코드에서 명시적으로(explicit threading) 스레드를 선언하고 만들어서 처리하는 방법도 있지만, 명시적으로 스레드를 선언하는 코드를 짜지 않고, implicit하게 처리하는 방법도 있다.
스레드 풀, Grand Central Disspatch이런 것들이 있는데 omp 또한 이런 implicit threading의 한 방법이다.
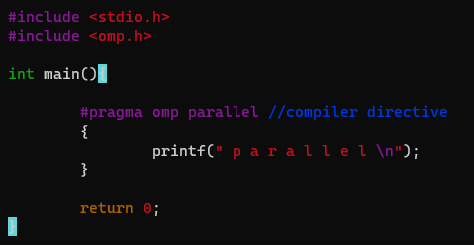
compiler directive를 줘서 컴파일시 병렬처리를 하도록 유도할 수 있음. 결과는 아래와 같다.
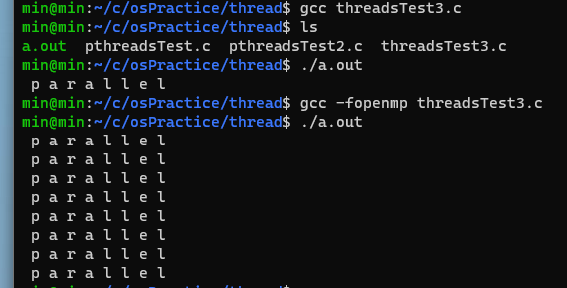
요약하자면,
-
gcc threadsTest.c 명령어로 아무 옵션 없이 평범하게 컴파일 할 경우 한 번만 실행됨.
-
gcc -fopenmp threadsTest.c 명령어로 실행할 경우, 위의 #pragma omp parallel 디렉티브를 읽고 컴파일 단계에서 병렬처리를 하도록 유도한 버전으로 컴파일 된다.
병렬처리 예제
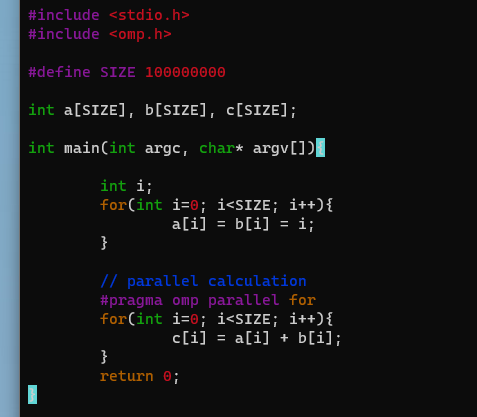
이제 위의 코드로 병렬 처리를 하면 시간이 얼마나 단축 될 수 있는지 한 번 테스트 해보자.

time 커맨드를 통해 실행 시간이 얼마나 되는지 측정할 수 있다. 여기서 real, user, sys 시간이 각각 무엇을 의미하는 지는 gpt의 설명으로 갈음한다.
-
real: Wall clock time, the total time elapsed from the start of the command to its completion. It includes time spent waiting for resources, I/O operations, etc.
-
user: CPU time spent in user mode, executing the command's code and user-level libraries.
-
sys: CPU time spent in system mode, executing system calls and other kernel-level operations on behalf of the command.
그런데 뭔가 시간이 이상하다.. 이건 좀 찾아봐야 할 듯..
