매퍼는 각 구성원의 나이를 검색합니다.
- operatuin: operation 함수는 매핑된 값을 reduce 하는 데 사용됩니다. 이 예에서 작업 함수는 Integer 값을 추가합니다.
다음 예에서는 각 성별 구성원의 평균 연령을 검색(retrieve)합니다.
Map<Person.Sex, Double> averageAgeGender = roster.stream().collect(Collectors.groupingBy(Person::getGender, Collectors.averagingInt(Person::getAge))));