왜 Auto_Increment 대신 랜덤 식별 값을 고려하게 되었는가
그동안 참여했던 웹 프로젝트에서도, 학습 과정에서 활용되었던 프로젝트에서도 자원을 식별하는 값의 전략으로 Auto Increment 를 사용해왔습니다. Auto Increment 전략은 테이블에 새로운 행을 생성할 때, 고유한 식별 값을 생성하는 과정을 데이터베이스에게 일임합니다. 증가하는 시퀀스 번호를 자동으로 할당해주기 때문에 개발자는 사용에 간편합니다. 가독성이 좋아 기억하기에도 쉽고 식별 값을 활용하는 내부 사용자(개발자, 관리자)간의 의사소통에도 불편함이 상대적으로 적습니다.
하지만, Auto Increment를 PK으로 사용하면서 발생될 수 있는 몇몇 문제들 때문에 ID 채번 전략을 다시 고민하게 되었습니다.
1) 분산 DB 환경에서 충돌 발생
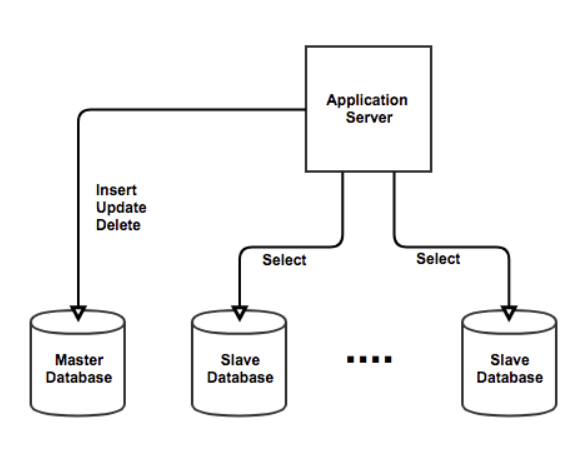 |  |
|---|---|
| 1개의 Master DB 사용시. 이미지 출처 : 링크 | 2개 이상의 Master DB 사용 시. 이미지 출처 : 링크 |
단일 DB 환경이 아닌, 여러 데이터베이스 서버를 사용하는 분산 DB 환경에서는, 데이터베이스간 동기화가 되어 있지 않으면, 동일한 ID가 나타나 충돌이 발생할 수 있습니다. PK의 일관성을 보장하지 못하는 문제가 발생하는 것입니다.
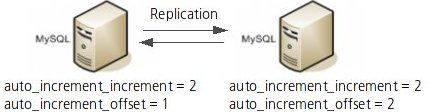
물론 분산DB 환경이라고 다 문제가 되는 것은 아닙니다. 일반적으로 분산DB 환경의 경우 Write 하는 Master 는 하나를 두고 Read만 하는 여러대의 Slave DB에 그 값을 동기화 하도록 하는데, 이 경우에는 AUTO_INCREMENT 를 사용해도 문제가 되지 않습니다. 또한 Write 하는 Master DB 가 2대 이상의 분산처리 하는 경우 auto_increment_offset, auto_increment_increment 설정을 통해 AUTO_INCREMENT 증가를 제어함으로써 충돌을 방지할 수 있습니다. 예를 들어 master db가 2대 인 경우 각각 홀/짝수로 증가하도록 해서 해결할 수 있습니다. 하지만 이러한 Multi Master Replication 환경에서는 여러 문제가 발생할 수 있습니다. ID의 유일성은 보장되지만 더 높은 값의 ID가 더 최근에 생성됨을 보장하지 않습니다. 즉 시간의 흐름에 따라 커짐을 보장할 수 없습니다. 또한, 서버를 추가하거나 삭제할때마다 올바른 ID 생성을 위해 설정을 변경해야 하는데 이를 처리하기가 쉽지 않다는 문제가 있습니다.
2) 추정 하기 쉬운 식별 값
Multi Master Replication과 같은 분산 DB 환경에서 애플리케이션이 동작하지 않더라도, Auto Increment 전략은 추정하기 쉬운 식별 값 이라는 문제에 있습니다. 규칙적으로 증가하는 형식의 PK를 통해 자원에 대한 정보를 추정하기 너무 쉽습니다.
특정 자원에 접근할 때, 클라이언트는 개발자의 의도 순서대로 자원에 접근하지 않고 URL 을 통해 식별 값을 변경시켜가며 직접접근을 시도할 수 있습니다. 이를통해 서비스의 자원을 손 쉽게 수집할 수 있으며, 순차 증가하는 전략의 특징으로 인해 서비스의 규모를 추정할 수 있는 여지가 되기도 합니다. 일반적인 사용자가 아니라 크롤링 봇인 경우 문제가 더욱 두드러집니다
자원을 수정하기 위한 요청을 전송할 때도 의도적으로 자원 식별 값을 위조하기에도 쉽습니다. 당연히 이러한 잘못된 접근을 방지하는 자원 접근 권한에 대한 검증 로직이 존재해야 하는 것은 맞습니다만, 애초에 외부 사용자에게 노출되는 식별 값이 쉽게 해석되지 않는 장벽이 있다면 올바르지 않은 시도를 더 줄일 수 있을 것이라 판단했습니다.
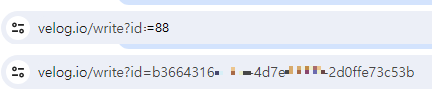
따라서 첫 번째 대안으로, 상단 이미지의 예시처럼 유추하기 쉬운 정수 값(88)을 식별 값으로 사용하는 것 보다, 그 아래와 같이 랜덤한 값을 자원 식별 값으로 사용하기 위해 UUID 도입을 먼저 고려하게 되었습니다.
UUID 에 대해 알아보기
개요
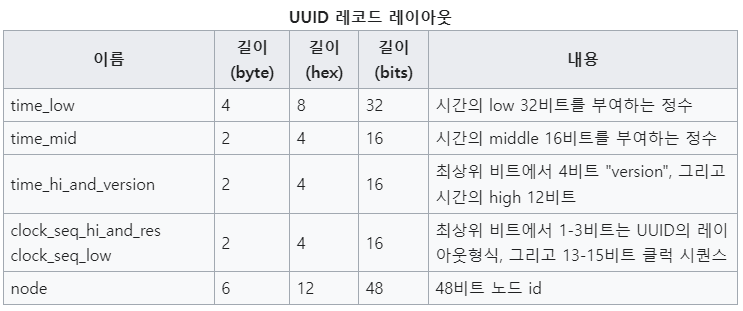
UUID(Universally Unique Identifier)는 개체의 고유성을 충족하기 위해 탄생한 식별자로, 아래와 같이 총 36개의 문자로 16진수 문자 32개와 하이픈 - 문자 4개로 구성되어 있습니다. 16진수를 나타내기 위해서는 4bit가 필요하고, 32개의 16진수 이기 때문에 128비트 길이를 가지고 있습니다. 초기 개념은 오픈 소프트웨어 재단(OSF)에 의해 표준이 제정되었습니다. 현재의 표준은 IETF에 의해 관리되고 있습니다. 참고링크 : Universally Unique IDentifiers (UUIDs) RFC 9562

중복 가능성
중복 가능성이 매우 낮은 특징을 가지고 있습니다. 이론상 중복될 확률이 0은 아니지만, UUID 버전 4를 기준으로 충돌 확률 0.00009% 를 만들기 위해서는 초당 100만개를 100년동안 생성해야 합니다(참고 링크 : 블로그). 따라서 사실상 0에 가깝다고 판단하고 UUID를 사용할 수 있습니다.
사용법
UUID는 버전 4 외에도 다양한 버전이 존재하고, 버전에 따라 생성 방식과 특징도 다릅니다. Java에서 java.util 패키지의 UUID 클래스를 사용하면 1,3,4 버전을 생성할 수 있습니다. 가장 간편하게 생성할 수 있는 버전 4는 randomUUID() 메서드를 사용합니다.
UUID uuid = UUID.randomUUID();MySQL 8.0 버전부터는 UUID() 함수를 사용하면 버전 1의 UUID를 간편하게 생성할 수 있습니다.
성능 비교를 통한 UUID 개선 과정
Auto Increment 되는 식별 값을 외부 클라이언트에게 노출하였을 때 발생하는 문제를 인지해 UUID 적용을 고려하게 되었고, ID 충돌이 발생할 확률도 매우 낮아 충분히 고유한 값을 갖는 키의 역할로 활용될 수 있습니다. 하지만 UUID를 서비스에 도입할 때 발생하는 생성비용, 삽입 및 조회 성능의 저하 등을 고려해야 합니다. 따라서 대량의 더미 데이터를 삽입하는 성능 비교를 통해 타협 가능한 정도인지를 확인하고 UUID 도입의 당위성을 챙기고자 했습니다.
InnoDB 인덱스 정렬 특징을 고려하기
8.0 버전을 기준으로 MySQL은 B-Tree 인덱스 알고리즘을 사용하기 때문에 인덱스 구조체 내에서 항상 정렬된 상태를 유지합니다. 물론 InnoDB 엔진의 특성상 Insert 쿼리가 수행될 때 지능적으로 인덱스 알고리즘을 적용하기 위해 즉시 새로운 인덱스 키 값을 B-Tree 인덱스에 변경하지는 않습니다. 그럼에도 비순차적 값을 인덱스로 사용할 경우, 인덱스 알고리즘이 동작할 때 B-Tree 구조의 재배치 동작이 순차적인 값을 사용하는 경우보다 성능적 측면에서 비효율 적입니다.
따라서 UUID에 인덱스를 걸어도 정렬이 올바르게 되어 있지 않다면 빠르게 원하는 key를 찾을 수 없습니다. 최대한 빠르게 찾아가기 위해서는 특정 순서로 정렬되어 있어야 합니다. 즉, UUID 컬럼의 값을 특정 순서로 정렬할 수 있어야 하기 때문에 구현이 간편한 UUID v4 를 사용하는 것 보다 정렬될 수 있는 UUID 버전을 사용해야 했습니다. 여러 버전 중 대표적으로 1, 6, 7 버전이 타임스탬프를 기준으로 정렬이 가능합니다.
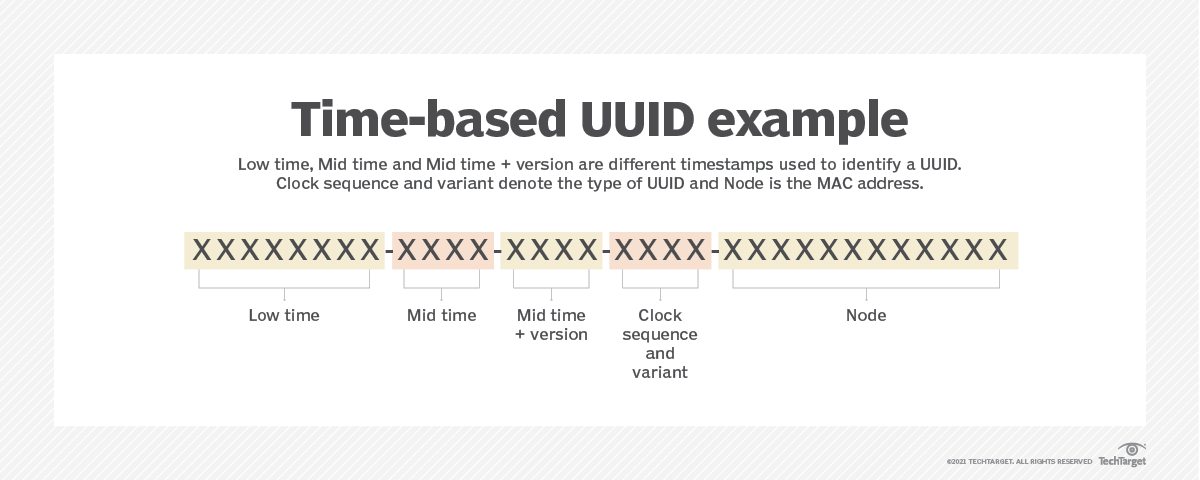 |  |
|---|---|
| 이미지 출처 : 링크 | 이미지 출처 : 위키피디아 |
이들 중 48 비트의 타임스탬프 + 74 비트의 무작위 값으로 구성된 버전 7을 선택했습니다. 버전 7을 선택한 이유는 버전 1에서는 중간 48비트를 MAC 주소를 사용하는데 이를통한 개인 정보 보호 및 네트워크 보안 문제가 발생할 수 있다고 알려져 있으며, 버전 6이 시스템 시간에 의존적인 반면 7은 Unix Epcoh 타임스탬프를 사용하여 시스템 독립성을 강화하였기 때문입니다. 또한 그레고리안 형식보다 Unix 타임스탬프의 형식이 계산과 저장연산이 조금 더 간단하고 빠르다고 알려져있습니다. IETF(Internet Engineering Task Force, 국제 인터넷 표준화 기구)에서도 가능한 version 7를 사용하도록 권장하고 있다고 합니다. (참고 링크)
최근에는 UUID 버전 7도 IETF의 표준화 과정을 거쳐 제안 표준(Proposed Standard)으로 승인되었음을 확인할 수 있었습니다.

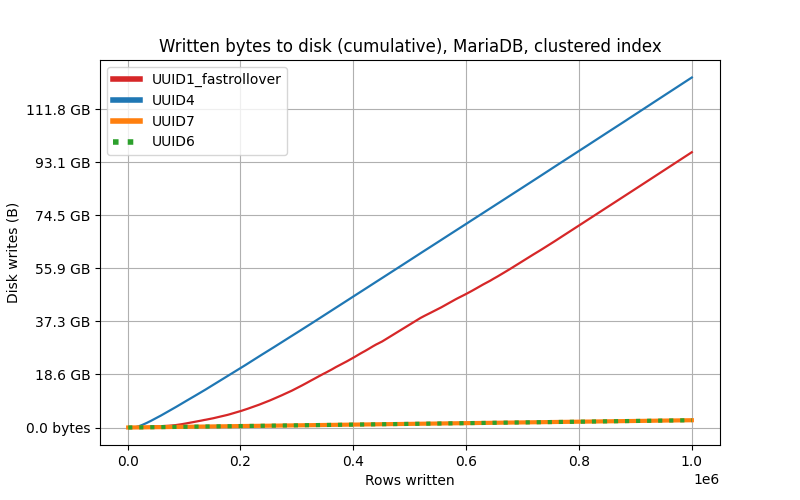
버전 별 삽입 성능 비교
위의 이론을 증명하는 벤치마크를 조사해본 결과 두 곳에서 유의미한 삽입 성능 비교 결과를 찾아볼 수 있었습니다. 공통적으로 v1, v4 보다 v6, v7이 월등한 삽입 성능 (약 28%) 을 보였습니다. v6와 v7은 근소한 차이밖에 나지 않았으나 v7이 가장 최신이며 효율적인 버전으로 간주됩니다.
| 버전 별 삽입 성능 비교 |
|---|
 이미지 출처 : 링크 이미지 출처 : 링크 |
 이미지 출처 : 링크 이미지 출처 : 링크 |
InnoDB 인덱스 크기를 고려하기
인덱스의 키 값의 크기는 인덱스 키 검색과 밀접한 관계가 있습니다. 데이터 버퍼과 데이터 저장의 기본 단위는 페이지에 저장할 수 있는 인덱스 키의 개수가 많을 수록, 더 적은 I/O 횟수로 페이지를 읽어 원하는 인덱스를 찾을 수 있기 때문입니다.
UUID는 하이픈을 포함해 36자리 문자열로 구성되어 있습니다. 하이픈을 제거하더라도 이를 통으로 저장하려면 varchar(32) 타입을 사용해야 하는데, 이는 DB 입장에서 너무 큰 ID 값입니다. 또한 비교 연산을 수행할 때도 유의미한 성능 저하가 발생합니다. 따라서 UUID를 ID으로 사용할 때도 그대로 저장하기 보다 조금이라도 줄이는 것이 좋다고 판단했습니다.
UUID의 구성을 보면 각 자리는 16진수(4비트) 32자리 입니다. 총 128비트는 16바이트으로, UUID는 16바이트 크기로 나타낼 수 있습니다. 따라서 UUID를 바이트 배열로 변환하여 MySQL에서 지원하는 BINARY(16) 데이터 타입을 사용하여 저장 크기를 기존 32바이트에서 절반으로 줄일 수 있었습니다.
실제로 UUID의 데이터타입을 어떤 것을 선택하는지에 따라 데이터 삽입 속도에서도 차이가 발생했습니다. 회당 50만 데이터를 삽입하는 작업을 5회 수행한 결과 VARCHAR(36) 타입을 선택한 경우 평균 10% 의 성능저하가 나타났습니다.
MySQL 공식문서와 JPA 하이버네이트 문서에서도 UUID를 16바이트 크기로 줄이는 방법을 권장하고 있습니다.
불편한 UUID
이렇게 정렬 가능한 UUID v7 버전을 선택하고, 저장 크기를 절반의 크기로 줄일 수 있었으나, UUID를 자원의 단일 식별 값으로 사용하기에 너무 긴 식별 값으로 인해 의사소통에 불편한 점이 발견되었습니다.
첫째로, 외부에 노출되었을 때 자원에 대해 추정하기 어렵다는 장점이 내부 관계자들이 소통할 때에도 소통에 어려움을 겪는 문제였습니다.
또한 둘째로, 일부 데이터베이스 도구에서 UUID 조회시 아래 이미지와 같이 BLOB 데이터 타입으로 보여지는 문제가 있습니다. (DataGrip 은 별도 변환 없이 문자열로 변환되어 보여집니다.)
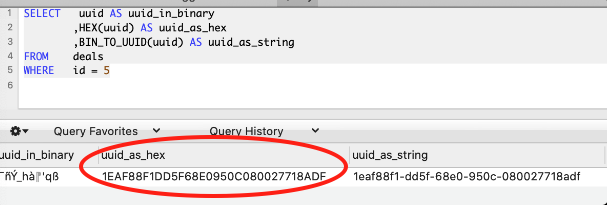
이를 해결하기 위해서는 아래와 같이 변환해야 조회가 가능합니다.
select LOWER(CONCAT(
SUBSTR(HEX(uuid), 1, 8), '-',
SUBSTR(HEX(uuid), 9, 4), '-',
SUBSTR(HEX(uuid), 13, 4), '-',
SUBSTR(HEX(uuid), 17, 4), '-',
SUBSTR(HEX(uuid), 21)
)), table.*
from table;저는 쿼리가 길어지는 문제를 다음과 같이 UuidResolver 를 구현해 해결하기도 했습니다.
@Slf4j
@Component
public class UuidResolver {
public UUID generateUuid() {
UUID uuidV7 = Generators.timeBasedEpochGenerator().generate();
return uuidV7;
}
public byte[] parseUuidToBytes(UUID targetUuid) {
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(targetUuid.getMostSignificantBits());
bb.putLong(targetUuid.getLeastSignificantBits());
return bb.array();
}
public UUID parseBytesToUuid(byte[] targetUuidBytes) {
ByteBuffer bb = ByteBuffer.wrap(targetUuidBytes);
long mostSignificantBits = bb.getLong();
long leastSignificantBits = bb.getLong();
return new UUID(mostSignificantBits, leastSignificantBits);
}
}이외에도 저장 공간 효율성 측면에서도 UUID는 128비트(16바이트)를 차지하여, 정수형 ID(BIGINT 8바이트)에 비해 더 많은 저장 공간을 필요로 합니다. 이로 인한 저장 공간 및 인덱스 크기 증가가 발생할 수 있습니다.
인덱스의 Unique 여부 비교하기 (Unique Index, Non Unique Index)
세컨더리 인덱스는 Unique 옵션의 여부에 따라 Unique Index(유니크 인덱스)와 Non Unique Index(일반 세컨더리 인덱스)으로 구분할 수 있습니다. Insert(쓰기) 관점에서 Unique Index는 유일성을 보장하기 위해 중복된 값이 있는지 확인하는 과정이 필요합니다. 따라서 Unique Index는 Non Unique 인덱스보다 삽입 성능이 낮습니다. (참고 : Real MySQL 8.0 1권 8장 9절)
실제로 책에서 학습한 내용과 동일한지 확인해보기 위해 Unique 옵션만 다르게 두 테이블을 생성하고, 50만 Row 를 삽입하는 테스트를 5회 반복했습니다. 의문스럽게도 삽입하려는 식별 값이 테이블에서 유일한지 검사가 필요한 Unique Index가 적용된 테이블이 그렇지 않은 테이블보다 느린적이 단 한번도 없었습니다. 삽입하는 행의 개수가 너무 적어서 이런 결과가 나왔을 수 있으니 100만 Rows를 삽입하는 테스트를 3회 더 반복해보았지만 결과는 다르지 않았습니다.
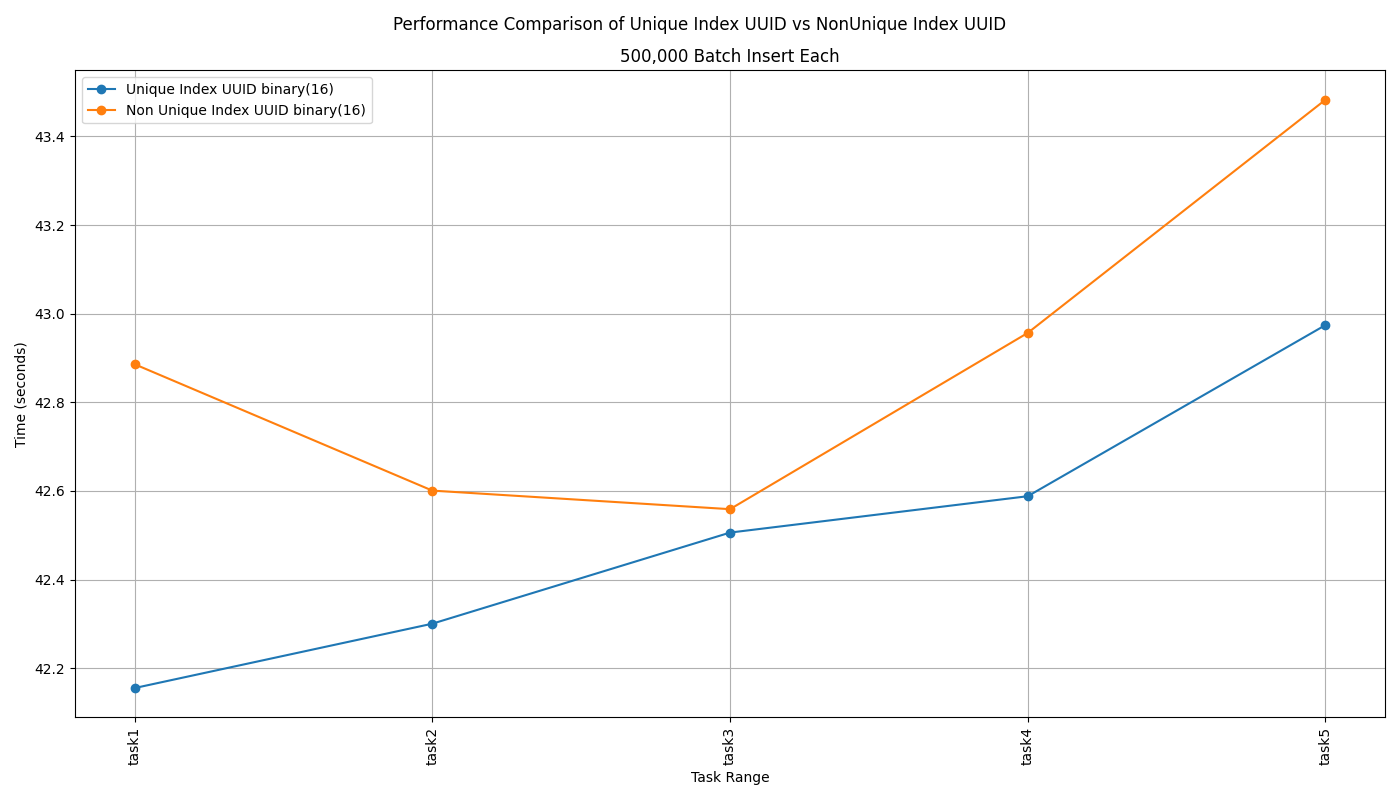 |  |
|---|---|
| 50만 건 삽입, 5회 반복 | 100만 건 삽입, 3회 반복 |
왜 이런 결과가?
[지피티 답변, 코파일럿 답변 참고해서 정리]
데이터 타입 때문일 수도...
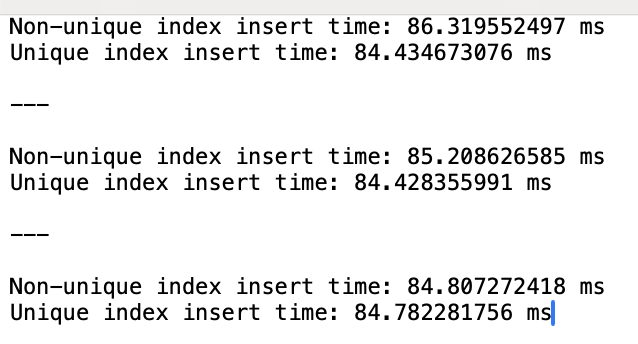
따라서 이번엔 UUID에 BINARY(16) 타입 대신 VARCHAR(36) 타입의 테이블 2개를 생성하고 Unique 옵션을 다르게 적용 후, 다시 테스트를 5회 반복했습니다. 전체 테스트의 40%는 Unique 옵션을 적용하였을 때 삽입 속도가 더 느린 흥미로운 결과를 받아볼 수 있었습니다.
UUID 버전 7은 중복된 식별 값이 생성될 확률이 로또 1등을 10회 연속 당첨될 확률 보다 낮습니다. 따라서 유일성 보장을 위해 Unique 옵션을 적용하는 것이 적절해 보임.
결과적으로 자원 식별 값이 외부 클라이언트에게 노출되어 UUID를 사용해야 한다면 자원에 대한 유일성을 보장
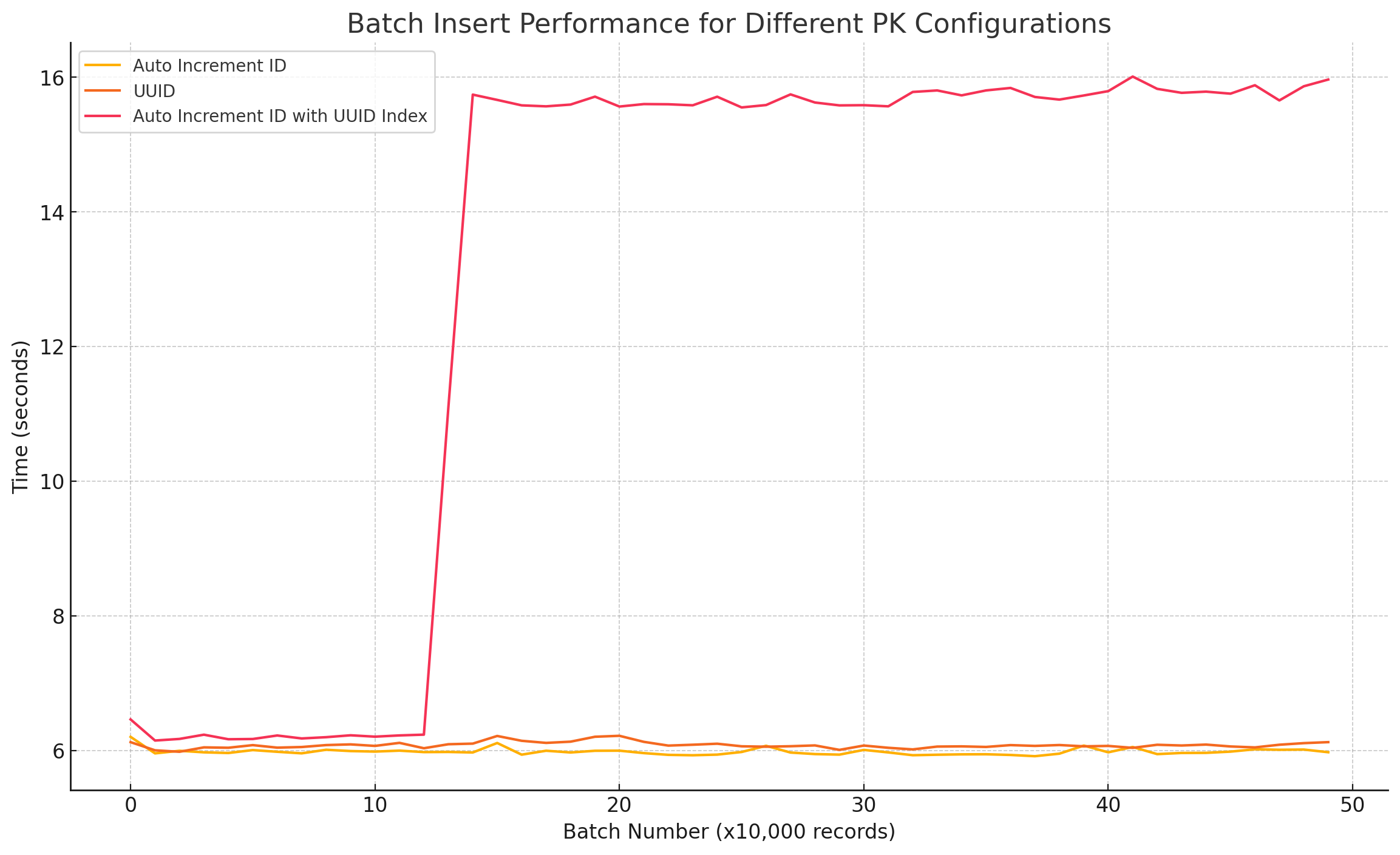
다음 세 가지 테이블을 생성 후, 50만 건의 데이터를 삽입하였을 때 소요되는 시간을 측정한 결과
- Auto Increment ID 를 PK 으로 사용하는 테이블
- 정렬 가능한 UUID 버전7을 PK 으로 사용하는 테이블
- Auto Increment ID 를 PK, UUID 버전7에 세컨더리 인덱스를 적용한 테이블
UUID 대안 찾기
UUID의 한계를 인식한 후, UUID를 대체할 식별자 전략을 조사했습니다. 주요 대안으로 유튜브 UID, Snowflake, TSID를 고려했습니다.
유튜브 UID
유튜브에서 사용하는 UID 시스템은 다음과 같은 특징을 가집니다:
- 11자리의 Base64 인코딩 문자열 사용
- 시간 정보를 포함하지 않음
- 고유성은 보장하지만 정렬이 어려움
- 깃허브 공식 래포지토리 링크
Snowflake
Twitter에서 개발한 Snowflake ID 방식은 여러 서버 인스턴스에서 각자 ID를 생성하는 방식입니다. 따라서 특정 시간에 특정 인스턴스가 생성한 시퀀스로 ID의 유일함을 보장합니다.

식별 값의 구조는 위와 같이 타임스탬프 41bit와 서버 인스턴스 번호(InstanceId) 10bit, 시퀀스 12bit를 합쳐서 63bit에 1bit를 더해 4byte로 표현합니다.
- 64비트 정수로 구성
- 타임스탬프, 워커 ID, 시퀀스 번호를 포함
- 시간 순 정렬 가능, 분산 시스템에 적합
- 하지만 워커 ID 관리의 복잡성이 존재
TSID (Time-Sorted Unique Identifier)
TSID는 다음과 같은 특징을 가집니다:
- 13자리의 숫자 문자열로 표현되어, 64비트 정수로 구성되어 있습니다. 따라서 UUID 보다 훨씬 짧아 가독성 측면에서도 이점이 있습니다.
- 식별 값에 타임스탬프를 포함하여 시간 순 정렬이 가능합니다.
- 시간 순 정렬 가능
- 충돌 가능성이 극히 낮아 분산 시스템에 적합합니다.
- 분산 시스템에 적합하며 관리가 간단
- Snowflake와 달리 추가적인 인프라 관리가 필요 없습니다.
- 깃허브 공식 래포지토리 링크
트위터 Snowflake
https://ramka-devstory.tistory.com/3
https://dev.to/josethz00/benchmark-snowflake-vs-uuidv4-2h80
https://techblog.lycorp.co.jp/ko/experience-in-migrating-order-db-on-ecommerce-platform
성능 비교
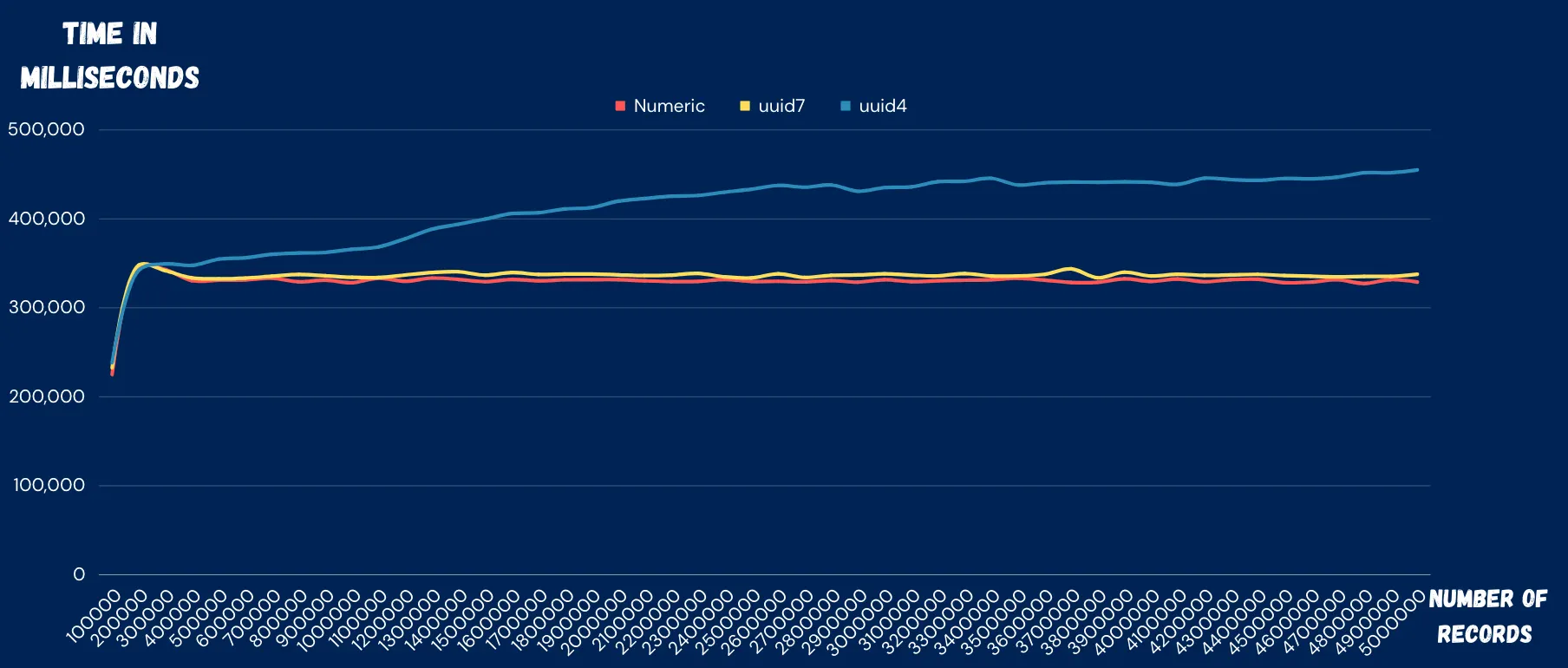
준수한 삽입 성능을 가지는 TSID
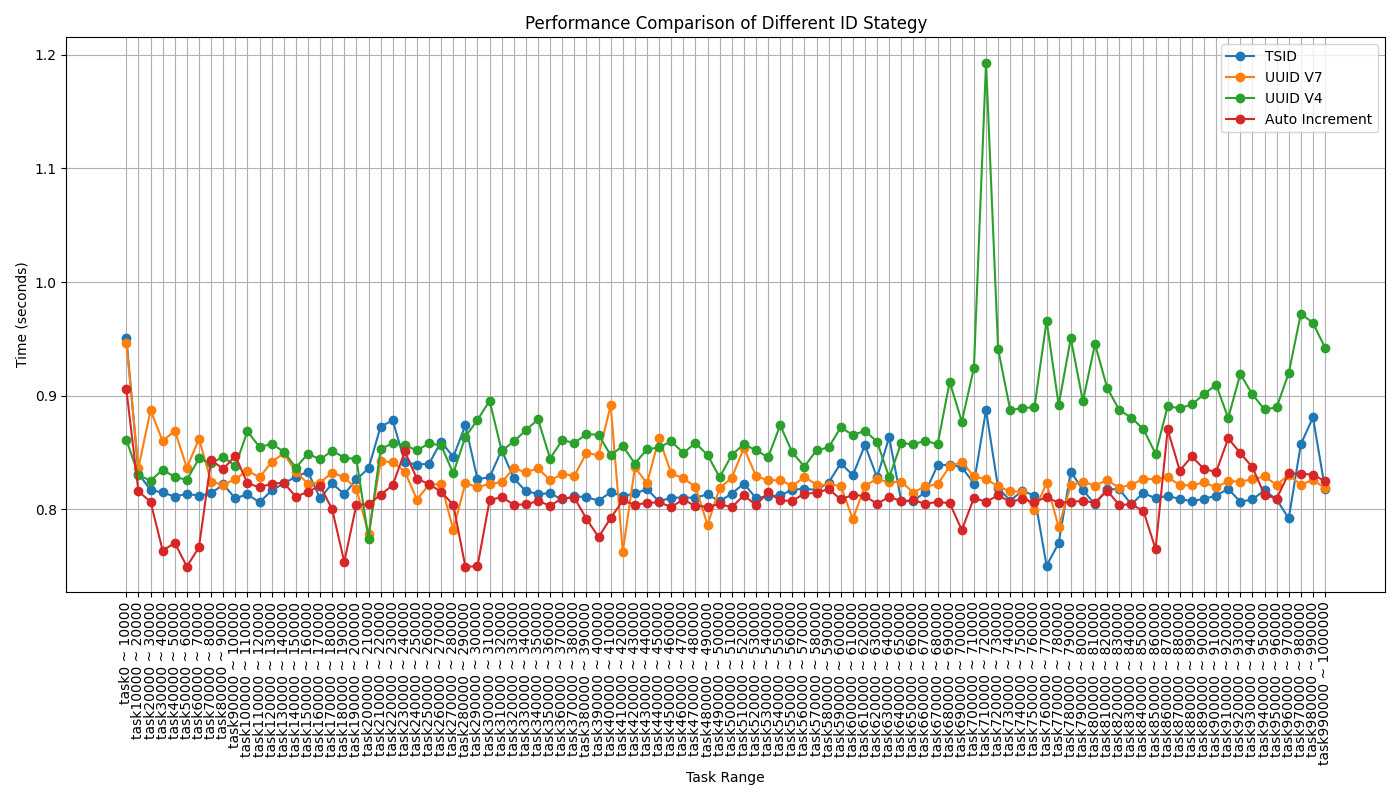
TSID가 다른 식별자들에 비해 우수한 삽입 성능을 보여주고 있습니다. 특히 Auto Increment와 비슷한 수준의 성능을 보이면서도
종합적인 분석 결과, 우리는 TSID를 새로운 식별자 시스템으로 도입하기로 결정했습니다. TSID는 UUID의 장점인 고유성과 분산 시스템 적합성을 유지하면서도, 더 짧고 효율적인 형태를 제공합니다. 또한, 시간 순 정렬이 가능하여 데이터베이스 성능 최적화에도 도움이 됩니다.
TSID 도입
트러블슈팅, Javascript의 최대 정수 표현 범위를 벗어나다
문제상황
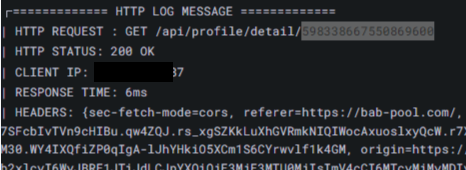
TSID를 식별 값 생성전략으로 변경한 후, 클라이언트가 정상적으로 데이터를 응답받지 못하는 이슈가 발생했습니다.
로그를 살펴보니 서버에서 클라이언트로 응답한 식별 값의 길이가 너무 길어서 Javascript가 뒤 2자리를 00으로 바꿔버려 요청 시 올바르지 않은 식별 값을 전달한 것을 확인할 수 있었습니다.
원인
TSID를 이용시에는 Long 타입의 16바이트를 모드 이용하는데, 자바스크립트 언어에서의 정수는 53비트로 제한되어 있습니다. 즉, 53비트보다 큰 수일 경우에 정확하게 수를 표현하지 못합니다. 프론트에서 처리해야 한다면, json-bigint와 같은 라이브러리를 활용해 해결할 수 있다는 것을 알게되었습니다. (라이브러리 공식 링크) 그러나, 기한 문제로 백엔드에서 처리해달라는 프론트의 요청에 의해 직렬화/역직렬화 시 형변환을 통해 백엔드에서 해결하는 방향을 선택했습니다.
해결) Json 직렬화/역직렬화
Spring Boot는 Jackson 라이브러리를 통해 Java 객체와 JSON 간의 변환을 처리합니다. Jackson은 Java 객체와 JSON 데이터 간의 변환을 수행하는 라이브러리로, Java 객체를 JSON으로 직렬화(Serialize)하거나, JSON 데이터를 Java 객체로 역직렬화(Deserialize)할 수 있습니다. SpringBoot 3.0 이상에서는 기본적으로 spring-boot-starter-json에 포함되어 있습니다.
그리고, ObjectMapper는 Jackson 라이브러리의 핵심 클래스으로, Spring Boot에서는 Jackson 라이브러리의 ObjectMapper 클래스를 사용하여 JSON 데이터를 처리합니다.
Jackson에서는 직렬화와 역직렬화를 수행할 때 사용하는 Serializer와 Deserializer를 지정할 수 있습니다. Serializer는 Java 객체를 JSON 데이터로 변환할 때 사용되고, Deserializer는 JSON 데이터를 Java 객체로 변환할 때 사용됩니다. Spring Boot에서는 이러한 Serializer와 Deserializer를 간편하게 등록하고 사용할 수 있도록 JsonSerialize와 JsonDeserialize 어노테이션을 제공합니다.
다음과 같이 직렬화를 위해 JsonSerializer<>를 상속받아 구현하고, @JsonSerialize 어노테이션을 통해 특정 객체의 필드나 메서드에 지정할 수 있습니다.
public class CustomLocalDateTimeSerializer extends JsonSerializer<LocalDateTime> {
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Override
public void serialize(LocalDateTime value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
gen.writeString(value.format(formatter));
}
}
// 활용 방법
@JsonSerialize(using = CustomLocalDateTimeSerializer.class)
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime eventDate;하지만, 식별 값은 이미 response, request DTO 들이 프로젝트 전반에 너무 많이 산재되어 있어, DTO 클래스마다 직렬화/역직렬화 어노테이션을 부착하기에는 너무 많은 변경과 작업량이 우려되었습니다. 따라서 프로젝트 전역적으로 해결할 수 있는 방법인 @JsonComponent 에 대해 조사하게 되었습니다.
완성된 직렬화/역직렬화 코드 일부는 아래와 같습니다.
서버 → 클라이언트 응답
@JsonComponent
public class JsonResponseLongToStringConfig extends JsonSerializer<Long>{
@Override
public void serialize(Long idLong, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString(String.valueOf(idLong));
}
}클라이언트 요청 → 컨트롤러 파라미터로 바인딩
@JsonComponent
public class JsonRequestNumericStringToLongConfig extends JsonDeserializer<Long> {
@Override
public Long deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JacksonException {
if(org.springframework.util.StringUtils.hasText(jsonParser.getText()) && StringUtils.isNumeric(jsonParser.getText())){
return Long.parseLong(jsonParser.getText());
}
return null;
}
}참고한 링크 : Spring Boot에서 특정 필드 직렬화 방식 변경하기
