0. 장애대응이 왜 필요할까?
🙅🏻장애란?
특정 상황이 발생해 현재 운영 중인 서버가 정상 작동이 불가능한 상태.
Lack of Resource: 메모리 누수 및 OOM(Out of Memory Error)로 인한 APP 비정상 종료Unhandled Exception: 처리되지 않은 Exception으로 인한 APP CashSlow Query, I/O: 응답 지연으로 이어지는 최적화 되지 않은 작업
이 외에도 예측불가한 상황과 유저의 행동 또는 환경들로 인해 언제든 발생할 수 있는게 장애이다.
장애가 지속 ➡️ 사용자의 불편 초래 ➡️ 서비스 이탈❗로 이루어 지기 때문에 장애를 모두 막을 순 없지만 일어난 장애에 대해 빠르게 대응해야한다.
장애 감지는 어떻게 할까?
모니터링 및 로깅중인 지표
- 서버의 리소스(Latency, Disk) 등의 지표를 확인한다.
- 데이터를 올바르게 파싱하지 못하는 경우에 로깅 및 알림을 받는다.
- 에러의 빈도가 잦은 경우에 알림을 받는다.
- 모든 Request, Response를 로깅한다.
중앙화된 로거 및 로깅 규칙
- Health Checker
- Datadog
- OpenSearch
- Slack Alert Bot
일전에 갑작스럽게 트래픽이 몰렸을 때를 대비한 작업들(인덱스, 캐시, 카프카 등.. )이 정말 트래픽을 견딜 수 있는지 미리 확인하기 위해서는 부하테스트를 해봐야한다.
1. 부하테스트는 어떻게 할까?
🔥부하테스트의 목적
- 장애를 유발할 수 있는 테스트 시나리오를 작성한다.
- 미리 서버의 성능에 대해 목표를 정하고 다음과 같은 상항들에 대해 점검한다.
1) 예상 TPS(Transaction Per Second)
2) 평균/중간/최대 응답시간
- 평균 응답시간? :
3) 다량의 트래픽 유입 시 동시성 이슈 발생 여부
위 사항들을 점검하고 목표치를 달성하지 못 하거나 기대치에 못 미치는 경우 원인을 분석하고 성능 개선을 진행한다.
부하테스트의 대상
우리 서비스에서 제공하는 전체 API를 나열해 보고, 각각의 목표 TPS를 대략적으로 작성한다.
목표 TPS를 활용하여 User, Response Time등을 설정해서 시나리오를 만들어 본다.
특수한 트래픽을 처리하기 위한 기능, 동시성 이슈를 고려한 기능 등 어떤 유형의 부하가 주어졌을 때, 기능이 예측과 같이 동작하는지 혹은 너무 낮은 성능을 보이고 있지는 않은지 등을 점검한다.
테스트 시나리오 설계
- 예상 병목지점에 대해 고려하고 시나리오를 설계한다.
- Db조회 등 연산이 무거운 API에 대해 Slow Query를 확인하는 시나리오를 생각해 본다.
성과 측정
부하 테스트로 다음의 지표를 수집한다.
- 평균 응답 시간(Response Time)
- 처리량(Throughput)
- 실패율(Error Rate)
- 최대 동시 사용자 수 (Concurrent Users)
2. 부하 테스트 대상 선정하기.
🛒E-Commerce에서 발생할 수 있는 성능 문제.
이커머스에서 갑자기 트래픽이 몰리는 사례
1. 프로모션 및 할인 이벤트🏷️
특정 시간 동안 할인을 제공하거나, 한정된 수량의 상품을 판매하는 이벤트를 진행한다.
- 트래픽 급증으로 인해 서버 과부하 발생.
- 장바구니 추가, 주문, 결제 API요청이 집중됨.
- DB에서 상품 재고 업데이트와 관련된 동시성 이슈
2. 신상품 출시
인기가 많은 브랜드나 카테고리에서 새롭게 출시된 상품을 구매하려는 고객이 몰림.
- 상품 조회 API가 집중적으로 호출됨.
- 빠른 품절로 인한 재고 관련 트랜잭션 처리 증가
- 특정 시간대에 높은 동시성 요청 발생.
3. 특정 시즌
ex) 블랙프라이데이, 크리스마스, 설날, 추석 등 쇼핑 수요가 높은 시기.
- 특정 시간, 기간에 집중적으로 트래픽이 증가.
- 장시간 고부하 상태가 지속될 가능성이 있음.
- 고객의 주문 및 결제 실패로 인해 CS증가.
4. 한정판 상품 판매
수량이 제한된 한정판 상품 특정시간에 판매.
- 트래픽이 판매 시작 직전, 시작 후 몇 분간 최고조에 도달.
- 특정 상품의 재고 조회, 주문 API가 집중 호출.
- 실패한 요청 재시도로 인한 요청 폭팔.
5. 바이럴 효과
특정 상품이 소셜 미디어, 뉴스 등을 통해 갑작스럽게 유명해짐.
- 예측이 불가하다 > 유명 인플루언서의 라이브 방송 소개로 인해 갑작스럽게 찾게될 수 있음.
- 해당 상품 조회, 주문 API요청 폭발.
- 전체 시스템의 자원이 특정 상품에 집중될 수 있음.
6. 시스템 장애 복구 직후
장애로 인해 중단된 서비스를 복구한 직후에 요청이 한꺼번에 몰림.
- 복구 후 밀렸던 요청이 한꺼번에 처리되어 부하 발생.
- 대기 상태였던 주문 및 장바구니 관련 요청 증가.
내 e-commerce 프로젝트에서 가능한 부하테스트 대상.
-
포인트 조회 : 대량 사용자 요청 시 성능 확인.
➡️ 상품 주문 시 현재 가지고 있는 포인트 조회를 하게된다.
1초에 100명의 사용자가 포인트를 조회할 경우. -
상품 주문 : 주문 시 동시성 문제 및 재고에 대한 데이터 일관성 확인
➡️100명의 사용자가 동시에 같은 상품을 주문할 경우에 대한 동시성 제어 -
같은 상품 조회 : 높은 조회 빈도에 대한 캐싱
➡️ 500명이 1초에 10번씩 조회
3. 트래픽 집중 시 발생하는 문제 & 대응 방안
발생하는 문제
- 서버 과부하 : 응답시간이 느려지거나 다운됨.
- 동시성 문제 : 재고 감소 또는 포인트 차감 시 데이터 불일치 발생.
- 데이터베이스 병목 : 읽기/쓰기 요청이 몰리면서 성능 저하.
- 캐시 부족 : 트래픽 폭증 시 캐시 용량 초과로 인한 DB과부하
- 사용자 경험 저하 : 주문 실패, 페이지 로드 지연, 장바구니 추가 실패 등
대응 방안
- 트래픽 예측
- 이벤트 전 트래픽 증가율을 예측하여 인프라 확장 계획.
- APM 도구를 활용해 과거 이벤트 데이터를 분석.
- 캐싱 사용
- 상품 조회, 카테고리 리스트에 캐싱 적용 (예: Redis).
- 캐시를 활용해 DB 접근 횟수 감소.
- 오토스케일링
- 클라우드 환경에서 트래픽에 따라 자동으로 서버 확장.
- CPU 사용량 기준으로 동적으로 조정.
- 큐잉 시스템
- RabbitMQ, Kafka 등을 활용해 주문 요청을 큐에 적재하여 처리 속도를 제어.
- 리소스 제한
- Docker에서 리소스 제한을 설정해 이벤트 동안 안정적으로 서비스 제공.
- 로드 밸런싱
- 트래픽을 여러 서버로 분산.
4. K6를 통한 부하테스트
주요 지표
http_req_failed: 실패한 요청의 수.http_req_waiting: 요청이 성공하기까지 대기한 시간.http_reqs: 전체 요청 수.iteration_duration: 1번의 사이클당 걸린 시간을 의미.p(90),p(95),p(99): 특정 값이 전체 데이터에서 차지하는 위치.
포인트 조회
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
vus: 100, // 가상 사용자 수 (100명)
duration: '1s', // 테스트 실행 시간
};
export default function () {
// __VU은 현재 Virtual User ID를 나타냄 (1부터 시작)
let userId = __VU;
let url = `http://localhost:8080/customers/${userId}/balance`;
let params = {
headers: {
'Content-Type': 'application/json; charset=utf-8',
},
};
// HTTP GET 요청
http.get(url, params);
// 1초 대기 (필요 시 조정)
sleep(1);
}customerId가 url로 들어가므로 __VU를 이용해서 customerId를 하나씩 늘려주며 요청을 보냈다.
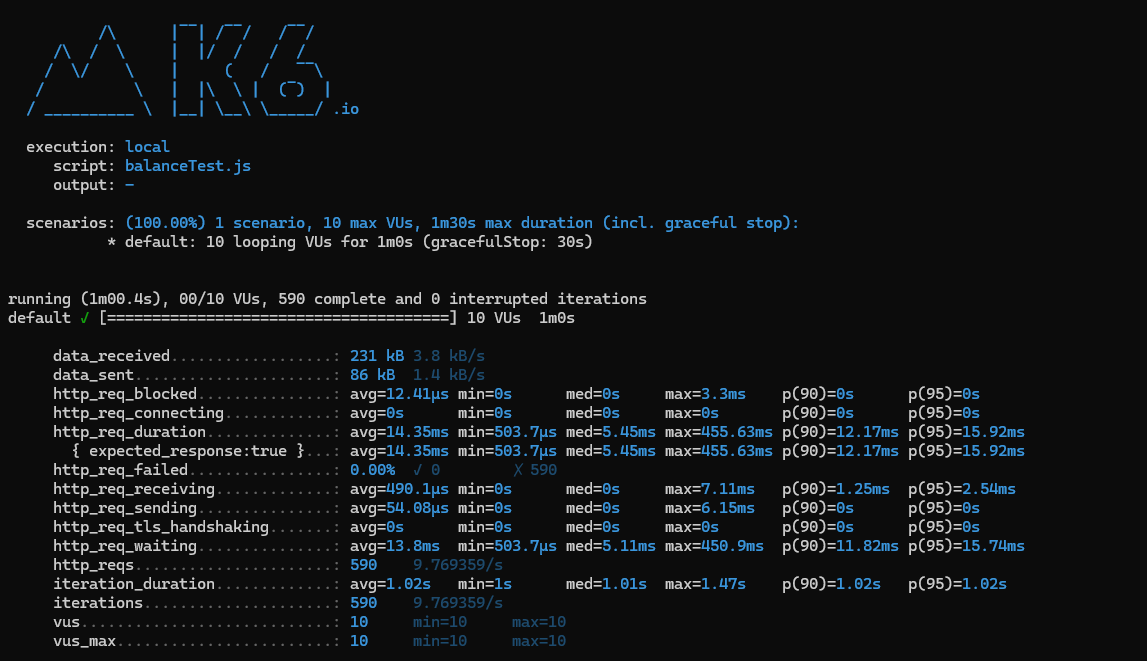
http_req_failed: 0.00%http_req_waiting: 13.8mshttp_reqs: 590iteration_duration: 1.02sp(90),p(95): http_req_waiting을 보면 95%의 사용자가 15.75ms 이내로 응답을 받은 것을 알 수 있다.
주문 테스트
import http from 'k6/http';
import { sleep } from 'k6';
import { check } from 'k6';
export const options = {
vus: 100, // 가상 사용자 수
duration: '1s', // 테스트 실행 시간
};
export default function () {
// 1~10000 사이의 랜덤 customerId 생성
const customerId = Math.floor(Math.random() * 10000) + 1;
const url = 'http://localhost:8080/orders';
const payload = JSON.stringify({
customerId: customerId,
orderProducts: [
{
productId: 3,
amount: 2,
},
],
});
const params = {
headers: {
'Content-Type': 'application/json; charset=utf-8',
},
};
// POST 요청 실행
const response = http.post(url, payload, params);
// 응답 상태 체크
check(response, {
'is status 200': (r) => r.status === 200,
});
// 1초 대기
sleep(1);
}

상품 3의 재고를 150개로 설정해 두었고, 부하 테스트로 3번 상품을 2개씩 100번 구매요청을 보내므로 25번의 요청은 실패를 할 것으로 예상했다.
그러나,
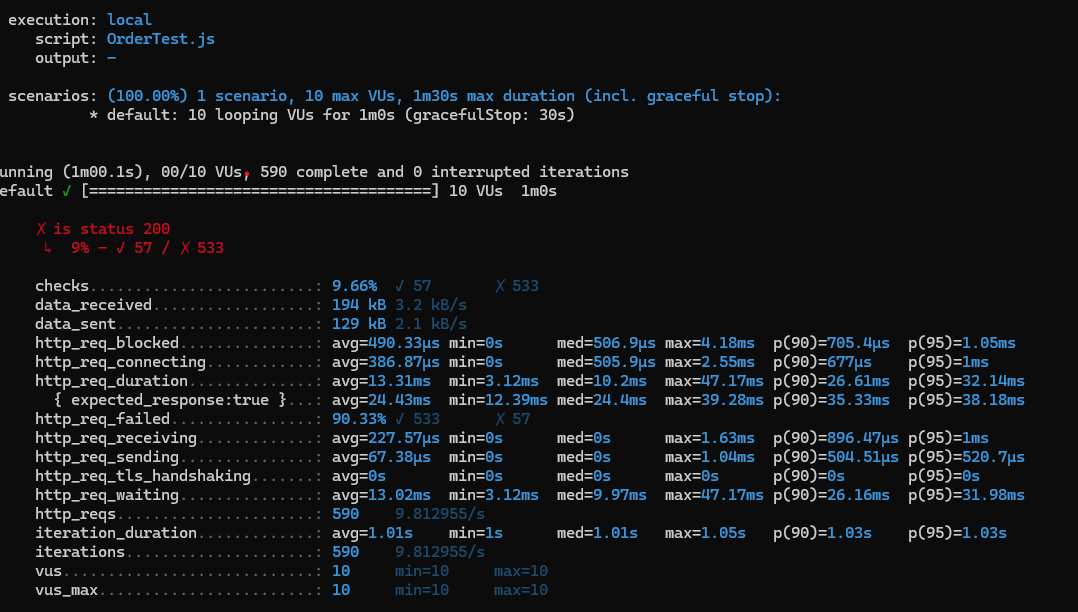
- 대다수(90.33%)의 응답이 실패.
- 평균 요청시간은 짧으나 많은 요청이 실패함.
➡️ 서버에서 오류 처리 도는 요청 자체가 성공하지 못해 빠르게 반환된 것으로 보인다.
문제점 분석
- 높은 실패율 >
서버의 부하,API로직 문제,서버 설정 오류 - 처리 대기시간 > 서버가 높은 요청량을 처리하지 못하고 병목이 발생함.
- 송수신 데이터량이 요청 수에 비례하지 않는 것으로 보아, 서버가 오류를 반환하거나 일부 요청이 무시된 것으로 추측된다.
추가로 해야 할 작업 및 테스트
1) 요청 사용자 수를 점진적으로 늘려보기.
2) 부하를 일으키는 로직 개선하기
3) 캐시를 적용할 수 있는 부분들은 캐시를 적용하고 성능 개선하기.
4) cpu 성능 향상시키기
병목 위치를 파악하려고 하였는데, 갑자기 된다(?)
🏷️Trouble Shooting
read:connection reset by peer:소켓 개수의 제한으로 발생하는 문제.

- 30초에 1명
최소 9ms, 최대 548ms의 편차가 발생했지만 네트워크 지연 초기 요청 설정 때문으로 보인다.
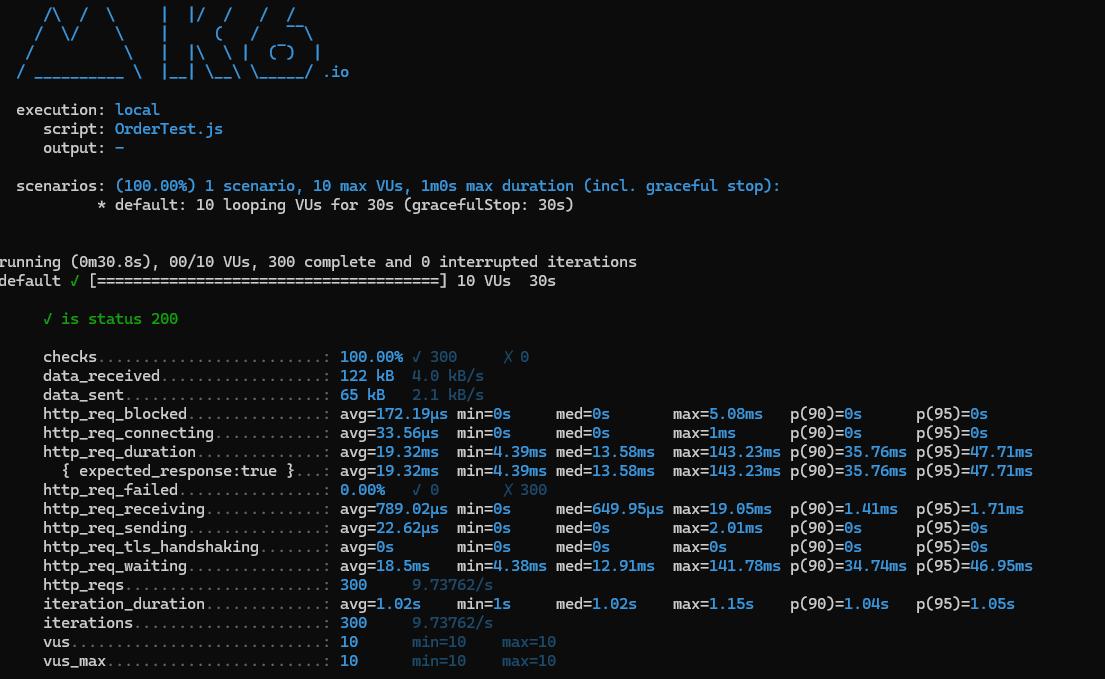
- 30초에 10명
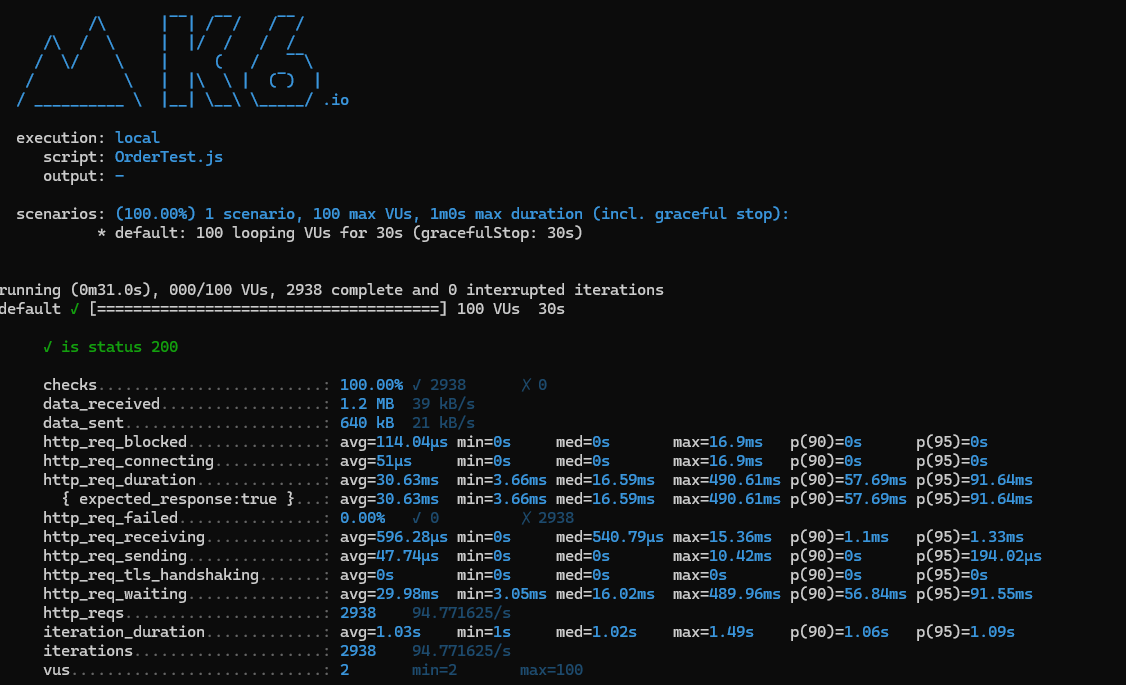
- 30초에 100명
➡️100명의 가상 사용자가 동시에 요청을 보냈음에도 서버가 안정적으로 처리했다.
점진적 과부화를 줬더니 다시 된다..?
성능 상태
- 모든 요청이 정상응답(HTTP 200)으로 완료되었다.
- 100VUs까지 부하를 증가시켰음에도 평균 응답시간이 40ms이내로 유지되었고, 성공률 또한 100%로 유지되었다.
- p(95) 기준 응답시간이 91.6ms로 안정적임을 알 수 있다.
병목 지점
- 100명의 가상 사용자 테스트 시 최대 응답시간이 증가하였으나 데이터베이스나 네트워크I/O 병목이 발생했을 가능성이 있다.
상품 조회
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
stages: [
{ duration: '10s', target: 500 }, // 10초 동안 500명의 사용자로 증가
{ duration: '1m', target: 500 }, // 1분 동안 500명의 사용자 유지
{ duration: '10s', target: 0 }, // 10초 동안 사용자를 0으로 감소
],
thresholds: {
http_req_failed: ['rate<0.01'], // 1% 미만의 요청만 실패해야 함
http_req_duration: ['p(95)<500'], // 95% 요청이 500ms 미만이어야 함
},
};
export default function () {
let url = 'http://localhost:8080/products/10';
let params = {
headers: {
'Content-Type': 'application/json; charset=utf-8',
},
};
for (let i = 0; i < 10; i++) {
http.get(url, params);
sleep(1); // 각 요청 사이에 1초의 대기 시간
}
}500명의 고객이 1초에 10번씩 조회하도록 하는 스크립트이다.
지난번에 인덱스 설정이 잘못되어 성능을 향상시킬 수 없었는데, 이번 부하테스트를 위해선 필연적으로 인덱스를 적용시켜야만 했다.
인덱스를 요리조리 바꿔보다가
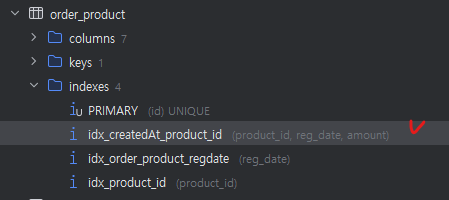
product_id와 reg_date의 순서를 변경하고 amount를 추가한 복합인덱스로 변경하였다.
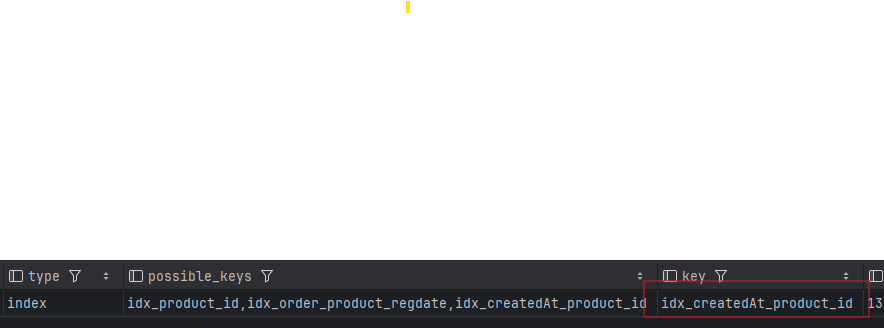
그 결과 내가 의도한 인덱스를 타게되었고 성능또한 향상되었다.
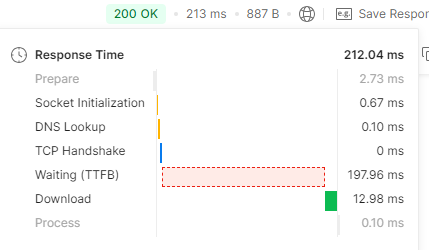
1번 호출 시 213ms가 걸렸고 이제 부하테스트를 해보겠다.

인덱스와 캐싱의 조합은 효과가 대단했다..!
http_req_failed : 0%
p(95) : 47.01ms
정도로 500명의 요청자가 무리없이 50ms 내로 응답을 받았다.
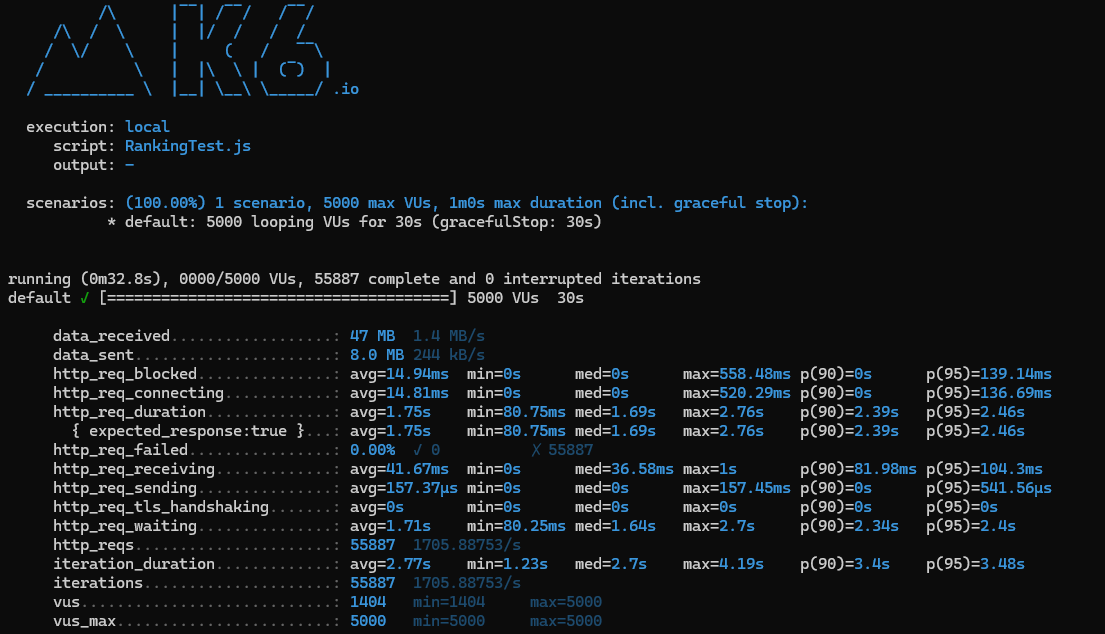
- 5000명, 30s
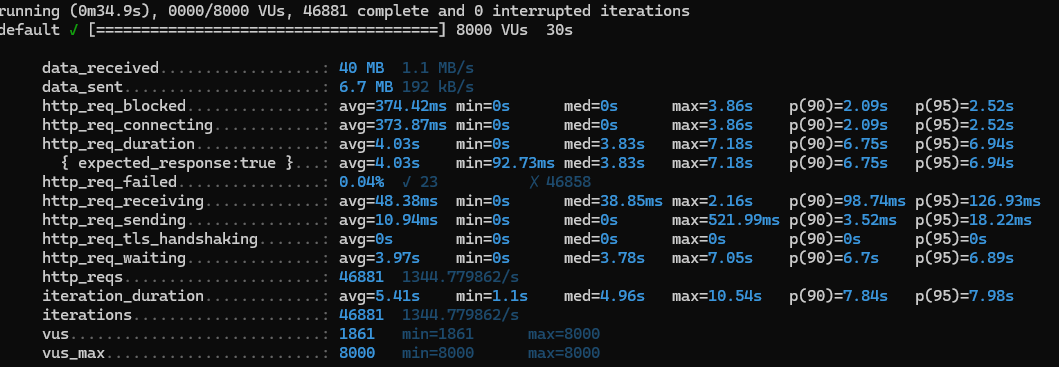
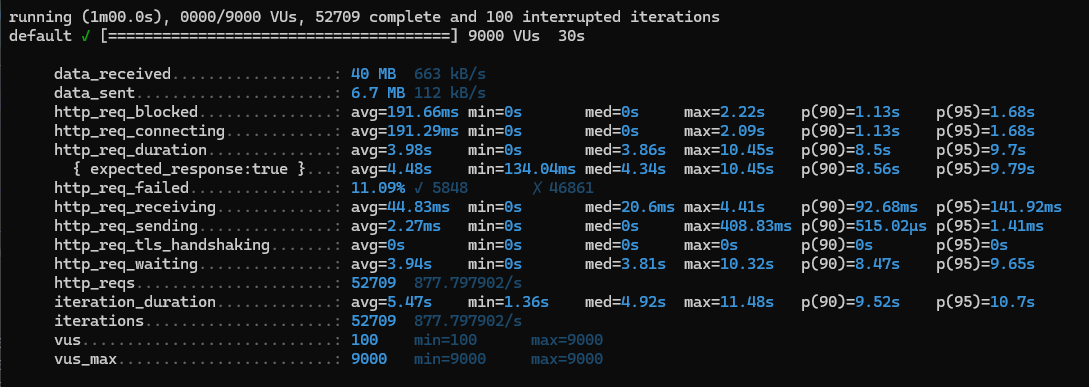
- 7500명까지도 버텼으나 8000명 부터 실패건수가 생기기 시작했다.
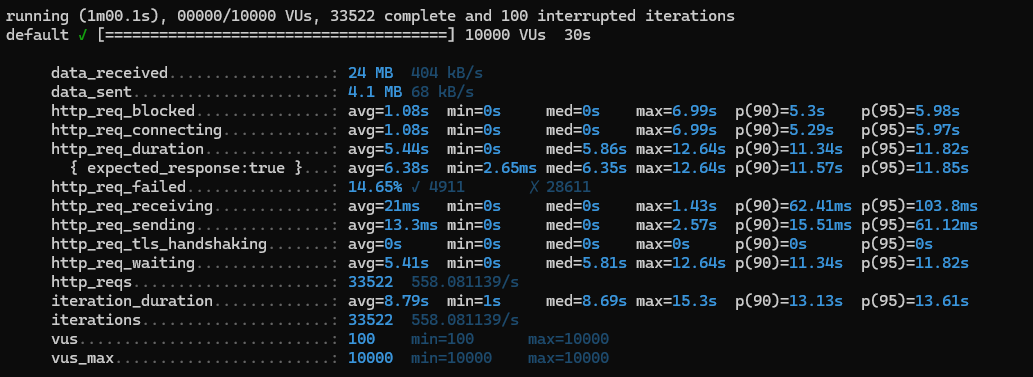
- 10000명, 30s
응답속도가 현저히 느려진 것을 볼 수 있다.
캐시와 인덱스조차도 힘을 내지 못하는 상황에 와 버린 것이다.
해결방안 도출하기.
spring.datasource.hikari.maximum-pool-size=20
히카리의 풀 사이즈를 최대로 잡아보았다.
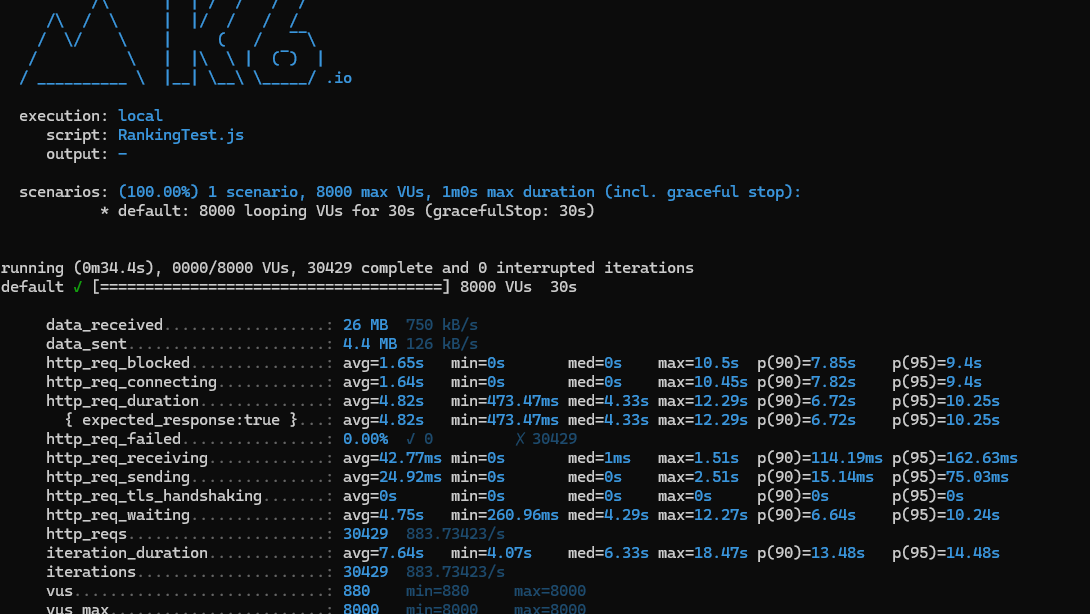
- 아까 실패건수가 생겼던 8000명을 실패없이 모두 처리했다.

하지만 10000명에서는 조금 더 많은 실패를 보였지만 p(95)의 응답시간은 많이 줄어들었다.
이 방법 말고도 위에서 언급한 로드밸런싱을 통해 요청을 분산시키는 방법으로도 트래픽을 대비할 수 있을 것이다.
5. 장애 대응은 어떻게해야할까?
장애 탐지
- 모니터링 시스템으로 비정상적인 오류나 트래픽을 탐지한다.
- 담당자에게 신속하게 전파 ex)온콜
장애 분류 및 전파
- 담당자에 의해 장애 영향도에 따른 등급 분류
- 장애 등급에 따른 심각도에 따라 관련 채널을 통해 장애 전파
- 각 담당자의 대응 작업 산정 및 고객 선제 응대
장애 복구 및 보고
- 장애 원인의 파악 및 대응 진행
- 장애 복구 진행 상황에 대한 신속한 공유 및 업데이트
- 장애 상황 요약 및 분석, 개선 내용 보고
장애 상황 해서 통지
- 장애 복구가 완료되어 장애 상황이 해소되었다면 유관 부서 및 사내에 전파
- 장애 해소 및 서비스 정상화에 대해 고객에게 공지
장애 회고
- 장애 상황 피드백 및 추가 개선점 분석
