Big-Query
빅쿼리(Big-Query)란???
- 대규모 데이터 저장 및 분석 플랫폼이며 데이터 웨어하우스라고 생각하면 된다.
- 스토리지와 컴퓨팅이 분리되어 있어 데이터 웨어하우스의 용량을 원하는대로 계획할 수 있다.
- SQL과 문법이 유사하여 사용하기 매우 쉽다.
- 내부적으로 관리형 열 형식 스토리지, 대량 동시 실행, 자동 성능 최적화 기능을 제공한다.
- 모든 배치와 스트리밍 데이터를 분석, 강력한 스트리밍 수집기능으로 실시간으로 데이터를 캡쳐하고 분석해서 통계를 항상 최신의 상태로 유지한다.
빅쿼리(Big-Query)의 특징
- 클라우드 서비스이기 때문에 설치나 운영이 필요없다.
- SQL 언어를 사용한다.
- 클라우드 스케일의 인프라를 활용한 대용량 지원과 빠른 성능
- 데이터 복제를 통해서 안정성이 높다.
- 배치와 스트리밍을 모두 지원한다.
- 비용이 싸다.
빅쿼리(Big-Query)가 빠른 이유
-
트래픽 최소화
관계형 데이터베이스들은 레코드 단위로 조회를 하지만 빅쿼리는 컬럼 기반 저장방식을 사용하기 때문에 해당 컬럼만 조회한다. -
높은 압축 비율
컬럼 기반으로 저장하기 때문에 같은 타입의 데이터들이 몰려서 저장된다. 그래서 1:10 비율로 압축이 가능하다. -
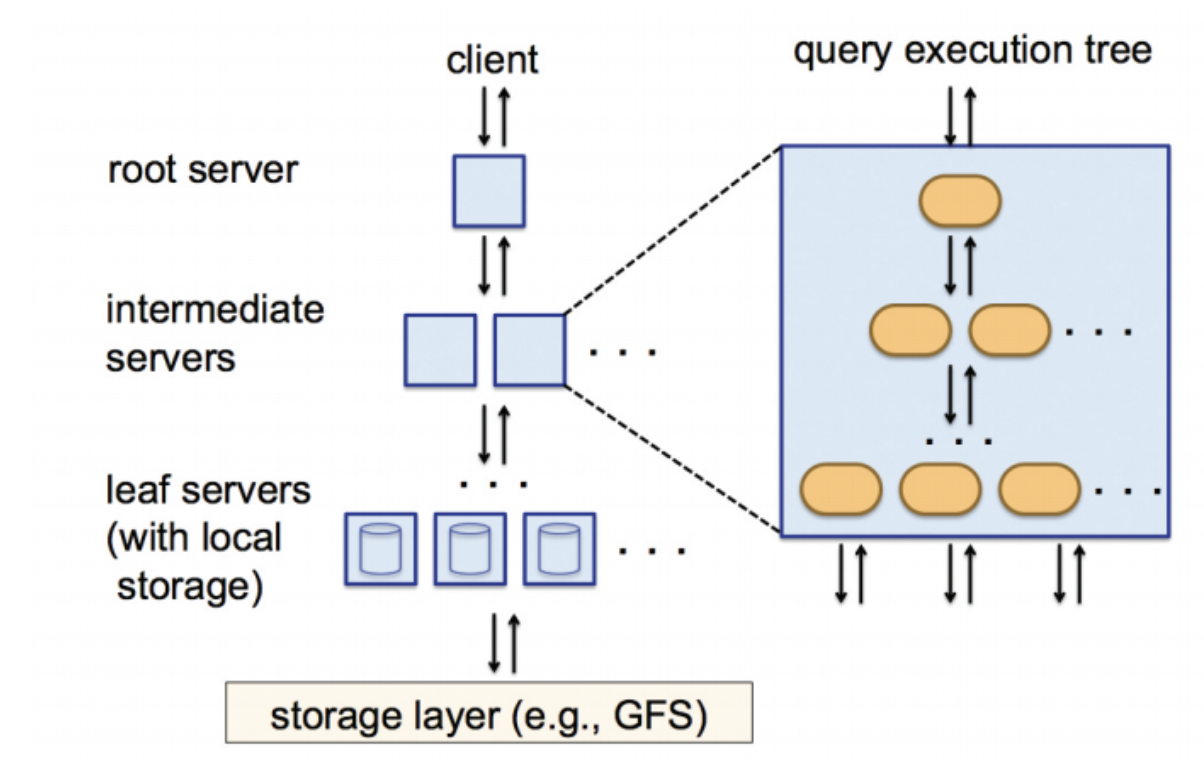
트리 기반의 분산처리
 이미지 출처 : https://happyer16.tistory.com/entry/BigQuery-1%EB%B9%85%EC%BF%BC%EB%A6%AC%EB%9E%80
이미지 출처 : https://happyer16.tistory.com/entry/BigQuery-1%EB%B9%85%EC%BF%BC%EB%A6%AC%EB%9E%80
root server : 클라이언트의 쿼리를 분석하여 분산 머신에서 동작하는 수많은 작은 단위의 쿼리문을 만들어서 intermediate servers에 전달한다.
intermediate servers : leaf servers에게 쿼리를 전달한다. 그리고 쿼리의 결과 값으로 반환되는 값들을 합쳐서 root server에게 전달한다.
leaf servers : 실제 쿼리가 동작하는 곳이다.
참고한 사이트 :
https://spacek82.tistory.com/68
https://tora-it-kingdom.tistory.com/11
https://happyer16.tistory.com/entry/BigQuery-1%EB%B9%85%EC%BF%BC%EB%A6%AC%EB%9E%80

백엔드 개발자가 되자!