
들어가며
라우터를 직접 구현해 보고자 라우터를 스터디하다가 BFCache를 알게 되었습니다.
그래서 관련 내용들을 이번에 한번 정리하고 넘어가고자 하여 작성하게 되었습니다.
1. Router
라우터(router)는 컴퓨터 네트워크 간에 데이터 패킷을 전송하는 네트워크 장치이다 - 위키백과
웹 애플리케이션에서 라우터란, URL 주소에 따라 사용자의 요청에 맞게 서버 리소스에 연결하는 역할을 말합니다.
즉, 웹 애플리케이션에서 사용자의 인터페이스와 상호 작용에 따라 다른 뷰나 컴포넌트를 보여주는 역할을 말합니다.
1-1. SPA 에서의 라우터의 역할
- URL 관리 : 브라우저의 URL과 애플리케이션의 뷰 사이를 연결하여 사용자가 URL을 변경하거나 브라우저의 뒤로가기/앞으로가기 버튼을 클릭할 때 알맞는 뷰를 렌더링합니다.
- 컴포넌트 렌더링 : URL의 변화에 따라 해당하는 컴포넌트를 동적으로 로드하고 렌더링하기 때문에 사용자는 페이지를 새로고침 하지 않고도 다양한 컨텐츠를 볼 수 있습니다.
- 상태 유지 : 사용자가 애플리케이션 내에서 이동할 때 그 상태를 유지하는데, 예를들어 사용자가 회원가입을 입력하다가 다른 페이지로 이동 후 다시 돌아왔을 때 기존에 작성했던 내용이 그대로 보존되어야 합니다.
- 데이터 관리와 로딩 : 라우터는 특정 경로에 접근할 때 필요한 데이터를 사전에 로드하는 역할도 수행하는데, 사용자가 프로필 페이지에 접근한다면 그에 맞는 사용자 데이터를 서버로부터 데이터를 받아와 렌더링합니다.
1-2. SPA 라우터의 구현 방식
해시(#)기반 라우팅
이전에는 URL의 해시를 사용해 라우팅을 구현했습니다.
예를 들어 http://example.com/#/user와 같이 URL의 해시 부분을 변경하여 페이지 콘텐츠를 변경하는 방식으로 해시가 변경될 때 페이지는 새로고침되지 않고 자바스크립트를 사용하여 해시 변경을 감지하고 해당하는 동적 변경을 적용할 수 있었습니다.
해시 기반 라우팅은 모든 브라우저에서 호환되며 구현이 간단하다는 장점이 있지만 URL에 해시(#)가 붙어야 했기 때문에 URL이 클린하지 않고 SEO에 좋지 않다는 문제점이 있었습니다.
History API 기반 라우팅
자세한 내용은 MDN의 History API 문서를 확인해주세요
대부분의 현대적인 SPA 프레임워크와 라이브러리는 HTML5 History API를 사용하여 브라우저의 세션 히스토리(session history)에 직접 접근하고 수정할 수 있는 메서드를 제공합니다.
History API는 페이지를 새로고침 하지 않고도 페이지의 내용을 동적으로 변경할 수 있고, 각 상태에 대한 적절한 URL을 제공하기 때문에 SPA 개발에서 매우 중요한 역할을 하며, 사용자가 애플리케이션 내에서 자연스럽게 내비게이션을 할 수 있어 사용자에게 일관된 경험을 제공해줍니다.
그리고 클라이언트 측에서 URL과 상태를 관리함으로써 서버에 대한 요청 수를 줄일 수 있기 때문에 대규모 트래픽이 있는 웹 애플리케이션에서 서버 리소스를 절약할 수 있는 장점이 있으며, 사용자가 브라우저의 내비게이션 버튼을 사용했을 때 애플리케이션의 이전 상태로 돌아갈 수 있게 해줌으로써 사용자 경험이 향상되며 SEO에 유리합니다.
2. 브라우저에서 라우터가 동작하는 방식
- 사용자가 웹사이트의 URL을 주소창에 입력합니다.
- 서버는 응답값(index.html 등)을 브라우저로 전송하고 이때 SPA의 모든 필수 자원들이 한꺼번에 로드됩니다.
- 브라우저는 받은 HTML, JS 등을 실행하여 사용자에게 초기 렌더링 화면을 표시합니다.
- 페이지가 렌더링되면 자바스크립트의 라우터가 초기화되고, 개발자는 라우터를 사용하여 애플리케이션의 경로(URL)과 연결된 컴포넌트를 정의합니다.
- 사용자가 애플리케이션 내의 링크를 클릭하거나 URL을 변경하면 라우터가 감지합니다.
- 라우터는 History API를 사용하여 브라우저의 히스토리 스택에 새로운 상태를 추가하거나 변경하고, 페이지를 새로고침 하지 않고 URL을 변경합니다.
- 라우터는 변경된 URL을 감지하고 미리 정의된 라우터와 매칭하는지 확인합니다.
- 이때, 필요한 경우 라우터는 새 페이지의 데이터를 로드하기 위해 AJAX요청을 보냅니다.
- 라우터는 매칭하는 컴포넌트를 로드하고, 새로운 컴포넌트로 DOM을 업데이트 하여 사용자에게 새로운 페이지를 렌더링합니다.
- 만약 사용자가 브라우저의 뒤로/앞으로 가기 버튼을 클릭하면 라우터는 popstate 이벤트를 통해 이전 또는 이후 상태로 복원하기 위해 히스토리 스택에서 해당 상태에 맞는 URL과, 일치하는 컴포넌트를 다시 로드하고 렌더링합니다.
3. Router 직접 구현하기
3-1. Vanilla JavaScript + TypeScript 로 구현
import Home from "./Home.js";
import Posts from "./Posts.js";
import MyPage from "./MyPage.js";
import NotFound from "./NotFound.js";
import PostDetail from "./PostDetail.js";
type Router = {
path: string;
view: () => string;
result?: RegExpMatchArray | null;
};
const NOT_FOUND_ROUTE: Router = {
path: "/404",
view: NotFound,
};
const pathToRegex = (path: string) =>
new RegExp("^" + path.replace(/\//g, "\\/").replace(/:\w+/g, "(.+)") + "$");
// 현재 url의 주소를 히스토리 스택에 추가
const updateUrlRoute = (url: string) => {
history.pushState(null, "", url);
};
const resolveRoute = (routes: Router[]) => {
const path: string = window.location.pathname;
const matchedRoute: Router =
routes.find((route) => path.match(pathToRegex(route.path))) ??
NOT_FOUND_ROUTE;
renderView(matchedRoute.view());
};
const renderView = (view: string) => {
const appElement: HTMLElement | null = document.getElementById("app");
if (appElement) appElement.innerHTML = view;
};
const getRouter = () => {
const routes: Router[] = [
{ path: "/", view: Home },
{ path: "/posts", view: Posts },
{ path: "/posts/:id", view: PostDetail },
{ path: "/mypage", view: MyPage },
];
resolveRoute(routes);
};
const handleLinkClick = (event: MouseEvent) => {
if (
event.target instanceof HTMLAnchorElement &&
event.target.matches("[data-link]")
) {
event.preventDefault();
updateUrlRoute(event.target.href);
}
};
const setupEventListeners = () => {
const app = document.querySelector<HTMLElement>("#app");
const nav = document.querySelector<HTMLElement>(".nav");
if (app && nav) {
app.addEventListener("click", handleLinkClick);
nav.addEventListener("click", handleLinkClick);
}
window.addEventListener("popstate", getRouter);
};
// 페이지가 처음 로드되면 실행되는 함수, 초기 라우팅 설정
document.addEventListener("DOMContentLoaded", () => {
setupEventListeners();
getRouter();
});4. BFCache (Back-Forward Cache)
BFCache란, 사용자가 브라우저의 뒤로가기 또는 앞으로가기 버튼을 사용할 때 이전에 방문했던 페이지를 빠르게 로드하기 위해 페이지의 전체 상태를 메모리에 저장하는 브라우저의 기능입니다.
사용자가 다른 곳으로 이동하는 순간 현재 페이지의 전체 스냅숏(자바스크립트의 힙 포함)을 저장하는 메모리 내부 캐시이기 때문에, 사용자가 다시 이전 페이지로 돌아오려고 할 때 브라우저는 메모리에 저장해둔 전체 페이지를 사용해서 페이지를 빠르고 쉽게 복원해주기 때문에 서버 요청 없이 즉시 페이지를 렌더링 할 수 있습니다.
- BFCache가 활성화 되지 않은 경우
- 이전 페이지를 로드하기 위해 새로운 요청이 시작됩니다.
- 해당 페이지가 재 방문에 얼마나 최적화되어있느냐에 따라 다르지만 브라우저는 방금 다운로드한 일부(또는 모든) 리소스를 다시 다운로드하고, 파싱하고, 실행해야할 수 있습니다.
- BFCache가 활성화 된 경우
- 이전 페이지 로딩이 기본적으로 즉시 수행되며, 전체 페이지를 메모리에서 복원할 수 있기 때문에 네트워크 요청을 전혀 사용하지 않습니다.
4-1. BFCache와 HTTP 캐시의 차이점
BFCache는 메모리에 있는 전체 페이지의 스냅숏(자바스크립트 힙 포함)을 저장하며, BFCache의 목적은 사용자가 브라우저의 뒤로가기 및 앞으로가기 버튼을 사용할 때 페이지 로딩 시간을 줄이기 위해 사용합니다.
HTTP 캐시는 이전에 보냈던 요청의 응답만 저장하며, HTTP 캐시의 목적은 웹 리소스(HTML, CSS, JavaScript, 이미지 등)를 브라우저나 서버에 저장하여 동일한 리소스에 대한 재요청시 빠르게 제공함으로 네트워크 사용량을 줄이고 페이지 로딩 시간을 개선하는데 목적이 있습니다.
BFCache의 작동방식
- 페이지의 전체 상태를 메모리에 저장하며, 페이지의 전체 상태란 HTML, CSS, JavaScript의 실행 상태, 스크롤 위치 등 현재 페이지의 모든 것이 포함됩니다.
- 사용자가 뒤로가기나 앞으로가기를 통해 페이지로 돌아올 때 BFCache는 저장된 페이지 상태를 불러와서 즉시 렌더링하기 때문에 서버 요청 없이 페이지를 빠르게 로드할 수 있습니다.
- BFCache는 사용자가 페이지를 벗어났다가 다시 돌아올때만 활성화되며, 새로운 페이지 로드에는 사용되지 않습니다.
- 브라우저가 자동으로 관리합니다.
HTTP 캐시의 작동 방식
- HTTP 캐시는 HTTP 헤더를 사용하여 리소스의 캐싱 정책을 제어합니다.
Cache-Control,Expires,Last-Modified,ETag등의 헤더가 사용됩니다. - 브라우저는 한 번 로드된 리소스를 캐시에 저장하고, 동일한 리소스에 대한 요청이 있을 때 캐시된 버전을 제공하여 리소스 로딩 시간을 줄입니다.
- 서버 설정에 따라 캐시된 리소스가 갱신되거나 만료되는 조건을 정의할 수 있습니다.
- 개발자가 HTTP 헤더를 통해 직접 관리할 수 있습니다.
즉, BFCache는 뒤로/앞으로가기 에서만 작동하며, HTTP 캐시는 일반적인 페이지 방문과 리소스 요청에서 항상 작동할 수 있으며, BFCache는 페이지 전체 상태의 빠른 복원을 목표로 하고 HTTP 캐시는 개별 웹 리소스를 캐싱하여 네트워크 요청을 줄이고 일반적인 페이지 로딩을 빠르게 하는데 초점을 둔다는 차이점이 있습니다.
4-2. 만약 페이지가 BFCache에 있는 동안 setTimeout() 호출이 있다면?
현재 페이지에서 setTimeout 같은 timer 함수가 아직 실행 완료되기 이전에 사용자가 뒤로/앞으로가기 버튼을 클릭해서 페이지를 벗어난다면 브라우저는 보류중인 timer, promise 등의 실행을 일시 중지하고(기본적으로 자바스크립트 태스크 큐에 있는 모든 작업들) 페이지가 BFCache로부터 복원이 되었을 때 다시 실행하게 됩니다.
굉장히 좋아 보이지만 때로는 굉장히 복잡한 결과나 이해할 수 없는 행동을 만들 수 있는데, 만약 브라우저가 IndexedDB transaction 의 일환인 작업을 중지한다면 다른 탭에서도 접근할 수 있는 IndexedDB의 특성상 다른 탭에서 페이지를 열었을 때 영향을 미칠 수 있기 때문에, 브라우저는 IndexedDB 트랜잭션 또는 다른 페이지에 영향을 줄 수 있는 API 호출 중에는 페이지를 캐싱하려고 하지 않습니다.
4-3. BFCache API 살펴보기
BFCache는 브라우저가 자동으로 하는 최적화 방법이기 때문에 이 동작을 잘 이해하면 페이지를 최적화하거나 성능을 측정하고 조정하는데 도움을 얻을 수 있습니다.
pageshow
- 페이지가 정상적으로 로딩될 때 발생
- BFCache로부터 페이지가 복원되었을 때 발생
event.persisted속성이true일 경우 페이지가 BFCache에서 복원된 것이고 false일 경우 새로 로드되거나 새로고침된 상태이기 때문에 꼭 pagehide가 되었다고 볼 수 없습니다.
window.addEventListener('pageshow', function(event) {
if (event.persisted) {
console.log('이 페이지는 BFCache에서 복원되었습니다.');
} else {
console.log('이 페이지는 새로 로드되거나 서버에서 새로 고침되었습니다.');
}
});pagehide
- 페이지가 정상적으로 언로드 될 때 (떠날 때)
- BFCache로 들어가는 순간, 즉 페이지가 캐시로 저장될 때 발생
event.persisted속성이true일 경우 페이지가 BFCache에 저장된 상태이지만, true라고 해서 페이지가 반드시 캐시되는 것은 아니며, 브라우저가 캐시를 시도하지만 캐시할 수 없는 다른 요인이 있을 수 있습니다.
window.addEventListener('pagehide', function(event) {
if (event.persisted) {
console.log('이 페이지는 BFCache에 저장될 수 있습니다.');
} else {
console.log('이 페이지는 BFCache에 저장되지 않습니다.');
}
});또는 freeze , resume 도 있습니다.
4-4. BFCache와 단일 페이지 앱(SPA)
BFCache의 기능은 전통적인 웹 페이지 탐색에 초점을 맞추기 때문에 단일 패이지 앱(SPA)내의 “소프트 탐색”에서는 기본적으로 작동하지 않습니다.
SPA의 탐색(소프트 탐색)
SPA에서의 페이지 탐색은 보통 페이지를 새로 로드하지 않고, JavaScript를 사용하여 동적으로 컨텐츠를 교체하는 방식으로 이루어집니다.(React, Angular, Vue.js등)
이러한 “소프트 탐색”은 브라우저의 기본 탐색 메커니즘을 우회하기 때문에 BFCache가 작동하지 않습니다.
즉, 사용자가 SPA 내부에서 다른 섹션으로 이동할 때는 페이지 전체를 새로 로드하지 않기 때문에 BFCache가 필요하지 않기 때문에 사용자가 다른 페이지로 완전히 이동하거나 브라우저를 닫았다 돌아오는 경우가 아니면, 페이지 상태가 자동으로 저장되거나 복원될 일이 없습니다.
BFCache의 잠재적 활용
SPA의 경우 사용자가 브라우저를 통해 SPA를 떠났다가 뒤로가기나 앞으로가기 버튼으로 돌아올 때 BFCache의 이점을 활용할 수 있습니다. 예를들어 사용자가 SPA를 사용 중에 다른 웹사이트로 이동했다가 뒤로가기로 SPA로 돌아오면 브라우저는 BFCache를 사용하여 이전에 보았던 페이지 상태를 빠르게 복원할 수 있으며 이때, SPA는 처음부터 완전히 다시 로드되지 않고, 이전 세션의 상태(스크롤 위치, 사용자 입력, 페이지 상태 등)를 빠르게 복원할 수 있습니다.
4-5. SPA에서 BFCache 관련 주의점
동적 콘텐츠 갱신
- 예를 들어서 React로 만든 프로젝트에서 소셜 로그인을 하고 뒤로가기 버튼으로 로그인 페이지로 돌아갔을 때 이전에 보았던 페이지 상태가 BFCache를 통해 복원될 수 있습니다.
- 즉, SPA에서 동적으로 로드되는 콘텐츠(로그인 상태, 최신 뉴스 등)는 BFCache로 인해 최신 상태를 반영하지 못할 수 있기 때문에
pageshow이벤트를 활용하여 페이지가 BFCache에서 로드되었는지 확인하고 필요한 콘텐츠를 다시 로드할 수 있게 합니다.
서버 상태 동기화
- 서버 상태와 클라이언트의 상태가 다를 수 있는데, 사용자가 로그인 페이지로 돌아왔지만 서버에서는 세션이 만료된 경우 등입니다. 이런 경우 상태 확인 로직을 추가해야합니다.
4-6. Next.js로 만든 웹사이트에서 BFCache가 활성화되는 경우
일반적으로 SPA로 만든 웹 사이트는 BFCache가 활성화 되지 않는게 맞지만, Next.js를 사용하는 일부 웹 사이트에서 BFCache가 활성화되는 현상이 있는데 벨로그의 경우가 이런 경우입니다.
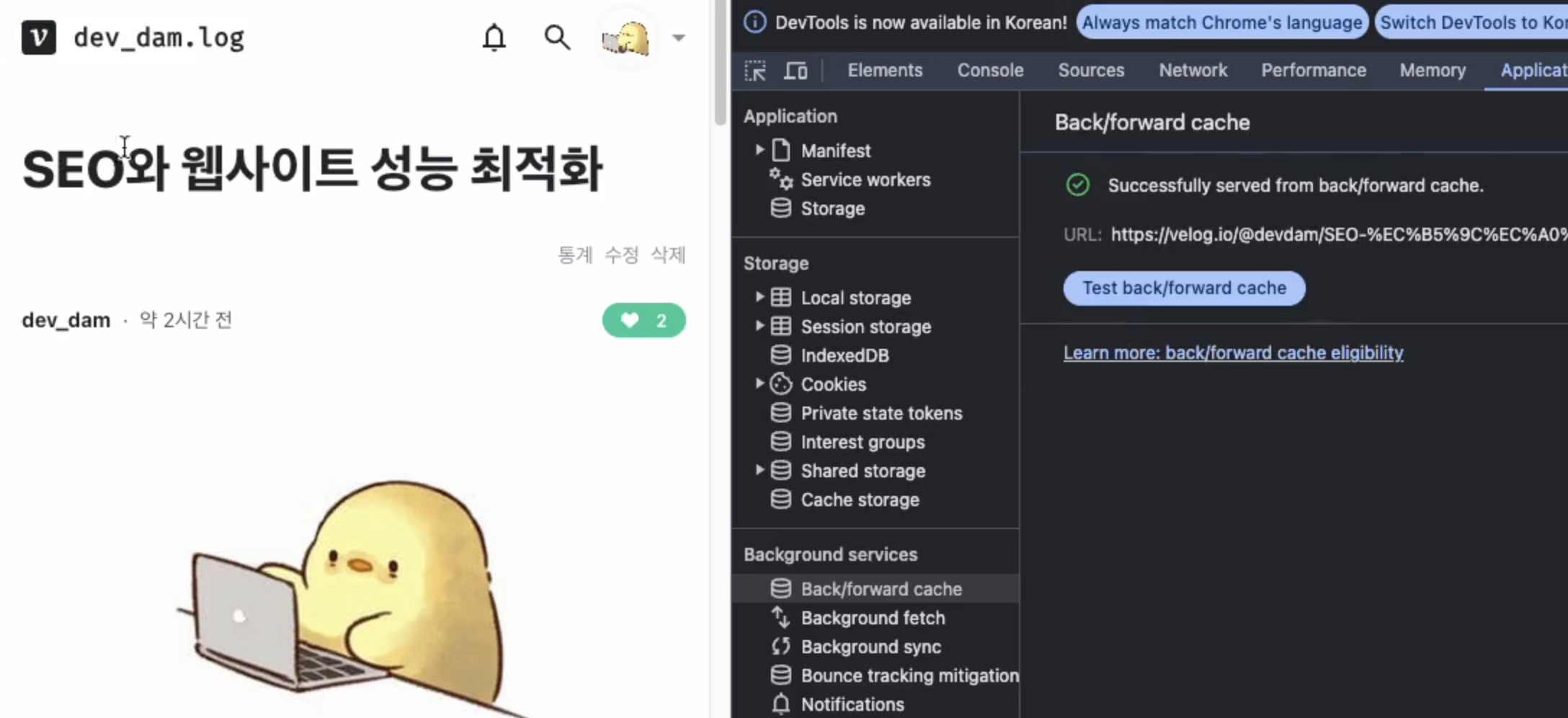
(동영상이 업로드 되지 않아 스크린샷을 첨부합니다. 개발자 툴에서 확인할 수 있습니다)
이 부분이 궁금해서 GPT로 확인했을 경우 Next.js는 서버사이드 렌더링(SSR)과 정적 사이트 생성(SSG)을 지원하기 때문에 라우팅 시에도 페이지가 빠르게 로드될 수 있도록 도와 준다고 합니다. 브라우저는 SSR과 SSG로 생성된 페이지를 더 쉽게 BFCache에 저장할 수 있다고 했고, wappalyzer 를 사용하여 Next.js를 사용하는 다른 웹사이트들의 경우 BFCache가 일반적으로 활성화되지 않는 경우가 많았던 것을 보면 CSR일 수 있겠다는 생각을 했습니다.
BFCache의 더 자세한 내용은 여기서 확인 가능합니다.
마무리
처음에는 간단히 라우터를 직접 구현하는 과정을 정리하고자 시작했었으나 라우터에 관해 학습하면서 BFCache를 공부하게 되면서 관련된 다양한 지식을 학습할 수 있었습니다.
앞으로도 단순히 어떤 것에 대해 학습을 할 때 좀 더 다양한 관점으로 바라보고 스터디할 수 있도록 노력해야겠습니다.


잘 보고 갑니다