어떤 기능을 최적화 했는가?
저는 깃허브와 연동하여 자신의 Repository들을 그룹화 시켜 관리할 수 있는 웹을 개발중에 있습니다.
그래서 내 깃허브와 연동하여(OAuth2) 로그인 할 때마다 자신의 Repository들을 얻어와서 기존 db에 있던 Repository와 sync를 맞춰줘야 하는 작업이 있습니다.
이 부분에서 기존 코드는 시간복잡도가 O(N * M)인 상황이었습니다.
그래서 이 부분을 개선해야겠다고 생각하여 최적화 작업에 들어갔습니다.
기존 코드는 아래와 같습니다.
private void _syncRepositoryDelete(List<GithubRepositoryRequest> newlyRepositories,
List<GithubRepository> repositories,
List<GithubRepositorySyncModel> sync) {
for(GithubRepository repository : repositories) {
boolean isExists = false;
for(GithubRepositoryRequest newly : newlyRepositories) {
if(newly.getRepositoryName().equals(repository.getRepositoryName())) {
isExists = true;
}
}
if(!isExists) {
sync.add(new GithubRepositorySyncModel(repository, true, false));
}
}
}
private void _syncRepositoryAdd(List<GithubRepositoryRequest> newlyRepositories,
List<GithubRepository> repositories,
List<GithubRepositorySyncModel> sync) {
for(GithubRepositoryRequest newly : newlyRepositories) {
boolean isExists = false;
for(GithubRepository repository : repositories) {
if(repository.getRepositoryName().equals(newly.getRepositoryName())) {
isExists = true;
sync.add(new GithubRepositorySyncModel(repository, false, true));
break;
}
}
if(!isExists) {
sync.add(new GithubRepositorySyncModel(newly.toEntity(), false, true));
}
}
}네.. 비효율의 끝판왕을 보여주고 있습니다.
그래서 O(N * M) 코드를 O(N)으로 개선할 방법을 생각하던 중
자료구조 LinkedList을 이용하면 될것같다는 생각이 들었습니다.
그래서 두 개의 데이터 (기존 db데이터, 새로 들어와서 기존 db와 sync를 맞춰줘야 하는 데이터)를 Linked-List에 넣고 정렬 기준은 레포지토리 이름으로 정렬하게 된다면 기존 데이터들이랑 sync가 맞을것이라고 생각하여 코드를 작성하였습니다.
(이전에 PriorityQueue를 이용하려고 했지만 데이터 이동이 있을 경우 재정렬 되어 배열이 흐트러지기때문에 LinkedList에 넣고 정렬하는 방식으로 바꿨습니다 그래서 PriorityQueue는 데이터를 뺄때마다 재정렬이 이루어져 LinkedList보다 느립니다.)
LinkedList는 데이터를 넣거나 뺄 경우 노드의 포인터만 바꿔주면 되기 때문에 poll(), add()가 O(1)으로 굉장히 빠르게 넣고 뺄 수있습니다.
그래서 LinkedList를 사용하기로 하였습니다.
/**
* O(N) sync
* @param objects1 기존 배열
* @param objects2 새로운 배열
* */
private static List<Object> syncArray(LinkedList<Object> objects1, LinkedList<Object> objects2) {
List<Object> result = new ArrayList<>();
List<Object> deleted = new ArrayList<>();
int olderSize = objects1.size();
int newlySize = objects2.size();
while(!objects1.isEmpty()) {
Object obj1 = objects1.peek();
Object obj2 = objects2.peek();
if(obj1.equals(obj2)) {
objects1.poll();
objects2.poll();
result.add(obj1);
}
else {
if (newlySize > olderSize) {
result.add(objects2.poll());
}
else {
deleted.add(objects1.poll());
}
}
}
return result;
}result 리스트에는 새로 추가해야할 값만 들어갑니다.
deleted 배열엔 지워야 할 값들이 들어갑니다.
기존 코드 성능 테스트
기존데이터 (N) = 100000
추가된 데이터/삭제된 데이터 (M) = 100001/99999
private static void _syncRepositoryDelete(Object[] objects1, Object[] objects2, List<Object> sync) {
for(Object repository : objects1) {
boolean isExists = false;
for(Object newly : objects2) {
if(newly.equals(repository)) {
isExists = true;
}
}
if(!isExists) {
sync.add(repository);
}
}
}
private static void _syncRepositoryAdd(Object[] newlyRepositories,
Object[] repositories,
List<Object> sync) {
for(Object newly : newlyRepositories) {
boolean isExists = false;
for(Object repository : repositories) {
if(repository.equals(newly)) {
isExists = true;
sync.add(repository);
break;
}
}
if(!isExists) {
sync.add(newly);
}
}
}이렇게 인자만 변경하여 테스트를 위한 코드를 만들고 기존 코드를 테스트 해봤습니다. 그리고 추가 및 삭제가 1개씩 이루어진 상황을 테스트 해보았습니다.
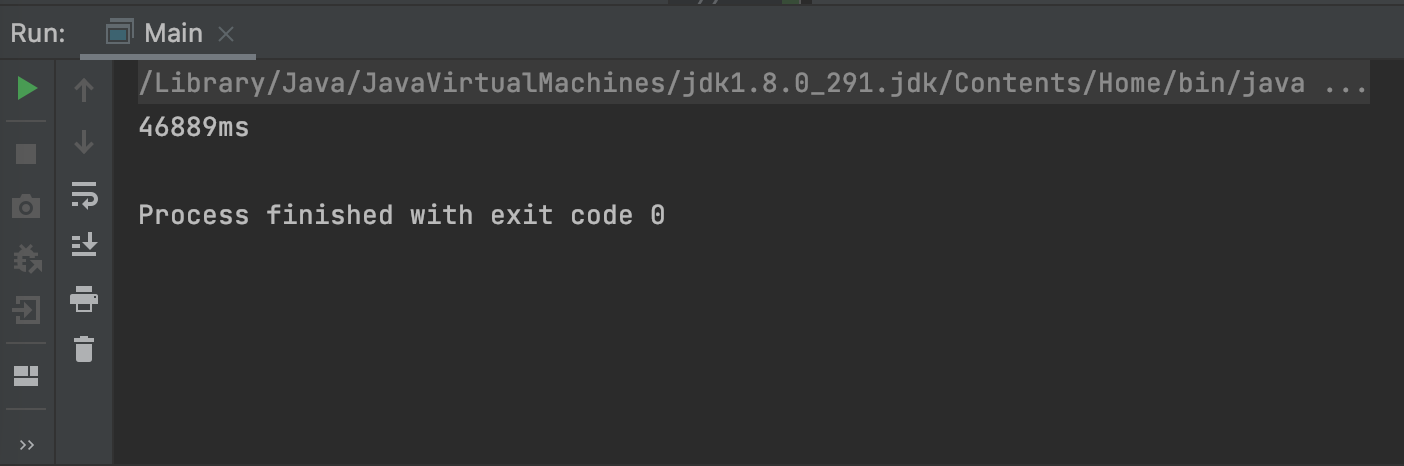
기존 알고리즘 - 결과1 (데이터 1개가 원격 저장소에서 생성된 상황)
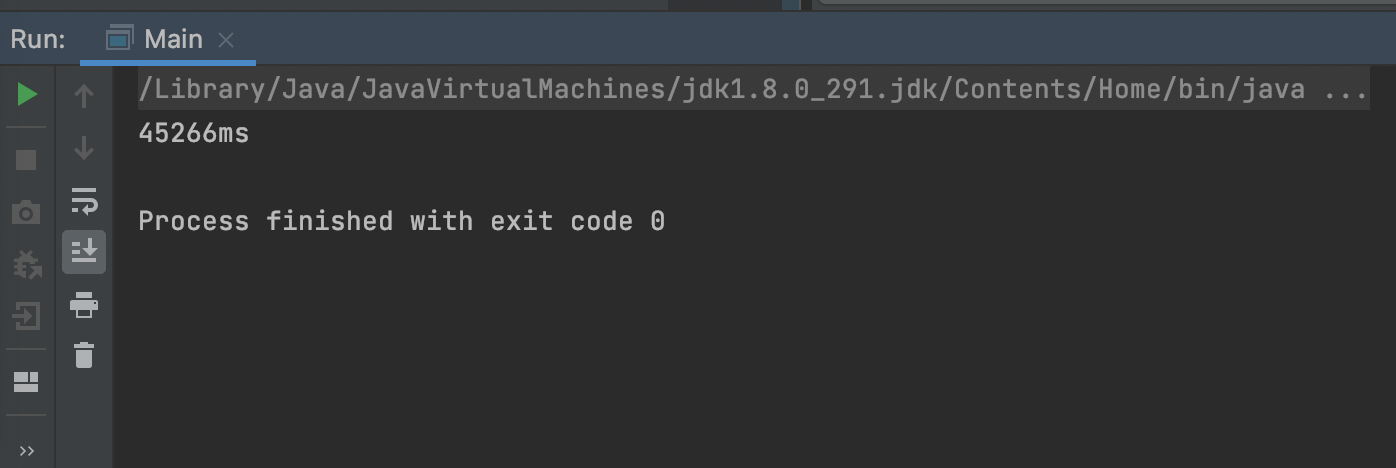
기존 알고리즘 - 결과2 (데이터 1개가 원격 저장소에서 삭제된 상황)
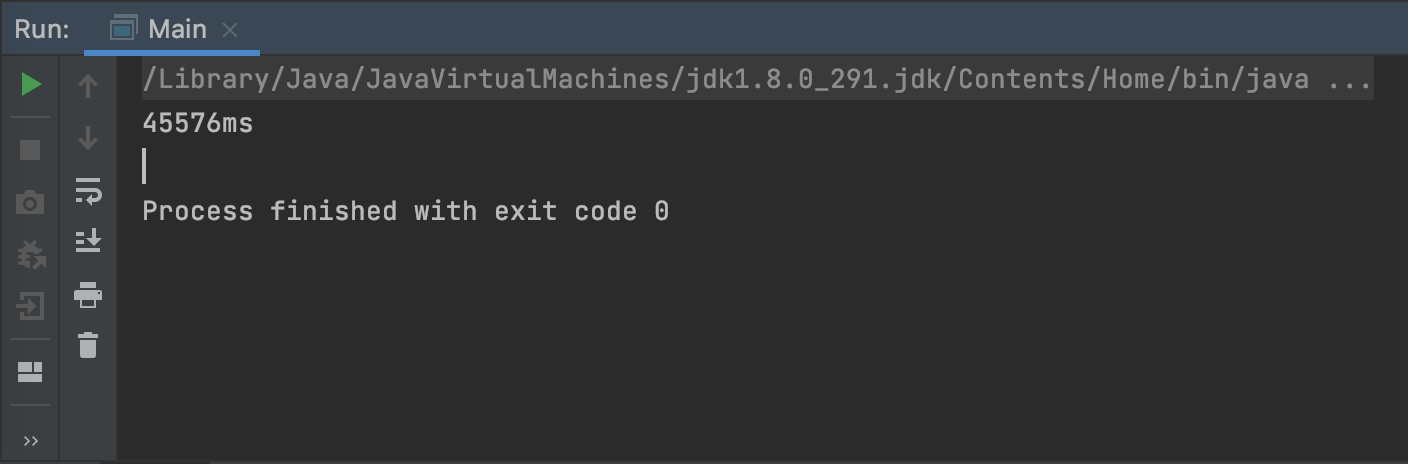
굉장히 참담한 결과입니다..
유저들이 100000개의 레포지토리를 가지고 있진 않겠지만 100개 이상의 레포지토리를 가지고 있다면 서비스를 이용하는데 굉장한 불편함을 느낄것입니다. 게다가 spring boot코드에서는 이 데이터들의 sync를 맞춰주고 db에 까지 넣어줘야하는 작업도 있으니 더 느릴것입니다.
그럼 이제 개선된 코드와 속도를 공개하겠습니다.
개선된 코드 성능 테스트
/**
* O(N) sync
* @param objects1 기존 배열
* @param objects2 새로운 배열
* */
private static List<Object> syncArray(LinkedList<Object> objects1, LinkedList<Object> objects2) {
List<Object> result = new ArrayList<>();
List<Object> deleted = new ArrayList<>();
int olderSize = objects1.size();
int newlySize = objects2.size();
while(!objects1.isEmpty()) {
Object obj1 = objects1.peek();
Object obj2 = objects2.peek();
if(obj1.equals(obj2)) {
objects1.poll();
objects2.poll();
result.add(obj1);
}
else {
if (newlySize > olderSize) {
result.add(objects2.poll());
}
else {
deleted.add(objects1.poll());
}
}
}
return result;
}개선된 알고리즘 결과1 - (데이터 1개가 원격 저장소에서 생성된 상황)
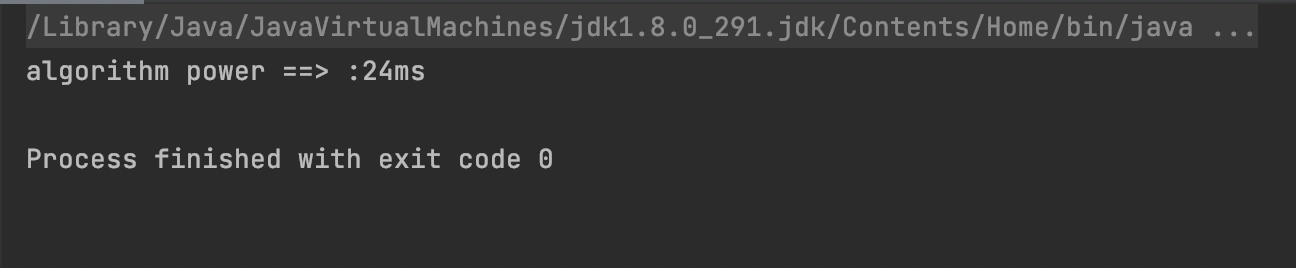
개선된 알고리즘 결과2 - (데이터 1개가 원격 저장소에서 삭제된 상황)
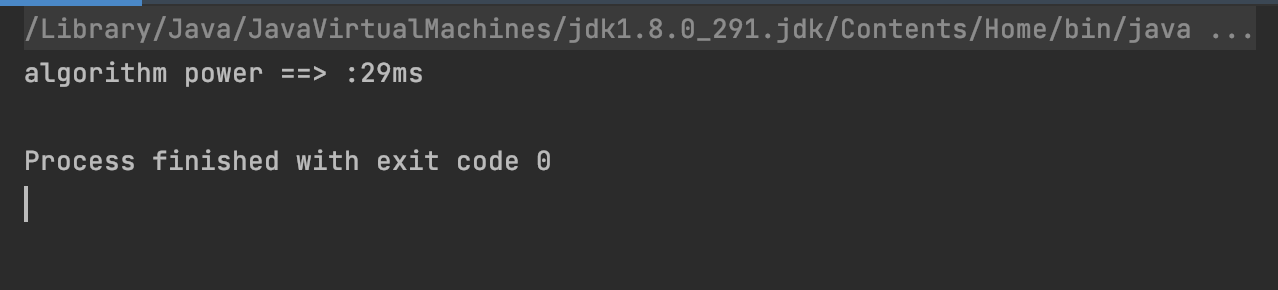
코드 퍼포먼스가 엄청 올라간걸 볼 수 있습니다.
45266ms -> 24ms
45576ms -> 29ms
대략 1728.5배만큼의 성능을 개선했다고 수치적으로 표현 할 수있습니다.
개선 후 적용된 spring-boot 코드
private Map<String, List<GithubRepository>> sync(List<GithubRepository> newly, List<GithubRepository> older) {
LinkedList<GithubRepository> olderQueue = toRepositorySorted(older);
LinkedList<GithubRepository> newlyQueue = toRepositorySorted(newly);
List<GithubRepository> result = new ArrayList<>(); // 추가할 것
List<GithubRepository> deleted = new ArrayList<>(); // 삭제할 것
Map<String, List<GithubRepository>> resultMap = new HashMap<>(); // sync 결과 맵
int newlySize = newlyQueue.size();
int olderSize = olderQueue.size();
//기존에 있던 큐들의 싱크를 맞춰주고 삭제할 것들을 추가해주는 작업
while(!olderQueue.isEmpty()) {
GithubRepository newlyRepository = newlyQueue.peek();
GithubRepository olderRepository = olderQueue.peek();
// 기존에 있었던 레포지토리이므로 큐에서 삭제
if(newlyRepository.getRepositoryName().equals(olderRepository.getRepositoryName())) {
newlyQueue.poll();
olderQueue.poll();
}
else {
if(newlySize > olderSize) {
result.add(newlyQueue.poll());
}
else {
deleted.add(olderQueue.poll());
}
}
}
resultMap.put("adding", result);
resultMap.put("delete", deleted);
return resultMap;
}
@Transactional
public void syncRepository(List<GithubRepository> newlyRepositories, Long ownerId) {
List<GithubRepository> repositories = repositoryCrud.findByOwner(ownerId);
Map<String, List<GithubRepository>> resultMap = sync(newlyRepositories, repositories);
List<GithubRepository> addRepositoryList = resultMap.get("adding");
List<GithubRepository> deleteRepositoryList = resultMap.get("delete");
for(GithubRepository addRepository : addRepositoryList) {
repositoryCrud.save(addRepository);
}
for(GithubRepository deleteRepository : deleteRepositoryList) {
repositoryCrud.deleteById(deleteRepository.getId());
}
}이 작업을 진행하면서 기본기의 중요성을 다시금 깨닫게 되는 시간이었습니다. 자료구조를 적재적소에 잘 사용하는게 코드의 성능을 올려줍니다.

좋은 포스팅 잘봤습니다!
GithubRepositry 객체에서 hashCode와 equals를 override해서 repositoryName을 기준으로 객체를 구분짓는다면 HashSet 로 O(1)만에 contains와 remove, add를 다 할수있을것같은데 이 방법은 어떤가요?
그렇게하면 LinkedList를 sort하는 오버헤드도 줄어들지 않을까요??