💡해시테이블(Hash Table)이란?
해시테이블은 키(Key) → 값(Value)를 빠르게 찾기 위해서 해시 함수를 사용하는 자료구조 이다.
해시 테이블은 데이터를 보관할 때 주소를 계산해서 바로 꺼내오는 방식을 이용한다.
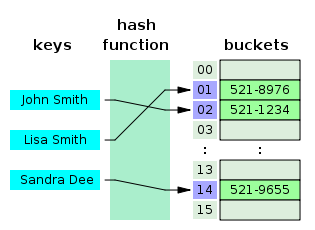
- 위
John Smith라는 사람의 전화번호를 찾는다는 가정을 해보자. - 해시 함수의 입력값은 John Smith고, 해시 함수를 통해 얻은 인덱스는
"01"이다. - 위에서 얻은 값을 배열의 인덱스로 사용하여 인덱스가 01인 bucket에서
"521-8976"을 찾는다.
💭해싱 원리
1️⃣Key 값을 입력받는다.
- 예시 : apple
2️⃣해시 함수를 통과시켜 숫자 인덱스를 얻는다.
- hash("apple") → 37
3️⃣그 숫자를 배열의 인덱스로 사용해 값을 저장한다.
- table[37] → "사과"
4️⃣다시 "apple"을 찾을 때도 똑같이 해시 함수를 거쳐 같은 인덱스를 찾아간다.
👉결국 "키 → 해시 함수 → 배열 인덱스" 를 거쳐 해싱한다.
⚡해시 충돌 (Hash Collsion)
해시테이블은 데이터를 Key로 간소화하여 저장한다. 하지만 만약 여러 데이터가 같은 해시를 갖는다면 어떻게 될까?
이러한 상황을 해시 충돌(Hash Collsion)이라고 한다.
같은 해시값을 갖는 데이터들이 생긴다는 것은 특정 해시에 데이터가 집중된다는 소리이며, 너무 많은 해시 충돌은 해시 테이블의 성능을 떨어 뜨린다.
이제 이러한 해시 충돌을 해결하기 위한 방법을 알아보자.
1️⃣체이닝(Chaining)
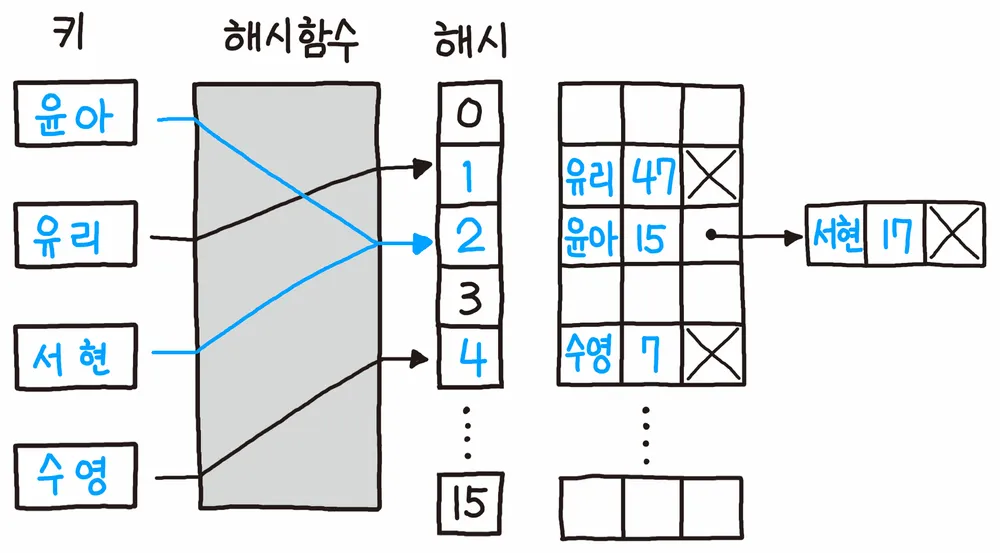
해시테이블의 기본 방식인 체이닝은 충돌 발생 시, 같은 인덱스에 연결 리스트나 트리를 두어 여러 값을 저장하는 방식이다.
- 충돌이 발생한 윤아, 서현은 윤아의 다음 아이템인 서현이 서로 연결 리스트로 연결되었다.
table[2] =["윤아","서현"]
⭕체이닝의 장점
- 구현이 단순(버킷에 연결리스트/트리만 붙이면 끝)
- Load Factor(저장된 원소 수/버킷 수)가 커져도, 테이블 크기를 반드시 늘리지 않아도 됨
- 삭제가 쉽다.
- 확장 시 충돌 관리에 유연
❌체이닝의 단점
- 포인터나 리스트/트리 때문에 메모리 추가 소모
- 캐시 효율이 떨어짐 -> 메모리가 여기저기 흩어져 있음
2️⃣오픈 어드레싱(Open Addressing)
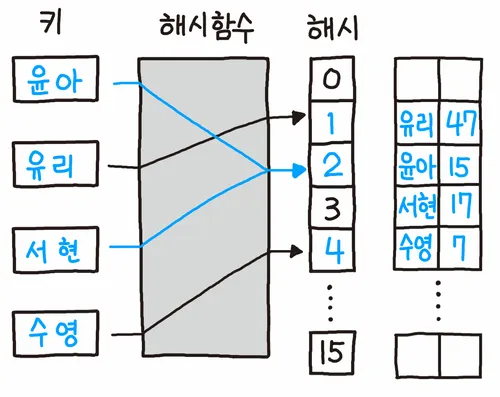
오픈 어드레싱 방식은 충돌 발생 시 버켓을 탐사하여 빈 공간을 찾고, 그 공간에 데이터를 삽입하는 방식을 말한다. 오픈 어드레싱 방식은 아래와 같다.
- 선형 탐사 : 충돌나면 다음 칸 확인
- 이차 탐사 : 1칸, 4칸, 9칸 ... 떨어진 곳 탐색
- 더블 해싱 : 다른 해시 함수를 한번 더 적용
⭕오픈 어드레싱의 장점
- 추가 자료구조가 필요 없음(배열 하나로 해결)
- 캐시 친화적 → 탐사 시 메모리 접근이 순차적이라 비교적 바름
❌오픈 어드레싱의 단점
- Load Factor가 커지면 성능이 급격히 나빠짐
- 삭제가 복잡
- 클러스터링 문제 발생(충돌이 몰리면 성능이 더 나빠진다)
☑️그럼 어떤걸 써야하나?
👉메모리 여유가 있고, 해시 함수 충돌 가능성이 꽤 있는 경우 → 체이닝 선호
👉메모리 제한이 있고, 해시 함수가 균등 분포를 잘 보장하는 경우 → 오픈 어드레싱 선호
⏱️시간 복잡도
- 평균 : O(1) → 해시 함수가 잘 설계되고, 충돌이 적을 때
- 최악 : O(n) → 모든 값이 한 버킷에 몰리면 연결 리스트 탐색 수준까지 느려질 수 있다.
👉 좋은 해시 함수가 매우 중요!
👍좋은 해시 함수의 조건
1️⃣균등성(Uniformity) : 값이 테이블 전체에 고르게 분포되어야 한다.
2️⃣결정성(Determinism) : 같은 입력은 항상 같은 해시값.
3️⃣효율성 (Efficiency) : 빠르게 계산 가능해야 함.
4️⃣낮은 충돌률 (Low Collision) : 다른 키가 같은 해시값을 덜 가지게.
✅실제 사용 사례
1. 세션 저장
- 사용자 로그인 시
sessionId→sessionData매핑 - 세션 조회 시 O(1)에 가까운 속도로 탐색 가능
2. 캐시(Cache)
url → response,query → result같은 매핑.- Redis 같은 인메모리 DB는 내부적으로 해시 테이블을 활용
3. 로드 밸런싱 (Consistent Hashing)
- 분산 서버에 요청을 나눌 때, 키를 해시값으로 바꿔 특정 서버에 매핑
- 서버 추가/삭제 시에도 최소한의 재배치만 발생

배우고 기록하며 성장하는 백엔드 개발자입니다!