💡Stream API란?
Stream API란 Java 8에서 도입되어 데이터 컬렉션을 함수형 스타일로 처리할 수 있게 하는 기능이다. 이는 데이터를 추상화하고 처리하는 다양한 연산을 수행할 수 있게 해준다. 특히, 데이터 소스에 대한 계산 로직을 고수준에서 간결하게 표현할 수 있어, 코드의 가독성과 유지보수성이 향상된다.
List<String> myList = Arrays.asList("a1", "a2", "b1", "b2", "c1", "c2");
myList.stream()
.filter(s -> s.startsWith("c"))
.map(String::toUpperCase)
.sorted()
.forEach(System.out::println);
✅Stream이란?
스트림이란 데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소로 정의할 수 있다.
연속된 요소
- 컬렉션과 마찬가지로 스트림은 특정 요소 형식으로 이루어진 연속된 값 집합의 인터페이스를 제공한다.
- 컬렉션은 자료구조이므로 시간과 공간의 복잡성과 관련된 요소 저장 및 접근 연산이 주를 이룬다.
- 반면 스트림은
filter, sorted, map처럼 표현 계산식이 주를 이룬다.
소스
- 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 제공 소스로부터 데이터를 소비한다.
- 정렬된 컬렉션으로 스트림을 생성하면 정렬이 그대로 유지된다.
- 즉, 리스트로 스트림을 만들면, 스트림의 요소는 리스트의 요소와 같은 순서를 유지한다.
데이터 처리 연산
- 스트림은 함수형 프로그래밍 언어에서 일반적으로 지원하는 연산과 데이터베이스와 비슷한 연산을 지원한다.
filter, map, reduce, finde, match, sort등으로 데이터 조작가능 하다.- 스트림 연산은 순차적 또는 병렬로 실행 가능하다.
✅Stream API의 특징
저장소가 없음(No Storage)
- 스트림 자체는 데이터를 저장하지 않는다.
- 컬렉션, 배열, I/O 채널 등의 데이터 소스를 표현하는데 사용된다.
함수형(Functional in nature)
- 스트림 연산은 주로 람다 표현식을 사용하여 함수형 프로그래밍의 접근 방식을 취한다.
- 이로 인해 외부 반복 대신 내부 반복을 사용할 수 있다.
지연성 추구(Laziness-seeking)
- 많은 스트림 연산들은 지연된다는 특징을 갖고 있다.
- 즉, 실제로 필요할때까지 계산을 수행하지 않는다.
무한성(Possibly unbounded)
- 스트림은 한정된 데이터 뿐만 아니라 무한한 데이터에 대해서도 작업을 수행할 수 있다.
소비 가능성(Consumable)
- 스트림의 요소들은 소비된다.
- 즉, 한 번 사용된 스트림은 재사용할 수 없다.
✅Collection vs Stream
위에서 설명한 것을 보면 Collection과 Stream이 다르다는 것을 얼추 느꼈을 것이다.
기존에 존재하뎐 Collection과 Stream은 무슨차이가 있을까?
📘Collection
- 모든 값을 메모리에 저장하는 자료구조다.
- 따라서 Collection에 추가하기 전에 미리 계산이 완료되어 있어야 한다.
- 외부 반복을 통해 사용자가 직접 반복 작업을 거쳐 요소를 가져올 수 있다(for-each)
📗Stream
- 요청할 때만 요소를 계산한다.
- 내부 반복을 사용하므로, 추출 요소만 선언해주면 알아서 반복 처리를 진행한다.
- 스트림에 요소를 따로 추가 혹은 제거하는 작업은 불가능 하다.
✅외부 반복과 내부 반복
Collection은 외부 반복, Stream은 내부 반복이라고 했는데 이 둘은 또 뭘까?
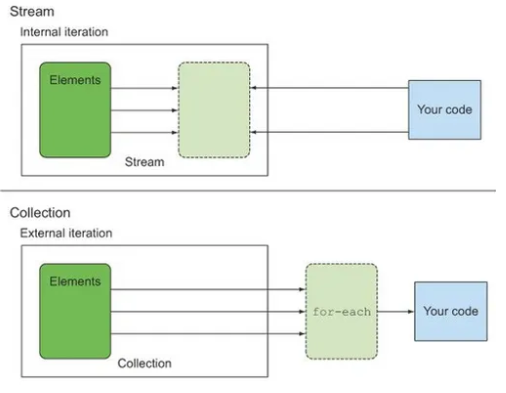
내부 반복은 작업을 병렬 처리하면서 최적화된 순서로 처리해주므로 성능면에서는 내부 반복이 비교적 좋다고 볼 수 있다.
외부 반복은 명시적으로 컬렉션 항목을 하나씩 가져와서 처리해야 하기 때문에 최적화가 불리하다.
즉, Collection에서 병렬성을 이용하려면 직접 Synchronized를 통해 관리해야만 한다.
✅Stream 연산
스트림은 연산 과정이 중간과 최종으로 나누어진다.
filter, map, limit등 파이프라이닝이 가능한 연산을 중간 연산count, collect등 스트림을 닫는 연산을 최종 연산
중간 연산에서는 호출해도 실제 연산을 수행하지 않고 파이프 라인만을 구성해두며, 최종 연산이 호출될때 비로소 중간 연산에서 만들어 둔 파이프 라인이 실행되어 실제로 연산이 수행된다.
예시로, Item 중에 가격이 1000이상인 item 이름을 5개 선택하는 Stream 연산을 구현해보자.
List<String> items = item.stream()
.filter(d->d.getPrices()>=1000)
.map(d->d.getName())
.limit(5)
.collect(tpList());위에서 filter와 map은 다른 연산이지만, 한 과정으로 병합된다.
만약 Collection이였다면
- 가격이 1000이상인 아이템을 찾고,
- 이름을 따로 저장한뒤
- 5개를 선택해야 한다.
연산 최적화와 가독성면에서 Collection보다 Stream이 더 좋다.
📌Stream 중간 연산
filter(Predicate): Predicate를 인자로 받아 true인 요소를 포함한 스트림 반환disctinct(): 중복 필터링limit(n): 주어진 사이즈 이하 크기를 갖는 스트림 반환skip(n): 처음 요소 n개 제외한 스트림 반환map(Function): 매핑 함수의 result로 구성된 스트림 반환flatMap(): 스트림의 콘텐츠로 매핑함. map과 달리 평면화된 스트림 반환
중간 연산은 모두 스트림을 반환한다.
📌Stream 최종 연산
(boolean) allMatch(Predicate): 모든 스트림 요소가 Predicate와 일치하는지 검사(boolean) anyMatch(Predicate): 하나라도 일치하는 요소가 있는지 검사(boolean) noneMatch(Predicate): 매치되는 요소가 없는지 검사(Optional) findAny(): 현재 스트림에서 임의의 요소 반환(Optional) findFirst(): 스트림의 첫번째 요소reduce(): 모든 스트림 요소를 처리해 값을 도출. 두 개의 인자를 가짐collect(): 스트림을 reduce하여 list, map, 정수 형식 컬렉션을 만듬(void) forEach(): 스트림 각 요소를 소비하며 람다 적용(Long) count: 스트림 요소 개수 반환
✅지연 평가(Lazy evaluation)
지연 평가(Lazy evaluation)는 필요해지기 전까지 계산을 미루는 전략이다.
값이나 연산을 바로 계산하지 않고, 실제로 그 값이 요구되는 시점에 계산을 수행하여 불필요한 계산을 줄이고 메모리/시간을 아낄 수 있다는 장점이 있다.
Stream의 중간 연산은 바로 실행 되지 않고 대기하다가 최종 연산이 호출되는 순간 실제 연산이 수행된다.
지연 평가가 중요한 이유는 아래와 같다.
1️⃣불필요한 연산 회피
findFirst, anyMatch, limit 같은 단축 연산은 조건이 만족되면 즉시 파이프라인을 종료하므로 시간이 절약 된다.
2️⃣파이프라이닝
파이프라인은 중간 연산들을 결합해 요소 하나를 끝까지 처리한 뒤 다음 요소로 넘어간다. 즉, 중간 결과 컬렉션을 만들지 않기 때문에 메모리 사용과 GC 압박이 감소된다.
3️⃣성능 최적화
스트림은 연산 순서와 조합에 따라 처리량이 크게 달라진다. 예를 들어, filter로 먼저 요소를 걸러 필요한 대상만 남기면, 그 뒤에 오는 map과 같이 무거운 연산의 호출 횟수가 줄어들어 전체 성능이 좋아진다.
