Pycon2019의 셀러리 핵심과 커스터마이제이션을 정리한 글입니다.
1. Celery
celery?
메세지 전달을 기반으로 한 비동기 task 큐
- 작업 : message로 표현됨
- Client : 작업을 요청하는 주체
- Worker : 작업을 수행하는 주체
- Broker : 클라이언트와 워커 사이에서 메세지를 전달함.
이러한 구조에서는 클라이언트와 워커 모두 scaling이 가능하다. 따라서 클라이언트는 불필요하게 무거운 작업으로부터 자유롭고, 워커는 필요에 따라 확장이 가능하다.
celery는 AMQP라는 프로토콜을 기반으로 만들어졌다.
메세지를 보낼때 최소한 한번은 반드시 전달된다!!
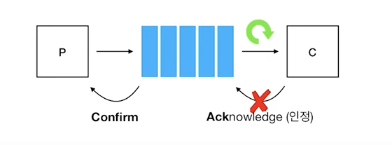
Producer가 브로커로 메세지를 보내면, 이 메세지는 Consumer로 전달된다. Consumer가 이 메세지를 Consume한 뒤 브로커로 다 처리했다는 의미의 "Ack"를 보내면, 브로커는 최초에 메세지를 보낸 Producer에게 "Confirm"을 보낸다.
만약 ack에서 문제가 생기면, 브로커는 메세지가 처리됐는지 알 수가 없어서, Consumer에게 메세지를 다시 보내게 됨.
따라서 AMQP 상에서는 이 메세지에 대한 처리를 idempotent하게 되어야 한다.
f(f(x)) = f(x) = ymessage는 여러번 전달 될 수도 있지만 이때 message 소비는 idempotent 해야한다. 즉, 여러번 전달 되어도 동일하게 하나의 작업만 수행된다는것.(엘레베이터 닫힘 버튼을 여러번 누른다고 여러번 닫히지 않는것과 같음)
2. 안정적으로 완료하기
Late Ack'
-
Why Late ACK? : 중요한 태스크를 실행을 해야하는데 실행이 되지 않았을 때.
Ack는 기본적으로 워커가 태스크를 실행하기 직전에 실행이 된다. 워커에서 Ack'를 브로커로 보내면 큐에서는 해당 작업이 삭제되고 워커에 의해서 작업이 실행된다. 이렇게 실행이 되다가 Worker Crash가 발생하면? 큐에서도 사라져 있으므로, 작업을 다시 실행할 방법이 없다. -
Late Ack 를 사용하면?
태스크의 실행이 완료됐을 때 ack가 브로커로 전달된다. 따라서 워커에 의해 태스크가 실행중일 때 worker crash가 발생해도 아직 큐에 남아있으므로 다시 실행할 수 있다. -
중복 실행될 수 있다!
Late Ack를 쓰면 태스크가 중복 실행될 수 있으므로, 반드시 태스크가 Idempotentic 하게 작성되어야 한다.
Retry
- 예상 가능하지만 통제될 수 없는 상황에서 문제가 생길 경우(외부 API 호출시의 순단 문제 등), 다시 수행되도록함.
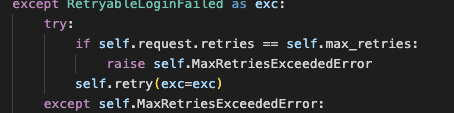
- 예상 가능한 예외에서만 적용이 되도록 해야하며, atomic하게 작동되어야 한다.
3. 효율적으로 처리하기
-
Worker는 자신이 처리할 수 잇는 만큼만 처리한다. 따라서 처리하는 속도보다 일이 쌓이는 속도가 커도 일시적으로는 큰 문제가 되지 않는다.
-
but, 이게 지속이 되면?? 브로커에 불필요한 부하가 가게 되고, 실제 필요한 작업이 진행이 되지 않을수가 있다.
-
time Limit을 설정해야 태스크가 일정시간 이상 실행되면 종료
> celery -A <PRJ> worker -P <WORKER_POOL_NAME> -c <concurrency>prefetch limit
-
prefetch limit : ack 되지 않은 태스크의 개수를 worker가 얼마나 갖고 있을 수 있는가?
prefetch limit = worker_prefetch_multifiler * concurrency
worker_prefetch_multifiler의 값에 설정한 concurrency 값을 곱하면 이 prefetch limit 값이다.
[worker_prefetch_multifiler = 0]이라면? prefetch limit에 대해 제한이 없으므로 메모리나 효율성을 고려하지 않고 작업을 실행하게 된다.
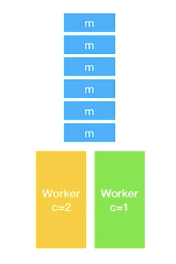
위 그림처럼 concurrency가 각각 1,2인 워커가 있고, message가 쌓여있다고 하자.
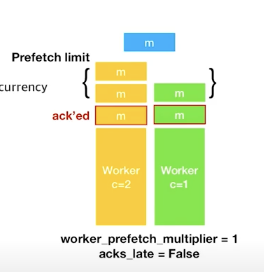
worker_prefetch_multiflier = 1, acks_late = False로 하게 되면
concurrency가 1,2 이므로 워커는 각각 prefetch_limit 이 1,2가 된다.
따라서 concurrency가 2인 워커는 (현재 수행중인 작업을 제외하고) 2개의 메세지를, concurrency가 1인 워커는 1개의 메세지를 prefetch 하게된다.
-
그럼 이 prefetch limit을 어떻게 쓸 수 있을까?
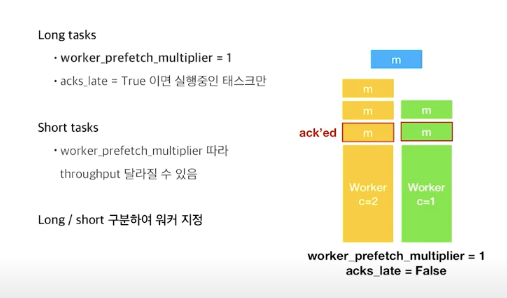
긴 태스크에 대해서는 worker_prefetch_multiplier = 1 로 설정하면 긴 태스크 뒤에 짧은 태스크들이 불필요하게 실행되는 것을 막을 수 있다.
-
acks_late = True로 설정하면?
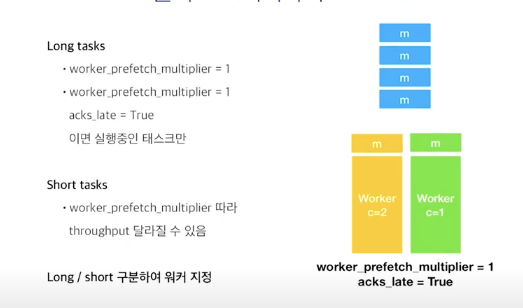
worker_prefetch_multiflier = 1이라면 실행중인 task만 prefetch하게 된다.
짧은 태스크들의 경우 worker_prefetch_multiflier에 따라 prefetch를 하는데도 네트워크를 타기 때문에 worker_prefetch_multiflier를 높여주면 task를 더 빠르게 실행시킬 수 있다(????뭔소리야???)
길고 짧은 태스크를 구분하여 워커를 지정하면서 이 옵션을 쓸 수 있다.
Prefork
- multiprocessing으로 구현이 돼있음.
- "-c N" 옵션으로 실행을 하면, 1개의 master process와 N개의 child process로 실행이 된다.
- master에서 task를 분배하고, 실제 처리는 child에서 이루어진다.
- -O fair 옵션 : master에서 child 로 task가 전달될 때 기본적으로는 pipe buffer(한방에 쓸 수 있는 양??)가 허용되는 만큼의 메세지를 전달한다. 하지만 "-O fair" 옵션을 주게 되면 실행 가능한 경우에만 메세지를 전달하게 된다.
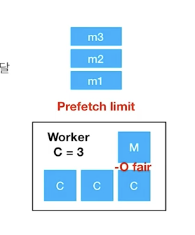
prefetch_limit은 브로커에서 워커로의 메세지 전달을 통제, -O fair는 마스터 프로세스에서 child process로의 메세지 전달을 통제하는 것이다.
긴 작업과 짧은 작업이 섞여 있는 경우에 -O fair 옵션을 주게 되면 성능 향상 및 예상 가능한 동작을 기대할 수 있다.(한줄서기를 할 때 줄이 더 빨리 줄어드는 것과 같은 원리)
작업의 성질에 따라 적절히 다르게 처리해야 한다.
- IO/CPU
- 중요도
- 수행시간
- 실행 빈도
4. customization
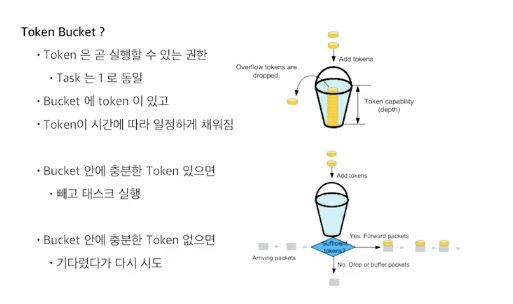
Global Rate Limit
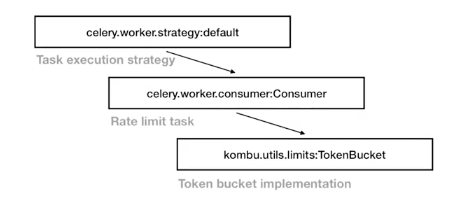
kombu라는 셀러리가 이용하는 메세징 라이브러리가 있는데, kombu에서 TokenBucket을 이용해서 RateLimit을 구현하고 있다.
TokenBucket?

좋은 글 잘 읽고 갑니다 :)