🖊 웹 크롤링
네이버 날씨 페이지 크롤링

미세먼지, 초미세먼지, 오존층 지수 세 가지의 속성값을 Python으로 크롤링하기 위해 BeautifulSoup 모듈에서 태그, 속성값에 접근하는 것을 공부했다. 각 태그에 적힌 text를 임의로 바꾸어 페이지의 내용을 맘대로 조작해보았다.
HTML 요소 - 태그:div / 속성:class / 속성값:detail_box(속성값은 여러 개도 올 수 있음)
네이버 날씨 페이지에서는 접속 위치를 알아서 계산하여 날씨 정보를 출력했다. 이때 위치에 따라 미세먼지 지수가 바뀌고, 그에 따르는 색깔, 표정 등의 속성값은 건드려도 변하지 않았다. => dd태그에 접근하는 방식
*find 함수는 찾고자 하는 것이 여러 개라면, 가장 먼저 오는 값만 탐색하지만 findAll 함수를 사용하면 여러 개를 탐색하여 각각의 줄로 분할할 수 있다.
*pprint 모듈은 줄바꿈 등의 정리가 자동적으로 이루어지고, 그 모양을 규칙적으로 배열하여 예쁘게 출력하는 모듈이다.
네이버 웹툰 페이지 크롤링

월요일~일요일까지 이름만 변하고 모두 같은 패턴의 코드를 가진다. 이를 반복문으로 태그를 추출할까 했지만 '*'로 패턴으로 처리하여 한 번에 추출할 수 있었다.
BeautifulSoup 모듈, pprint 모듈
🖊 웹 자동화
유튜브 검색창을 띄워 검색어 입력하기
유튜브 검색창에 대한 X Path를 copy하여 selenium모듈에서 사용하는 특정 경로 지정함수,'find_element_by_xpath'로 그 경로에 접근했다. 특정 패턴 문자열에 따라 원하는 정보를 변수에 저장하고 입력(click)하기까지 코드를 짰다.
1 to 50, 색맹테스트 자동화
두 게임의 공통점은 여러 개의 칸 중에서 하나를 선택할 때, 그 다음으로 넘어갈 수 있다는 것이다. 이는 각 칸마다 반복되는 패턴 문자열이 있다는 것이고 반복되는 X Path의 패턴을 '*' 로 표시하면. 패턴으로 인식해서 모두 받아올 수 있다.
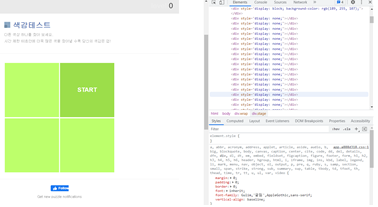
//*[@id="grid"]/div[1]
//*[@id="grid"]/div[2]
.
.
//*[@id="grid"]/div[6]=> BUT 사이트의 분석을 통해 특징을 파악하고, 규칙과 패턴을 찾는 방법도 있지만 꼭 정석대로 하지 않아도 class명, tag명만 알아도 간단하게 코드를 구현하여 같은 결과를 도출할 수 있다.
웹 사이트 분석의 중요성.
앞으로의 계획: html 이해하기, 웹 공부를 통해 내가 자주 사용하는 사이트의 패턴과 구성 공부해서 정리하기, 앞으로 공부하면서 유의미하다고 느끼는 부분들은 Velog에 정리하기
selenium 모듈
진행과정을 보고 싶지 않을 때, 즉 Chrome 창을 숨기고 싶을 때 디음 코드를 추가한다.
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920X1080')
# options.add_argument("disable-gpu")
# options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Max OS X 10_12_6) AppleWebKit/536.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
driver = webdriver.Chrome('chromedriver', chrome_options=options)
동적 페이지와 정적 페이지
정적 페이지란 한 번 생성하면 변하지 않는 페이지이고, 동적 페이지는 한 번 생성된 이후로 사용자의 환경에 따라 페이지를 재구성한다(ex> twitch).
코드 작성 후, 옵션을 추가할 때는 의도했던 test 결과와 옵션 추가 이후의 test 결과를 비교하기(사용자의 상태 반영 여부가 달라져서 옵션 추가 전에는 기본 상태로 출력된다.)
🖊 메일 전송
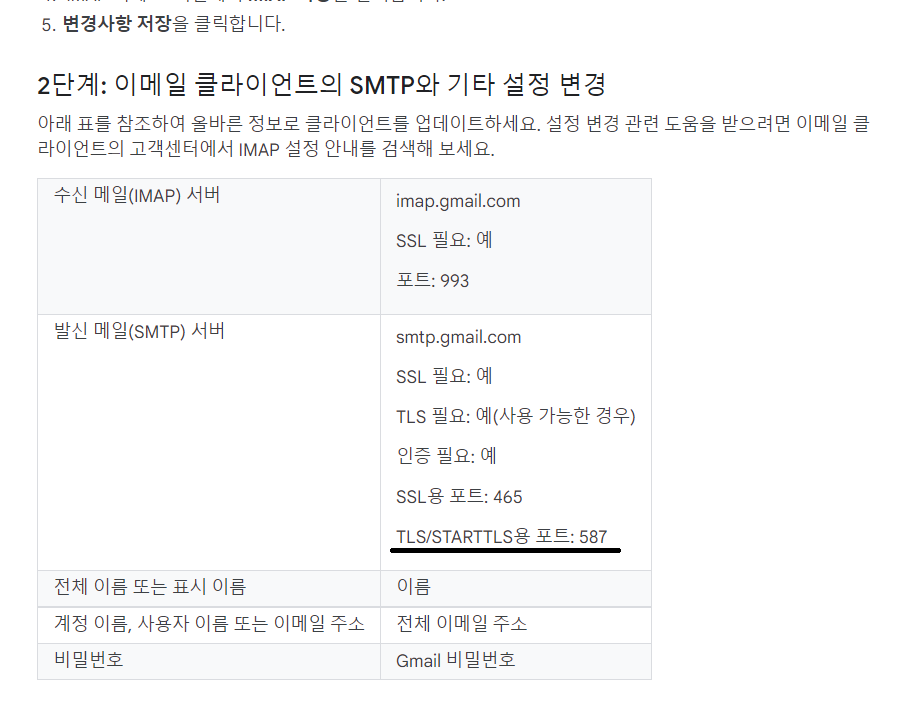
구글 메일 전송과 네이버 메일 전송
*구글과 네이버의 포트, 서버명, 규칙 등 서버 주소 제외 모두 동일함
우리의 목표는 우체국(서버)으로 택배상자를 보내는 것이다.
모듈의 역할
- MIMEText: 편지 본문 내용을 담은 편지지
- MIMEApplication: 첨부한 파일을 담은 선물상자
- MIMEMultipart: 위 두 가지를 모두 포장한 택배상자
이렇게 택배상자가 구성이 되면, 우체국인 smtp 서버로 이동한다.
##### 우체국(smtp 서버)로 이동! #####
s = smtplib.SMTP(smtpName, smtpPort) # 메일 서버 연결(서버이름, 어떤 포트를 연결할지)
s.starttls() # TLS 보안 처리
s.login(sendEmail, password) # 로그인하기
s.sendmail(sendEmail, recvEmail, msg.as_string()) # 메일을 전송하기 위해 문자열로 변환
s.close() # 서버를 연결했으면 반드시 닫아야 한다.*포트란? 컴퓨터의 작동을 구분할 수 있는 연결 구멍
smtplib 서버, mime 객체
smtplib: '우체국'의 역할. 사이트마다 각 smtplib 서버가 존재한다.
mime: 메일을 보낼 때, 메일에 대한 데이터(메세지)를 전송할 때 필요한 객체
🖊 API 분석
오픈 API 분석 방법
- 내 애플리케이션 등록 (client_id, client_secret 이용)
-> API 1일 사용 횟수가 제한되므로, 자신의 클라이언트 id를 넣어 코드를 실행해야 사용 횟수를 서버에서 알 수 있다. - API 레퍼런스 체크
- 요청 URL과 파라미터, 구현 예제를 중심으로 읽을 것
*요청 URL은 공개된 인터넷 주소로 서버에 요청하는 과정을 거친다.
네이버 오픈 API를 호출할 때 HTTP 헤더에 포함해서 전송해야 API를 호출할 수 있다. - 구현 예제 - Java, PHP, Python, Node.js, C# 중에 선택해서 활용
- 구현 예제에 나온 가이드라인 그대로 따라가기
- 코드를 분석해서 실행해보고 분석한 내용 주석 달기
- 레퍼런스 내용과 출력값 비교하여 각각의 Key에 어떤 요소들이 들어 있는지 파악하고 그 형태와 활용된 문법 체크하기
네이버 클로버 얼굴인식 API
CFR(Clova Face Recognition) API란?
이미지 데이터를 입력 받아 얼굴 인식 형태를 json 형태로 변환하고, 요청 URL의 인터넷 주소로 얼굴 인식 코드를 요청한다.
- 이미지에 있는 얼굴을 인식하여 분석 정보를 제공하는 얼굴 API
- 닮은꼴을 알려주는 유명인 얼굴 인식 API
print로 출력한 형태를 보면 { ... }의 중괄호 형태이다.
{"info":{"size":{"width":900,"height":1350},"faceCount":2},"faces":[{"roi":{"x":38,"age":{"value":"42~46","confidence":1.40847E-4},"emotion":{"value":"laugh","confidence":0.77752},2,"y":491,"width":322,"height":322},"landmark":null,"gender":{"value":"female","confidence":0.95276},"age":{"value":"20~24","confidence":0.901693},"emotion":{"value":"sad","confidence":0.975901},"pose":{"value":"left_face","confidence":0.697878}},{"roi":{"x":285,"y":536,"width":194,"height":194},"landmark":null,"gender":{"value":"male","confidence":0.990768},"age":{"value":"42~46","confidence":1.40847E-4},"emotion":{"value":"laugh","confidence":0.77752},"pose":{"value":"part_face","confidence":0.906816}}]}이는 python에서 dictionary 형태에 해당한다. 하지만 이에 대한 type 결과는 'str'이었다. 이는 dictionary와 같은 형태를 가진 json 형태의 응답 데이터이다.
json이란
문자열로 소통하는 웹 통신에서, 데이터 또는 객체 정보를 문자열로 표현하기 위해 만들어진 포맷이다. => 형식적인 문자열 ex>자기소개
하지만, 데이터를 예쁘게 정렬하기 위한 pprint는 문자열에 적용할 수 없다. 따라서 json 데이터를 의미 있는 데이터(dictionary)로 바꾸어야 한다. 이는 원하는 값을 찾고자 할 때 훨씬 편리하게 사용될 수 있다.
<결론> 문자열보다 딕셔너리에서 데이터에 더 쉽고 자유롭게 접근할 수 있다
얼굴 감지 API를 사용하면 얼굴이 여러 개일 경우, 각각 리스트로 치환되어 위치한 좌표값과 얼굴의 정보들을 출력한다. 한 사람만 존재하는 경우는 단독 데이터로만 저장된다.
유명인 얼굴 인식 API를 사용하면 얼굴마다 닮은 유명인의 이름을 출력하고, 그 확률까지 함께 나온다. 그러나, 이는 지금 개발 중에 있는 AI 서비스라 아직은 동일인물도 1%의 확률로 나올 만큼 부정확하지만 앞으로 기대가 되는 기술 중 하나이다.
네이버 파파고 API
Naver Papago의 NMT(Neutral Machine Translation, 인공신경망 기반 기계번역) 기술은 입력 문장을 문장벡터로 변환하는 신경망(encoder)과 문장벡터에서 번역하는 언어의 문장을 생성하는 신경망(decoder)을 대규모 병렬 코퍼스로부터 자동 학습한다. 입력문장의 일부가 아니라 전체 문장 정보의 연관성과 배경을 바탕으로 번역을 수행하여 문장 맥락에 맞는 번역을 하는 것이 특징이다.
기존에는 인공신경망 기반(NMT), 통계 기반(SMT) 2가지가 존재했지만 현재는 인공신경망만 존재한다.
파파고 API는 레퍼런스에 제공된 단축어로 다른 국가의 언어를 자유자재로 변환시킬 수 있다.
BUT
메모장에 적힌 한글을 영어, 중국어 등으로 바꾸려고 할 때 영어를 제외한 나머지 언어는 모두 에러가 발생한다.
그 이유는 온전히 영어로만 이루어진 텍스트 파일은 자동적으로 utf-8 인코딩 방식을 아스키코드로 치환한다. 하지만 다른 언어들은 따로 인코딩 방식을 utf-8로 바꾸어 주어야 한다.
- 메모장을 불러오는 과정에서의 인코딩과 파일을 생성하는 과정에서의 인코딩은 완전히 다른 코드 부분으로 간주. 서로 영향을 주지 않으므로 각각 인코딩 코드를 포함시켜야 한다.
네이버 외에도 Kakao, Google, 기상청, 외국 사이트 등에서 공개 API를 공유한다. 이를 분석해보고 코드의 흐름과 짜임을 더욱 이해하기 바라며..
🖊 Google Drive
Google Drive Assist Program 'gdrive'
구글 드라이브에 있는 파일 목록 확인, 업로드, 다운로드를 다루는 프로그램. github에서 각자에 맞는 운영체제에 따라 실행파일로 저장할 수 있다.
왜 Google Drive API를 사용하지 않고 굳이 ..?
Console, 구글 프로젝트 등록 등 복잡한 절차를 거쳐야 하므로 assist program으로 간단하게 해결하자 !
import os
os.system('gdrive list') #내 구글 계정과 연동하는 작업
os.system('gdrive about') #연동된 계정 확인
os.system('gdrive mkdir "폴더명"') #업로드 전용 폴더 생성 -> 폴더 ID
os.system('gdrive upload --parent "폴더 ID" "파일명"') #생성한 폴더에 원하는 파일 업로드(같은 디렉토리 내에 있어야 함. 없다면 경로를 함께 적어야 함.)특정 폴더를 가리켜 파일을 생성하고자 할 때 개인의 고유 폴더 ID를 이용할 수 있다. 각 파일 역시 ID가 존재해 코드로 드라이브를 제어할 때는 ID로 접근한다.
🖊 Firebase
Firebase(파이어베이스)란?
구글에서 지원하는 플랫폼으로, 서버 인프라 구축 없이도 기본적으로 Database, Storage, Auth, Analytics 등의 서비스 구축 도구를 지원한다.
Admin SDK와 상호작용하여 다양한 작업을 수행할 수 있다.
프로젝트 만들기 -> Realtime Database 생성
프로젝트 생성 때 테스트 모드가 아닌 잠금 모드로 사용 규칙을 지정했으므로, 보안 키가 필요하다.
Firbase 설정 -> 사용자 및 권한 -> 서비스 계정 -> Python -> 새 비공개 키 생성
이 때 발급되는 키가 json 확장파일로 저장되고, 이를 이용해 realtime database에 접근할 수 있다.
Database에 레퍼런스를 생성하고 데이터 읽기
내부 데이터에 접근하려면? URL 뒤에 붙는 key값에 주목!
'이름':'값'의 구조에서 클릭하면 접근 URL에 '/이름'으로 접근된다.
ex> 'tving':'환승연애'의 구조; 'tving'이라는 곳에 '환승연애'라는 값이 들어있다.
다중 값을 입력하여 상하위 계급 분류로 데이터를 생성할 수도 있다.
ex> 게임 계정의 정보 보관 구현
값을 저장하려면 특정 위치까지 가서 값을 넣어야 한다. 특정 위치에 들어갈 때마다 기본 databaseURL에 추가적으로 url 주소가 붙는다.
먼저 처음 위치를 reference라고 할 때,
- 따로 ref의 경로를 지정해주지 않으면 단독 데이터로 입력이 된다. 이는 get함수로 출력 시 특성값을 가져온다.
ref = db.reference()
ref.update({'반원': '고슴도치'})- 경로가 존재하지 않는 것에 대해 데이터를 가져오려고 할 때는 None이 출력된다.
- '/'를 이용하여 경로에 접근한 후 이름과 값을 입력하면 json 형태-{ }를 가져온다.
ref = db.reference('강좌/파이썬')
ref.update({'파이썬 레시피 웹 활용': 'complete'})
ref.update({'파이썬 과식 레시피': 'Proceeding'})- 리스트로 저장 시, 리스트의 인덱스가 이름으로 취급되어 저장한다. index: name ; 이는 get함수에서도 list로 반환된다.
ref = db.reference() # db 위치 지정
ref.update({'수강자': ['구독자A', '구독자B', '구독자C', '구독자D']})
