Class
Java란 남의 것을 얼마나 더 잘 가져다 사용할 수 있는가에 중점이 되어 만들어진 언어라는 설명을 하였는데 이 내용에 중점이 되는 것이 Class이다.
다른 사람이 만든 부품을 잘 가져다 사용하기 위해선 잘 분류해두어야 하므로 Java는 package 와 class 라는 분류(classification) 체계가 존재한다.
Class는 각종 method와 변수 등을 담는 분류이므로 Class의 이름은 어떤 변수와 함수의 종류를 대변하는이름이어야 한다.
예를들어 아래와 같은 method 들의 이름이 있다고 했을 때 class 명을 만들어보자
- 메소드명: run(), jump(), walk(), swim() → 클래스 명 : Exercise
- 메소드명: plus(), minus(), multiple(), devide() → 클래스 명 : Calculator
- 메소드명: acceleration(), break(), drift() → 클래스 명 : AutomobileFunction
이렇게 class 명을 보았을 때 어떠한 기능을 담고 있는지를 유추할 수 있도록 만들어야 한다.
그렇다면 package 는 무엇일까?
package 의 아이콘을 잘 보면 네모 박스에 끈이 묶어져 있는 선물상자 모양을 하고 있다.
즉package는 class를 담고 있는 상자인 것이다.
Class의 4가지 특징
OOP의 4가지 특징에는 캡슐화, 상속, 추상화, 다형성이 있다.
이 4가지 특징에 대해서는 다음 글에서 계속 다룰 예정이다!
- 캡슐화 (Encapsulation)
- 상속 (Inheritance)
- 추상화 (Abstractionism)
- 다형성 (Polymorphism)
Class 선언 규칙
-
Java 파일은 최소 1개 이상의 class를 가지고 있어야 한다. (class는 파일이 아닌 분류의 영역이기 때문에 여러개도 만들 수 있다 권장 x)
-
class는 하나의 자료 형(데이터 타입)이 될 수 있다. (String, Integer, Double ···)
-
class 안에 class를 선언 할 수도 있다. (권장 x)
-
class를 만드는 몇 가지 규칙이 있다.
- 클래스의 첫 글자는 대문자로 한다. (파스칼 표기법)
$나_외의 특수문자는 사용할 수 없다.- 클래스와 자바파일명은 서로 동일해야 한다. (지금은 시스템이 자동으로 맞춰준다.)
표기법은 여러가지가 있는데 그 중 대표적인 몇 가지는 파스칼, 카멜, 스네이크 표기법이다.
파스칼 표기법 : class 이름을 작성할 때 주로 사용하며, 모든 단어의 첫 번째 문자를 대문자 나머지를 소문자로 표기 (예 : Blackcolor)
카멜 표기법 : 변수, 메소드 이름을 작성할 때 주로 사용하며, 의미있는 단어의 첫 글자를 대문자료 표기 (예 : blackColor)
스네이크 표기법 : 의미가 있는 단어를 _로 구분해 사용하며, 대소문자가 구분되지 않는 언어에서 사용 (예 : black_color)
class의 객체(instance)화
class의 특정 내용을 사용하기 위해서는 객체(instance)화가 필요하다.
객체화 란 static 영역에 있는 원본 class를 복사해 와서 사용하는 과정을 말하며, 호출, 객체화, 인스턴스화 라고도 부른다.
원본 클래스를 복사해서 사용하는 이유는 원본은 중요한 내용을 담고 있기 때문에 사용하는 사람마다 수정하거나 데이터가 변형되는 일을 방지하기 위해 복사본을 만들어 사용해주어야 한다.
class가 존재하는 구조는 T형 메모리 구조로 STATIC(원본), HEAP(복사본), STACK 영역이 있다.

원본을 복사해 와서 객체화 시킬 경우 데이터 타입은 객체의 원본 클래스가 된다.
Exsample sample = new Exsmple() // 클래스(데이터 타입) 변수 = new 클래스() (생성자)복사를해오기 때문에 동일한 클래스를 가져와 객체를 2개 만들경우 그 2개는 같은 객체가 아닌 다른 객체가 되므로 서로에게 영향을 주지 않는다.
API
API(Application Programming Interface) : 응용 프로그램에서 사용할 수 있도록, 운영체제나 프로그래밍 언어가 제공하는 기능을 제어(사용)할 수 있도록 만든 인터페이스 (메소드라고 부른다.)
-> ex) toString()
Interface : 실제로 하면 복잡한 일을 간단하게 할 수 있도록 만들어 놓은 어떤 장치 (프로그램에선 방법) 그래서 function이 아닌 method로 표현을 해주는 것이다.
만약 어떤 어플리케이션을 실행할 때 파일의 소스코드를 찾아 열지 않고 터치를 통해 어플을 열 수 있도록 인터페이스를 제공하는 것이고,
전등을 키려고 할 때 전구에 전선을 연결하는 것이 아닌 스위치를 통해 전등을 켜는 즉 복잡한 일을 이렇게 간단하게 할 수 있도록 만든 장치를 인터페이스라고 한다.
Java 에서 API는 어떤 일을 수행하기 위해 사용하는 도구나 방법(method)이기 때문에 추가로 사용법도 포함하고 있다.
설명서는 직접 만들 수 있는데 방법은 다음과 같다.
/**
* 이 메서드는 정수형태의 두개 인자값을 더해 정수 형태로 반환합니다.
* @param a 정수 형태의 인자값
* @param b 정수 형태의 인자값
* @return a 와 b를 더한 정수 값
*/
int plus(int a, int b) {
return a + b;
}이렇게 생성한 설명서는 메소드 호출 시 확인할 수 있다.
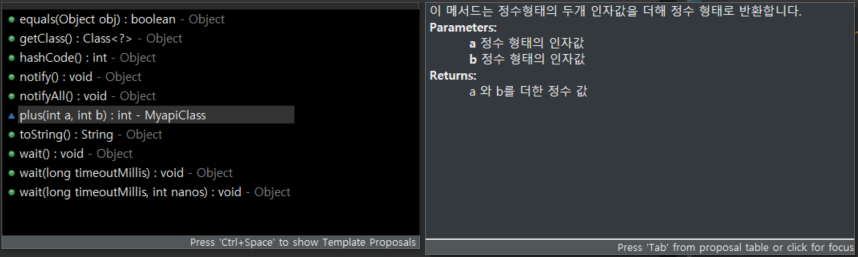
만약 회사에서 상사가 API를 가져오라고 한다면 그건 개발문서를 가져오라는 뜻으로 이해하면 된다! (API는 설명서를 포함하니까!)
위에서 객체화는 class를 복사하는 것과 같으며 객체화를 하면 객체 내의 모든 것 (일부만도 사용 가능)을 사용할 수 있다고 했다.
이렇게 객체를 사용하는 것, 그리고 그 설명서를 API라고 한다.
class 의 member
class 안에는 여러가지들이 들어 있는데, 그것들을 우리는 class member이라고 부른다.
즉 같은 클래스에 묶여 있으면 member이다.
public class Ex01{ // 클래스
int fildName; // 필드 == 클래스 안에 있는 변수 (멤버필드, 멤버변수, 클래스 변수)
public Ex01(){ // 생성자 (생략할 수 있다.) - 객체화를 해주는 부분 *객체를 생성하자 마자 실행되는 부분
}
public void methodName(){ // 메소드
}필드는 변수와 비슷하게 생겼지만 변수라고 부르지는 않는다.
메소드 안에 선언된 변수는 메소드 내에서만 실행되고, 생성자와 메소드가 종료되면 자동 소멸되는데,
필드는 생성자와 함께 메소드 전체에 사용되며 객체가 소멸하지 않는 한 객체와 함께 존재한다.
생성자(constructor)
생성자(constructor)는 class를 객체화 해주며, 생략이 가능하다.
우리가 풍경화를 그릴 때 당연히 존재하는 공기는 그리지 않는 것처럼 프로그램도 너무나 당연하게 있어야 하는 것들은 따로 작성하지 않아도 인정 해주기 때문이다.
객체화를 하는 과정을 자세히 살펴보면 이미 생성자가 사용 되었다는 것을 알 수 있다.
Exsample sample = new Exsample(); // new Exsample() : 기본 생성자즉 class가 instance화 되면서 가장 먼저 실행된다고도 볼 수 있다.
그 과정은 객체화 요청 → 생성자 호출 → 객체화 로 진행된다.
그렇다면 생성자를 우리를 어떨 때 사용해야 할까?
생성자는 객체화 될 때 초기화 하는 수단으로 활용이 된다.
이때 초기화는 0을 만드는 리셋이 아니고, 최초의 값을 준다는 의미이다.
예를들어 강아지를 입양한다면 강아지의 이름을 처음에 지어주는 것을 초기화 하며 최초의 값을 준다고 생각하면 된다.
public class Puppy{
public String name;
public Puppy(String name){
this.name = nema;
}
}이렇게 Puppy class에 생성자를 만들어주고 객체화를 하게 되면 기본 생성자 안에 name를 적어주며 초기화를 진행하면 된다.
Puppy p = new Puppy("멍멍이");생성자는 클래스와 동일한 이름으로 만들기 때문에 1개만 만들 수 있다.
그런데 만약 이름만 넣어주는 경우와 이름과 나이를 넣어주는 경우 그리고 아무것도 넣어주지 않는 등 여러개의 경우의 수를 지정해주어야 한다면 어떻게 해야할까..?
class를 3개를 만들어야 할까?
이럴때 사용하는 것이 바로 오버로드(overload)이다.
오버로드(과적)
같은 이름으로 여러 개의 생성자를 만드는 것을 생성자 오버로드 라고 하며, 매개변수의 개수가 형태가 달라야 한다.
기본적으로 Java 에서는 같은 이름은 하나만 만들 수 있지만 경우에 따라서 동일한 이름으로 여러개를 만들 수 있도록 해주는 것이 오버로드(overload)이다.
(원래는 하나만 가능하지만 2, 3개 이상 만들 수 있기 때문에 과적이라고 한다.)
오버로드는 이름은 동일하나 매개변오버로드는 이름은 동일하나 매개변수는 달라야 한다.
이름이 달라도 타입과 갯수가 같으면 동일하게 만들 수 없다.
즉 생성자 오버로드를 다양한 객체화를 위해 만들어 진 것이다.
메소드 오버로딩(method overloading)
생성자가 아닌 메소드도 오버로딩하여 같은 이름의 매개변수가 다른 여러개의 메소드를 만들 수 있다.
그렇다면 메소드는 왜 오버로딩 해야할까?
만약에 우리가 더하기를 해주는 plus() 메소드를 만든다고 했을 때 우리는 문자와 문자를 더할 수도 있고, 정수와 소수를 더할 수도 있다.
이렇게 여러 경우의 수를 모두 계산해 메소드를 만든다면 이름을 생성하는 것부터 어려움이 생길것이다.. (그리고 누군가에게 설명하기도 누군가가 사용하기도 어렵다!)
그렇기 때문에 plus() 라는 이름의 메소드를 하나 만들고 오버로딩 하여 생성자도 사용자도 편리하게(편하게) 이용할 수 있도록 하기 위해 메소드 오버로딩을 해야하는 것이다.
static (원본 영역)
우리가 class를 instance화 하여 사용하는 이유는 원본이 훼손되지 않도록 하기 위해서 라고 배웠다.
하지만 굉장히 중요한 사안은 원본을 변형해야할 때도 있다.
만약 원본을 변형하지 않으면 해당 원본을 복사한 모든 복사본을 하나하나 수정해야 하기 때문에 원본 파일에 데이터를 수정하여 다른 복사본들이 원본을 확인할 수 있도록 하는 것이다.
static 에는 공통적으로 봐야할 때 사용되며 Main() 메소드는 객체화가 필요 없는 static 이다.
static은 객체화를 하지 않고, 원본을 사용해야 하며 사용 방법은 아래와 같다.
public class Inner{
static String str = "hello"; // static 멤버 생성
}
System.out.println(Inner.str); // 원본 이름으로 호출 (직접 접근)
하지만 객체화를 해서 사용할 수도 있는데, 그러한 이유는 사람들이 많이 틀리기 때문에 java에서 허용을 해주기 때문이다.
사용할 수 있기는 하지만 객체화해서 사용할 경우 바로 원본으로 찾아가는 것이 아니라 객체에서 원본으로 이동한 후 원본에서 해당 영역에 접근을 하는 방식으로 효율성이 떨어진다.
static이 아닌 복사본 영역을 건드리게 된다면 생성된 객체별로 다른 값을 저장할 수 있지만 static은 값을 변경하면 다른 복사본에서도 변경된 값이 출력된다. (원본은 건드리는 것이기 때문에)
static 영역에는 클래스 원본이 저장되고 힙 영역에는 클래스의 복사본(instance)가 저장된다.
또한, 같은 클래스에 있다고 하더라도 영역{ }이 다르면 별도로 불러줘야 한다.
final
final은 한번 지정되면 프로그램 종료 시 까지 변경이 불가능하며, 생성자에서만 초기화가 가능하다.
그렇다면 static final 은 어떻게 해야하는가?
(static 은 생성자에서 초기화가 불가능 한데...!!)
이런 값은 "상수" 라고 한다.
상수란 무엇인가?
예를들어 '지구는 둥글다' 처럼 절대 바꿀 수 없는 값을 상수라고 하며 모두 대문자로 표기한다.
클래스 다이어그램 (Class Diagram) : 클래스간 관계를 그린 그림
public : +를 앞에 붙여 표시
생성자 : <<create>> 를 뒤에 작성
static : ____________ 밑줄로 표시
final : {readOnly} 작성
static final : 대문자 표기 + ____________ 밑줄 + {readOnly}
상수만 있는 클래스 : <<utility>> 를 class명 옆에 표기
