💡 문제
🤔 고민사항
- 백트래킹을 정복하기 위해 백준에서 백트래킹 문제집을 조지고 있다.
- 얼핏 어렵지 않게 느껴졌고, [백준 1182번] 부분수열의 합 (실버2, Java) 와 유사하게 느껴졌다.
트리를 그려서 dfs를 구현해야겠다.
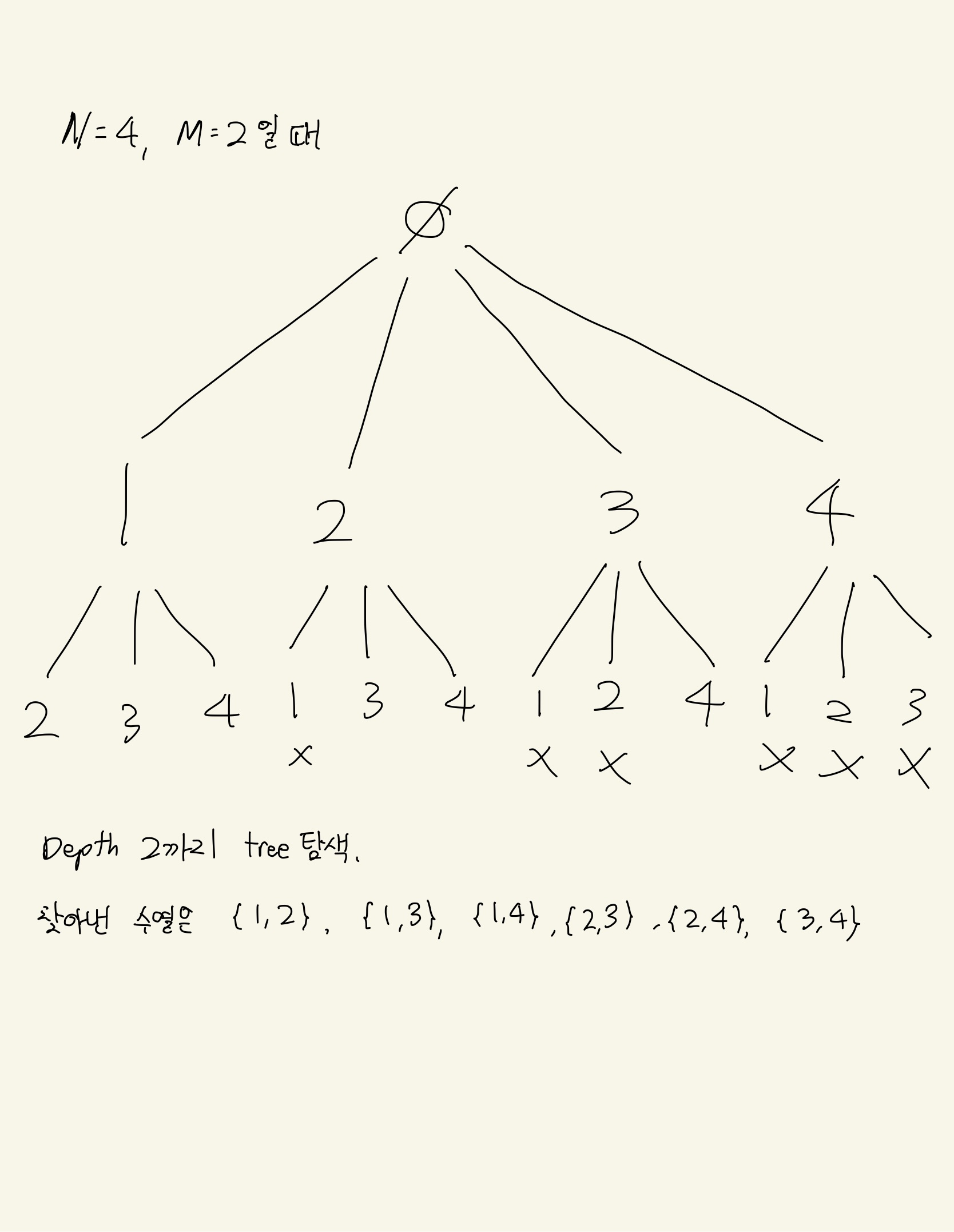
- 예제의 N=4, M=2 일 경우의 트리 탐색이다.
- 제약 조건의 '오름차순 수열이어야 한다'는 깊이 탐색을 왼쪽에서부터 하면 자연스레 해결이 된다.
- 제약 조건의 '중복되는 수열을 여러 번 출력하면 안된다'는 현재 노드의 값보다 큰 값만 탐색하도록 하면 된다.
의외로 문제에서 제약조건으로 주어지는 사항들 중 꽤 많은 경우는 출제의도에 맞게 풀어내면 알아서 해결이 되는 경우다. - dfs의 각 depth(node)에서 지금껏 탐색해온 node를 담을 배열을 갖도록 할 것이다
즉 dfs 메서드 콜마다 스택메모리에 각자의 배열을 갖도록. (비슷한 상황에서 이거 전역변수로 설정했다가 1시간 삽질한 경험이 있다.) - 여기까지 문제를 풀고 코딩을 해본 결과다.
import java.util.Scanner;
public class N과M_2 {
static int N, M;
static int[] ARR;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
N = sc.nextInt();
M = sc.nextInt();
ARR = new int[N + 1];
for (int i = 1; i < N + 1; i++)
ARR[i] = i;
dfs(1, 0, new int[M]);
}
public static void dfs(int num, int depth, int[] arr) {
if (num > N)
return;
if (depth == M) {
for (int i : arr)
System.out.print(i + " ");
System.out.println();
return;
}
arr[depth] = num;
for (int i = num; i < N + 1; i++)
dfs(i + 1, depth + 1, arr);
}
}- 부끄럽지만 실패한 과정을 올려놓는다. 코테 공부를 좀 쉬긴 했나보다. dfs 코드 짜는 감을 제대로 잃어버렸다.
현타가 씨게 왔다. 대충 큰 흐름은 맞긴한데, - main에서 각 node에 대해 dfs 탐색을 시켜놓고선 dfs 과정중에 다시 for문을 돌리고 있다. 중복된 값이 안나올 수가 없다.
- if(num < N) return; 부분은 boilerplate code다. 어차피 dfs의 for문에서 저 범위 안으로 값을 준다.
- arr[depth] = num 을 하게되면 tree 탐색이 똑바로 되겠나.. for문 안의 i로 초기화해주어야한다.
- 사실 코드짜다 막혀서 ChatGPT에게 도움을 구했었고, 그러고 나서야 이런 부족함을 볼 수 있었다.
 진짜 무시무시한 녀석이다..
진짜 무시무시한 녀석이다.. - 아직 Recursive한 사고, 코딩 능력이 미숙하면 이러한 과정을 겪게 된다.
잘못 작성했던 코드를 기록하고 꺼내보면서 깨달아가는 이 순간과 과정이 남았으면 좋겠다.
👨💻 CODE
import java.util.Scanner;
public class N과M_2 {
static int N, M;
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
N = sc.nextInt();
M = sc.nextInt();
dfs(1, 0, new int[M]);
}
public static void dfs(int num, int depth, int[] arr){
if(depth == M){
for(int i : arr)
System.out.print(i + " ");
System.out.println();
return;
}
for(int i=num; i<N+1; i++){
arr[depth] = i;
dfs(i + 1, depth + 1, arr);
}
}
}문제를 복기하다가 헷갈리는 지점을 찾았다.
어떻게 dfs(1, 0, new arr[])로 모든 노드를 다 탐색했지? 하는 의구심. 역시 dfs는 진짜진짜 헷갈린다.
직접 그려보면서 이해를 해봤다. 필기가 너무 더러워서 올려놓진 않겠지만,for(int i=num; i<N+1; i++){ arr[depth] = i; dfs(i + 1, depth + 1, arr); }에서 잘보면 arr[depth] = i 다. 그러니까 depth가 0으로 시작하기 때문에, 탐색을 시작하는 노드가 i에 따라 바뀌는 것이다. 배열의 첫번째 값이 dfs내의 for문에 의해 계속 상승하는 것.
<arr[depth] = num 을 하게되면 tree 탐색이 똑바로 되겠나.. for문 안의 i로 초기화해주어야한다.> 라고 저 위에 헛똑똑이씨는 이해한줄 알고 넘어가셨다.
🛠 리뷰
코딩테스트를 공부하면서 dfs를 자신있게 코딩했던 적은 생각해보니 graph 탐색이었다. 왜 그 visited배열 찍어가면서 노드 탐색하는 과정..
그리고 dfs를 코딩할때 어려움을 느꼈던 분야는 이 문제와 같이 재귀적으로 알고리즘을 직접 짜야하는 경우, 특히 백트래킹 문제였던 것 같다. 머슬 메모리에 의해 그냥 타이핑하는 dfs가 아니라 직접 설계하는... 생각해보니 삼성그룹 코테 기출문제에서도 dfs에서 애먹었던 문제는 이런쪽이었다.
좋아 넌 내가 정복한다

기록의 필요성을 느끼고 시작한 곳입니다. 혼잣말 하는것 같아 재밌네요!