
Week 1 - C part 2
This course is intended for students who have never coded before. The post may be elaborate due to the reason.
🧩 What I Should Learn?
- Create a mini block program
- Comments
- Operator and Types (short)
- Data Types
- Operators
- Conditional Statements
- Loops
- Command Line
- Magic Number
🎯 What I learned today
Mario
Create a block
Imagine we want to emulate the blocks in the game Super Mario Brothers.

There are four question mark blocks in the sky, and we are trying to change those blocks into a textual version.
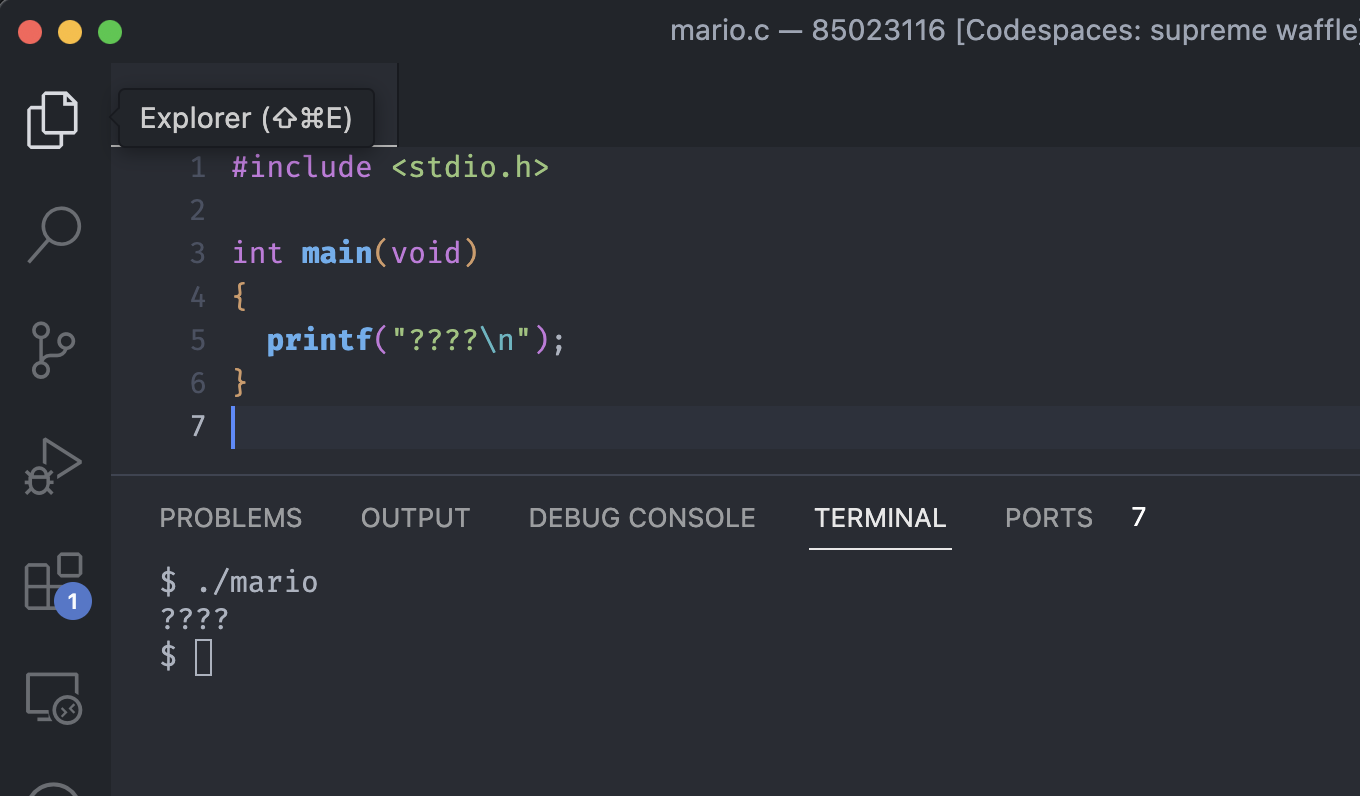
Probably the picture above is the simplest way to implement those four horizontal blocks using pure text.
But we've seen that there are better ways to do this, and if we want to generalize this code to be five, six or sixty question marks, the loop is always the answer for not repeating ourselves.
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 4; i++)
{
printf("?");
}
printf("\n");
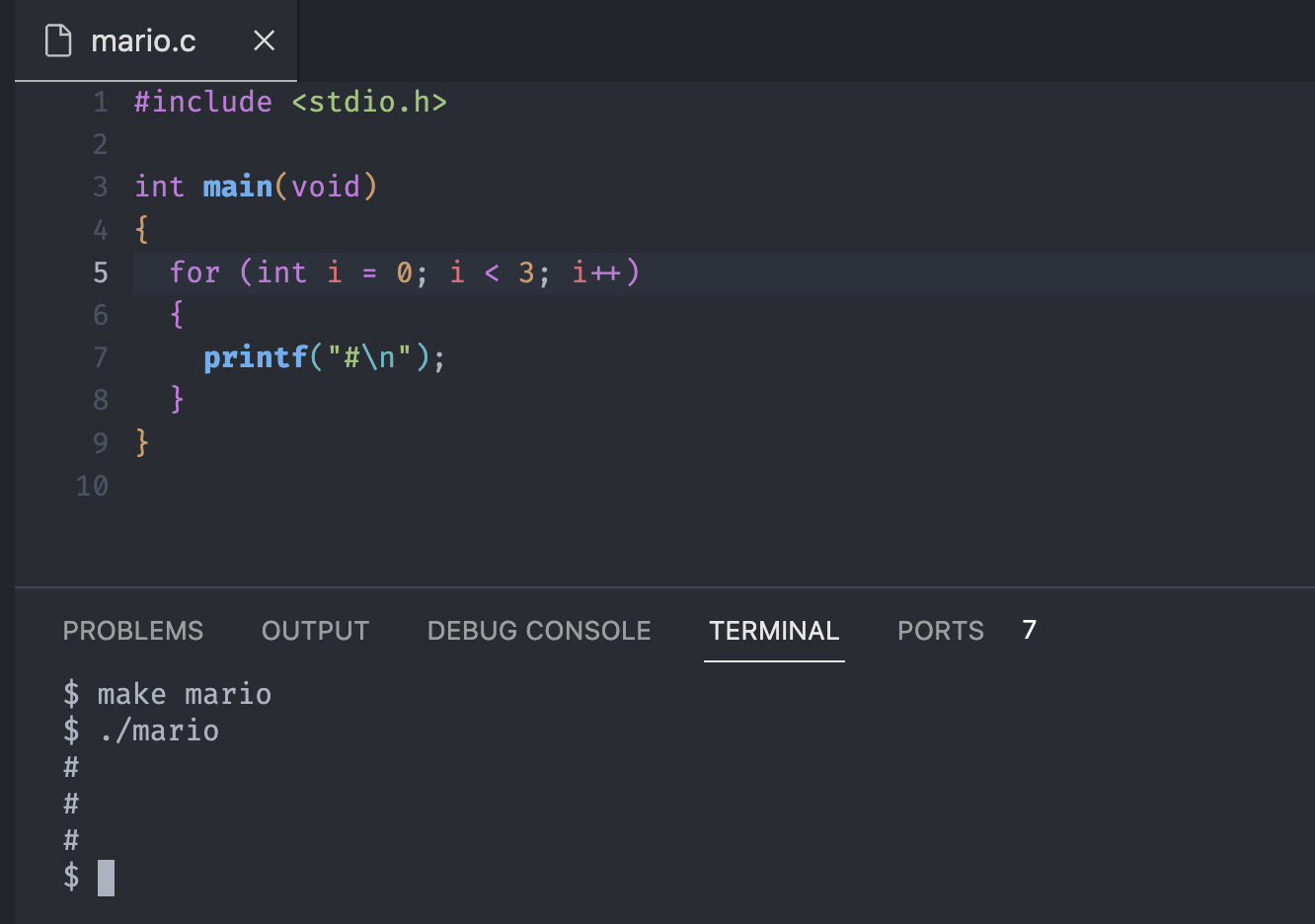
}Notice we placed the printf("\n"); after the loop, because when we place it inside, it creates a vertical block.

What if we want to do some other scene from Mario such as the picture above?
We can modify our code like below to make the vertical obstacles.
Advanced blocks
To escalate things one level further, when we're in the underground version of Mario, there's lot of obstructions like the one picture below.

That is not a single line, but the grids or bricks or combined three-by-three group of blocks.
We can think logically that we want to print three rows of bricks and three columns of bricks together. Take this problem into a smalle pieces, we can start from the loop.
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 3; i++)
{
}
}The loop above will do something three times, even though there is nothing inside yet.
Then, if we want to print out a row of three bricks in the same line, that's similar to the four question marks in the sky.
To compose one into the other, we can change our code like this:
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
printf("#");
}
printf("\n");
}
}Notice we used the different integer i and j for the loop, that's because if we use the same name, it could cause a collision or trouble.
Combine one loop to the other, the inner j loop will prints out the vertical row, and the outer i loop will prints out the new line, and make three columns.
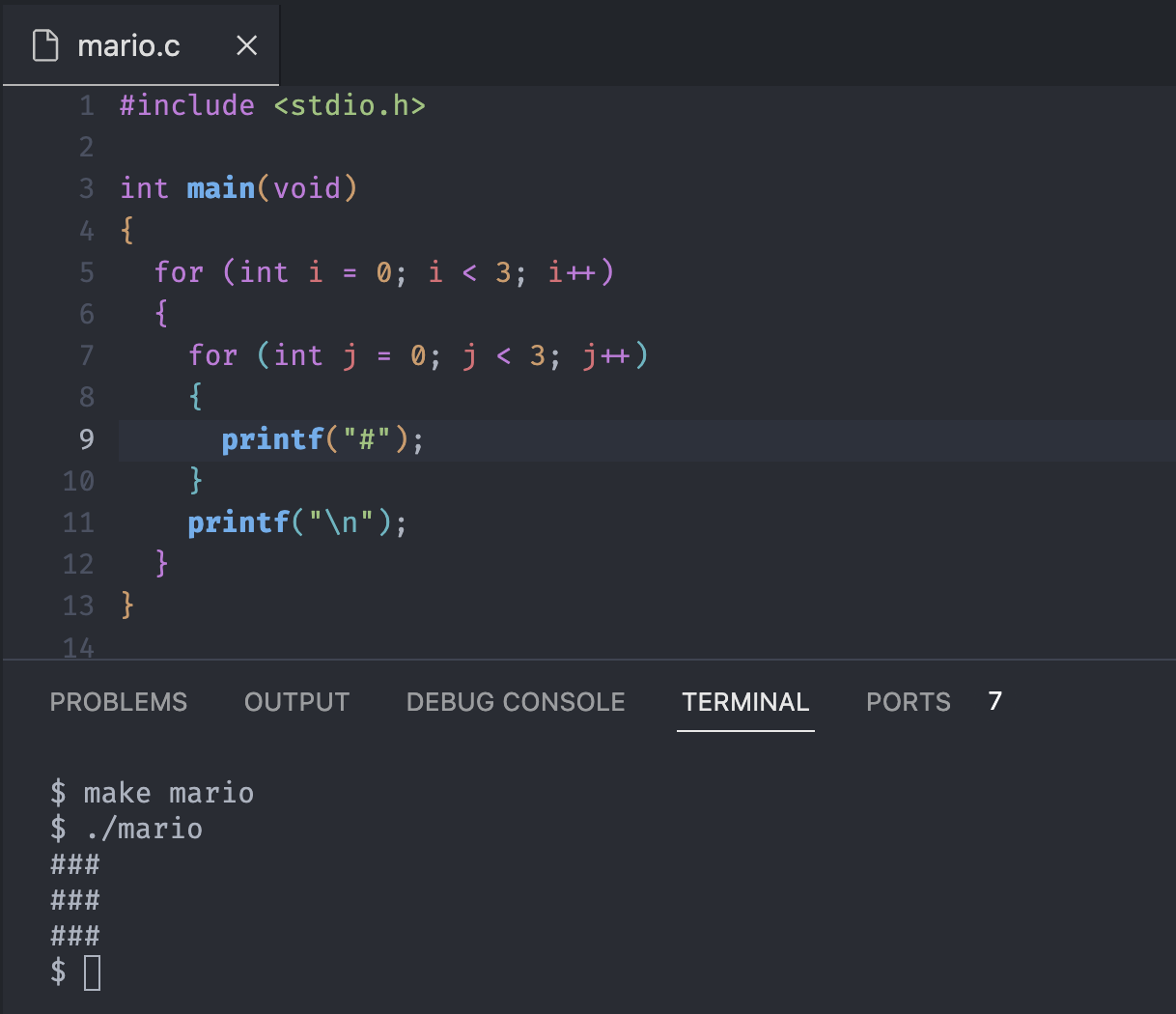
But this is not the best design, because suppose if we want to change the size of grid and the grid is always square, we have to manually change the numbers and eventually will make some mistake.
#include <stdio.h>
int main(void)
{
int n = 3;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}We can solve the issue above by initialize n for numbers. The above code has better design, because there's a lower probability of mistakes.
But technically we can still screw up somehow, by accidentally changing the n value. To prevent this error, we can declare n to be a constant using the keyword const.
#include <stdio.h>
int main(void)
{
const int n = 3; // Chaged here
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}That's the way of programming more defensively, and it's a good practice. The defensive programming makes our code better designed because it's less vulnerable to mistakes by us, collegues or anyone else using the code.
Ask user
We can make our code to prompt the user for the size of the grid.
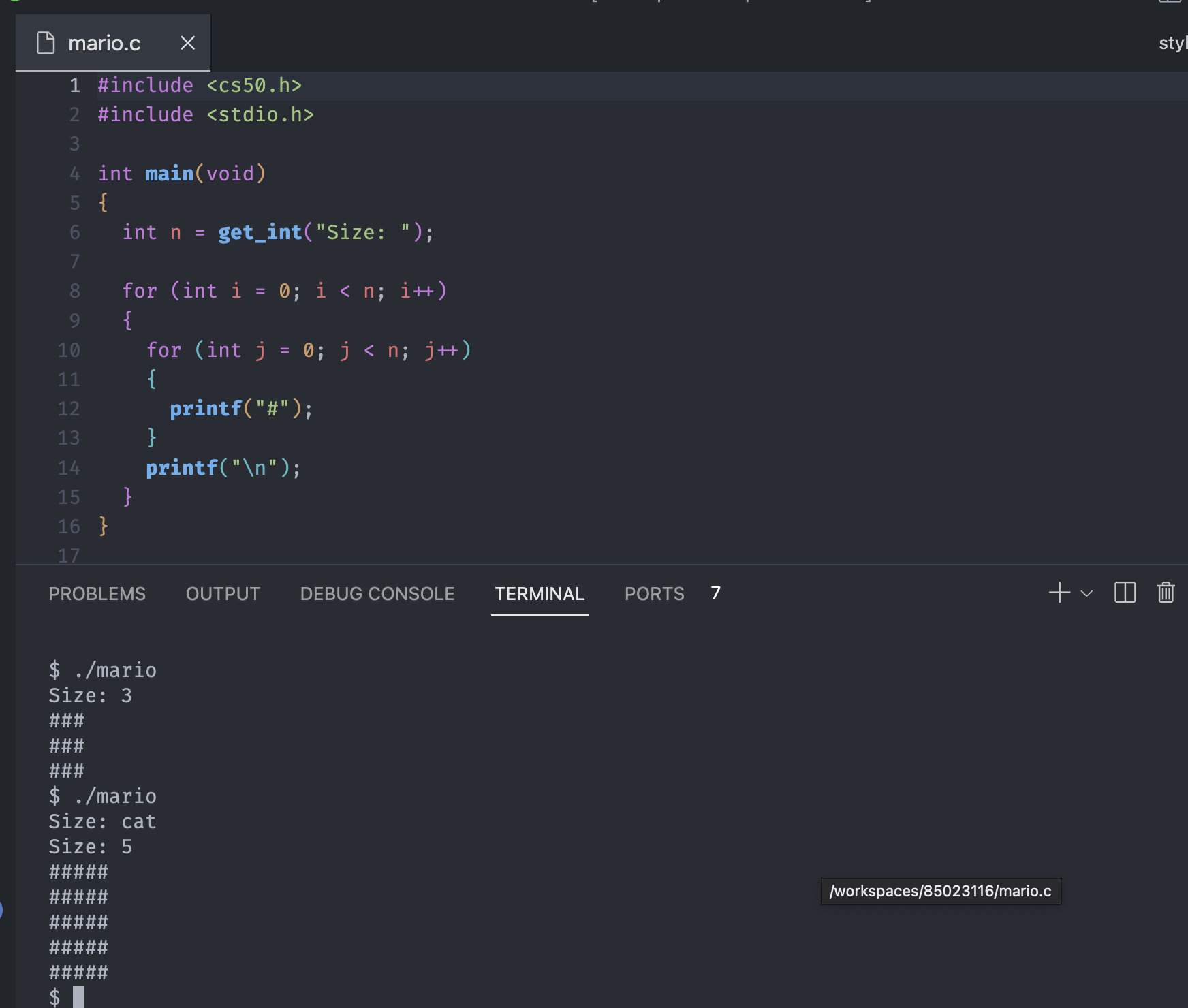
Don't forget to include the cs50 library to use get_int function.
Notice the get_int function deals with erroneous input, if the user type something like a string cat.
But we only desinged a function to get an integer, and the user input might be negative, positive, zero or some combination thereof.
It's clear that if we allow user to type the negative 1 for the size of the grid, so let's force the user to give the program a positive value.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int n = get_int("Size: ");
while (n < 1)
{
n = get_int("Size: ");
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}The code here is the better design, because it's only two requests for the information. But we are using two identical lines, which is not ideal.
That is the best time to introduce the third loop, a do-while loop.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}Do-while loop is in C, and other languages like Python doesn't have it. Even though the code above seems a little weird, that we have to decalre variable at top and then check it below, it is the cleanest way to achieve the logic so far.
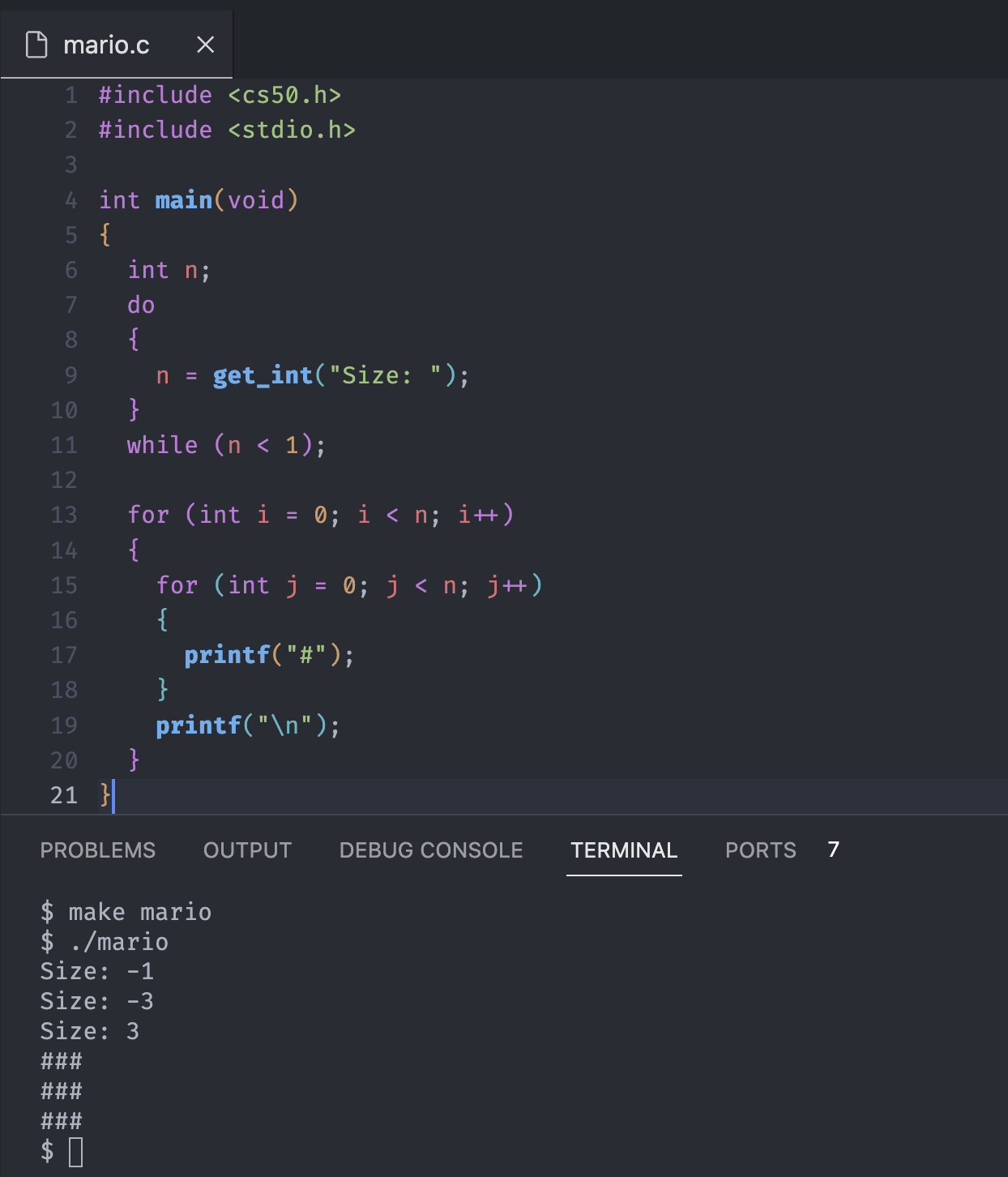
A general piece of advice within programming is that we should never fully trust the user. They will likely misbehave, typing incorrect values where they should not.
We can protect our program from bad behavior by checking to make sure the user's input satisfies our needs (defensive programming).
Comments
Leave a note
In Scratch, there was ability to leava a yellow sticky notes that we can add citations or explanations.
There's a couple of ways to write comments in C, and in general comments are for ourselves or for colleagues as to what the shared code is doing and why or how.
For instance, we can leave our fisrt note as follows:
int main(void)
{
// Get size of grid
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
...
}Notice the comments begin with a //, involve placing // into the code followed by a comment. It's just an explanatory remark in terse English that generally explains the next chunk of code.
int main(void)
{
// Get size of grid
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
// Print grid of bricks
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}There is another comment to ourself that makes the code more understandable by adding some English explanation thereof.
Comments are the fundamental parts of a computer program to ourselves and especially ohters when we collaborating with our code.
Typically each comment is a few words or more, providing the reader an opportunity to understand what is happening in a special block of code. Further, the comments are good reminder for us later when we need to revise our code.
Abstraction
Abstract existing blocks
Suppose we don't know where to begin with our code, but we have a instruction or comments for the program.
int main(void)
{
// Get size of grid
// Print grid of bricks
}Comments are good way to getting started because it can be an approximation of pseudocode. And the code above really just represents how our program or function should work.
int main(void)
{
// Get size of grid
int n = get_size();
// Print grid of bricks
print_grid();
}
int get_size(void)
{
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
return n;
}
void print_grid(int size)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
printf("#");
}
printf("\n");
}
}
First function get_int()
We created a function that get the size what user wants, and doesn't take any input but returns an integer. This is the syntax of C, and we will learn that in another time.
Another term here is a return, which means the function will hand back to any funtion that uses that function the value in question.
Notice how we use this function in main, just like with the get_int() from the CS50 library, calling the function. Nothing in the parentheses, but we are using assignment operator = to copy the return value into variable n.
Second function print_grid()
The second function just needs to print, which we call it has a side-effect.
So we put void to say it has no return value, but it takes an argument (int size). An argument is an input, and the syntax for this in C is to name the type of the input and the name of the variable.
The name can be anything, as we know we are going to use the n in here, so it could be (int n), but we will use size to distinct for the moment.
The content of this function is the same as the previous logic except we use size instead of n. Additionally, we can arbitrarily move the codes to the bottom like we did in Scratch to clean up the work space.
Now we have abstractions, the puzzle pices like red blocks are exist in the workspace. However, C is a little naive, it reads top to bottom and consider the function doesn't exist.
We can move all the created functions at the top and place the main function at the bottom, but that doesn't look great and take longer to find the main function.
Since it's not the clear solution, what solution we can imply to this?
int get_size(void);
void print_grid(int size);
int main(void)
{
// Get size of grid
int n = get_size();
// Print grid of bricks
print_grid();
}
...Copy and paste the first line of each function, and place at the top. With this syntax, we can tease the compiler by giving it just enough of a hint at the top of the file.
That's like telling the compiler that these top functions don't exist until down later, but top few lines are the hint that they will exist.
By doing so, we can convince the compiler to trust our program and those two functions still be in lower in the file below the main.
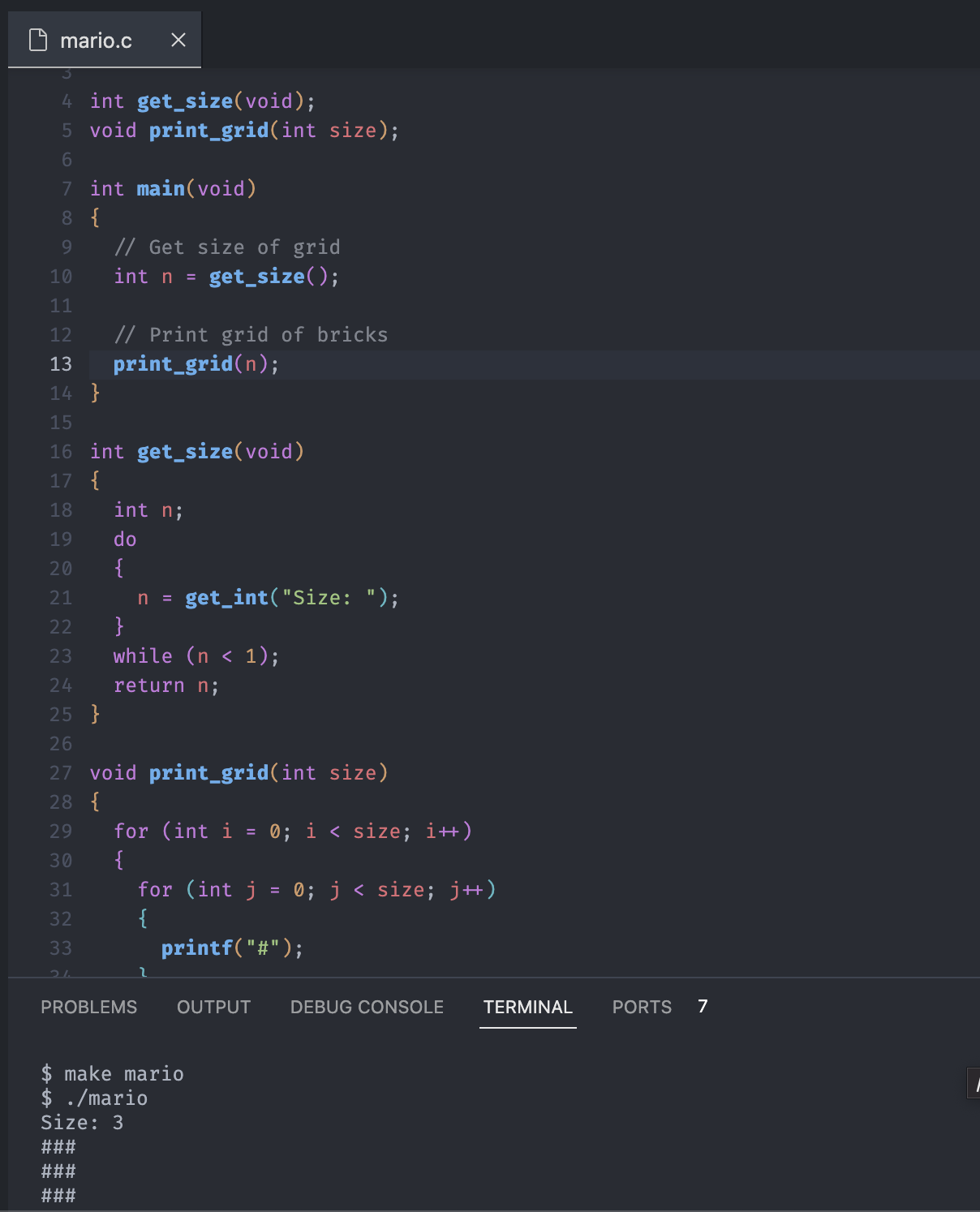
To sum up, we have three functions. The first function is the main, that calls two functions. The second function called get_size includes the size logic that we keep used. The third function called print_grid has the side-effect, which prints the grid.
Notice this solution is better designed, because the main function has only two lines of code without the comments. Because we abstracted away or factored out the essential problems within our program, our main function can be remain short.
Operators and Types(short)
Mathematical Operators
C indeed supports numerous mathematical operators, via we can do four arithmatic operations including calculating the remainder.
+for addition and-for subtraction*for multiplication and/for division%for remainder
Create own calculator
Let's create our own calculator to practice the operators above.
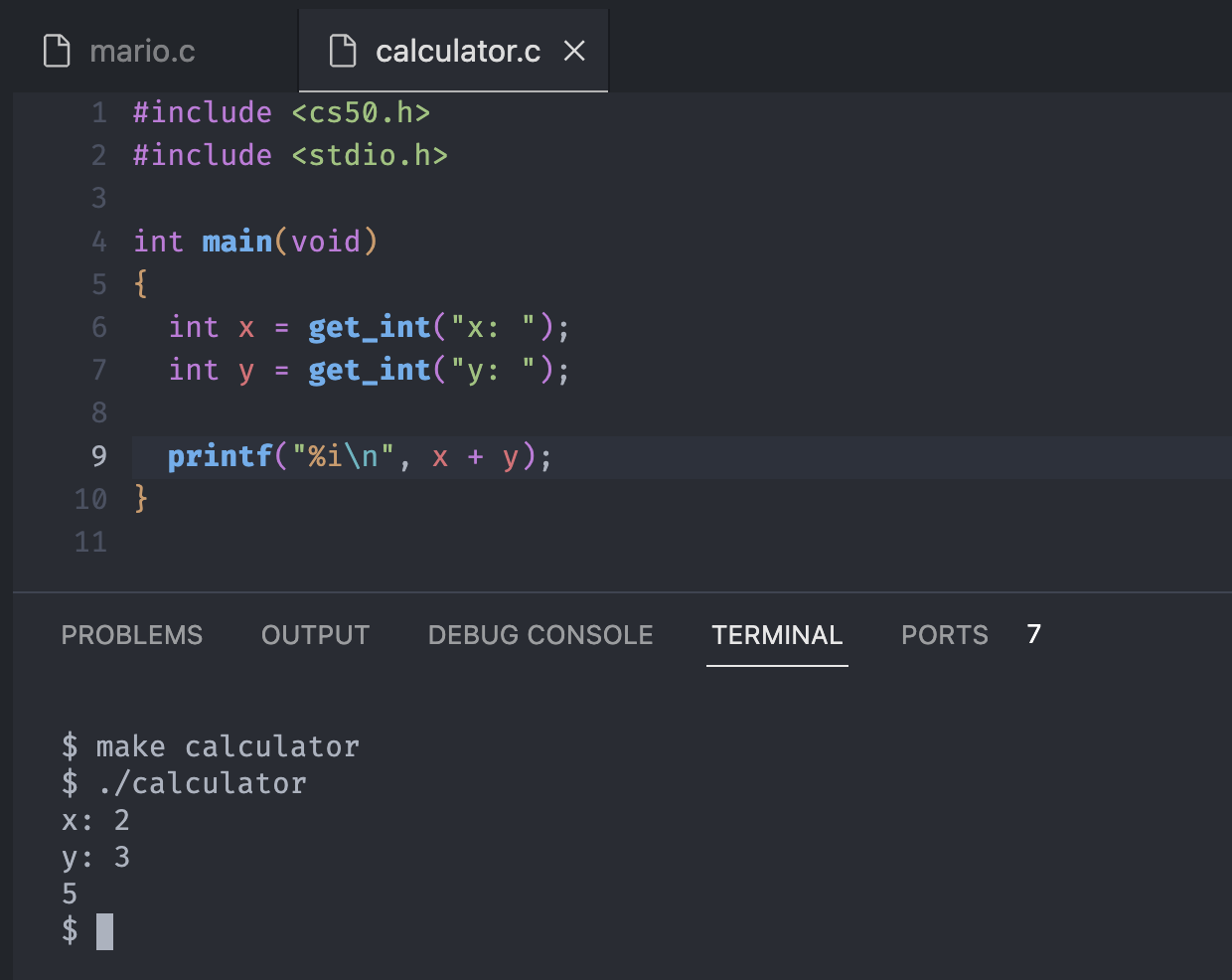
Notice we implemented simple addtion calculator, and works as expected. However, sometimes we are going to bump up against the limitations.
Try add 2 billion for x and 2 billion for y in calculator.
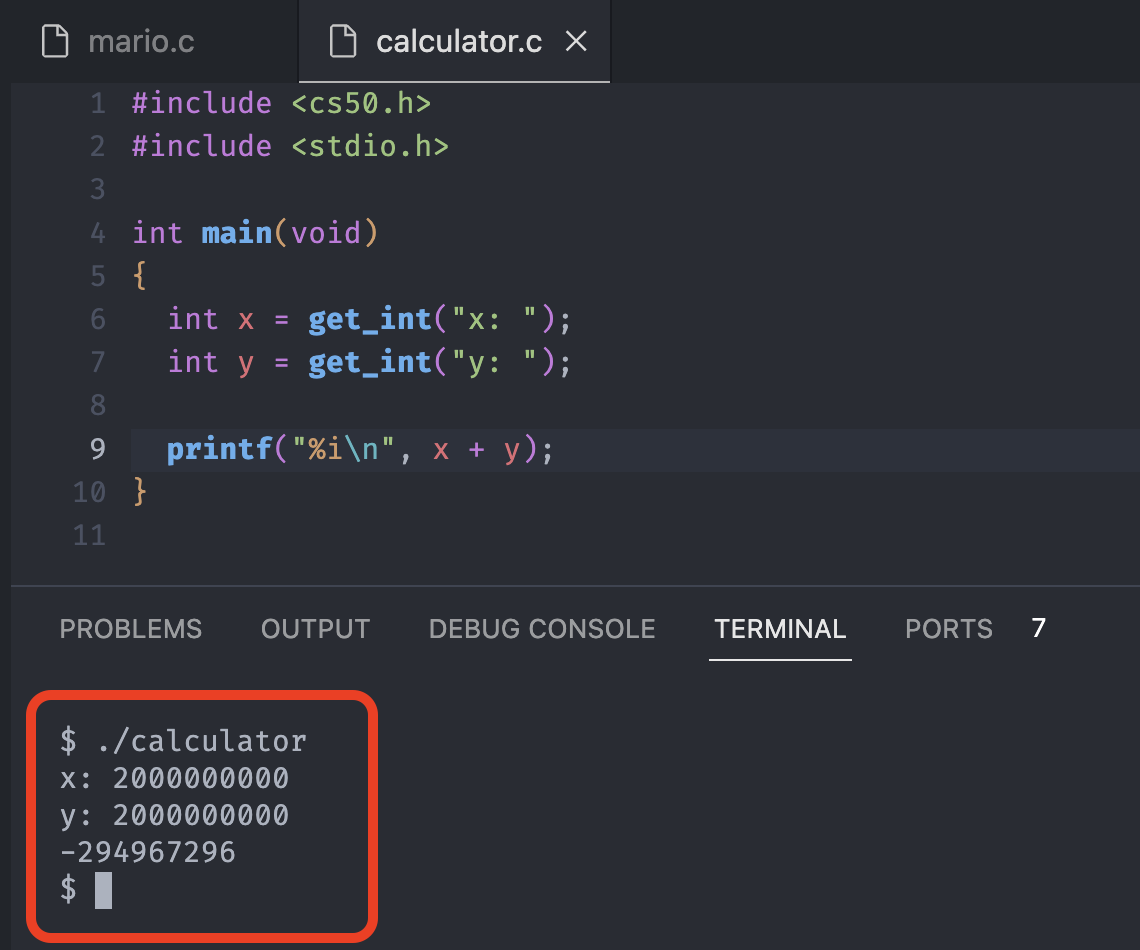
Clearly, that is not the answer nor what we expected. Why might this actually be?
Integer Overflow
Turns out each computer has memory or RAM the random access memory, and we have only have a finite amount of memory inside our computers.
No matter how high we want to count, there will be a limitation we can count because we only have a finite amout of memory, in other words, we don't have an infinite numbers of zeros and ones.
Computers typically use as many as 32 bits in zeros or ones to represent an integer. For instance, the smallest number we can represent using 32 bits would be zero. And the biggest number we can represent by changing all of 32 zeros to ones idealy give us a number that roughly equals to 4 biliion. (2^32 == 4294967296)
However, in general, we need to represent a negative numbers. Hence, we can't count from 0 to 4 billion. Instead we've got to split the difference and allocate half of those patterns of zeros and ones to negative and postive numbers.
In fact, if we using 32 bits the highest most computers could count in a program like C using an int would be roughly two billiion. (2147483648 == 2^32 / 2).
But we have the flip side of that we could also now using different patterns of bits to represent negative numbers as low as negative two billion. (-2147483648)
The implication is that if we only have a finite number of bits and can only count so high, at some point, we are going to run out of bits.
We call this encounter as integer overflow. Where we want to use more bits then available, as a result, we overflow the available space.
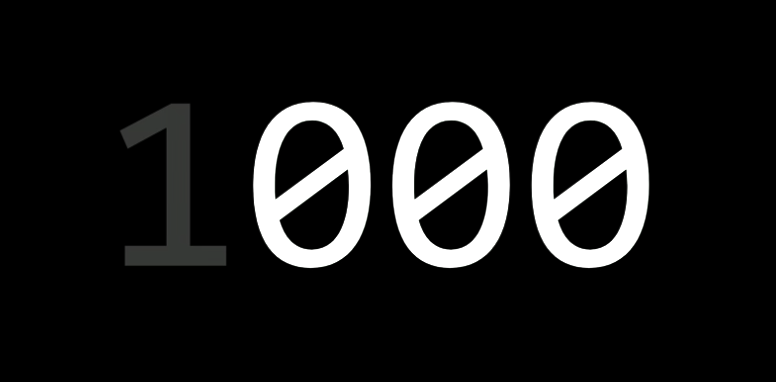
Suppose we have a computer that uses 3 bits, as soon as we get to 7, the next number in computer is going to be 0 or worse might be a negative value. There is no room to store the fourth bit, so the picture above grayed out the 1 and the integer is overflowed.
Types
To address the problems above, we can use a type long, the longer integers that have more bits available to them.
We can now fix our previous calculator to this:
Recall the
format codewe learned. Same as the%i or %s, there are many types of format code for each data types.
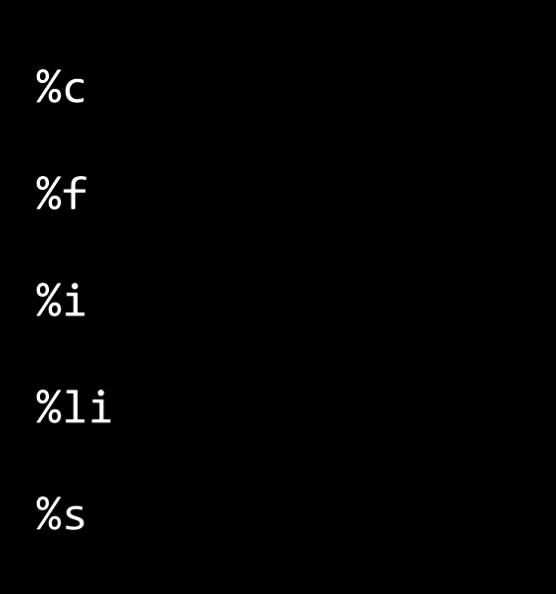
Notice now the error disappear, because the long or long integer uses 64 bits and we have enough spare bits.
In fact, a long can count up to roughly 9 quintillion (quintillion == 10^18), but it too is ultimately going to be finite and numbers can be overflow.
Truncation
There's another problem we might run into when we dealing with math involving floating point values is what's called truncation.
Let's change and recompile the calculator program function to division and do the following:
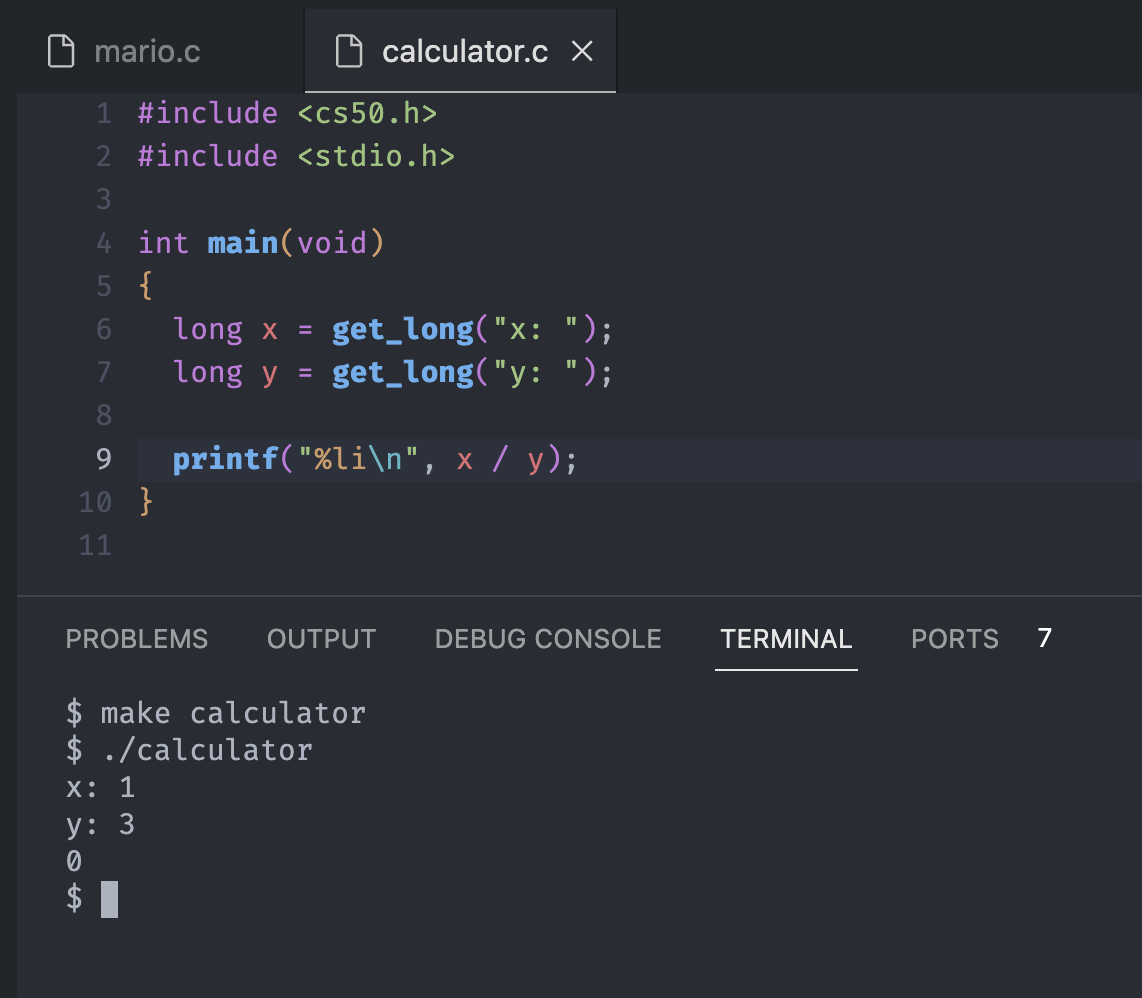
Does the answer right? Well, 1 divided by 3 should be 0.33333... or at least 1/3, not 0
That happened because the answer supposed to give us the fraction or a floating-point value with a decimal point, so we can't continue to use the integers or longs(long integers).
We can solve this problem by change the format code from %li to %f. One step further, let's define another z variable as a float and calculate two integers and pass it to the printf function
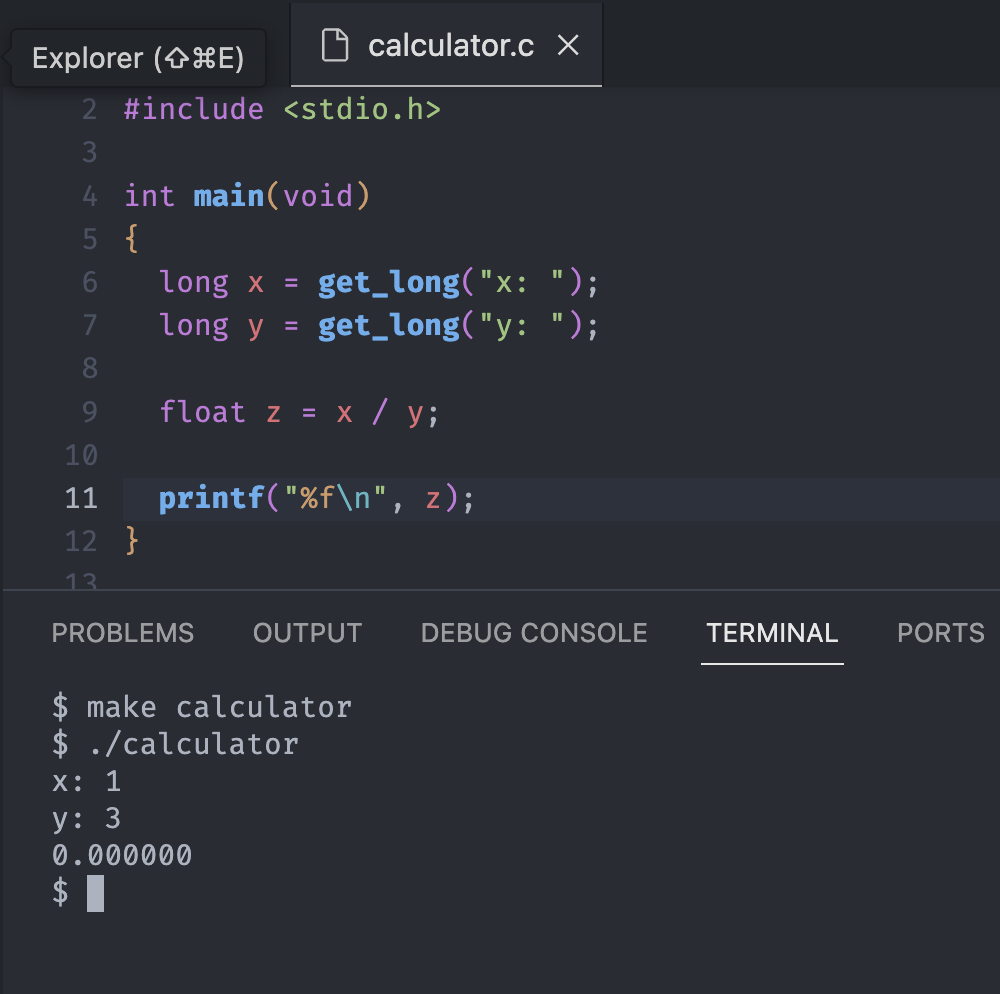
Again, we still have the 0.00000. At least we can see the decimal point, but it seems that our code already truncated the value 1/3.
To get around this, we can use a feature called type casting - convert one data type to another by explicitly telling the compiler that we want to do so.
The problem here is that C is still treating x and y as integers with no decimal point and dividing one by the ohter, therefore has no room for any numbers after a decimal point.
Let's use a slightly new syntax with parentheses to specify that we want to convert x from a long to a float.
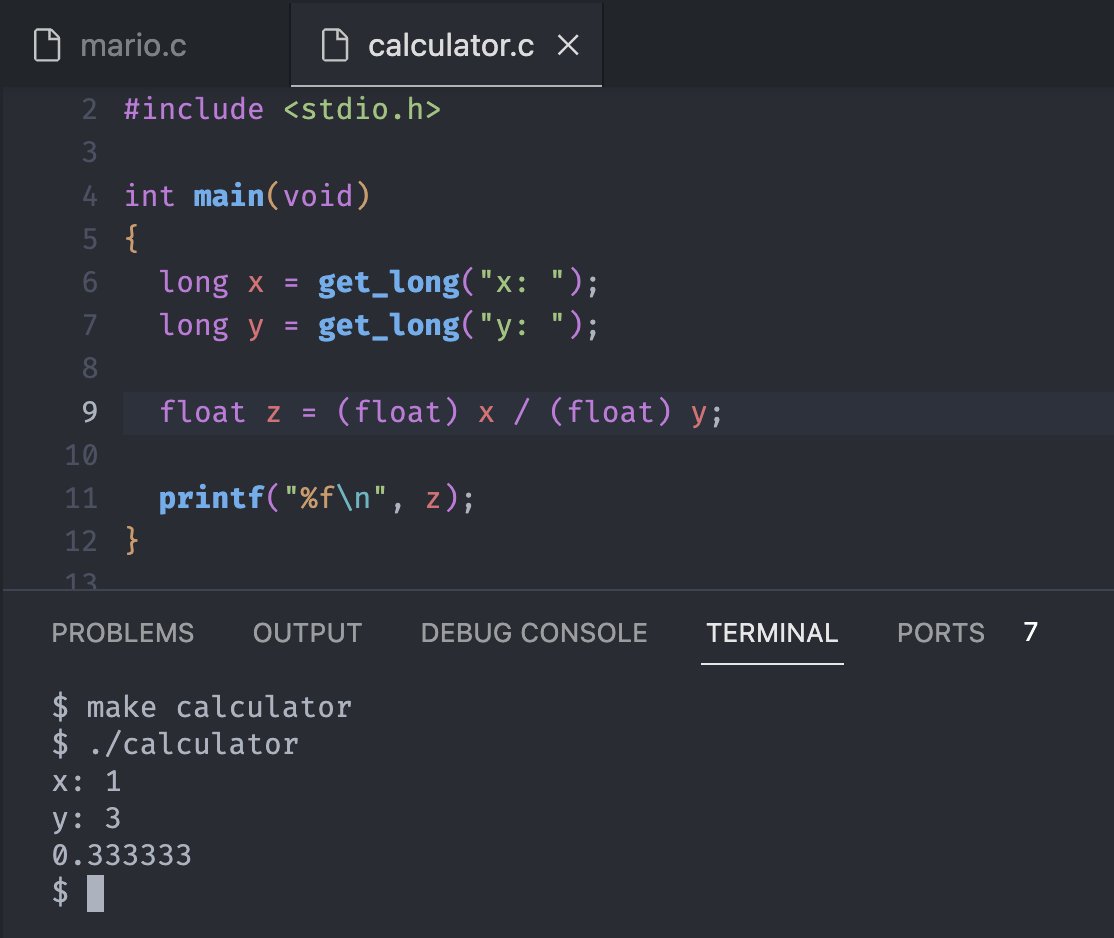
Notice the result of division z had the value of float / float and the output has a desired format although it only shows limited numbers of 3s.
Floating point imprecision
When we are manipulating numbers in a computer using a finite amount of memory, we might run up against another challenge. Besides integer overflow and truncation, this problem is known as floating-point imprecision.
We learned about that we can't represent as big as we want using int or long alone because of the upper bound. In similar manner, there is a boundary on how precise our numbers can be.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
long x = get_long("x: ");
long y = get_long("y: ");
float z = (float) x / (float) y;
printf("%.20f\n", z);
}Notice that our format code now changed to %.20f, indicates to show 20 decimal point numbers after the decimal point.
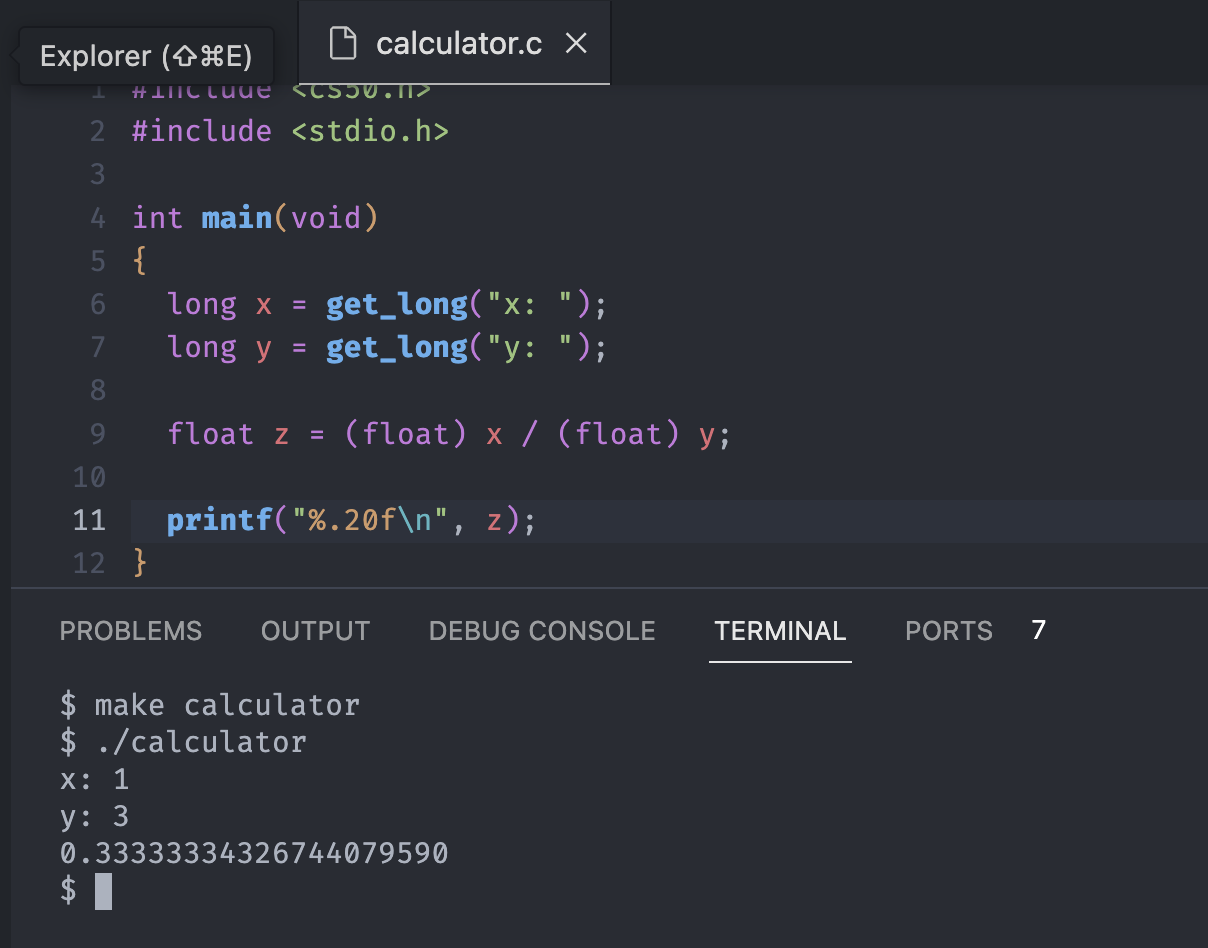
The answer goes even worse at this point, with the weird approximation. As we all know the answer should be the infinite numbers of 3 after the decimal point.
This issue of floating-point imprecision happened because we only have a finite numbers of bits or a finite amount of memory, the computer can only be precise intuitively.
Hence, the computer given the way to implementing these floating-point values in some way because the computer cannot represent the infinite numbers.
So the number given in the terminal is essentially the closest approximation that the computer can represent.
There is alternative way to solve this problem with another data type double where it gives us twice as many bits as a float.
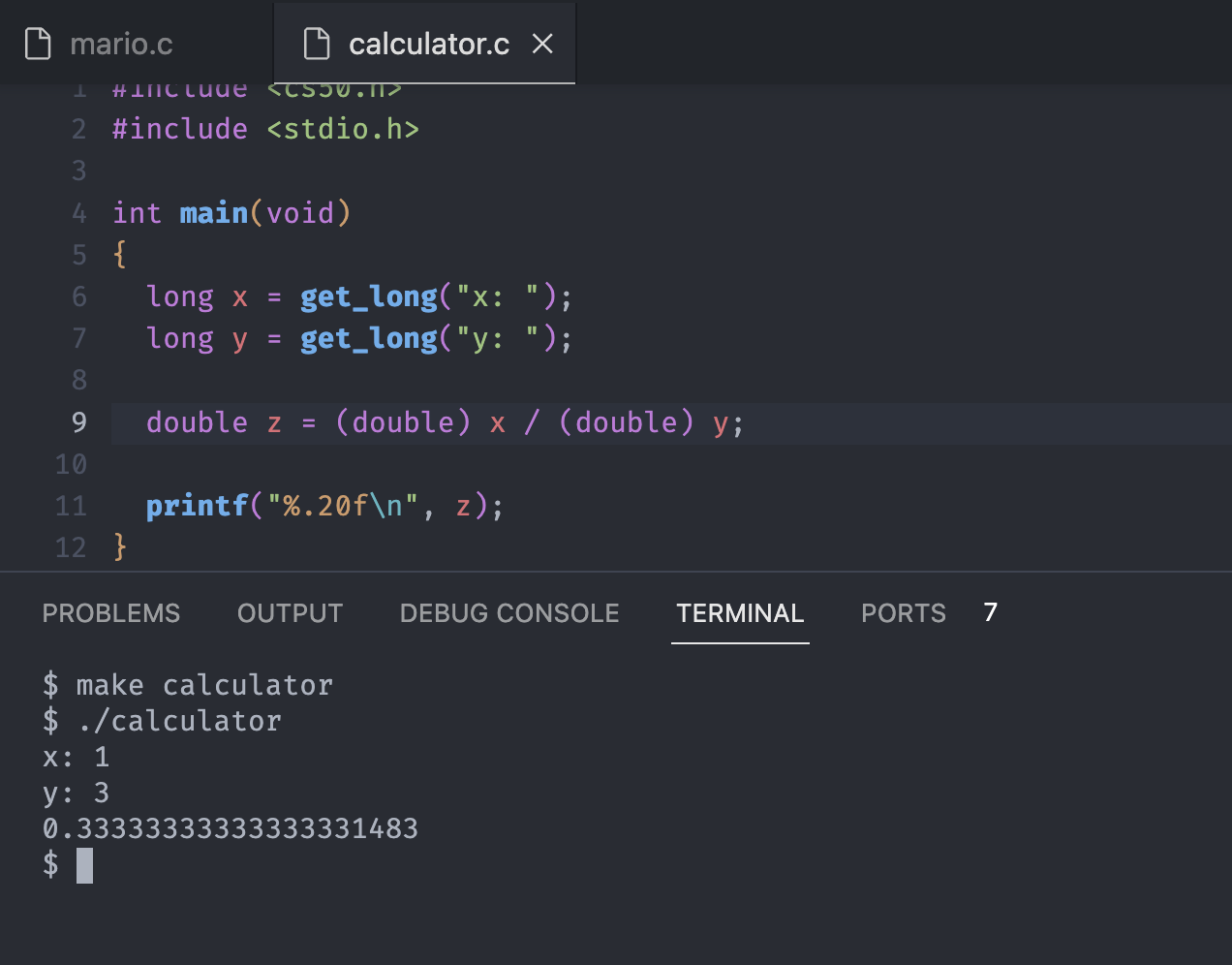
Notice the answer have more threes after the decimal point, which means more and more precise number. We can't get the perfect infinite number because of the memory limitation, but we can get a precise number as much as the memory allows.
Y2K
Switch our gears to the real-world, this memory issue still exist in our daily life.
Back in the year 1999, we got a taste of this when the world realized that leading up to year of 2000, it might not have been the best idea to storing year information in software by using only two digits.
Like instead of storing 1 9 9 9 to represent the year, a lot of computers used 99 for reason of space and cost.
The problem is that if systems were not updated by the year 1999 to support the year 2000, the computers might face the integer overflow, and might add 1 to the year in their memory.
It should be 2000 but if the computers ussing two digits to represent the years, they might mistake the year and take the year to 1900 instead.
Now we are in 2023, and as we understand more about the limitations of code and computing, did we overcome this issue?
Turns out we will run up against the same issue on Jan 19, 2038. On 2038, we will have run out of bits in most computers currently to keep track of time.
Years ago, humans decided to use a 32-bit integer to keep track of how many seconds had elapsed over time. They chose an arbitrary date in the past - Jan 1, 1970 - and started counting seconds from there on out.
Hence, if a computer stores some number of seconds, that tells the computer how many seconds have passed since Jan 1, 1970.
Unfortunately, using a 32-bit integer, we eventually overflow the size of that variable. Potentially if we don't get ahead as society, as computer scientists, on the date of Jan 19, 2038, that bit might flip over, thereby overflowing the size of that particular integers bringing us back computationally to Dec 13, 1901.
Everything we've discussed in this lesson has focused on varioius building-blocks of our work as a programmer.
Also those building-blocks will be a guide to us for this question: How does one approach a computer science related problem?
Data Types
Define variable verbally
To create a variable, we need a special syntax for each programming language. In C, we use the syntax like this:
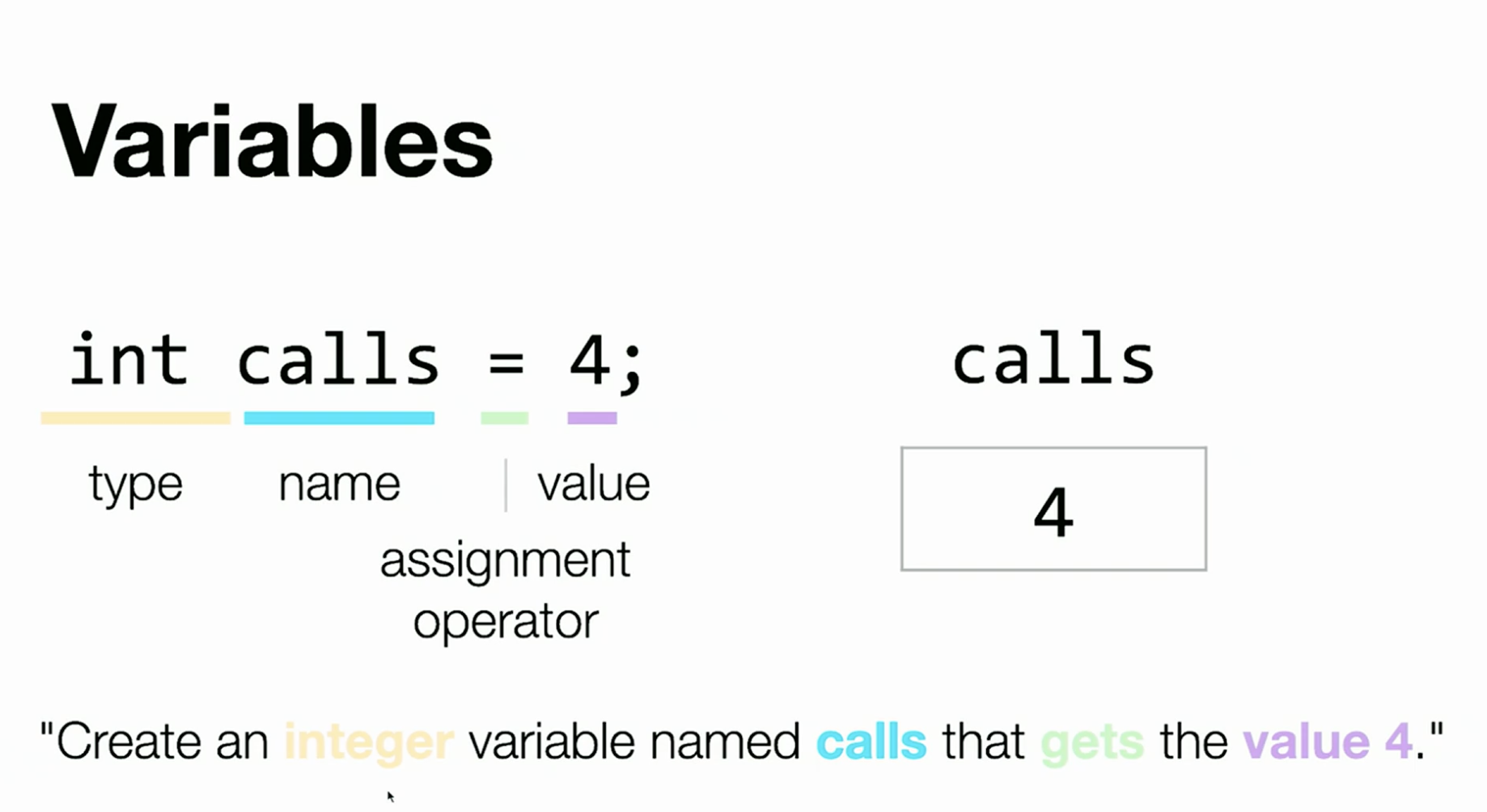
We can verbally express the variable like the picture above that we want to create an integer variable named calls that gets the value 4. Where the integer is the data type, the calls is the variable name, the gets is the equal sign, and the value 4 is the integer call's value 4.
Int
There are many data types in programming, and modern programming languages like Python or JavaScript doesn't necessairly specify the data type.
But in C, we need to declare the varaible type every time when we create a variable.
The first data type is int which is the intger. The int data type is used for variables that will store integers.
The thing to remember is that the integers always take up 4 bytes of memory and that is 32 bits because there are eight bits in a byte.
This means the range of values that an integer can store is limited by what can fit within 32 bits worth of information.

As we know there are negative and positive integers so we need to split up that range of 32 bits to each getting half of the range.
Hence, the range of value of an integer is -2^31 to the 2^31 - 1 because we need a spot for zero. (2^32 / 2 == 2^31)
That is roughly about negative two billion to positive two billion.
Unsigned Int
There is some another int we should take a look is called unsigned int. The unsigned integer is not a seprate type of variable.
Rather, unsigned int is a qualifier. It modifies the data type of integer slightly. Integer is not the only one, and we can use unsigned other data types.
The unsigned var effectively doubles the positive range of variables of that type, in this case an integer, at the expense of disallowing any negative values.
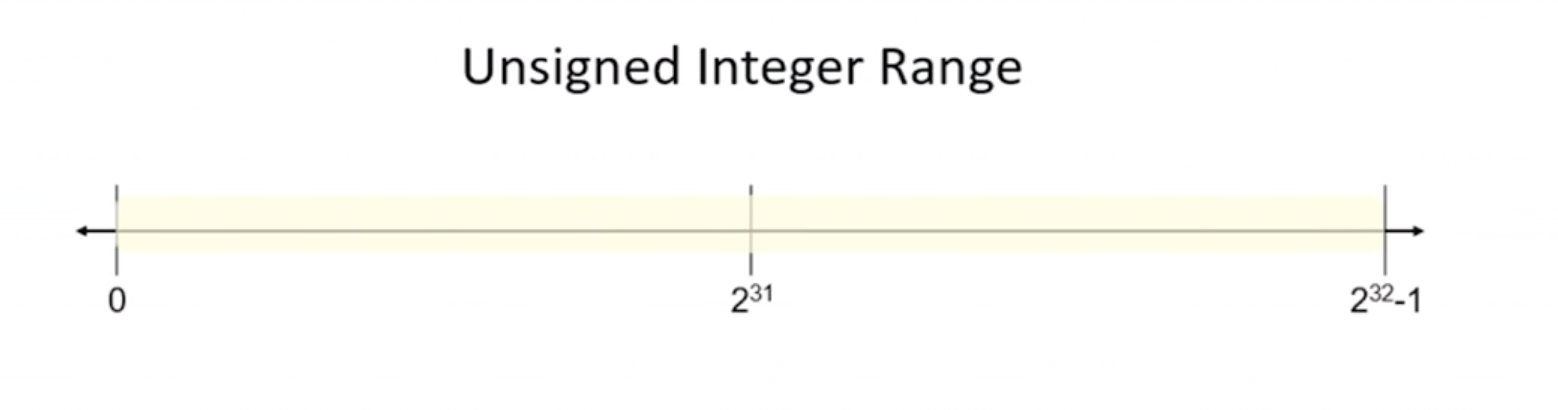
Notice the range is all positve. We can use this unsigned int if we know that the value will never be negative.
Chars
The char data types is used for variables that will store single characters.
Characters always take up one byte of memory, which is 8 bits. This means they can only fit values in the range of -2^8 == -128 to 2^8 - 1 == 127.

Thanks to ASCII, they create a way to map those positive numbers from 0 to 127 to various characters that all exist on our keyboard.
For example, the capital A maps to the number 65 and lowercase a is 97. The character 0 is 48 and notice that number 0 and character 0 means slightly different in this context.
Float
The next major data type is floating point numbers, where the float data type is used for variables that will store floating-point values, also known as real numbers.
They are basically the numbers that have a decimal point in them. Floating point values also contained within 4 bytes of memory.
It is complicated to describe the range of a float because it is not clear or intuitive.
Suffice it to say we have 32 bits to work with, the floating number like pi has integer part 3 and decimal part 14159.... Suppose we need to represent all of the integer and floating-point values and suppose the decimal part gets longer.
pi = 3.1415926535 ...In that case, if the number has a large integer part, the number might not be able to precise with the decimal part. Hence, the float has a precision problem.
Double
Fortunately, there is another data type called double, the double data type is also used for variables that will store floating-point values.
The difference is that doubles are double precision, which means they can fit 64 bits of data or 8 bytes of memory.
With an additional 32 bits of precision, we can be a lot more precise with the decimal point. If we working with the number that has a long decimal point and the precision is important, use double over float.
Void
The type void is not a data type, but it is a type. We can't create a variable of type void and assign a value to it.
Functions like printf is a generic void function, and it has void return type which means they don't return a value.
Recall that printf just prints the value and we called that a side effect, but it doens't give us the value back.
int main(void)We probably feel comfortable with the code above, and this time, the void is a parameter list. The parameter list of a function can also be void, what that means is that function main doesn't take any parameters.
More complicated details are in later course, but suffice it to say, think of the void serve as a placeholder for nothing
Boolean and String
The above five are primary types we will encounter in C, but there are two additional types we need to know for general programming.
Boolean
The bool data type is used for variables that will store a Boolean value. More precisely, a Boolean value is capable of only holding two diffferent distinct values - True and False.
Many modern language has Boolean as a standard default data type, but in C, they are not built-in data type. So we need to add a header file, the library, same as the stdio.h.
In this course we use cs50.h and normally we can include stdbool.h library to use True and False.
String
The other major data type is string, which is the collections of characters and they can be words, sentences, paragraphs and the like.
The string data type is used for variable that will store a series of characters.
The library cs50.h provide the string data type and if we need to use string without the cs50.h, we can include string.h library.
Creating a variable
To bring a variable into existence, we can simply specify the data type of the variable and give it a name like this:
int number;
char letter;In case of creating multiple varaible of same type, we only need to specify the type name once, and then list as many variables as we need.
int height, width;
float sqrt2, sqrt3, pi;Notice we can split the float code in three separate lines, but consolidate three lines in a single line of code makes the code clean and short.
Using a variable
After we declare the variable, we don't need to specify the data type of that variable anymore. In fact, if we inadvertently re-decalre the variables with the same name might causing weird error in the program.
int number; // declaration
number = 17; // assignment
char letter;
letter = 'G';Notice that the code above is how we can create a variable. We can also simultaneously declaring and assigning the value of a variable, thus consolidate the above in one step.
// We can call this initializing
int number = 17;
char letter = 'G';Operators
Arithmetic operators
In order to manipulate and work with variables and values in C, we have a number of operators at our disposal that we can use.
As we learned, we can do a basic math operations like add, subtract, multiply and divide numbers. Guess the value of x when the x is initialized and the value of the last x.
int y = 10;
int x = y + 1;
x = x * 5;Another important operator is % and is called the modulus operator. The modulus operator gives the remainder when the number on the left of the operator divided by the number on the right.
int m = 13 % 4 // m is now 1The modulus operator used frequently when calculating even and odd numbers or random number.
For instance if the random number generator gives us a number from zero to some huge number, but maybe we only need a number from 0 to 20. We use the modulus operator here on that giant random number, divide it by 20 and get the remainder. The remainder can only be a value from 0 to 19
It will become more handy as we go through the lecture and deal with more practice problems.
Short syntax
C also provide us shorthand way to apply an arithmetic operator to a single variable.
x = x * 5
x *= 5Notice that the above two lines of code is identical, but the second line is slightly shorter version to express. We don't need to use it but have to be familiar with this syntax to read and understand the code like this.
We can refine the shorthand syntax even further, when incremeting or decrementing a variable by one. This is such a common case in C, especially when we use a loop.
x++;
y--;The first line code above has the same meaning of x = x + 1 or x += 1, but we have even short handed that to x++. Those three codes are the same code that has different styles.
Boolean Operators
Boolean expressions are fall into the overall category of operators. However, Boolean expressions are used to comparing values unlike arithmetic operators.
It evaluates one of two possible values - True or False
We can use the results of Boolean expression in a lot of ways in programming. For example, we can use it to decide whcih branch down our code conditional, so to speak. One familiar example might be the loop, when the codition is false, we keep do some behavior over and over again.
Sometimes when working with Boolean expressions, we will use variables of type bool but we don't always have to declare it.
In fact, C treats every non-zero value as True and zero as False.
#include <stdbool.h>
int n = 1, 2, 3 // true
int m = 0 // falseThere are two main types of Boolean expressions: logical operators and relational operators.
Logical Operators
Logical AND (&&) is true if and only if both operands are true, otherwise false.
| x | y | (x && y) |
|---|---|---|
| true | true | true |
| true | false | false |
| false | true | false |
| false | false | false |
Logical OR (||) is true if and only if at least one operand is true, otherwise false.
| x | y | (x || y) |
|---|---|---|
| true | true | true |
| true | false | true |
| false | true | true |
| false | false | false |
The final logical operator is NOT (!), which inverts the value of its operand.
| x | !x |
|---|---|
| true | false |
| false | true |
It might sounds weird at beginning, where we call if x is true, then not x is false and if x is false, then not x is true.
Relational Operators
These are faimliar math operators and behave as we would expect to, and appear syntatically similar to elementry arithmetic.
(x < y) // Less than
(x <= y) // Less than or equal to
(x > y) // Greater than
(x >= y) // Greater than or eqaul toAnother two operators that are important are testing two variables for equality and ineqaulity.
(x == y) // Eqaulity
(x != y) // InequalityCommon mistake for most of beginer programmers make is to use the single eqaul sign (=) for the eqaulity comparison operator (==). It will leads weird behavior in our code, so we need to keep that in mind.
Conditionals
Conditional Branch
Conditional expressions allow our program to make decisions and take different forks in the road, depending on the values of the variables or the user inputs.
C provides a few different ways to implement conditional expressions, which we also sometimes call this a conditional branch. Some of which likely look familiar from Scratch.
If
Recall that in Scratch, we had a if-block that has the C-shape, and all of the code inside of that if-block will execute if the condition is true.
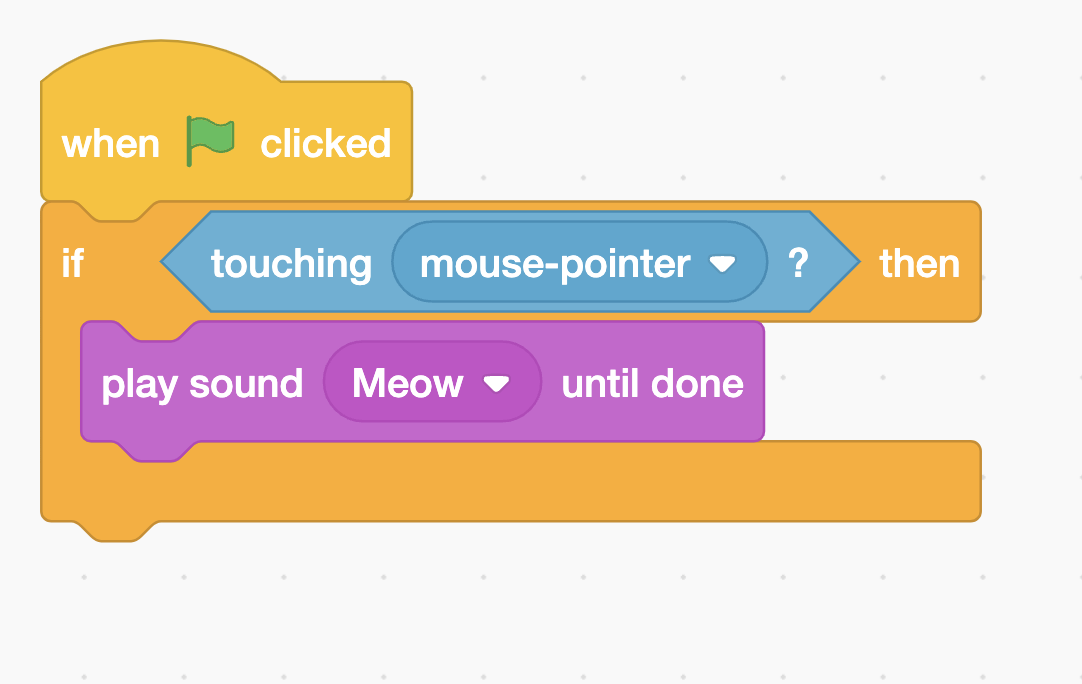
In same manner, we have a if statement that has the same structure as the block above. One of the Boolean expressions we learned go inside of parentheses, and if the Boolean expression is true, the code inside of the curly braces will execute in order from top to bottom.
if (boolean-expression)
{
}If the Boolean expression is false, we will skip over everything in between curly braces because we only want to go down that fork in the road if the Boolean expression is true.
If-else
The block below is the Scratch's Oscar time from the first lecture.
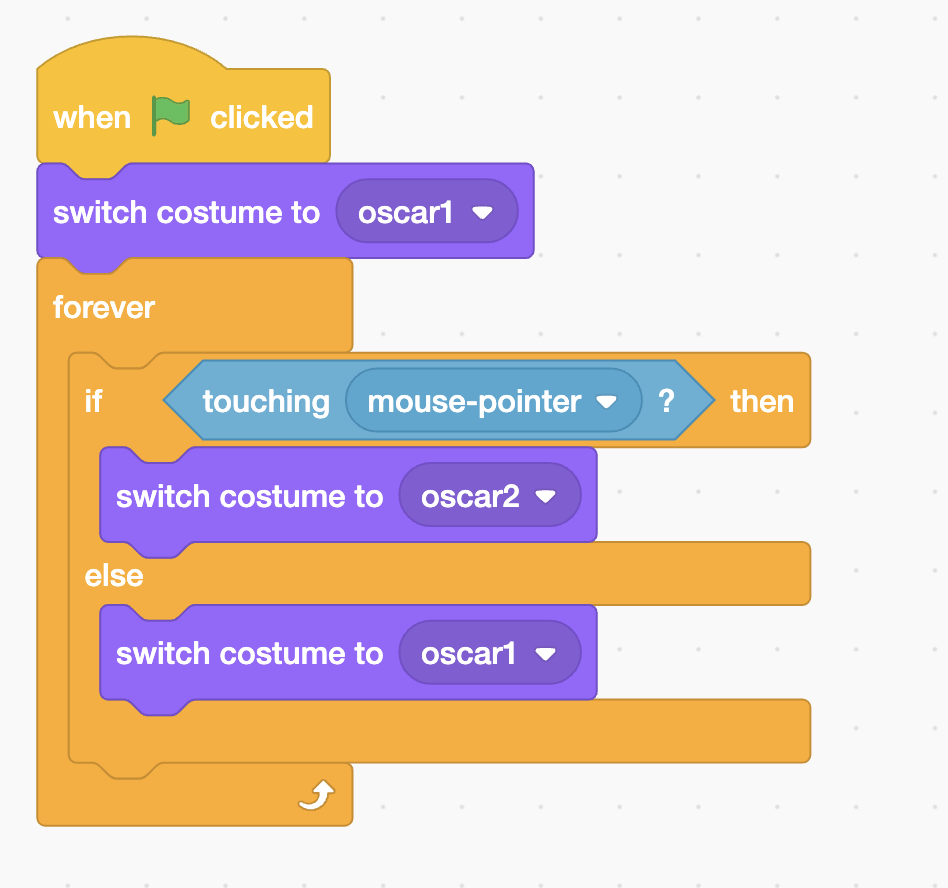
The block above is the analogus to the conditionals in C. If the Boolean expression evaluates to true, all lines of code between the first set of curly braces will execute.
if (boolean-expression)
{
}
else
{
}Indeed, if the Boolean expression evaluates to false, all lines of code between the second set of curly braces will execute in order from top to bottom.
Conditinoal Chain
In C, we can create an if-else if-else chain like this:
if (boolean-expr1)
{
// first branch
}
else if (boolean-expr2)
{
// second branch
}
else if (boolean-expr3)
{
// third branch
}
else
{
// fourth branch
}All of the branches above are mutually exclusive, whcih means we can only ever go down one of the branch. It is also possible to create a chian of non-mutually exclusive branches.
if (boolean-expr1)
{
// first branch
}
if (boolean-expr2)
{
// second branch
}
if (boolean-expr3)
{
// third branch
}
else
{
// fourth branch
}In this case, only the thrid and fourth branches are mutually exclusive. The else binds to the nearest if only. We can satisfy the first condition, the second condition, and the third or fourth condition. Then we go down the first, the second branches and choose between third or fourth branch.
Switch statement
Another important conditional statement is a switch() statement, which permits to specify distinct cases. Instead of relying on Boolean expressions, switch statement allow to make decisions for our program.
#include <cs50.h>
int x = GetInt();
switch (x)
{
case 1:
printf("One!\n");
break;
case 2:
printf("Two!\n");
break;
case 3:
printf("Three!\n");
break;
default:
printf("Sorry!\n");
}For instance, the above program asks user to provide an input, and switching. What it does is, the program changing or switching the behavior depending on what user typed at the prompt.
It's important to break each case otherwise we will fall through. If we didn't have any breaks between each cases, and if the user typed 1, the program print all of the cases.
In face, sometimes omitting the break can be useful, and here is the example:
#include <cs50.h>
int x = GetInt();
switch (x)
{
case 5:
printf("Five!\n");
case 4:
printf("Four!\n");
case 3:
printf("Three!\n");
case 2:
printf("Two!\n");
case 1:
printf("One!\n");
default:
printf("Blast-off!\n");
}Notice that if the user typed 4, the program will execute all of the printf below the case 4 including four. We call this behavior as fall through each case.
Ternary Operator
The last coditional statment is a ternary operator or ? :.
// regular
int x;
if (expr)
{
x = 5;
}
else
{
x = 6;
}
// ternary
int x = (expr) ? 5 : 6;Notice that the above two code snippets act identically. The ternary operator (? :) is mostly cute trick, but is useful for writing trivially short conditional branches.
The first variable after the question mark is what x's value will be if expression is true. The second variable after the colon is what x's value would be if expression is false.
Loops
While loop
The while-loop is what we call an infinite loop, which is simliar to forever block in Scratch.
while (true)
{
}The lines of code between curly braces will exectue repeatedly from top to bottom, until the program find a way to break out the loop with a break statement same as in switch statement, or otherwise kill our program manually with ctrl + c.
Notice that while loops are not always infinite because we can replace the Boolean expression with a little more useful than just true.
while (boolean-expr)
{
}The code above is pretty much analogous to repeat until block in Scratch, although they are slightly different.
In C, if the Boolean expression inside the while loop evaluates to true, the lines of code between curly braces will execute repeatedly until the Boolean expression evaluates to false.
The difference between repeat until block in Scratch is that the Scratch block repeats until the expression is true. Meanwhile, the while loop in C continue to do something inside the loop until the Boolean expression is false.
int x = 0;
while (x < 10)
{
x++;
}Notice that the code above will increment x by one until x becomes 10 because 10 is not less than 10.
They are quite similar, but there is a little distinction. So just to be careful of especially as we make our first foray from transitioning to Scratch into C.
do-while loop
The do-while loop execute all lines of the code between curly braces once, then it will check the Boolean expression.
do
{
}
while (boolean-expr);If the Boolean expression is true, the loop will go back and repeat the process in curly braces again until the Boolean expression evaluates to false.
The biggest difference between while loop is that do-while loop is guaranteed to run at least one time.
for loop
The for loop might looks syntactically unattractive, but for loops are used to repeat something a specific number of times.
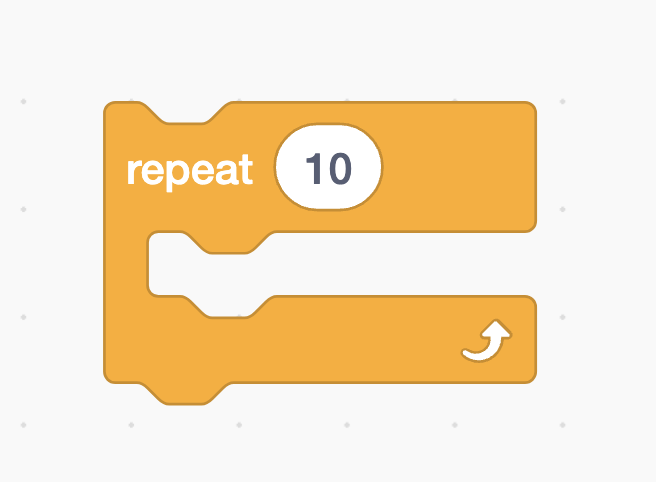
As we know there is a repeat block in Scratch, and it is analogous to the for loop down below:
for (int i = 0; i < 10; i++)
{
}Let's break it down to what is happenning step by step.
- The first thing that happened is the counter variable
iis set. We declared a variable type as integer, named asiand set value to0. - The second thing is then immidiately evaluate the Boolean expression. The body of the loop will behave follow by the evaluation(true/false).
- Lastly, the counter variable is incremented, and then the loop will check the Boolean expression again until the
i's value becomes10in this loop.
for (start; expression; increment)
{
}Notice we can think of the for loop like the pattern above.
Use cases
To sum up, we will go over each loop and learn where we can use those loops.
- Use the
while loopwhen we want a loop to repeat an unknown number of times, and possibly might not run at all.
Most common use case is to run the control flow for a game. We don't know how long the user is going to playing, but we want to keep doing the same thing. - For
do-while loop, it is quite similar, to use when we want a loop to repeat an unknown number of times, but at least once.
A common use case is prompting the user for input. When we ask the user to provide a positive integer, it will ask the user at least once. - The
for loopcan be used typically when we want to repeat a loop a discrete number of times, though we may not know the number at the moment the program is compiled.
If we have a loop that waits the user input number, and after we get the input, the program will execute the given number times.
Although we outlined these use cases, we should to know that in most circumstances we can interchange all of these loops.
Command Line
Using the Linux Command Line
We briefly learned about the commands previously, again that is a keyboard-based commands for working with the IDE or any UNIX-based operating system including Linux and MacOS.
As a programmer, we will likely be using our terminal window frequently, instead of GUI, the graphical user interfaces.
ls
The command ls is short for list, which it gives us a readout of all the file and folders in the current directory.
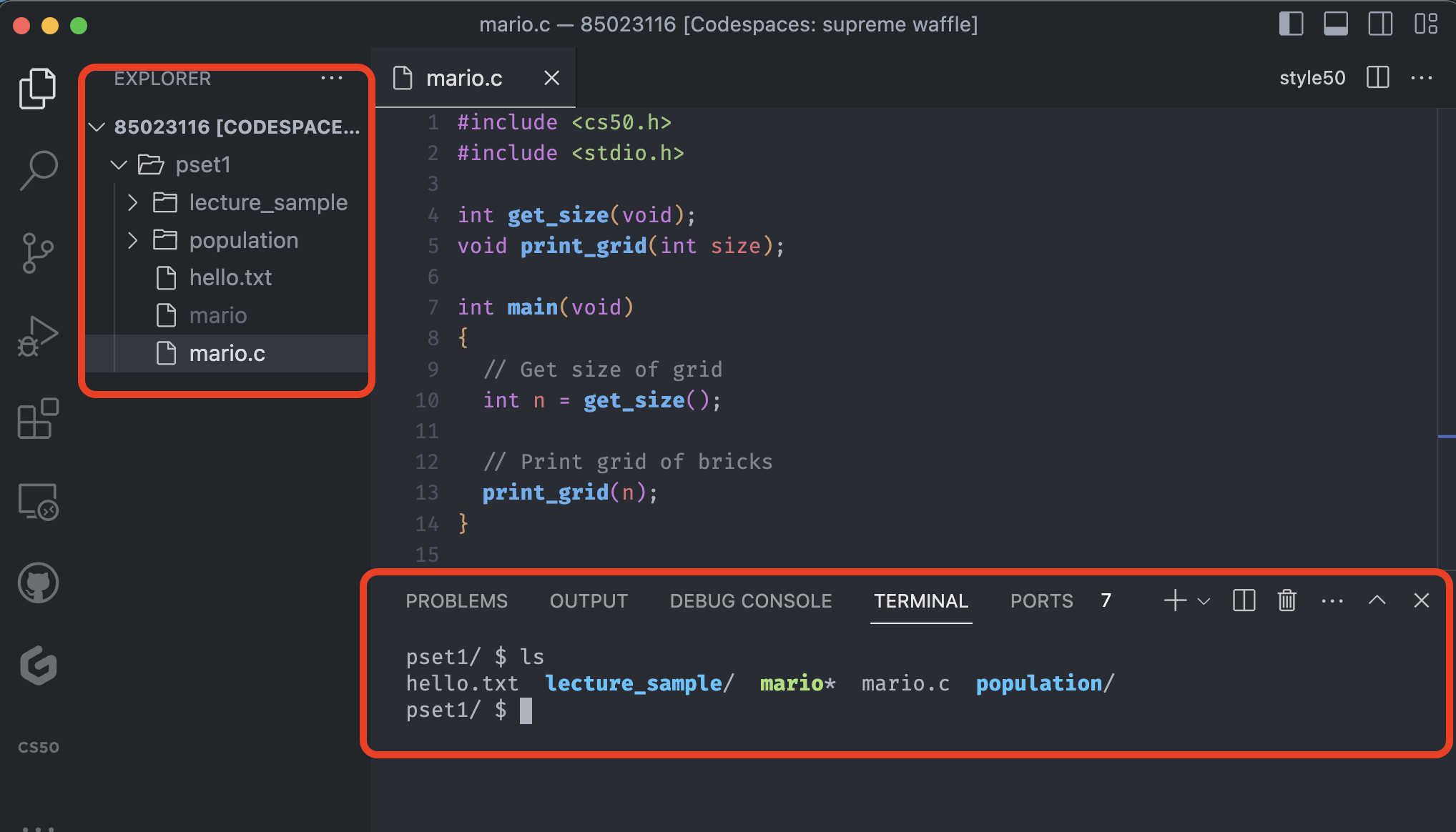
Notice on the left side we have a GUI, which we can interact with the mouse like we normally do with our computer. We are in the pset1 directory, and the ls command shows the list of files and folders exactly same with the GUI.
On the bottom right, we typed ls and it shows the files with three different colors.
The gray files indicates the text files or the source code like the mario.c in the code space above.
The blue files indicates the folders and the green file indicates the file is executable, which means we can run the program from the terminal.
cd <dicrectory>
The command cd is short for change directory, which allows to change the current directory to <directory> or navigate between directories at the command line as opposed to double-clicking on folders.
As an aside, the name of the current directory is always ., and the name of the directory one level above the current directory is ..
If we ever curious about the name of the current directory, we can type pwd which stands for present working directory.
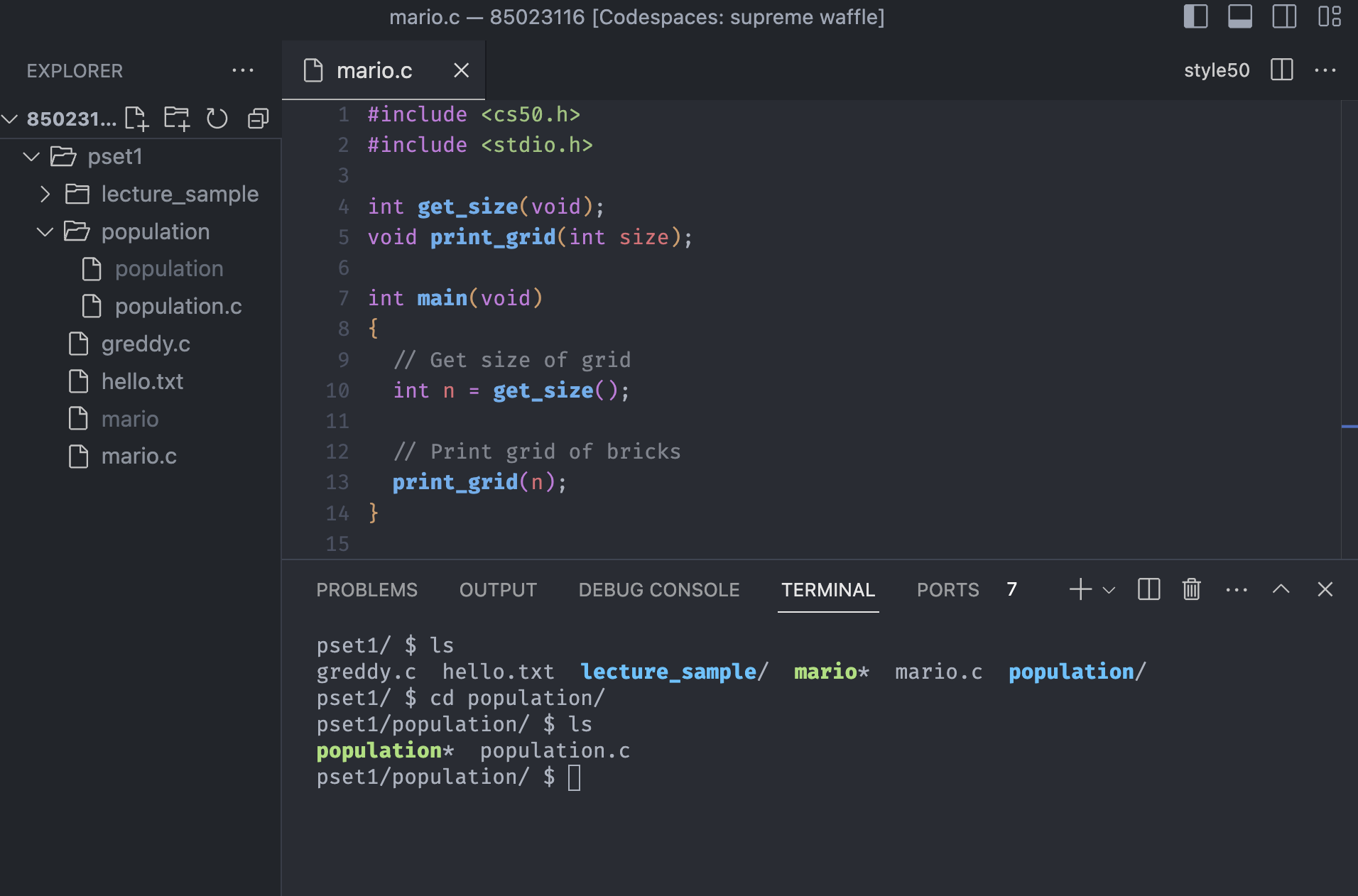
Notice we used cd into the population directory, and the path has changed accordingly.
If we want to go back to the pset1, we can do this:
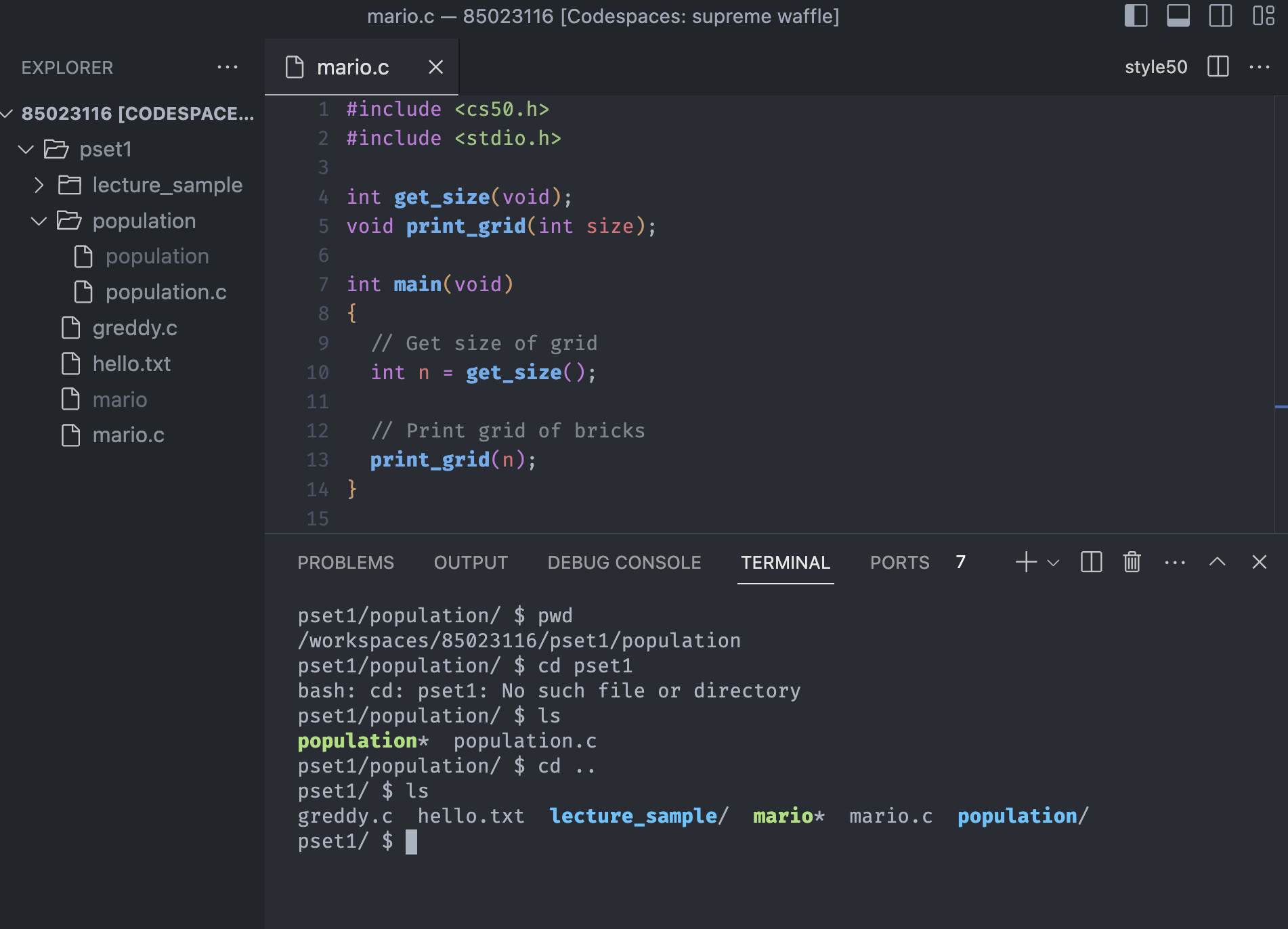
We can see that pwd shows the current path, and cd pset1 command can't be used because the directory pset1 is not in the current directory.
After using cd .. command, we navigated to the one level above, and we can see all the files as before.
Another good use case is the picture above. Suffice it to say we are in some directory but we don't know where we are, because of the complicated working tree.
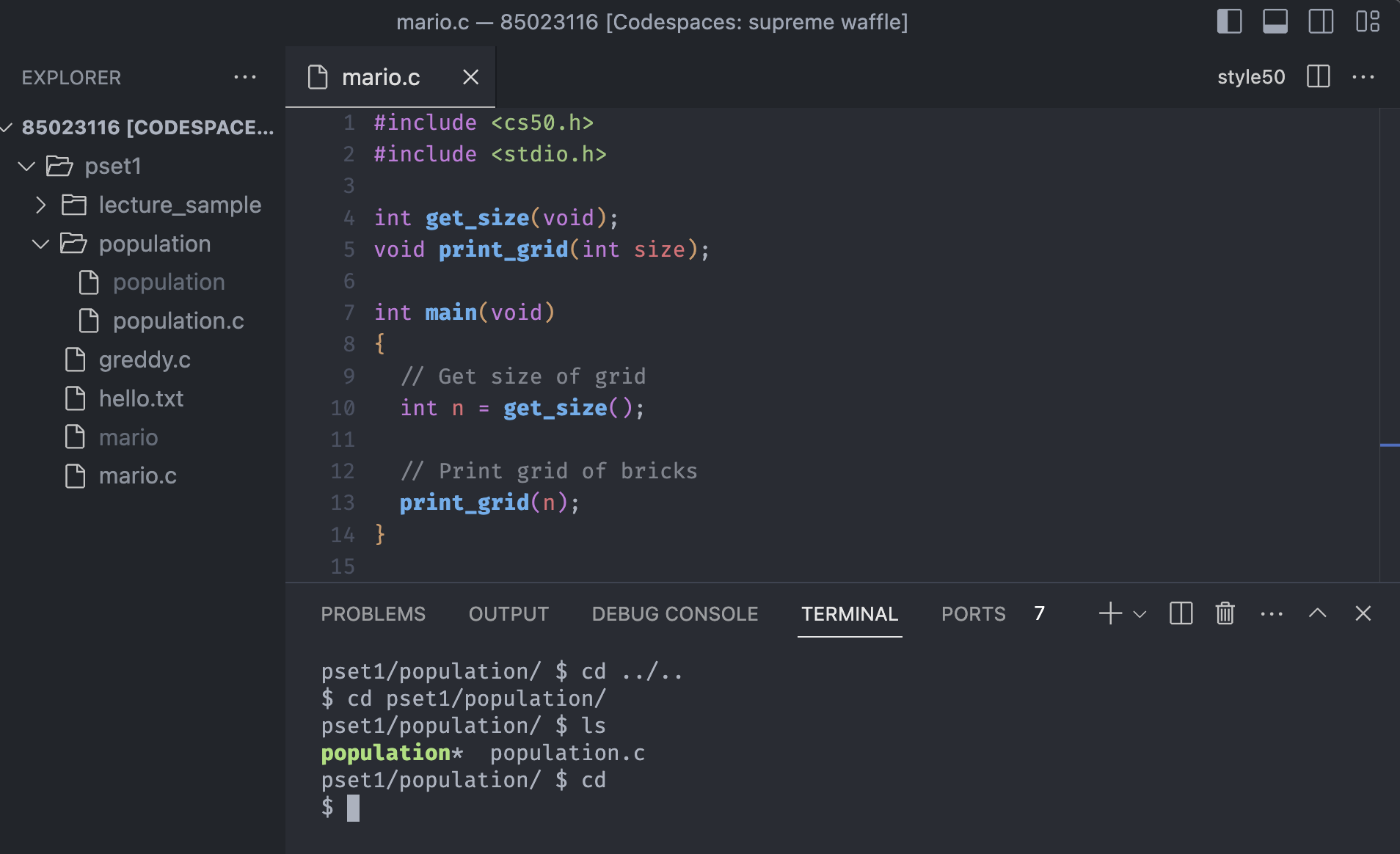
Here, we are in the population directory, and once we want to go to the root or home directory, which means where the pset1 belongs, we can use cd and nothing else.
We can use ../.. because the population directory is two level deep from the root, but if we are in five or six level deep, we can simply escape and go to home directly.
One good example is ./mario, whcih we used for run the program. If we look at the command closer, . indicates the current directory, and by /mario command, we are executing the file called mario.
mkdir <directory>
The command mkdir is short for make directory, and thie command will create a new directory in the current folder.
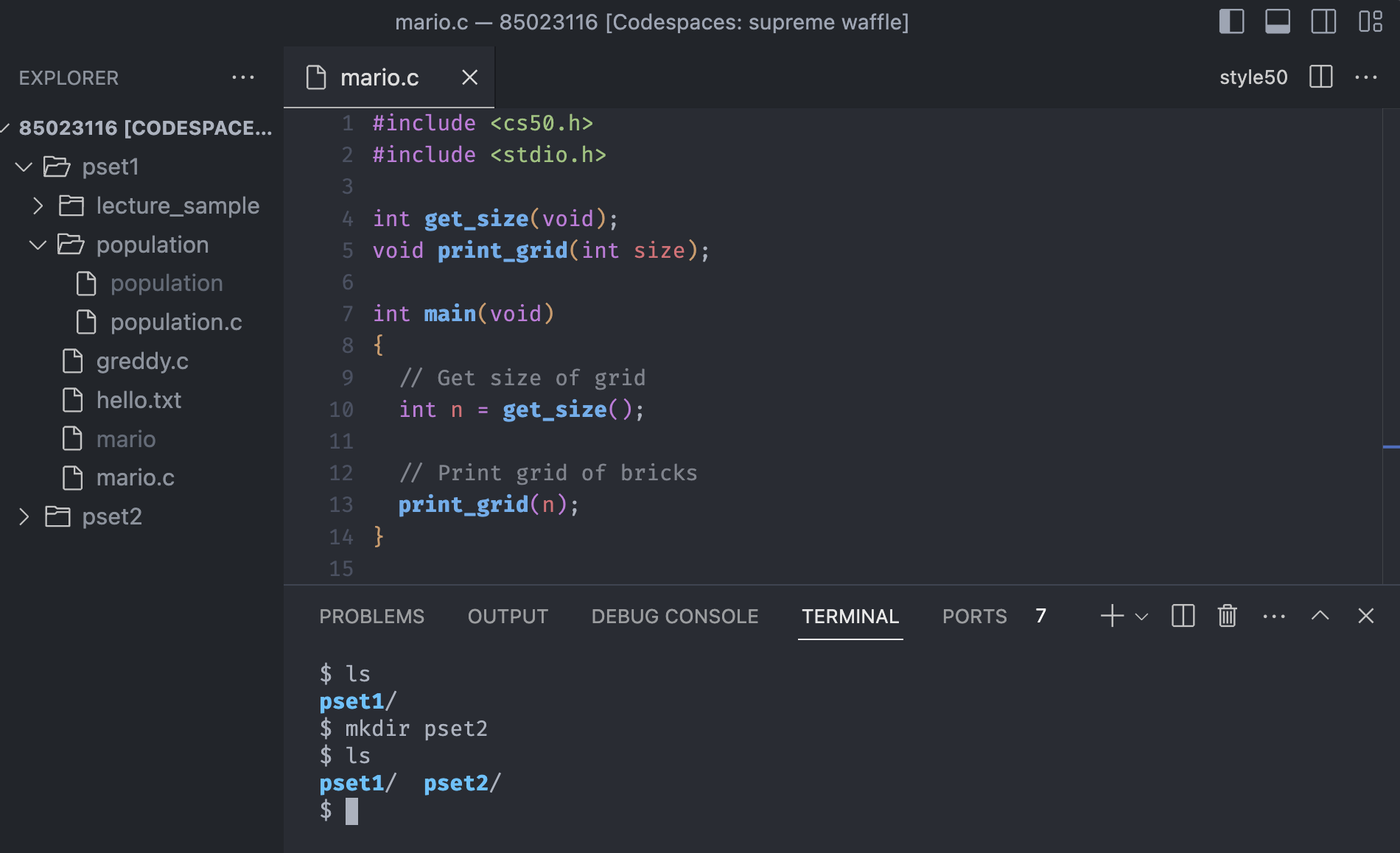
We were in the home directory, and suppose now we finished with pset1, and want to create pset2 to working with.
We can run mkdir pset2, and check the current directory. Indeed the pset2 directory has been made and go inside with cd pset2 to working with the pset2 folder.
cp <source> <destination>
The command cp is short for copy, and unlike other commands we have seen above, it takes two arguments - A source, the name of the file that we want to copy, and a destination, where we want to copy the file to.
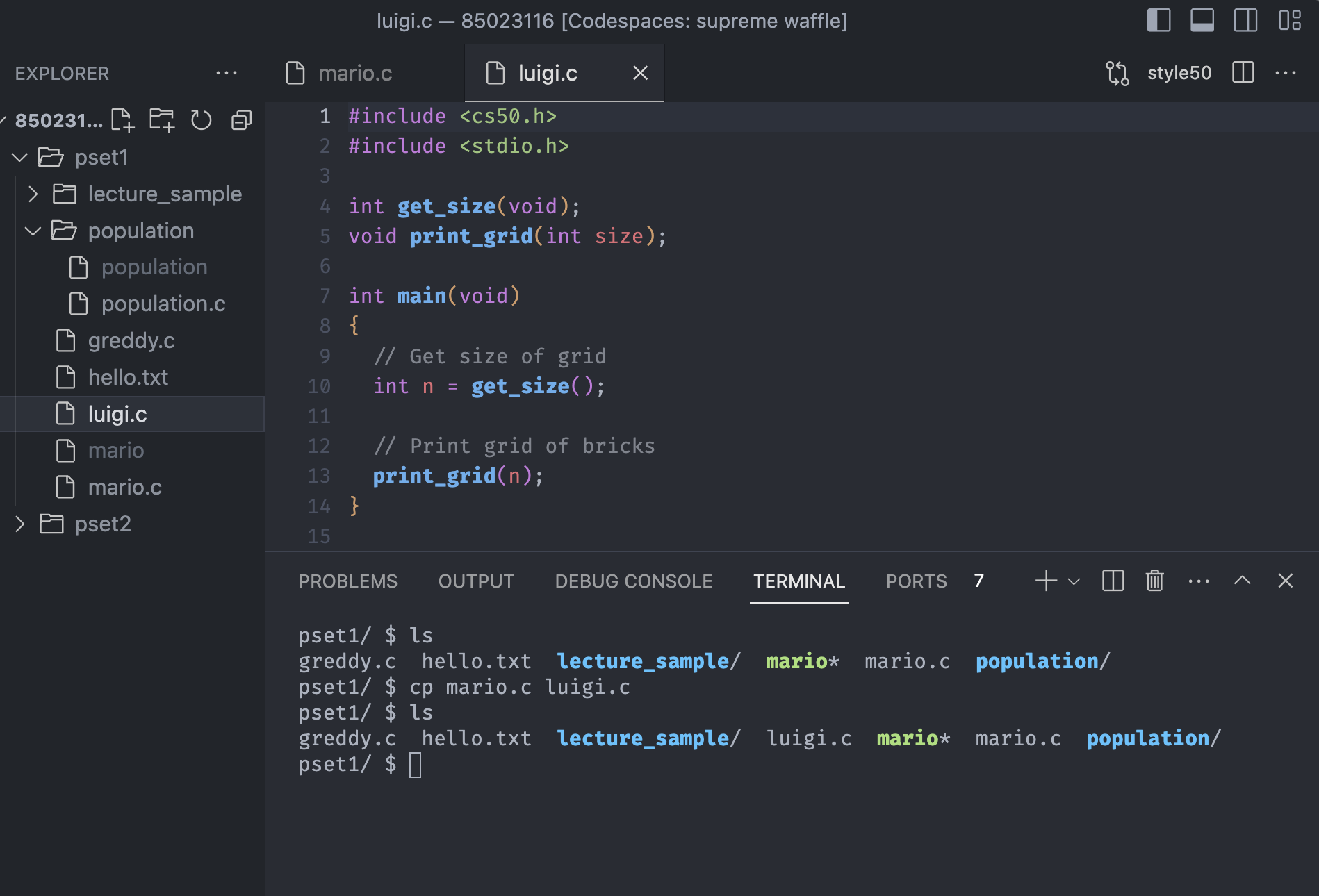
Suppose we want to make another content that is relative to mario, we can go to the GUI, copy the file and paste the file, but with the cp command, we can do it with one line of code.
Notice that we copied the whole code from mario.c to luigi.c with the cp command. Once we manually open luigi.c, it has the exactly same code with mario.c.
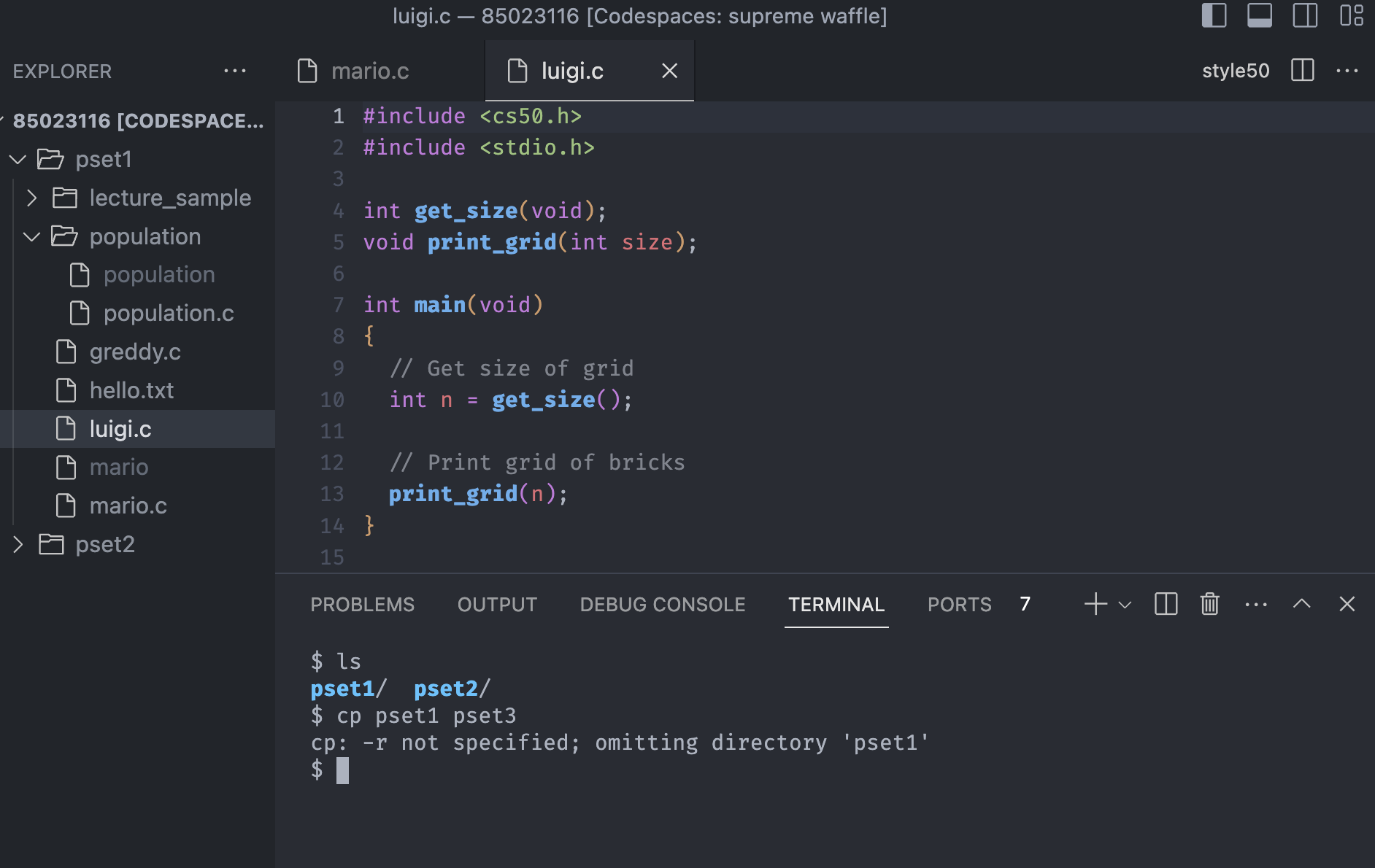
As we see, we can't use the cp command with the directory. It turns out when we copying the directory with other stuff inside of it, cp command doesn't know what to do with it.
We need to explicitly tell the terminal, to copy the directory and copy every folders and files that exists inside of it. In other words, the terminal need to recursively dive down into the pset1 folder and make a copy of everything in there.
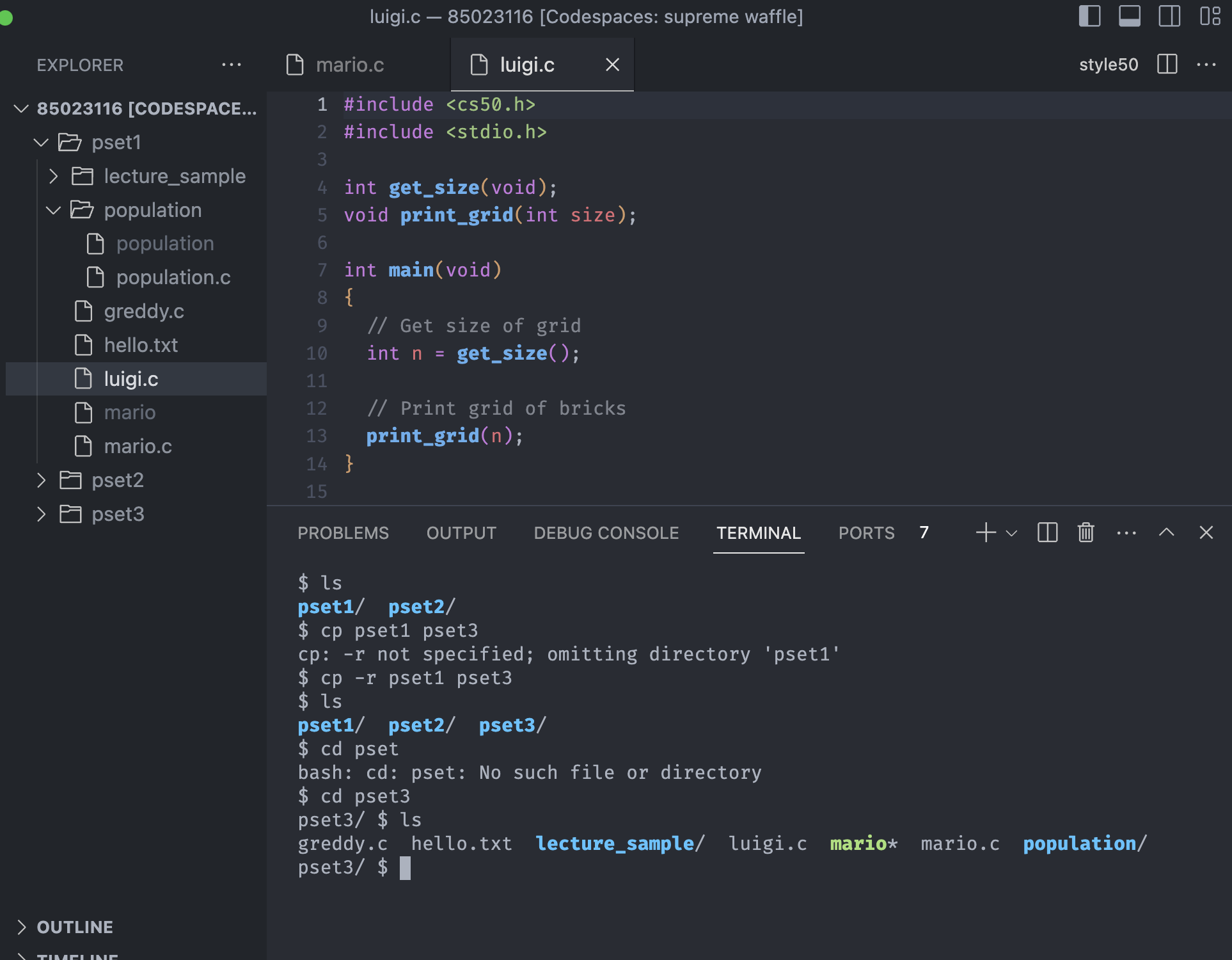
Run the command cp with -r, stands for recursive, and the command should be cp -r pset1 pset3. See the command line in picture, we can see the pset3 folder has been created and the files are the same with pset1.
rm <file>
The command rm is short for remove, this command will delete the file after it asks to confirm (y/n) to delete it.
Be very careful because there is no recylcle bin like the Windows or Mac OS. Once the file is deleted it is gone, there is no way to recover it.
Let's remove luigi.c that we previously created(if not, we can create it first).
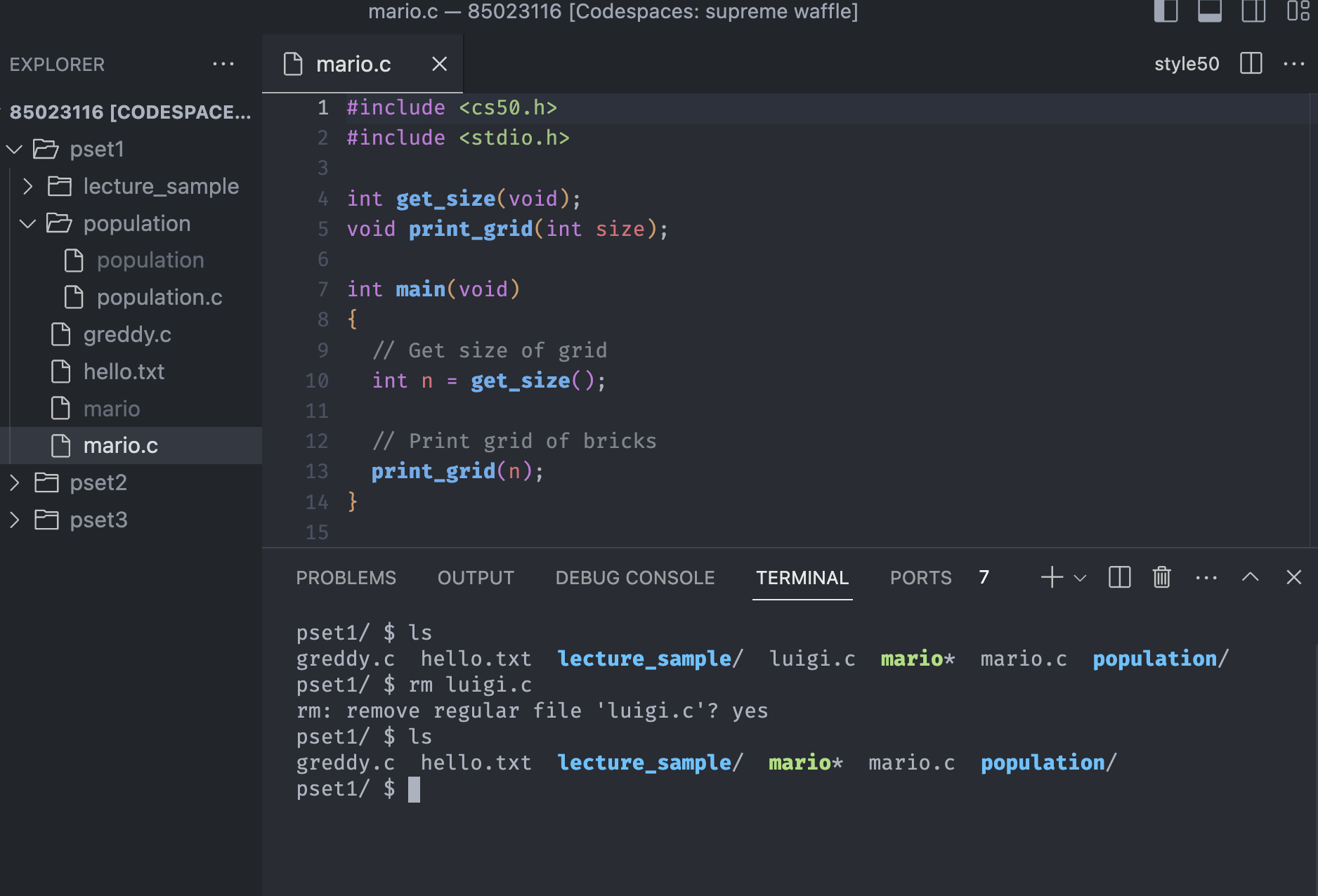
Notice that the terminal asks to confirm the deletion, and think of it as the pop-up message in Windows or MacOS when we try to delete some file. Type yes or y, is essentially the same, and we can see the file is gone.
We if really sure that we want to delete the file and we don't want to be asked the question, we can skip the confirmation by specifying an extra flag, like we did with cp.
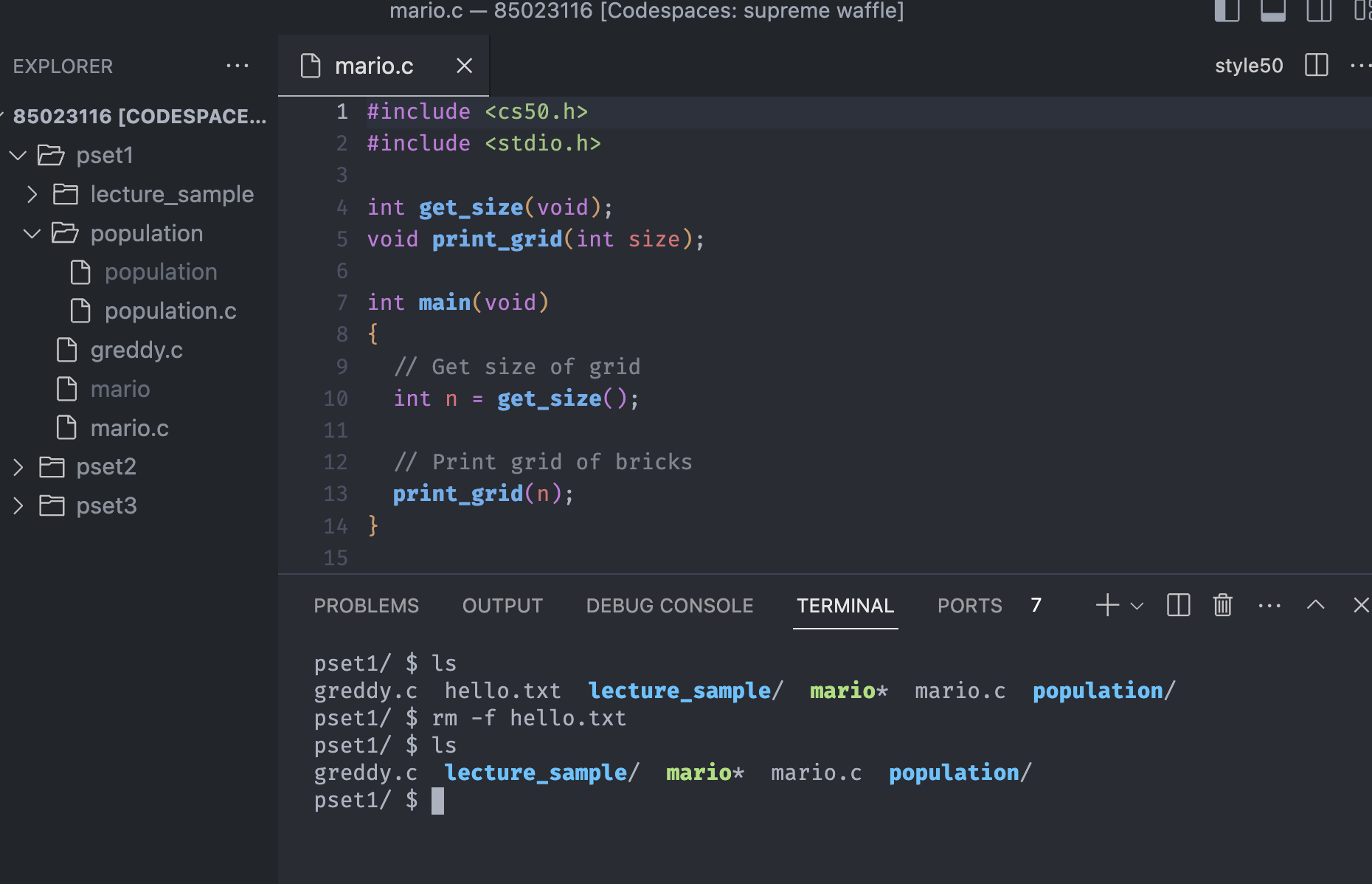
Now, suppose we want to delete the hello.txt. With the rm -f command, the terminal won't ask the question. Next, we actually don't want the pset3 directory, so let's remove the copied folder pset3, how can we do that?
Same with the cp -r, we run rm -r and it will recursively delete the directory and everything inside of it.
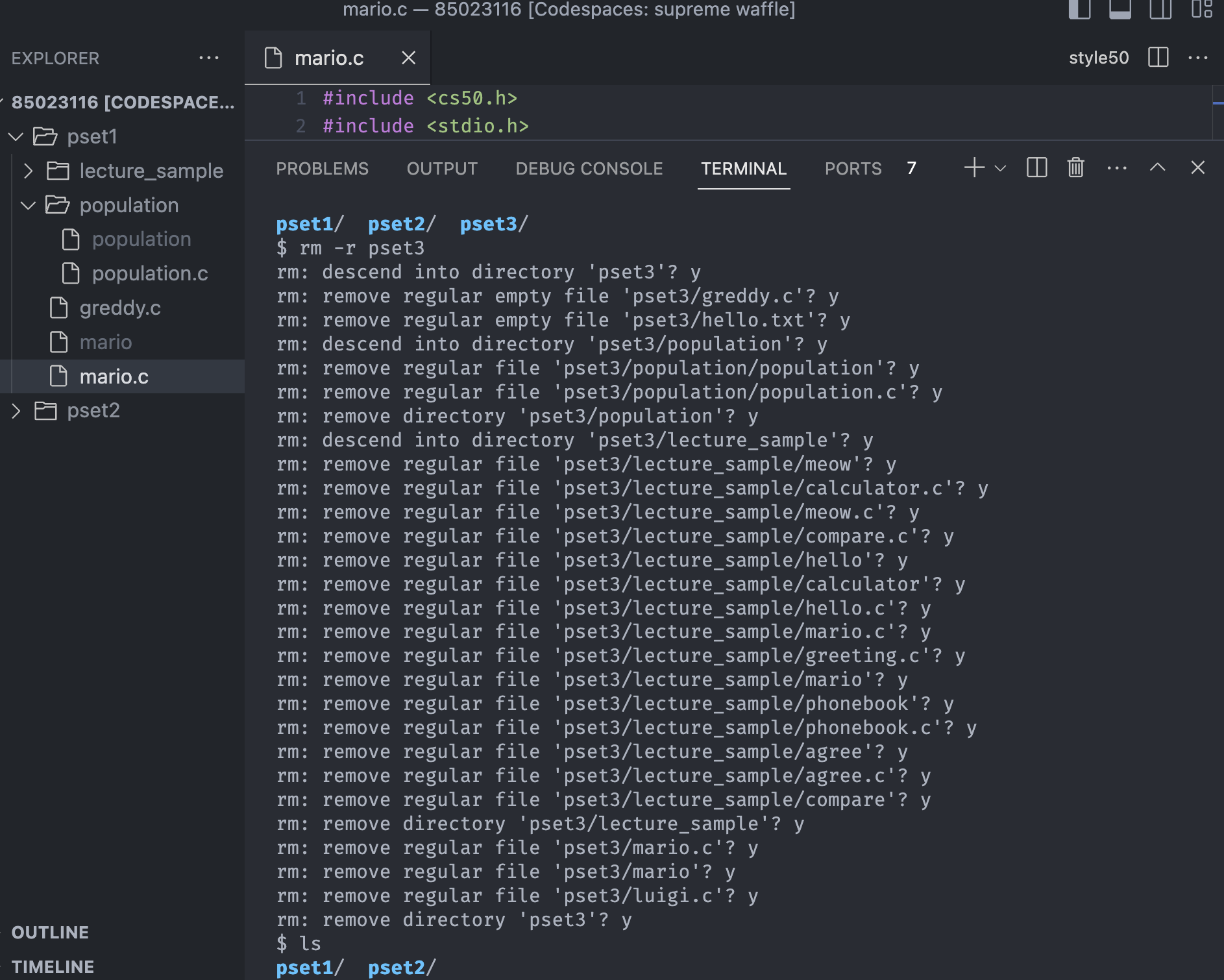
Notice everytime when we meet the files, it asks the confirmtion and we have to answer all the questions like the picture above.
One last variation on rm command is rm -rf. -rf means we want to remove the directory recursively and forcibly. As the picture above, it asks the question again and again until it deletes all the files in the directory and the directory it self.
But that's a quite disaster when we have a big project that contains more than 100 files in one directory. We can avoid the repeated confirmation by adding -rf flag to the command.
Be really careful and use this command at your own peril, because it can lead to some disastrous consequences if we delete the wrong thing.
mv <source> <destination>
The last command is mv is short for move, this command is basically equivalent to rename a file. It moves a file from one location to another, the source to the destination.
Sometimes we accidently name a file with a wrong name. One way to rename a file is using cp and rm commands.
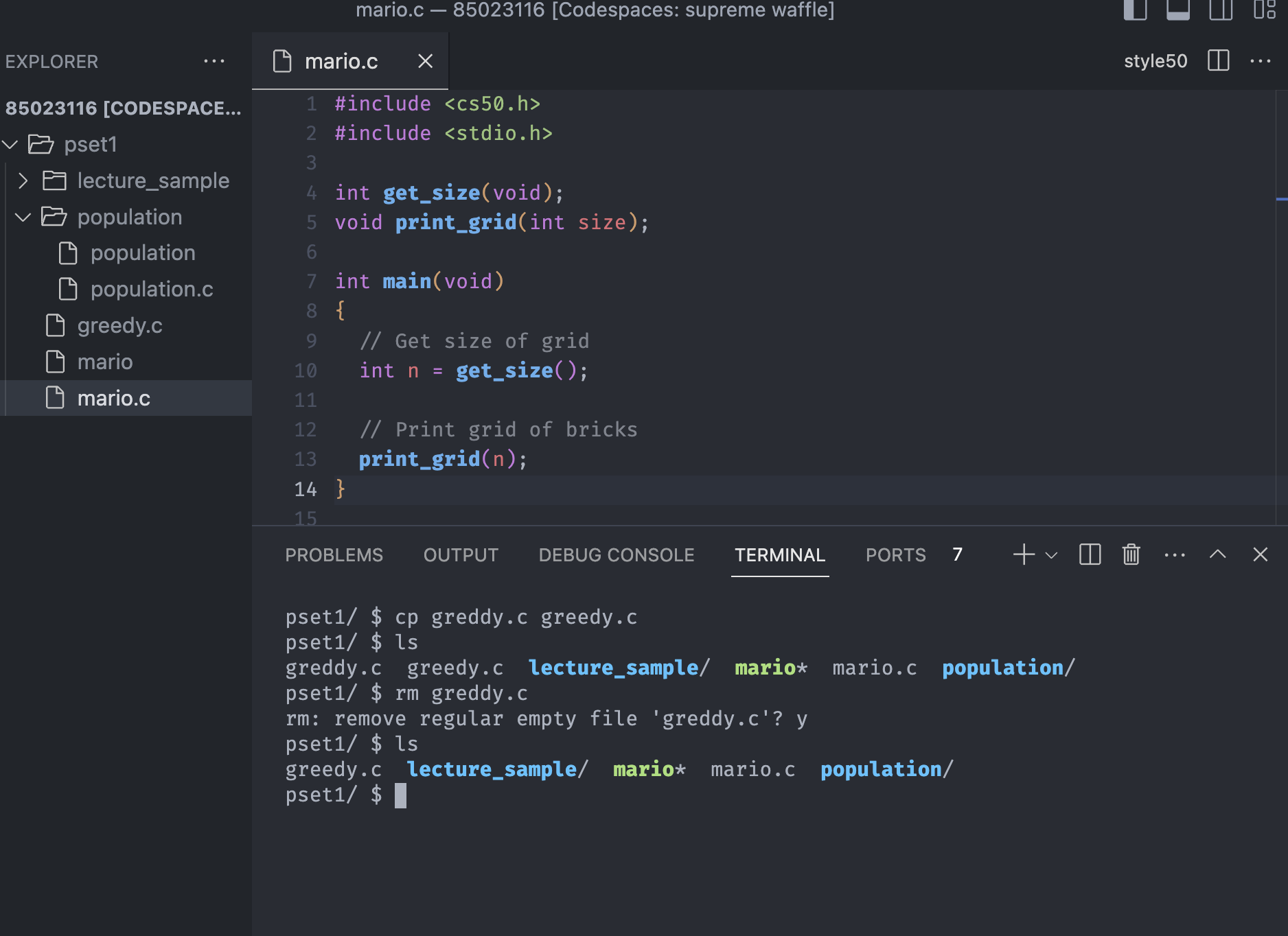
Notice that we copied all the code into greedy.c and delete the greddy.c. However, that's a multi-step process, and there is a better way to do this.
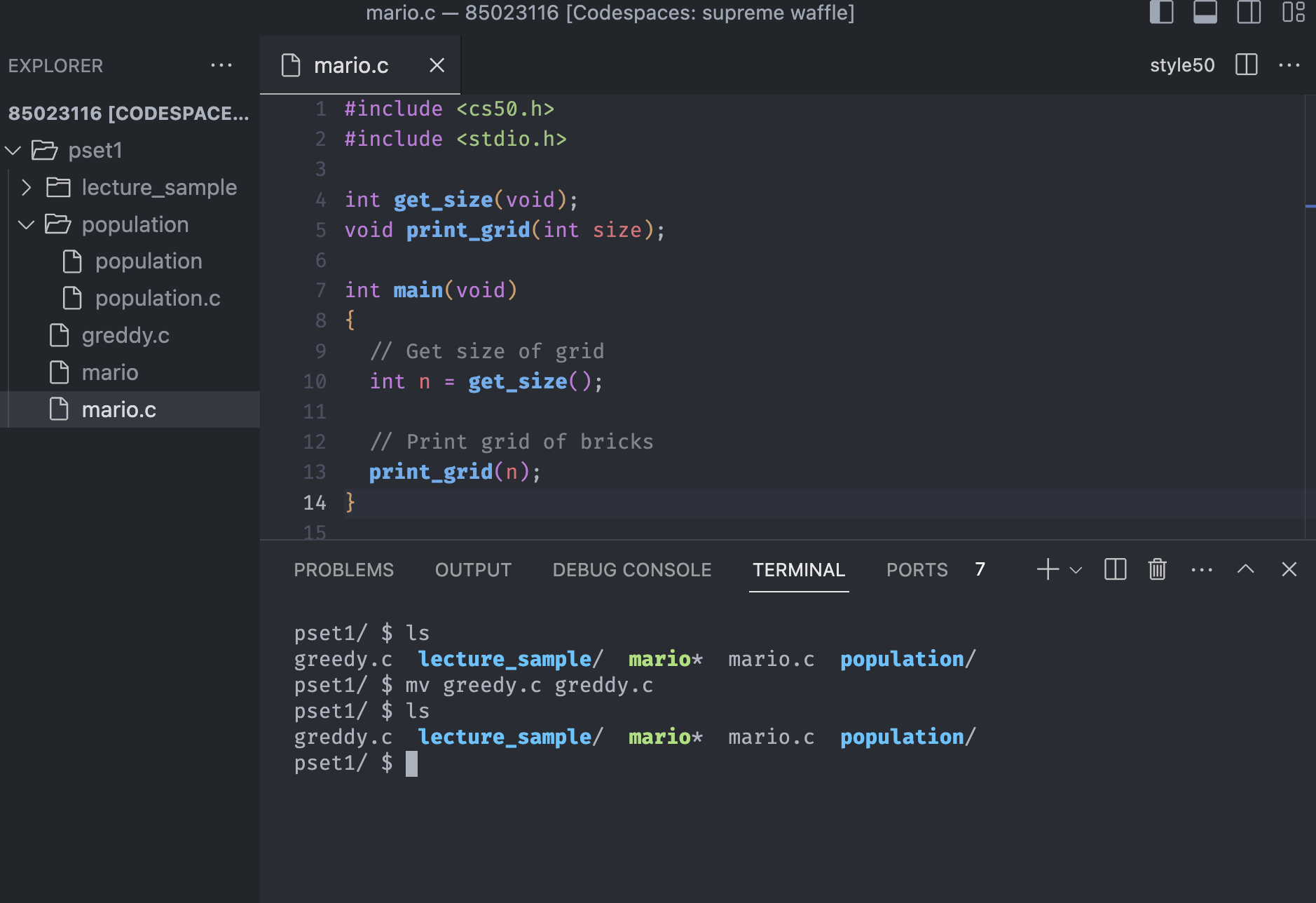
We used mv greedy.c greddy.c to go back to the original version. We didn't have to copy and remove the file, but we were able to rename it.
Magic Numbers
In general, it's a bad habit to write constants into our code. In doing so, when we actually do write a constant into the code, it sometimes referred to as using magic numbers.
Suffice it to say we have a pseudocode version of the function deck which is dealing with the cards.
card deal_cards(deck)
{
for (int i = 0; i < 52; i++)
{
// deal the card
}
}It deals with the deck as its parameter and will output a single card. Where the trump card has 52 cards in one deck and we loop through the cards and deal a card.
What is the magic number here or more importantly what is the probelm in this code snippet? - It's 52, like intuitively we could understand a deck of cards contains 52 cards.
However, in our program, the number is just floating around in there. Which means all of sudden there's a 52.
One way to resolve this problem is to explicitly declare the deck size like the below:
card deal_cards(deck)
{
int deck_size = 52
for (int i = 0; i < deck_size; i++)
{
// deal the card
}
}By setting int deck_size to 52, we can fix the problem, which means the variable deck_size gives some symbolic meaning to the constant.
But, this method actually introduces another problem, that might not be immediately apparent.
Even if the variable declared globally, if one of our functions that shares the deck_size and that function deal with the card manipulation that inadvertently changes the deck_size, that could spell a trouble.
In simple term, if the variable deck_size increases by one or decreases by one, the whole deck_size changes, and that affects the first function's result as well.
Preprocessor Directive
To prevent the magic number issue, C provides a preprocessor directive, also know as a macro for creating symbolic constants.
We have actually seen this preprocessor directive through out this course, which is the #include.
The #include is the another example of macro and it is similar to copy/paste.
The way to create symbolic constants or giving a name to a constant that has more meaning is this:
#define NAME REPLACEMENTWe don't put semicolon at the end of this preprocessor directive, and if we reall the #include <stdio.h>, it doesn't have a semicolon either.
When our program compiled, the compiler go through our code and replace every instance of the word NAME with the value in REPLACEMENT.
Analogously, if #include is copy/past, the #define is similar to find/replace same with the feature in Microsoft Word.
For example, suppose if we want to replace a word PI to 3.14159265, because the number 3.14159265 is a magic number. We know intuitively the number is pi, but when we use the number itself directly in our code, it's just a sudden number that came from nowhere.
Maybe we can give it a little more symbolic meaning, instead of using magic number. We will declare a PI and set the value to 3.14159265.
When the program compiles, the preprocessor directive will go through the code and every time it finds a word PI, it will replace the word PI with the number 3.14159265.
We don't have to type the mouthfull number everytime when we need the value of PI, instead we can use a word PI in the place where we need.
The preprocessor directive is not limited to the number substitution only. We could replace a word with this #define COURSE CS50.
Notice we use the capital letters when we define symbolic constants. That's a convention that makes clear that the capital letter element of our code is a defined constant. It's not required, but if it was lowercase, there might me a confusion with the regular variable especially to people who see our code.
To apply this particular solution to our example, it will look like this:
#define DECKSIZE 52
card deal_cards(deck)
{
for (int i = 0; i < DECKSIZE; i++)
{
// deal the card
}
}We first define DECKSIZE to 52, then we can use 52 anywhere in our code. It's a lot more intuitive and we can't manipulate a constant, hence, it is safer then a variable.
We can change a variable to something, which was the previous int deck_size = 52 case. However, we can't increase or decrease the defined value 52, 52 is always 52 unless we change the defined value at the top.
📌 Takeaway
layout: single
title: "[CS50] TIL CS50X Week 1 - C part 2"
excerpt: "Imagine we want to emulate the blocks in the game Super Mario Brothers."
categories: TIL
tag: [CS, computer_science, EDX, MOOC, TIL]
permalink: /TIL/CS50-04
toc: true
toc-sticky: true
published: true

Week 1 - C part 2
This course is intended for students who have never coded before. The post may be elaborate due to the reason.
🧩 What I Should Learn?
- Create a mini-block program
- Comments
- Operator and Types (short)
- Data Types
- Operators
- Conditional Statements
- Loops
- Command Line
- Magic Number
🎯 What I learned today
Mario
Create a block
Imagine we want to emulate the blocks in the game Super Mario Brothers.
There are four question mark blocks in the sky, and we are trying to change those blocks into a textual version.
The picture above is probably the simplest way to implement those four horizontal blocks using pure text.
But we've seen that there are better ways to do this, and if we want to generalize this code to be five, six or sixty question marks, the loop is always the answer for not repeating ourselves.
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 4; i++)
{
printf("?");
}
printf("\n");
}Notice we placed the printf("\n"); after the loop because placing it inside creates a vertical block.
What if we want to do some other scene from Mario, such as the picture above?
We can modify our code like the one below to make the vertical obstacles.
Advanced blocks
Let's escalate things one level further. When we're in the underground version of Mario, there are a lot of obstructions like the one pictured below.
That is not a single line, but the grids or bricks or combined three-by-three groups of blocks.
We can logically think that we want to print three rows of bricks and three columns of bricks together. Take this problem into smaller pieces; we can start from the loop.
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 3; i++)
{
}
}The loop above will do something three times, even though nothing is inside yet.
Then, if we want to print out a row of three bricks in the same line, that's similar to the four question marks in the sky.
To compose one into the other, we can change our code like this:
#include <stdio.h>
int main(void)
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 3; j++)
{
printf("#");
}
printf("\n");
}
}Notice we used the different integers i and j for the loop; that's because if we use the same name, it could cause a collision or trouble.
Combine one loop with the other; the inner j loop will print out the vertical row, and the outer i loop will print out the new line and make three columns.
But this is not the best design. Suppose we want to change the grid size, which is always square. We have to change the numbers manually and eventually will make some mistakes.
#include <stdio.h>
int main(void)
{
int n = 3;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}We can solve the issue above by initializing n for numbers. The above code has a better design because there's a lower probability of mistakes.
But technically, we can still screw up somehow by accidentally changing the n value. To prevent this error, we can declare n to be a constant using the keyword const.
#include <stdio.h>
int main(void)
{
const int n = 3; // Chaged here
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}That's the way of programming more defensively, and it's a good practice. Defensive programming makes our code better designed because it's less vulnerable to mistakes by us, colleagues or anyone else using the code.
Ask user
We can make our code to prompt the user for the size of the grid.
Don't forget to include the cs50 library to use the get_int function.
Notice the get_int function deals with erroneous input if the user types something like the string cat.
But we only designed a function to get an integer, and the user input might be negative, positive, zero or some combination thereof.
It's clear that if we allow the user to type the negative 1 for the grid size, it doesn't make any sense. So, let's force the user to give the program a positive value.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int n = get_int("Size: ");
while (n < 1)
{
n = get_int("Size: ");
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}The code here is the better design because it only has two requests for the information. However, we are using two identical lines, which is not ideal.
That is the best time to introduce the third loop: the do-while loop.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}The do-while loop is in C, and other languages like Python don't have it. Even though the code above seems weird, we have to declare the variable at the top and then check it below. It is the cleanest way to achieve the logic so far.
A general piece of advice within programming is that we should never fully trust the user. They will likely misbehave, typing incorrect values where they should not.
We can protect our program from bad behavior by ensuring the user's input satisfies our needs (defensive programming).
Comments
Leave a note
In Scratch, there was the ability to leave yellow sticky notes so we could add citations or explanations.
There are a couple of ways to write comments in C, and in general, comments are for ourselves or colleagues as to what the shared code is doing and why or how.
For instance, we can leave our first note as follows:
int main(void)
{
// Get size of grid
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
...
}Notice the comments begin with a // and involve placing // into the code followed by a comment. It's just an explanatory remark in terse English that generally explains the next chunk of code.
int main(void)
{
// Get size of grid
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
// Print grid of bricks
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
printf("#");
}
printf("\n");
}
}There is another comment to ourselves that makes the code more understandable by adding some English explanation thereof.
Comments are the fundamental parts of a computer program, and they help us understand the program for ourselves and others when we collaborate with our code.
Typically, each comment is a few words or more, providing the reader an opportunity to understand what is happening in a special block of code. Further, the comments are a good reminder for us later when we need to revise our code.
Abstraction
Abstract existing blocks
Suppose we don't know where to begin with our code, but we have instructions or comments for the program.
int main(void)
{
// Get size of grid
// Print grid of bricks
}Comments are a good way to get started because they can be an approximation of pseudocode. And the code above really just represents how our program or function should work.
int main(void)
{
// Get size of grid
int n = get_size();
// Print grid of bricks
print_grid();
}
int get_size(void)
{
int n;
do
{
n = get_int("Size: ");
}
while (n < 1);
return n;
}
void print_grid(int size)
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
printf("#");
}
printf("\n");
}
}
First function get_int()
We created a function that gets the size that the user wants and doesn't take any input but returns an integer. This is the syntax of C, and we will learn that in another part.
Another term here is a return, which means the function will hand back to any function that uses that function the value in question.
Notice how we use this function in main, just like with the get_int() from the CS50 library, calling the function. Nothing is in the parentheses, but we are using the assignment operator = to copy the return value into variable n.
Second function print_grid()
The second function just needs to print, which we call it, and has a side effect.
So we put void to say it has no return value, but it takes an argument (int size). An argument is an input, and the syntax for this in C is like this: name the type of the input and the name of the variable.
The name can be anything. As we know, we are going to use the n here, so it could be (int n), but we will use size to distinguish.
The content of this function is the same as the previous logic, except we use size instead of n. Additionally, we can arbitrarily move the codes to the bottom as we did in Scratch to clean up the workspace.
Now we have abstractions, and the puzzle pieces like red blocks exist in the workspace. However, C is a little naive; it reads top to bottom and considers the function doesn't exist.
We can move all the created functions to the top and place the main function at the bottom, but that doesn't look great and takes longer to find the main function.
Since it's not a clear solution, what solution can we imply?
int get_size(void);
void print_grid(int size);
int main(void)
{
// Get size of grid
int n = get_size();
// Print grid of bricks
print_grid();
}
...Copy and paste the first line of each function and place it at the top. With this syntax, we can tease the compiler by giving it just enough of a hint at the top of the file.
That's like telling the compiler that these top functions don't exist until later, but the top few lines are the hint that they will exist.
By doing so, we can convince the compiler to trust our program, and those two functions can still be lower in the file below the main.
To sum up, we have three functions. The first function is the main, which calls two functions. The second function, called get_size, includes the sizing logic that we keep using. The third function, called print_grid, has the side-effect, which prints the grid.
Notice that this solution is better designed because the main function has only two lines of code without the comments. Our main function can remain short because we abstracted away or factored out the essential problems within our program.
Operators and Types(short)
Mathematical Operators
C indeed supports numerous mathematical operators, via which we can do four arithmetic operations, including calculating the remainder.
+for addition and-for subtraction*for multiplication and/for division%for remainder
Create our own calculator
Let's create our calculator to practice the operators above.
Notice we implemented a simple addition calculator, and it works as expected. However, sometimes, we are going to bump up against the limitations.
Try to add 2 billion for x and 2 billion for y in the calculator.
Clearly, that is not the answer or what we expected. Why might this actually be?
Integer Overflow
It turns out each computer has memory or RAM, the random access memory, and we only have a finite amount of memory inside our computers.
No matter how high we want to count, there will be a limitation we can count because we only have a finite amount of memory; in other words, we don't have an infinite number of zeros and ones.
Computers typically use as many as 32 bits in zeros or ones to represent an integer. For instance, the smallest number we can represent using 32 bits would be zero. Ideally, the biggest number we can represent by changing all 32 zeros to ones gives us a number that roughly equals 4 billion. (2^32 == 4294967296)
However, in general, we need to represent negative numbers. Hence, we can't count from 0 to 4 billion. Instead, we've got to split the difference and allocate half of those patterns of zeros and ones to negative and positive numbers.
In fact, if we use 32 bits, the highest most computers could count in a program like C using an int would be roughly two billion. (2147483648 == 2^32 / 2).
But we have the flip side of that we could also now use different patterns of bits to represent negative numbers as low as negative two billion. (-2147483648)
The implication is that if we only have a finite number of bits and can only count so high, we will run out of bits at some point.
We call this encounter an integer overflow. Where we want to use more bits than are available, as a result, we overflow the available space.
Suppose we have a computer that uses 3 bits. As soon as we get to 7, the next number in the computer is going to be 0 or worse, it might be a negative value. There is no room to store the fourth bit, so the picture above grayed out the 1 and the integer is overflowed.
Types
To address the problems above, we can use the type long, which refers to the longer integers with more bits available.
We can now fix our previous calculator to this:
Recall the
format codewe learned. Same as the%i or %s, there are many types of format code for each data type.
Notice the error disappears because the long or the long integer uses 64 bits, and we have enough spare bits.
In fact, a long can count up to roughly 9 quintillion (quintillion == 10^18), but it too is ultimately going to be finite, and numbers can overflow.
Truncation
There's another problem we might run into when we deal with math involving floating point values, which we call truncation.
Let's change and recompile the calculator program function to division and do the following:
Is the answer right? Well, one divided by three should be 0.33333... or at least 1/3, not 0.
That happened because the answer was supposed to give us the fraction or a floating-point value with a decimal point, so we can't continue to use the integers or longs(long integers).
We can solve this problem by changing the format code from %li to %f. One step further, let's define another z variable as a float and calculate two integers and pass it to the printf function
Again, we still have the 0.00000. At least we can see the decimal point, but it seems that our code already truncated the value 1/3.
To get around this, we can use a feature called type-casting - convert one data type to another by explicitly telling the compiler that we want to do so.
The problem here is that C still treats x and y as integers with no decimal point and divides one by the other. Therefore, it has no room for any numbers after a decimal point.
Let's use a slightly new syntax with parentheses to specify that we want to convert x from a long to a float.
Notice the result of division z had the value of float/float, and the output has a desired format, although it only shows limited numbers of 3s.
Floating point imprecision
When we are manipulating numbers in a computer using a finite amount of memory, we might run up against another challenge. Besides integer overflow and truncation, this problem is known as floating-point imprecision.
We learned that we can't represent as big as we want using int or long alone because of the upper bound. Similarly, there is a boundary on how precise our numbers can be.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
long x = get_long("x: ");
long y = get_long("y: ");
float z = (float) x / (float) y;
printf("%.20f\n", z);
}Notice that our format code has now changed to %.20f, indicating that the output should show 20 decimal point numbers after the decimal point.
The answer goes even worse at this point, with the weird approximation. As we all know, the answer should be the infinite number of 3 after the decimal point.
This issue of floating-point imprecision happened because we only have a finite number of bits or a finite amount of memory; the computer can only be precise intuitively.
Hence, the computer is given a way to implement these floating-point values in some way because the computer cannot represent infinite numbers.
So, the number given in the terminal is essentially the closest approximation the computer can represent.
There is an alternative way to solve this problem with another data type, double, which gives us twice as many bits as a float.
Notice that the answer has more threes after the decimal point, which means a more precise number. We can't get the perfect infinite number because of the memory limitation, but we can get a precise number as much as the memory allows.
Y2K
Switch our gears to the real world; this memory issue still exists in our daily lives.
Back in 1999, the world came to realize that storing year information in software using only two digits may not have been the best idea as we approached the year 2000.
By then, instead of storing 1 9 9 9 to represent the year, a lot of computers used 99 for reasons of space and cost.
The problem is that if systems were not updated by 1999 to support 2000, the computers might face the integer overflow and add 1 to the year in their memory.
For instance, it should be 2000, but if the computers use two digits to represent the years, they might mistake the year and take the year 1900 instead.
Now we are in 2023, and as we understand more about the limitations of code and computing, did we overcome this issue?
Turns out we will run up against the same issue on Jan 19, 2038. In 2038, we will have run out of bits in most computers currently to keep track of time.
Years ago, humans decided to use a 32-bit integer to keep track of how many seconds had elapsed over time. They chose an arbitrary date in the past - Jan 1, 1970 - and started counting seconds from there on out.
Hence, if a computer stores some number of seconds, that tells the computer how many seconds have passed since Jan 1, 1970.
Unfortunately, using a 32-bit integer, we eventually overflow the size of that variable. Potentially, if we don't make progress as a society and as computer scientists, an integer in the system might overflow on Jan 19, 2038. This could cause the size of that particular integer to overflow, bringing us back computationally to Dec 13, 1901.
Everything we've discussed in this lesson has focused on various building blocks of our work as a programmer.
Also, those building blocks will be a guide to us for this question: How does one approach a computer science-related problem?
Data Types
Define variable verbally
To create a variable, we need a special syntax for each programming language. In C, we use the syntax like this:
We can verbally express the variable, like the picture above. We want to create an integer variable named calls that gets the value 4. Where the integer is the data type, the calls is the variable name, the gets is the equal sign, and the value 4 is the integer call's value 4.
Int
There are many data types in programming, and modern programming languages like Python or JavaScript don't necessarily specify the data type.
But in C, we need to declare the variable type every time we create a variable.
The first data type is int, which is the integer. The int data type is used for variables that will store integers.
Remember that the integers always take up 4 bytes of memory, which is 32 bits because there are eight bits in a byte.
This means the range of values that an integer can store is limited by what can fit within 32 bits' worth of information.
We know there are negative and positive integers, so we need to split up that range of 32 bits to each get half of the range.
Hence, the range of value of an integer is -2^31 to the 2^31 - 1 because we need a spot for zero. (2^32 / 2 == 2^31)
That is roughly about negative two billion to positive two billion.
Unsigned Int
There is another int we should look at, which is called unsigned int. The unsigned integer is not a separate type of variable.
Rather, unsigned int is a qualifier. It modifies the data type of integer slightly. Integer is not the only one, and we can use unsigned other data types.
The unsigned var effectively doubles the positive range of variables of that type, in this case, an integer, at the expense of disallowing any negative values.
Notice the range is all positive. We can use this unsigned int if we know that the value will never be negative.
Chars
The char data type is used for variables that will store single characters.
Characters always take up one byte of memory, which is 8 bits. This means they can only fit values in the range of -2^8 == -128 to 2^8 - 1 == 127.
Thanks to ASCII, they create a way to map those positive numbers from 0 to 127 to various characters that all exist on our keyboard.
For example, the capital A maps to the number 65 and the lowercase a is 97. The character 0 is 48, and notice that the number 0 and character 0 mean slightly different in this context.
Float
The next major data type is floating point numbers, where the float data type is used for variables that will store floating-point values, also known as real numbers.
They are basically the numbers that have a decimal point in them. Floating point values are also contained within 4 bytes of memory.
It is complicated to describe the range of a float because it is not clear or intuitive.
Suffice it to say we have 32 bits to work with the floating number like pi has integer part 3 and decimal part 14159.... Suppose we need to represent all of the integer and floating-point values, and the decimal part gets longer.
pi = 3.1415926535 ...In that case, if the number has a large integer part, the number might not be able to be precise with the decimal part. Hence, the float has a precision problem.
Double
Fortunately, there is another data type called double, the double data type is also used for variables that will store floating-point values.
The difference is that doubles are double precision, which means they can fit 64 bits of data or 8 bytes of memory.
With an additional 32 bits of precision, we can be much more precise with the decimal point. If we are working with a number that has a long decimal point and the precision is important, use double over float.
Void
The type void is not a data type, but it is a type. We can't create a variable of type void and assign a value to it.
Functions like printf are a generic void function, and it has a void return type, meaning they don't return a value.
Recall that printf just prints the value, and we called that a side effect, but it doesn't give us the value back.
int main(void)We probably feel comfortable with the code above. This time, the void is a parameter list. The parameter list of a function can also be void, which means that the function main doesn't take any parameters.
More complicated details are in a later course, but suffice it to say, think of the void serving as a placeholder for nothing.
Boolean and String
The above five are the primary types we will encounter in C, but there are two additional types we need to know for general programming.
Boolean
The bool data type is used for variables that store a Boolean value. More precisely, a Boolean value is capable of holding only two different distinct values - True and False.
Many modern languages have Boolean as a standard default data type, but in C, it is not a built-in data type. So we need to add a header file, the library, the same as the stdio.h.
We use cs50.h in this course, and outside of this course, we can include the stdbool.h library to use True and False.
String
The other major data type is string, which is the collection of characters, and they can be words, sentences, paragraphs and the like.
The string data type is used for a variable that will store a series of characters.
The library cs50.h provides the string data type, and if we need to use string without the cs50.h, we can include the string.h library.
Creating a variable
To bring a variable into existence, we can simply specify the data type of the variable and give it a name like this:
int number;
char letter;In the case of creating multiple variables of the same type, we only need to specify the type name once and then list as many variables as we need.
int height, width;
float sqrt2, sqrt3, pi;Notice we can split the float code into three separate lines, but consolidating three lines in a single line of code makes the code clean and short.
Using a variable
After we declare the variable, we no longer need to specify that variable's data type. In fact, if we inadvertently re-declare the variables with the same name, it might cause weird errors in the program.
int number; // declaration
number = 17; // assignment
char letter;
letter = 'G';Notice that the code above is how we can create a variable. We can also simultaneously declare and assign the value of a variable, thus consolidating the above in one step.
// We can call this initializing
int number = 17;
char letter = 'G';Operators
Arithmetic operators
In order to manipulate and work with variables and values in C, we have a number of operators at our disposal that we can use.
We learned that we could do basic math operations like add, subtract, multiply, and divide numbers in C. Guess the value of x when the x is initialized and the value of the last x.
int y = 10;
int x = y + 1;
x = x * 5;Another important operator is % and is called the modulus operator. The modulus operator gives the remainder when the number on the left of the operator is divided by the number on the right.
int m = 13 % 4 // m is now 1The modulus operator is frequently used when calculating even and odd numbers or random numbers.
For instance, if the random number generator gives us a number from zero to some enormous number, we may only need a number from 0 to 20. We use the modulus operator here on that giant random number, divide it by 20 and get the remainder. The remainder can only be a value from 0 to 19.
It will become more handy as we go through the lecture and deal with more practice problems.
Short syntax
C also provides us with a shorthand way to apply an arithmetic operator to a single variable.
x = x * 5
x *= 5Notice that the above two lines of code are identical, but the second line is the shorter version to express. We don't need to use it but have to be familiar with this syntax to read and understand the code like this.
We can refine the shorthand syntax even further when incrementing or decrementing a variable by one. The below is such a common case in C, especially when using a loop.
x++;
y--;The first line code above has the same meaning as x = x + 1 or x += 1, but we have even short-handed that to x++. Those three codes are the same code but have different styles.
Boolean Operators
Boolean expressions fall into the overall category of operators. However, unlike arithmetic operators, Boolean expressions are used to compare values.
It evaluates one of two possible values - True or False.
We can use the results of Boolean expressions in a lot of ways in programming. For example, we can use it to decide which branch down our code conditional, so to speak. One familiar example might be the loop. When the condition is false, we keep doing some behavior over and over again.
Sometimes, when working with Boolean expressions, we will use variables of type bool, but we don't always have to declare it.
In fact, C treats every non-zero value as True and zero as False.
#include <stdbool.h>
int n = 1, 2, 3 // true
int m = 0 // falseThere are two main types of Boolean expressions: logical operators and relational operators.
Logical Operators
Logical AND (&&) is true if and only if both operands are true; otherwise, it is false.
| x | y | (x && y) |
|---|---|---|
| true | true | true |
| true | false | false |
| false | true | false |
| false | false | false |
Logical OR (||) is true if and only if at least one operand is true; otherwise, it is false.
| x | y | (x || y) |
|---|---|---|
| true | true | true |
| true | false | true |
| false | true | true |
| false | false | false |
The final logical operator is NOT (!), which inverts the value of its operand.
| x | !x |
|---|---|
| true | false |
| false | true |
It might sound weird initially, where we call if x is true, then not x is false and if x is false, then not x is true.
Relational Operators
These are familiar math operators, behave as we expect them to, and appear syntactically similar to elementary arithmetic.
(x < y) // Less than
(x <= y) // Less than or equal to
(x > y) // Greater than
(x >= y) // Greater than or equal toTwo other important operators test two variables for equality and inequality.
(x == y) // Equality
(x != y) // InequalityA common mistake most beginner programmers make is to use the single equal sign (=) for the equality comparison operator (==). It will lead to weird behavior in our code, so we need to keep that in mind.
Conditionals
Conditional Branch
Conditional expressions allow our program to make decisions and take different forks in the road depending on the values of the variables or the user inputs.
C provides a few different ways to implement conditional expressions, which we sometimes call a conditional branch. Some of which likely look familiar from Scratch.
If
Recall that in Scratch, we had an if-block with the C-shape, and all of the code inside that if-block will execute if the condition is true.
In the same manner, we have an if statement with the same structure as the block above. One of the Boolean expressions we learned goes inside of parentheses, and if the Boolean expression is true, the code inside of the curly braces will execute in order from top to bottom.
if (boolean-expression)
{
}If the Boolean expression is false, we will skip over everything in between curly braces because we only want to go down that fork in the road if the Boolean expression is true.
If-else
The block below is the Scratch's Oscar time from the first lecture.
The block above is analogous to the conditionals in C. If the Boolean expression evaluates to true, all lines of code between the first set of curly braces will execute.
if (boolean-expression)
{
}
else
{
}Indeed, if the Boolean expression evaluates to false, all lines of code between the second set of curly braces will execute in order from top to bottom.
Conditional Chain
In C, we can create an if-else if-else chain like this:
if (boolean-expr1)
{
// first branch
}
else if (boolean-expr2)
{
// second branch
}
else if (boolean-expr3)
{
// third branch
}
else
{
// fourth branch
}All of the branches above are mutually exclusive, which means we can only ever go down one of the branches. It is also possible to create a chain of non-mutually exclusive branches.
if (boolean-expr1)
{
// first branch
}
if (boolean-expr2)
{
// second branch
}
if (boolean-expr3)
{
// third branch
}
else
{
// fourth branch
}In this case, only the third and fourth branches are mutually exclusive. The else binds to the nearest if only. We can satisfy the first condition, the second condition, and the third or fourth condition. Then, we go down the first and the second branches and choose between the third or fourth branches.
Switch statement
Another important conditional statement is a switch() statement, which permits the specification of distinct cases. Instead of relying on Boolean expressions, switch statements allow us to make decisions for our program.
#include <cs50.h>
int x = GetInt();
switch (x)
{
case 1:
printf("One!\n");
break;
case 2:
printf("Two!\n");
break;
case 3:
printf("Three!\n");
break;
default:
printf("Sorry!\n");
}For instance, the above program asks the user to provide input and switching. What it does is the program changes or switches the behavior depending on what the user typed at the prompt.
It's important to break each case. Otherwise, we will fall through. If we didn't have any breaks between each case, and if the user typed 1, the program prints all of the cases.
In fact, sometimes omitting the break can be useful, and here is an example:
#include <cs50.h>
int x = GetInt();
switch (x)
{
case 5:
printf("Five!\n");
case 4:
printf("Four!\n");
case 3:
printf("Three!\n");
case 2:
printf("Two!\n");
case 1:
printf("One!\n");
default:
printf("Blast-off!\n");
}Notice that if the user types 4, the program will execute all of the print below the case 4, including four!. We call this behavior a fall through each case.
Ternary Operator
The last conditional statement is a ternary operator or ? :.
// regular
int x;
if (expr)
{
x = 5;
}
else
{
x = 6;
}
// ternary
int x = (expr) ? 5 : 6;Notice that the above two code snippets act identically. The ternary operator (? :) is mostly a cute trick but is useful for writing trivially short conditional branches.
The first variable after the question mark is what x's value will be if the expression is true. The second variable after the colon is what x's value would be if the expression is false.
Loops
While loop
The while-loop can be what we call an infinite loop, similar to the forever block in Scratch.
while (true)
{
}The lines of code between curly braces will execute repeatedly from top to bottom until the program finds a way to break out the loop with a break statement. It is the same as the break in switch statement, or otherwise kill our program manually with ctrl + c.
Notice that the while loops are not always infinite because we can replace the Boolean expression with a little more useful than just true.
while (boolean-expr)
{
}The code above is pretty much analogous to the repeat until block in Scratch, although they are slightly different.
In C, if the Boolean expression inside the while loop evaluates to true, the lines of code between curly braces will repeatedly execute until the Boolean expression evaluates to false.
The difference between the repeat until block in Scratch is that the Scratch block repeats until the expression is true. Meanwhile, the while loop in C continues to do something inside the loop until the Boolean expression is false.
int x = 0;
while (x < 10)
{
x++;
}Notice that the code above will increment x by one until x becomes 10 because 10 is not less than 10.
They are quite similar, but there is a little distinction. So, be careful, especially as we make our first foray from transitioning to Scratch into C.
do-while loop
The do-while loop executes all lines of the code between curly braces once, and then it will check the Boolean expression.
do
{
}
while (boolean-expr);If the Boolean expression is true, the loop will go back to the top and repeat the process in curly braces until the Boolean expression is evaluated to be false.
The biggest difference between the while loop and the do-while loop is that the do-while loop is guaranteed to run at least one time.
for loop
The for-loop might look syntactically unattractive, but for-loops are used to repeat something a specific number of times.
As we know, there is a repeat block in Scratch, and it is analogous to the for-loop down below:
for (int i = 0; i < 10; i++)
{
}Let's break it down to what is happening in the loop step by step.
- The first thing that happened is the counter variable
iis set. We declared a variable type as an integer, namedi, and set the value to0. - The second thing is to evaluate the Boolean expression immediately. The body of the loop will behave, followed by the evaluation(true/false).
- Lastly, the counter variable is incremented, and then the loop will check the Boolean expression again until the
i's value becomes10in this loop.
for (start; expression; increment)
{
}Notice we can think of the for-loop like the pattern above.
Use cases
To sum up, we will review each loop and learn where to use those loops.
- Use the
while loopwhen we want a loop to repeat an unknown number of times and possibly might not run at all.
The most common use case is running the game's control flow. We don't know how long the user is going to play, but we want to keep doing the same thing. - The
do-while loopis quite similar to use when we want a loop to repeat an unknown number of times, but at least once.
A common use case is prompting the user for input. When we ask the user to provide a positive integer, it will ask the user at least once. - The
for-looptypically can be used when we want to repeat a loop a discrete number of times, though we may not know the number at the moment when the program is compiled.
We can use it if we have a loop that waits for the user input number. The program will execute the given number of times after receiving the input.
Although we outlined these use cases, we should know that we can interchange all of these loops in most circumstances.
Command Line
Using the Linux Command Line
We briefly learned about the commands previously. Again, that is a keyboard-based command for working with the IDE or any UNIX-based operating system, including Linux and MacOS.
As a programmer, we will likely be using our terminal window frequently instead of GUI, the graphical user interface.
ls
The command ls is short for list, which gives us a readout of all the files and folders in the current directory.
Notice on the left side, we have a GUI, which we can use to interact with the mouse like we normally do with our computer. We are in the pset1 directory, and the ls command shows the list of files and folders exactly the same as the GUI.
On the bottom right, we typed ls, and it shows the files with three different colors.
The gray files indicate the text files or the source code like the mario.c in the code space above.
The blue files indicate the folders and the green file indicates the file is executable, meaning we can run the program from the terminal.
cd <dicrectory>
The command cd is short for change directory, allowing us to change the current directory to <directory> or navigate between directories at the command line as opposed to double-clicking on folders.
As an aside, the name of the current directory is always ., and the name of the directory one level above the current directory is ..
One good example is ./mario, which we used to run the program. If we look at the command closer, . indicates the current directory, and by the following /mario command, we are executing the file called mario.
If we are ever curious about the name of the current directory, we can type pwd, which stands for the present working directory.
Notice we used cd to go into the population directory, and the path has changed accordingly.
If we want to go back to the pset1, we can do this:
We can see that pwd shows the current path. Also, the terminal indicates that the cd pset1 command can't be used because the directory pset1 is not in the current directory.
After using the cd .. command, we navigated to the one level above and all the files as before.
Another good use case is the picture above. Suffice it to say we are in some directory, but we don't know where we are because of the complicated working tree.
Here, we are in the population directory, and once we want to go to the root or home directory, which means where the pset1 belongs, we can use cd and nothing else.
We can use ../.. because the population directory is two levels deep from the root, but if we are five or six levels deep, it is quite hard to escape. In that case, we can simply escape and go home directly with this command.
mkdir <directory>
The command mkdir is short for make directory, and this command will create a new directory in the current folder.
We were in the home directory, and I suppose we have now finished with pset1 and want to create pset2 to work with.
We can run mkdir pset2 and check the current directory. Indeed, the pset2 directory has been made and goes inside with cd pset2 to work with the pset2 folder.
cp <source> <destination>
The command cp is short for copy. Unlike other commands we have seen above, it takes two arguments: A source, the name of the file that we want to copy, and a destination, where we want to copy the file to.
Suppose we want to make another content that is relative to mario. We can do this by going to the GUI, copying the file and pasting the file, but with the cp command, we can do it in one step.
Notice that we copied the whole code from mario.c to luigi.c with the cp command. Once we manually open luigi.c, it has exactly the same code as mario.c.
As we see, we can't use the cp command with the directory. It turns out that when we copy the directory with other stuff inside of it, the cp command doesn't know what to do with it.
We need to explicitly tell the terminal to copy the directory and copy every folder and file that exists inside of it. In other words, the terminal needs to recursively dive down into the pset1 folder and make a copy of everything in there.
Run the command cp with -r, which stands for recursive, and the command should be cp -r pset1 pset3. See the command line in the picture. The pset3 folder has been created, and the files are the same as pset1.
rm <file>
The command rm is short for remove. This command will delete the file after it asks to confirm (y/n) to delete it.
Be very careful because there is no recycle bin like for Windows or Mac OS. Once the file is deleted, it is gone. There is no way to recover it.
Let's remove the luigi.c that we previously created(if not, we can create it first).
Notice that the terminal asks to confirm the deletion, and think of it as the pop-up message in Windows or MacOS when we try to delete some file. Type yes or y, which are essentially the same; now we can see the file is gone.
If we are really sure we want to delete the file and don't want to be asked the question, we can skip the confirmation by specifying an extra flag, as we did with the cp command.
Now, suppose we want to delete the hello.txt. The terminal won't ask the question with the rm -f command.
For the next step, let's say we don't want the pset3 directory, so let's remove the copied folder pset3; how can we do that?
Same with the cp -r, we run rm -r, which will recursively delete the directory and everything inside.
Every time the evaluation meets the files, it asks for confirmation, and we have to answer all the questions, like the picture above.
One last variation on the rm command is rm -rf. -rf means we want to remove the directory recursively and forcibly. As in the picture above, it asks the question again and again until it deletes all the files in the directory and the directory itself.
But that's quite a disaster when we have a big project that contains more than 100 files in one directory. We can avoid the repeated confirmation by adding the -rf flag to the command.
Be really careful and use this command at your own peril because it can lead to some disastrous consequences if we delete the wrong thing.
mv <source> <destination>
The last command is the mv, which is short for move, and this command is basically equivalent to renaming a file. It moves a file from one location to another, from the source to the destination.
Sometimes, we accidentally name a file with the wrong name. One way to rename a file is by using the cp and rm commands.
Notice that we copied all the code into greedy.c and deleted the greddy.c. However, that's a multi-step process, and there is a better way to do this.
We used mv greedy.c greddy.c to go back to the original version. We didn't have to copy and remove the file, but we were able to rename it.
Magic Numbers
In general, it's a bad habit to write constants into our code. In doing so, when we actually do write a constant into the code, it is sometimes referred to as using magic numbers.
Suffice it to say we have a pseudocode version of the function deal_cards, which deals with the cards.
card deal_cards(deck)
{
for (int i = 0; i < 52; i++)
{
// deal the card
}
}It deals with the deck as its parameter and will output a single card. The trump card has 52 cards in one deck, and we loop through the cards and deal a card.
What is the magic number here, or more importantly, what is the problem in this code snippet? - It's 52. Intuitively, we could understand a deck of cards contains 52 cards.
However, in our program, the number just floats around there. This means all of a sudden, there's a 52, and other people may not know where it comes from.
One way to resolve this problem is to declare the deck size like the below explicitly:
card deal_cards(deck)
{
int deck_size = 52
for (int i = 0; i < deck_size; i++)
{
// deal the card
}
}By setting int deck_size to 52, we can fix the problem, which means the variable deck_size gives some symbolic meaning to the constant.
But, this method actually introduces another problem that might not be immediately apparent.
Even if the variable is declared globally, if one of our functions shares the deck_size and that function deals with the card manipulation that inadvertently changes the deck_size, that could spell trouble.
In simple terms, if the variable deck_size increases by one or decreases by one, the whole deck_size changes, which also affects the first function's result.
Preprocessor Directive
To prevent the magic number issue, C provides a preprocessor directive known as a macro for creating symbolic constants.
We have actually seen this preprocessor directive throughout this course, which is the #include.
The #include is another example of macro, and it is similar to copy/paste.
The way to create symbolic constants or give a name to a constant that has more meaning is this:
#define NAME REPLACEMENTWe don't put a semicolon at the end of this preprocessor directive, and if we recall, the #include <stdio.h>, it doesn't have a semicolon either.
When our program is compiled, the compiler goes through our code and replaces every instance of the word NAME with the value in REPLACEMENT.
Analogously, if #include is copying/pasting, the #define is similar to finding/replacing, like the feature in Microsoft Word.
For example, suppose we want to replace the word PI with 3.14159265 because the number 3.14159265 is a magic number. We intuitively know the number is pi, but when we use the number itself directly in our code, it's just a sudden number that came from nowhere.
Maybe we can give it a little more symbolic meaning instead of using a magic number. We will declare a PI and set the value to 3.14159265.
When the program compiles, the preprocessor directive will go through the code, and every time it finds the word PI, it will replace the word PI with the number 3.14159265.
We don't have to type the mouthful number every time we need the value of PI. Instead, we can use the word PI in the place where we need it.
The preprocessor directive is not limited to the number substitution only. We could replace a word with this: #define COURSE CS50.
Notice we use capital letters when we define symbolic constants. That's the convention that makes clear that our code's capital letter element is a defined constant. It's not required, but if it was lowercase, there might be confusion with the regular variable, especially for people who see our code.
To apply this particular solution to our example, it will look like this:
#define DECKSIZE 52
card deal_cards(deck)
{
for (int i = 0; i < DECKSIZE; i++)
{
// deal the card
}
}We first define DECKSIZE to 52. Then, we can use 52 anywhere in our code. It's a lot more intuitive, and we can't manipulate a constant. Hence, it is safer than declaring a variable.
We can change a variable to something like the previous int deck_size = 52 case. However, we can't increase or decrease the defined value 52. A 52 is always 52 unless we change the defined value at the top.
📌 Takeaway
- When using a loop, declaring a variable can cause an unpredictable error in the loop. Hence, we use
constto make the variable a constant. - Defensive programming makes our code better designed because it is less vulnerable to mistakes.
- The do-while loop is only in
C, which declares a variable first and triggers the function, then checks the conditional statement. - Abstraction in
Cis much like in Scratch, but the difference is that we have to declare the return type of functions at the top of the program. - Computers typically use 32 bits. With 32 bits, we can represent roughly from 0 to 4 billion.
- Because of negative values, we have to split and allocate half of the bits to each negative and positive number.
- We only have a finite number of bits and can count so high; inevitably, we will run out of bits. We call this encounter an
integer overflow. - To resolve the integer overflow issue, we can use the data type
long, which allows us to add more bits. The long integers can use 64 bits, allowing us to count up to nine quintillion. - We might still run into problems like truncation or floating point imprecision. We can use another data type called
floatto fix the truncation issue. If we need a more precise output, we can use the datatypedouble, which gives the program twice as many bits as afloat. - The issues above are related to memory limitation, and they can occur even in real life, like time tracking for years.
- We can use
unsigned intif we know that the value will never be negative. - The
intandfloattypes take up 4 bytes of memory, andchartakes up one byte of memory. Data typedoubletakes up 8 bytes of memory, which allows 64 bits. - The data type
voidmeans nothing. If it is a return value from the function, the function will return nothing, and if it is a parameter, the function takes no parameters. Ctreats non-zero values asTrueand zeros asFalse.- The difference between a while loop and a
do-whileloop is that thedo-whileloop executes before the evaluation process. - The command line flag
-rstands for recursive, and it recursively executes certain behavior with the command. For instance, the commandcp -rrecursively goes into the directory and copies all the files and folders into another directory. - The preprocessor directive or
#definehelps us to use a constant. Also, by using a constant, we can distinguish constant from regular variables and prevent unpredicted behavior.
💻 Solution
- None
🔖 Review
- We can make a 3x3 size grid by nested loop.
- In general, within programming, we should never trust the user because they will likely misbehave, typing incorrect values where they should not.
- We can protect our program from bad behavior by ensuring the user's input satisfies our needs.
- Comments are the fundamental parts of a computer program, and they help us understand the program for ourselves and others when we collaborate with our code.
- Conditional expressions allow our program to make decisions and take different forks in the road depending on the values of the variables or the user inputs.
- When we create a conditional chain with an
if-elsestatement, every branch is mutually exclusive, which means we can only ever go down one of the branches.
