Spring Boot와 Elasticsearch를 활용한 고성능 검색 엔진 구축
앞선 게시글을 통해 Elasticsearch의 특징과 핵심 개념 등을 살펴 보았습니다. 이번 글에서는 진행하고 있는 개인 프로젝트에 Elasticsearch를 직접 적용하여 효과적인 검색이 가능하도록 구현해보겠습니다.
현재 프로젝트는 '개인 맞춤형 뉴스 제공'을 목적으로 스프링 스케줄러를 통해 네이버 뉴스 기사를 수집하여 데이터로 활용하고 있습니다. 이에 엘라스틱서치를 활용하여 수집되는 뉴스 데이터를 쌓아두고, 강력한 검색 기능을 제공할 수 있도록 하겠습니다.
Elasticsearch 도입 이유 ?
우선 엘라스틱서치를 도서관을 예를 들어 진행 중인 프로젝트에 어떤 이점이 있는지 살펴보겠습니다.
- PostgreSQL (RDBMS): 도서관의 모든 책(데이터)을 책장에 순서대로 꽂아두는 서고와 같습니다. 특정 책(예: ID가 123인 책)을 찾거나, 특정 저자의 책 목록을 찾는 데에는 매우 효율적입니다. 하지만 "인공지능에 대한 내용이 포함된 모든 책을 찾아줘" 와 같은 내용 기반 검색에는 매우 취약하고 느립니다.
- Elasticsearch: 이 도서관의 슈퍼 파워를 가진 사서 또는 디지털 검색 시스템과 같습니다. 모든 책의 제목, 저자, 목차, 본문 내용을 전부 키워드별로 분석해서 색인(Index)을 만들어 둡니다. 그래서 다음과 같은 복잡하고 강력한 검색이 가능해집니다.
- "머신러닝"으로 검색했지만 "기계학습"이 포함된 책도 찾아주기 (동의어 처리)
- "develop"으로 검색했지만 "developing", "developed"가 포함된 책도 찾아주기 (형태소 분석)
- "인공지능"과 "빅데이터"가 모두 언급된 책 찾아주기 (복합 조건 검색)
- 오타가 좀 있어도 (예: "머신러닝" -> "머신러니") 알아서 찾아주기 (오타 교정)
이와 같이 '개인 맞춤형 뉴스 제공'을 목표로 하는 프로젝트에 엘라스틱서치를 통해 아래와 같은 이점을 취할 수 있을 것으로 예상됩니다.
-
강력한 전문(Full-text) 검색: 사용자가 뉴스 제목이나 내용의 일부만으로 원하는 기사를 빠르고 정확하게 찾을 수 있습니다. (SQL의 LIKE '%...%' 와는 비교할 수 없는 성능과 정확도) -
콘텐츠 기반 추천의 초석: 특정 뉴스 기사와 "유사한 내용의 다른 뉴스"를 찾는 것이 매우 쉬워집니다. 예를 들어, 사용자가 '인공지능'에 대한 뉴스를 좋아했다면, Elasticsearch에 "이 기사와 비슷한 기사들을 찾아줘"라고 요청하여 관련 뉴스를 추천해 줄 수 있습니다. -
다양한 통계 및 필터링: 카테고리별, 기간별, 키워드별 뉴스 집계 및 필터링을 매우 빠른 속도로 처리하여 관리자 대시보드나 사용자 필터 기능을 구현하는 데 유리합니다.
1. Elasticsearch 서버 생성 및 실행
# Docker로 Elasticsearch 8.14.1 버전 실행 명령어
docker run -d --name simple-elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e "xpack.security.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.14.1 2. 스프링부트 프로젝트 의존성 및 설정 추가
Spring Boot 프로젝트가 Elasticsearch와 통신할 수 있도록 관련 라이브러리를 build.gradle 파일에 추가합니다.
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'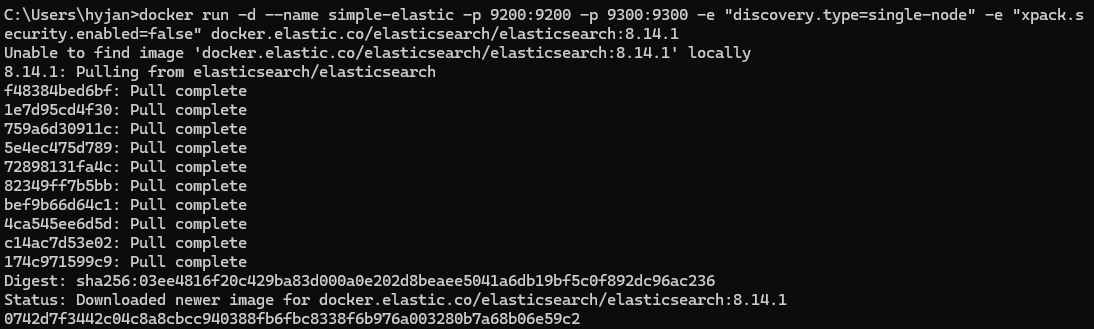
Elasticsearch 서버 연결을 위해 application.yml 에 설정 정보를 추가합니다. 일반적으로 Elasticsearch는 9200번 포트로 통신합니다. 로컬 개발 환경을 기준으로, localhost:9200으로 접속하도록 설정합니다.
elasticsearch:
uris: http://localhost:92003. Document 모델 생성 (Elasticsearch에 저장될 데이터 설계)
이제 Elasticsearch에 어떤 데이터를, 어떤 형태로 저장할지 설계합니다. 이 역할을 하는 것이 바로 Document 클래스입니다.
@Document
-
Elasticsearch에서는
@Document어노테이션을 붙인 클래스를 만들어 인덱스(Index)에 저장될 문서(Document) 데이터를 표현합니다.- 인덱스(Index) : RDBMS의 테이블(Table)과 유사한 개념. 데이터가 저장되는 논리적인 공간
- 문서(Document) : RDBMS의 행(Row)과 유사한 개념. 실제로는 JSON 객체 형태로 저장
NewsDocument.java 파일 생성:
-
검색에 필요한 필드만 모아서 NewsDocument 라는 새로운 클래스를 만듭니다. 이 클래스는 com.ccp.simple.document 라는 새로운 패키지에 생성하여, DB용
domain객체와 명확히 분리합니다. -
이 클래스에는 다음과 같은 어노테이션을 사용하여 각 필드를 어떻게 저장하고 검색할지 Elasticsearch에게 알려줍니다.
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "news") // "news"라는 이름의 인덱스에 문서를 저장
@Setting(settingPath = "elasticsearch/nori-settings.json") // nori 분석기 설정 파일 경로 지정
public class NewsDocument {
@Id
private Long newsId; // 뉴스 원본 ID
@Field(type = FieldType.Text, analyzer = "nori_analyzer")
private String title;
@Field(type = FieldType.Text, analyzer = "nori_analyzer")
private String description;
@Field(type = FieldType.Keyword) // Keyword 타입 사용
private String link;
@Field(type = FieldType.Date)
private LocalDateTime pubDt;
}{
"analysis": {
"analyzer": {
"nori_analyzer": {
"tokenizer": "nori_tokenizer"
}
}
}
}
- 이 클래스는 Elasticsearch에 저장된 뉴스 데이터의 '설계도' 역할을 합니다.
@Document(indexName = "news"): 이 클래스의 데이터는 Elasticsearch의 "news"라는 인덱스에 저장하라는 의미입니다.@Id: 이 필드가 문서의 고유 식별자(Primary Key)임을 나타냅니다.@Field(type = FieldType.Text): 이 필드는 전문(Full-text) 검색이 가능한 텍스트 데이터임을 나타냅니다. Elasticsearch는 이 필드의 내용을 단어 단위로 쪼개고 분석(Analyze)하여, 내용 기반 검색이 가능하도록 만듭니다. (title,description에 적합)@Field(type = FieldType.Date): 날짜 형식의 데이터임을 나타냅니다.
nori 분석기란?
Elasticsearch가 한국어 텍스트를 더 잘 이해하도록 도와주는 형태소 분석기입니다.
'nori' 분석을 사용하면 "뉴스를 검색합니다" 라는 문장을 단순히 공백으로 자르는 것이 아니라, 의미를 가진 최소 단위인 형태소, 즉 '뉴스', '검색', '하다'로 분해합니다. 사용자가 "검색하는 뉴스"라고 입력해도 "뉴스를 검색합니다"라는 제목의 기사를 조회할 수 있게 되어 검색 품질이 비약적으로 향상됩니다.
Elasitcsearch에 기본적으로 포함되어 있어 별도의 설치 없이 바로 사용할 수 있습니다.
참고!!! nori 플러그인 설치 필요
- 테스트 중 nori가 자동으로 내장 설치되지 않아 오류가 계속 발생하였습니다.
- 도커로 elasticsearch 를 설치하고 bin/bash 안에 nori 플러그인을 직접 설치했습니다.
- nori 설치 > 도커 컨테이서 stop > 도커 컨테이너 run
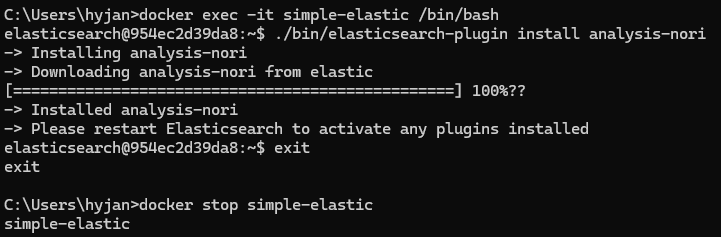
- nori 분석기 설정 파일 경로로 매핑된 것을 확인
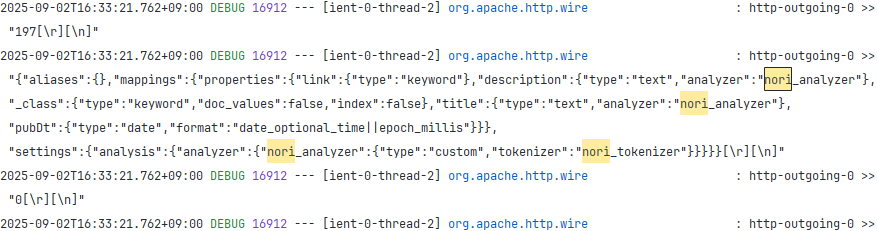
- 노리 플러그인 설치 확인
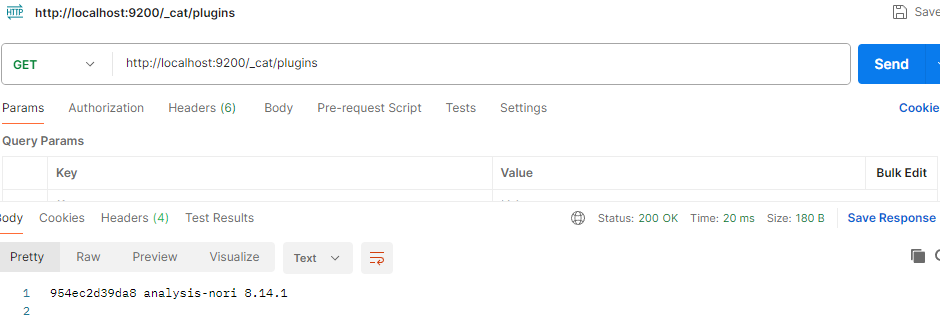
4. ElasticsearchRepository 상속
Spring Data에서는 ElasticsearchRepository 인터페이스를 상속받아 엘라스틱서치 관련 기본적인 CRUD 메소드를 구현할 수 있습니다. (예전에 공부했던 JPA 와 비슷한 형식)
덕분에 별도의 SQL 쿼리를 작성하지 않고도 newsSearchRepository.save(), newsSearchRepository.findById(), newsSearchRepository.delete() 와 같은 메소드를 바로 사용할 수 있어 매우 편리합니다.
package com.ccp.simple.repository;
import com.ccp.simple.document.NewsDocument;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface NewsSearchRepository extends ElasticsearchRepository<NewsDocument, Long> {
}데이터 인덱싱 (뉴스 수집 시 Elasticsearch에 저장하기)
뉴스 수집 시 PostgreSQL에 저장함과 동시에 Elasticsearch에도 저장(Indexing) 하도록 기존 뉴스 수집 로직을 수정합니다.
- 기존에는 DB 저장만 진행
// DB 뉴스 저장
newsMapper.insertNews(news);- DB 저장 + 엘라스틱서치 인덱싱 진행
// 1. DB 뉴스 저장
newsMapper.insertNews(news);
// 2. Elasticsearch에 뉴스 인덱싱
NewsDocument newsDocument = NewsDocument.builder()
.newsId(newsId)
.title(news.getTitle())
.description(news.getDescription())
.link(news.getLink())
.pubDt(news.getPubDt())
.build();
newsSearchRepository.save(newsDocument);Elasticsearch를 활용한 검색 API 구현
1. GET 메소드로 요청을 받는 /api/news/search 엔드포인트를 만듭니다.
// 뉴스 검색
@GetMapping("/news/search")
public List<NewsDocument> searchNews(@RequestParam("q") String query) {
return newsService.searchNews(query);
}- @RequestParam("q") 어노테이션을 사용하여, URL의 쿼리 파라미터(예: ?q=검색어)로 들어온 검색어를 query라는 이름의 String 변수로 받습니다.
2. 엘라스틱서치 검색 서비스 코드를 작성합니다.
@Override
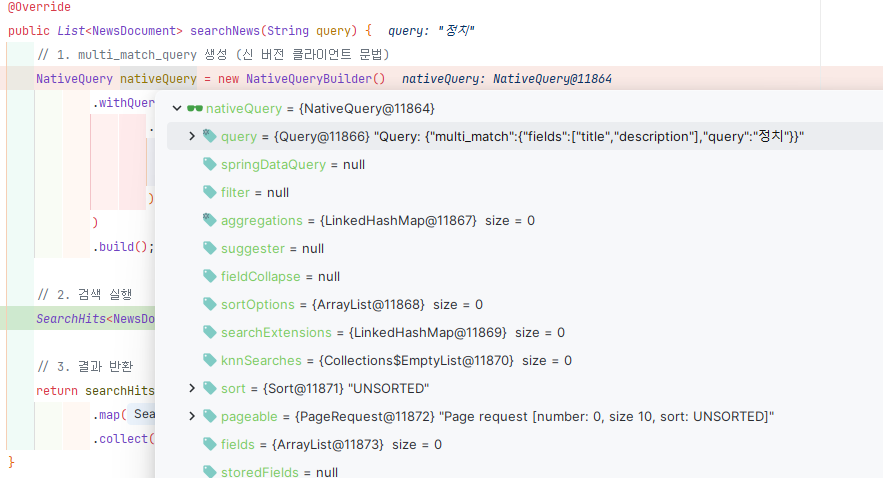
public List<NewsDocument> searchNews(String query) {
// 1. multi_match_query 생성
NativeQuery nativeQuery = new NativeQueryBuilder()
.withQuery(q -> q
.multiMatch(mmq -> mmq
.fields("title", "description")
.query(query)
)
)
.build();
// 2. 검색 실행
SearchHits<NewsDocument> searchHits = elasticsearchOperations.search(nativeQuery, NewsDocument.class);
// 3. 결과 반환
return searchHits.getSearchHits().stream()
.map(hit -> hit.getContent())
.collect(Collectors.toList());
}- 검색어를 title과 description 필드에서 찾는 multi-match 쿼리를 구현합니다.
인덱싱 및 검색 테스트
1. Elasticsearch 인덱싱 테스트
- Elasticsearch 서버 실행 중
- 뉴스 수집 스케줄러를 실행하여 DB INSERT와 Elasticsearch 에 동일한 데이터가 인덱싱 되도록 함
- DB에 20개의 새로운 뉴스 데이터가 INSERT
- 엘라스틱서치 카운트 확인 결과 20개로 동일
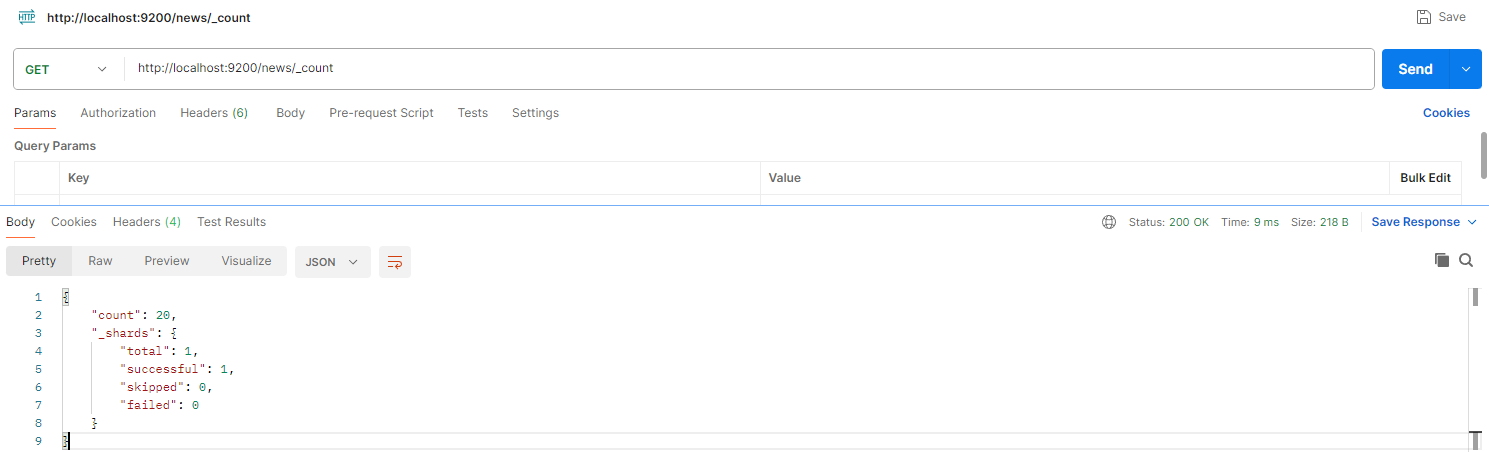
- DB 데이터와 동일한 데이터가 엘라스틱서치에 인덱싱 된 것을 확인
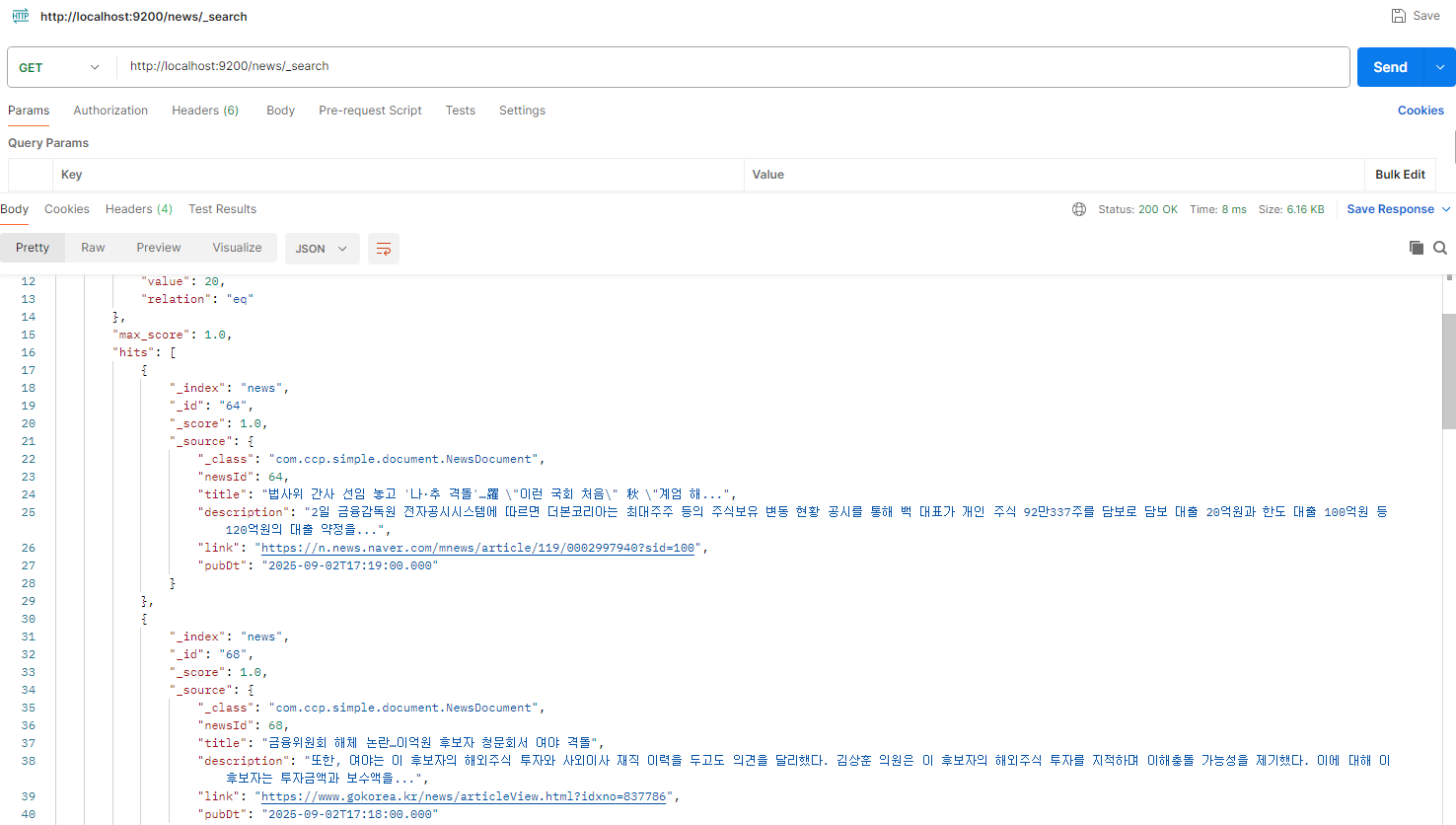
2. 검색 API 테스트
- Postman에 아래와 같은 형식의 URL을 입력하여 GET 요청을 보냅니다.
- 요청 예시 : http://localhost:8080/api/news/search?q=정치
3. 응답값 확인 및 비교:
- 응답(Response)으로 검색어와 일치하는 NewsDocument 객체의 JSON 배열이 반환되는지 확인
- 검색어를 바꿔가며, 제목이나 내용에 해당 검색어가 포함된 뉴스들이 정확히 찾아지는지 테스트 진행
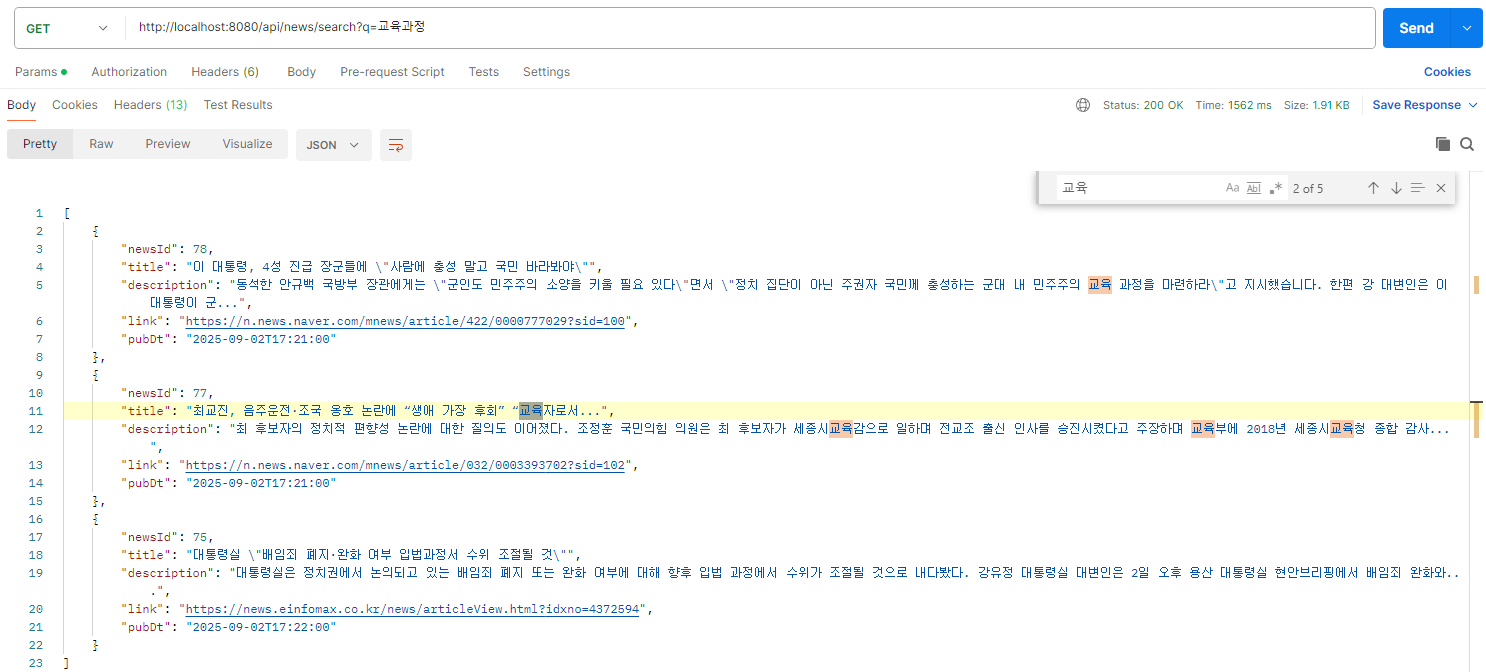
- 검색어 : 교육과정
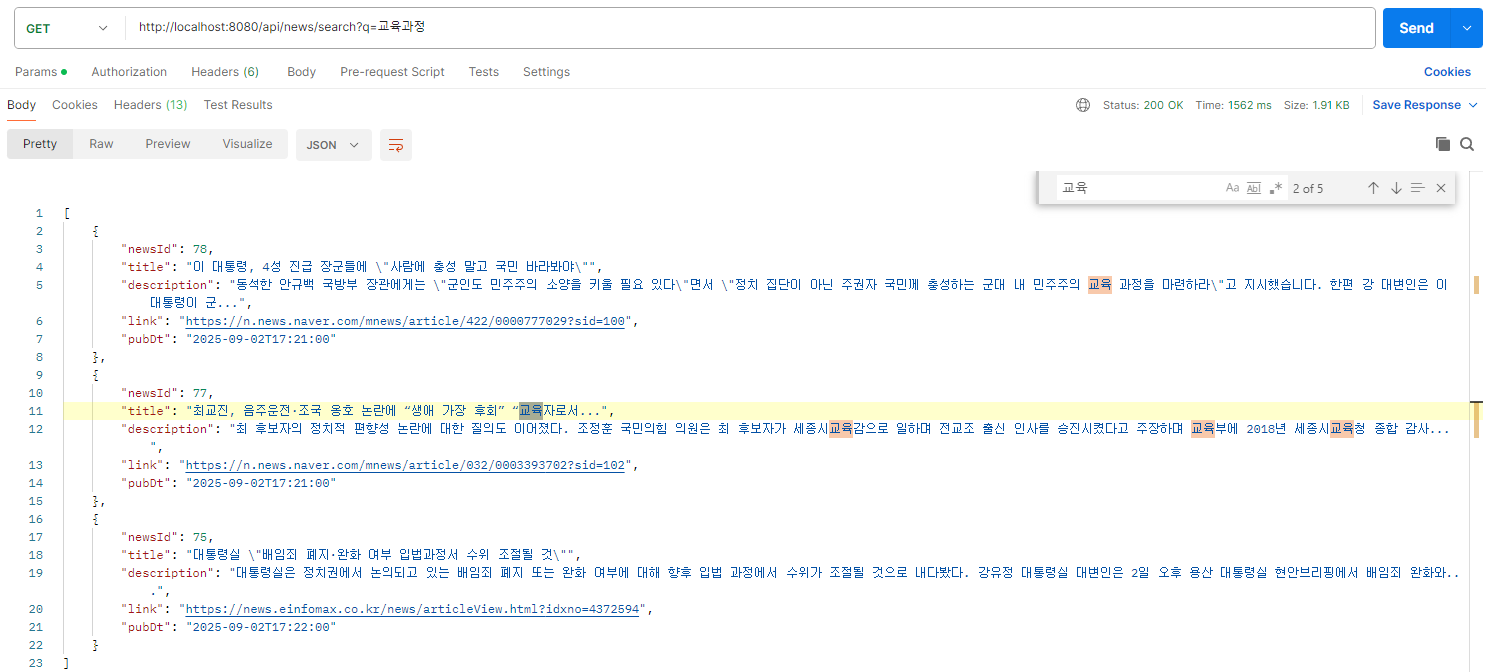
- 엘라스틱서치를 통한 검색으로는 '교육과정'으로 검색을 했을 때 '교육 과정'이 속한 기사뿐만 아니라 '교육' 형태소가 속한 데이터를 결과로 조회하는 것을 확인

- SQL 검색 결과 '%교육과정%' LIKE 검색이 이루어졌기 때문에 정확히 일치하지 않는 데이터는 조회되지 않음
- 검색어 : 교육과정
결과
지금까지 Spring Boot 환경에 Elasticsearch를 성공적으로 연동하고, nori 한국어 분석기를 적용하여 RDBMS의 한계를 뛰어넘는 효율적인 전문 검색 기능을 구현했습니다.
-
다중 필드 동시 검색: 사용자는 검색어 하나만 입력했지만, 시스템은 multi_match 쿼리를 통해 뉴스의 제목과 본문 내용을 동시에 탐색하여 관련도 높은 결과를 찾아냅니다.
-
한국어 형태소 분석: nori 분석기 덕분에, 사용자가 "뉴스를 검색하는 방법"이라고 검색해도, "뉴스 검색 방법"이나 "뉴스의 검색"이 포함된 문서를 찾아낼 수 있습니다. 이처럼 단어의 원형과 조사를 이해하는 지능적인 검색이 가능해졌습니다.
-
높은 성능과 확장성: 수백만 건의 문서가 쌓이더라도 Elasticsearch는 거의 실시간에 가까운 검색 속도를 보장합니다. 이는 사용자에게 쾌적한 검색 경험을 제공할 뿐만 아니라, 향후 데이터가 증가하더라도 안정적인 성능을 유지할 수 있는 확장성을 확보했음을 의미합니다.
