JAVA
1.[Java기초]컬렉션 Stack, Queue, Set, Map
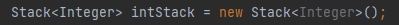
값을 수직으로 쌓아놓고 넣었다가 빼서 조회하는 형식으로 데이터를 관리 (First In Last Out)최근 저장된 데이터를 나열하고 싶거나, 데이터의 중복 처리를 막고싶을 때 사용한다. 한 쪽에서 데이터를 넣고 반대쪽에서 데이터를 뽑을 수 있는 형태. 생성자가 없는
2.[Java/Spring] 동시성 제어 (Synchronized/Volatile/Atomic)

이전 포스팅으로 동시성 제어를 하는 방법에는 synchronized/ReentrantLock/ConcurrentHashMap가 있다고 했다. 이번 포스팅에서 세가지 방법을 java코드로 좀 더 자세히 구현해 보려고 한다. 동기화가 필요한 메서드나 코드블럭 앞에 사용하여
3.[Java] HttpStatus.class 톺아보기 - HTTP상태 코드 표(100~500)
Intro API를 구현하다 보면 필연적으로 예외처리를 해 줄 수 밖에 없는데 백엔드 개발자에게 HttpStatus처리가 가장 많이 쓰이는 예외처리 중 하나일 것이라고 생각한다. 왜냐하면 아주 간단한 과제들에서도 해당 클래스를 너무나도 많이 써왔기 때문에.. 안의 내
4.[Java] JPA란?
JPA 한줄 요약 > 자바의 ORM기술을 쉽게 구현하도록 도와주는 API ORM (Objcet-Relation Mapping/ 객체-관계매핑) 객체와 DB의 데이터를 자동으로 매핑 SQL 쿼리가 아닌 메서드로 데이터 조작 가능 객체간 관계를 바탕으로 SQL
5.[Java]JPA - @OneToMany, @ManyToOne 이해하기.
OneToOne - 1:1OneToMany - 1:NManyToOne - N:1ManyToMany - N:M >>> 실무 사용 금지! N:M 연관관계는 RDB에서 일반적인 방법으로 표현할 수 없어서 중간 테이블이 생기게 된다. 따로 중간 엔티티를 만들어서 1:N, N:
6.[Spring/JPA] @Modifying + flushAutomatically, clearAutomatically
Spring.io공식 문서@Query 어노테이션(JPQL Query, Native Query)을 통해 작성된 DML쿼리에서 사용되는 어노테이션. 기본적으로 JpaRepository에서 제공하는 메서드 혹은 메서드 네이밍으로 만들어진 쿼리에는 적용되지 않는다.clearA
7.[java] Guava:Google Core Libraries 활용법, 예제 코드
https://mvnrepository.com/artifact/com.google.guava/guava/11.0.2 Gradle // https://mvnrepository.com/artifact/com.google.guava/guava implementation
8.[JAVA]메서드 체이닝에 대해 알아보자.

가끔 프로그래머스 같은 사이트를 보면 메소드 체이닝을 이용해 한줄로 끝내는 천재들을 많이 볼 수 있다. 메소드체이닝을 이용하면 코드가 간결해 진다는 이점도 있지만, 때로는 가독성 적인 부분에서 이해하기 어려운 코드가 되기도 하여 상황에 따라 적절하게 쓰는 것이 중요하다
9.[Java] VO(Value Object)란? 왜 사용하는데?
내가 하고있는 이커머스 프로젝트에서는 최근 3일간의 판매 순위 Top5를 뽑아오는 Rank API가 존재한다. RankingRepository.javaRankingService.javaJPQL로 3일전에 판매된 데이터를 모두 가져와서 같은 productId로 그룹핑 한
10.[Java] DTO vs Record / Record를 DTO로 사용하는 이유?

Java에서 DTO와 Record를 왜 구분지어 쓰고 Record사용을 권장하는걸까? Record와 DTO, 어떤 상황에 쓰면 좋을지 알아보자.
11.[Java] Java 8 문법을 알아보자. -1 (람다표현식&Stream API / Optional )
0. 왜 많고 많은 버전 중 Java 8인가?