ᑒ 오류
java.lang.RuntimeException: java.lang.**InterruptedException**: sleep interrupted
at sopt.org.umbba.api.service.scheduler.FCMScheduler.lambda$schedulePushAlarm$4(FCMScheduler.java:81) ~[main/:na]
at org.springframework.scheduling.support.DelegatingErrorHandlingRunnable.run(DelegatingErrorHandlingRunnable.java:54) ~[spring-context-5.3.29.jar:5.3.29]
at org.springframework.scheduling.concurrent.ReschedulingRunnable.run(ReschedulingRunnable.java:95) ~[spring-context-5.3.29.jar:5.3.29]
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515) ~[na:na]
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) ~[na:na]
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304) ~[na:na]
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[na:na]
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[na:na]
at java.base/java.lang.Thread.run(Thread.java:829) ~[na:na]
Caused by: java.lang.InterruptedException: sleep interrupted
at java.base/java.lang.Thread.sleep(Native Method) ~[na:na]
at sopt.org.umbba.api.service.scheduler.FCMScheduler.lambda$schedulePushAlarm$4(FCMScheduler.java:79) ~[main/:na]✐ 문제 원인 및 해결 방안
Keyword: 쓰레드 풀, 동시성 문제, 병렬처리
InterruptedException
스케줄링 작업에서 쓰레드 풀을 미리 10개로 확보해둔 후에, ① 매번 연결 요청이 오가거나 ② 한번에 여러 개의 작업을 병렬처리할 때의 부하를 방지할 수 있었다.
- ① 작업 요청이 들어올 때마다 쓰레드를 생성하고 작업을 할당한다면, 오버헤드가 너무 크다!
- ② API 요청 작업 뒤에서 정해진 시간마다 비동기적으로 처리되고 있었기에, 쓰레드 수를 제한하지 않으면 쓰레드 폭증으로 인한 애플리케이션 성능 저하가 발생할 위험이 컸기 때문이다.
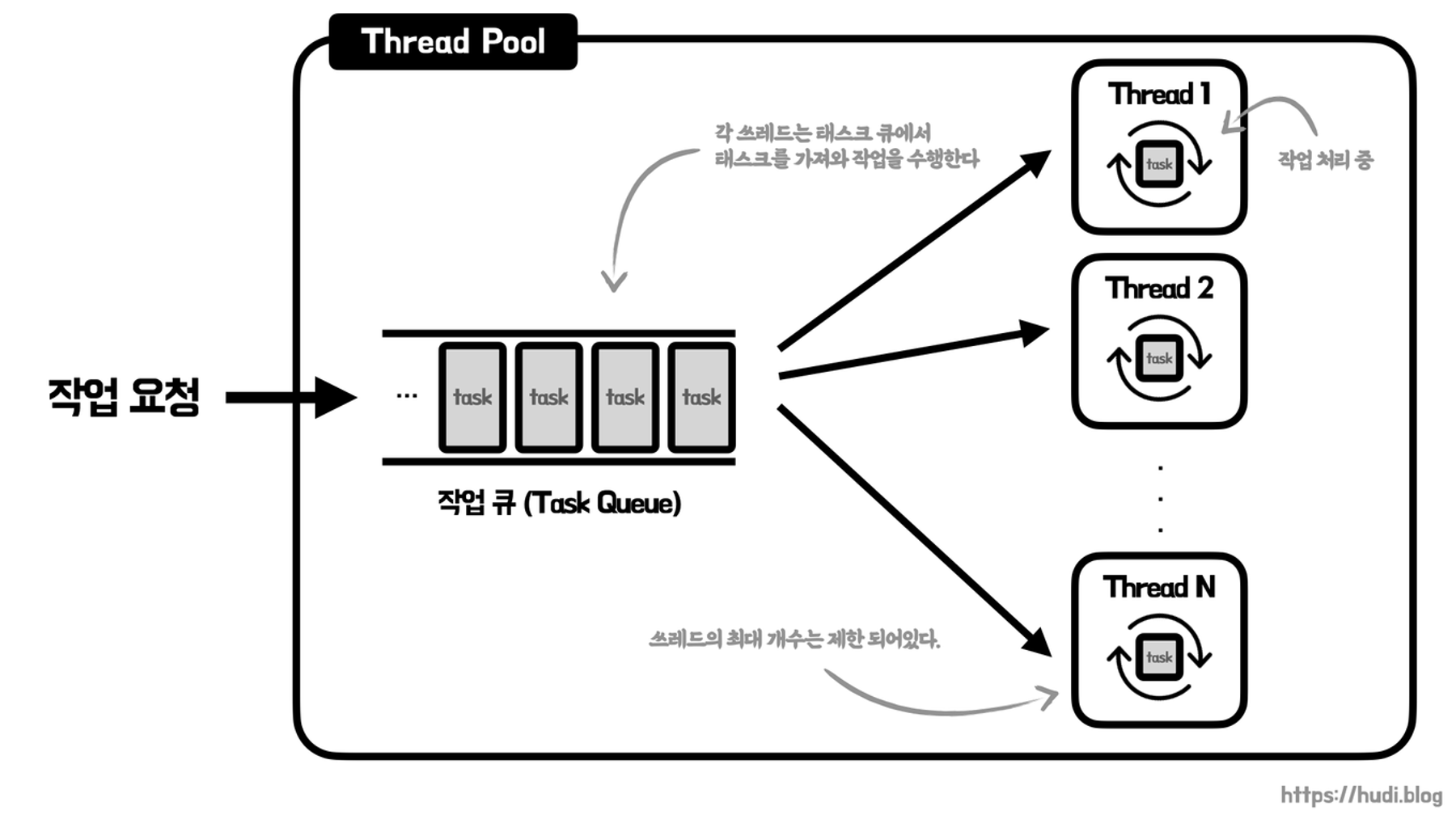
여러 작업들을 병렬로 처리하기 위해 미리 생성된 쓰레드들을 관리하는 기술
DBCP와 유사한 개념으로, 데이터베이스 커넥션 풀을 여러 개 미리 할당해둔 후 쿼리를 날릴 때 연결 과정을 생략한 채로 빠르게 사용이 가능한 것처럼!
쓰레드를 미리 생성하고, 작업 요청이 발생할 때마다 미리 생성된 쓰레드로 해당 작업을 처리하는 방식을 의미한다.
@Bean
public TaskScheduler scheduler() {
scheduler = new ThreadPoolTaskScheduler();
**scheduler.setPoolSize(POOL_SIZE); // 10**
scheduler.setThreadNamePrefix("현재 쓰레드 풀-");
scheduler.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
scheduler.initialize();
return scheduler;
}
// 스케줄러 중지 후 재시작 (초기화)
public static void resetScheduler() {
scheduler.shutdown();
FCMService.clearScheduledTasks();
**scheduler.setPoolSize(POOL_SIZE); // 10**
scheduler.setThreadNamePrefix("현재 쓰레드 풀-");
scheduler.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
scheduler.initialize();
}위 코드는 내가 스케줄러를 사용하기 위해 설정해준 코드인데, 여기서 초기화를 쓴 이유는 새로운 작업을 예약할 때마다 기존에 예약된 모든 작업을 초기화한 후에 처음부터 다시 모든 작업을 예약하는 방식으로 구현했기 떄문이다.
초기화에서 사용한 shutdown()은 현재 쓰레드가 처리 중인 작업과 작업 큐에 대기하고 있는 작업을 모두 마친 뒤에 쓰레드 풀을 종료하는 메서드이다. (아마도 쓰레드 풀을 10으로 초기화해도 계속해서 번호는 증가하는 이유가 작업 큐에 채워지는 순서대로 번호가 붙는 것인 걸로 예상된다 → 서버가 돌아갈 때마다 쓰레드 수가 100, 200까지 계속 증가하는 현상을 볼 수 있었거든요..)
작업을 예약할 때마다 쓰레드 풀에 들어오는 작업들을 작업 큐에 채우고, 쓰레드 별로 할당하여 처리할 것이다. 이때, 쓰레드 간 충돌되거나 한꺼번에 많은 작업을 요청하는 경우를 고려해 실행 중인 일정 기간동안 중지시키는 sleep(1000)을 사용했다.
→ sleep() 메서드를 사용할 때는 반드시 InterruptException에 대한 예외처리를 하도록 되어 있다.
InterruptException은 결국 1초간 sleep()을 수행하다가 입출력이나 특정 로직의 수행이 블로킹 당해서 발생한 것인데, 이는 쓰레드 풀이 꽉 차 있어서 쓰레드를 강제 종료 시키려 한 것 또는 쓰레드 풀 내의 작업을 종료시키다가 쓰레드가 반응하지 않은 경우로 예상해볼 수 있다. 후자로 의심이 가는 부분은 clearScheduledTasks()에서 완전히 모든 작업의 예약을 취소하기 전까지는 실질적으로 초기화의 효력을 제대로 보지 못해 작업이 계속 쌓이고 있을 가능성이 크다.
기본적으로, 쓰레드 풀 내의 작업을 종료시키기 위한 cancel(), shutdownNow() 등의 메서드들은 쓰레드의 인터럽트 메커니즘에 의존하므로 인터럽트에 반응하지 않으면 작업을 종료할 수 없다. 즉, 작업을 종료했는데 중간에 인터럽트를 무시해버린다면 계속해서 작업이 쌓이고 풀이 꽉 차게 되어버리는 것이다.
(문제들이 돌고 도네..)
그래서 쓰레드 풀 작업에 대한 sleep()을 사용할 때 아래와 같이 작성하는 것을 권장한다고 한다.
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 권장
// throw new RuntimeException(e); -> 현재 구현된 코드
}인터럽트를 시도했으면, 끝까지 인터럽트를 수행하도록! → InterruptException이 발생했다는 것은 상태가 interrupt로 인식되는 데 실패했음을 의미하므로 수동으로 상태를 바꿔주고 작업이 종료되도록 해야 한다.
.͙·☽ 참고 자료
