Elasticsearch 공식 페이지 : 6.7.2 노리 (nori) 한글 형태소 분석기
nori
-
Elasticsearch 6.6 버전부터 공식 지원하는 한글 형태소 분석기
-
mecab-ko-dic 사전 사용
설치
설치
$ bin/elasticsearch-plugin install analysis-nori
제거
$ bin/elasticsearch-plugin remove analysis-nori인덱스 정의 예시
PUT nori_index
{
"settings": {
"analysis": {
"analyzer": {
"nori_discard": {
"type": "custom",
"tokenizer": "nori_t_discard",
"filter": ["synonym", "my_shingle"]
}
},
"tokenizer": {
"nori_t_discard": {
"type": "nori_tokenizer",
"decompound_mode": "discard",
"user_dictionary": "analysis/userdic.txt"
}
},
"filter": {
"synonym": {
"type": "synonym_graph",
"synonyms_path": "analysis/synonyms.txt"
},
"my_shingle": {
"type": "shingle",
"token_separator": "",
"max_shingle_size": 3
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"nori": {
"type": "text",
"analyzer": "nori_discard"
}
}
}
}
}
}rooms 도큐먼트 검색 api
request example
GET nori_index/_search
{
"query": {
"match": {
"title.nori": "동해"
}
}
}
response example
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.3166962,
"hits" : [
{
"_index" : "nori_index",
"_type" : "_doc",
"_id" : "iVF7_nwB93HRpra7cb9E",
"_score" : 2.3166962,
"_source" : {
"title" : "동해물과 백두산이"
}
}
]
}
}nori_tokenizer
-
사전 정보를 이용해 형태소를 분리
-
user_dictionary 옵션
사용자 사전이 저장된 파일 경로 입력
사전 내용 변경시 _close / _open 하여 인덱스에 변경사항 반영
- user_dictionary_rules
사용자 정의 사전을 배열 형태로 입력
- decompound_mode
합성어 저장 방식 결정
none : 완성된 합성어만 저장
discard (default) : 합성어를 분리하여 어근만 저장
mixed : 어근, 합성어 모두 저장
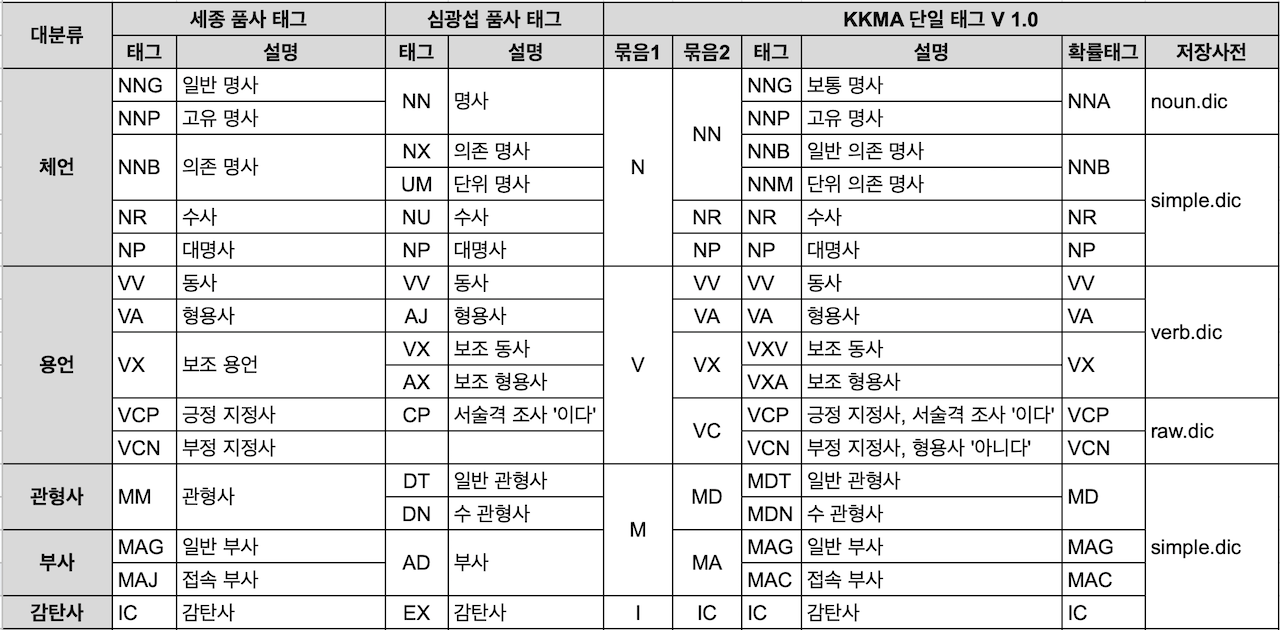
- nori_part_of_speech
제거할 품사를 지정하는 토큰 필터
옵션 stoptags 배열에 제외할 품사코드 나열해서 사용
- 품사코드
nori_readingform
- 한자 단어를 한글로 바꾸어 저장하는 토큰 필터
termvectors api
- 색인된 도큐먼트의 역인덱스를 확인할 때 사용하는 api
GET {index_name}/_termvectors/{document_id}?fields={fieldname}request example
GET nori_index/_termvectors/jVHQ_nwB93HRpra7_L_M?fields=title.nori
response example
{
"_index" : "nori_index",
"_type" : "_doc",
"_id" : "jVHQ_nwB93HRpra7_L_M",
"_version" : 1,
"found" : true,
"took" : 4,
"term_vectors" : {
"title.nori" : {
"field_statistics" : {
"sum_doc_freq" : 102,
"doc_count" : 8,
"sum_ttf" : 102
},
"terms" : {
"과" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 3,
"end_offset" : 4
}
]
},
"과백두" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 3,
"end_offset" : 7
}
]
},
"과백두산" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 3,
"end_offset" : 8
}
]
},
"동해" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 2
}
]
},
"동해물" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 3
}
]
},
"동해물과" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 4
}
]
},
"물" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 2,
"end_offset" : 3
}
]
},
"물과" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 2,
"end_offset" : 4
}
]
},
"물과백두" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 2,
"end_offset" : 7
}
]
},
"백두" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 5,
"end_offset" : 7
}
]
},
"백두산" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 5,
"end_offset" : 8
}
]
},
"백두산이" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 5,
"end_offset" : 9
}
]
},
"산" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 7,
"end_offset" : 8
}
]
},
"산이" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 7,
"end_offset" : 9
}
]
},
"이" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 8,
"end_offset" : 9
}
]
}
}
}
}
}analyze api
- 형태소 분석 결과를 확인할 때 사용하는 api
request example
GET nori_index/_analyze
{
"text": "동해물과 백두산이",
"analyzer": "nori",
"explain": true
}
response example
{
"detail" : {
"custom_analyzer" : false,
"analyzer" : {
"name" : "nori",
"tokens" : [
{
"token" : "동해",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0,
"bytes" : "[eb 8f 99 ed 95 b4]",
"leftPOS" : "NNP(Proper Noun)",
"morphemes" : null,
"posType" : "MORPHEME",
"positionLength" : 1,
"reading" : null,
"rightPOS" : "NNP(Proper Noun)",
"termFrequency" : 1
},
{
"token" : "물",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 1,
"bytes" : "[eb ac bc]",
"leftPOS" : "NNG(General Noun)",
"morphemes" : null,
"posType" : "MORPHEME",
"positionLength" : 1,
"reading" : null,
"rightPOS" : "NNG(General Noun)",
"termFrequency" : 1
},
{
"token" : "백두",
"start_offset" : 5,
"end_offset" : 7,
"type" : "word",
"position" : 3,
"bytes" : "[eb b0 b1 eb 91 90]",
"leftPOS" : "NNG(General Noun)",
"morphemes" : null,
"posType" : "MORPHEME",
"positionLength" : 1,
"reading" : null,
"rightPOS" : "NNG(General Noun)",
"termFrequency" : 1
},
{
"token" : "산",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 4,
"bytes" : "[ec 82 b0]",
"leftPOS" : "NNG(General Noun)",
"morphemes" : null,
"posType" : "MORPHEME",
"positionLength" : 1,
"reading" : null,
"rightPOS" : "NNG(General Noun)",
"termFrequency" : 1
}
]
}
}
}
2년차 백엔드 개발자