key
컴포넌트의 리스트를 렌더링할 때 각 요소에 고유 식별자를 할당하는데 사용된다.
또한 key는 React가 어떤 항목을 변경, 추가 또는 삭제할지 식별하는 것을 돕는다.
key를 선택하는 가장 좋은 방법은 리스트의 다른 항목들 사이에서 해당 항목을 고유하게 식별할 수 있는 문자열을 사용하는 것이지만(예 : 데이터의 ID) 안정적인 ID가 없다면 최후의 수단으로 항목의 인덱스를 key로 사용할 수 있다.
key를 사용하는 이유
React는 상태 변화가 일어나게 되었을 때 변화를 감지하고 리렌더링이 일어나게 된다.
우선 list와 같은 iterable한 객체를 렌더링해보자
function App() {
const [list, setList] = useState([
{
title: "1번째 요소",
id: 101
},
{
title: "2번째 요소",
id: 102
},
{
title: "3번째 요소",
id: 103
}
])
return (
<ul>
{datas.map(item => {
return <li>{item.id} {item.title}</li>
})}
</ul>
)
}React가 리스트는 고유한 key를 가져야한다는 오류를 반환해 알려준다.
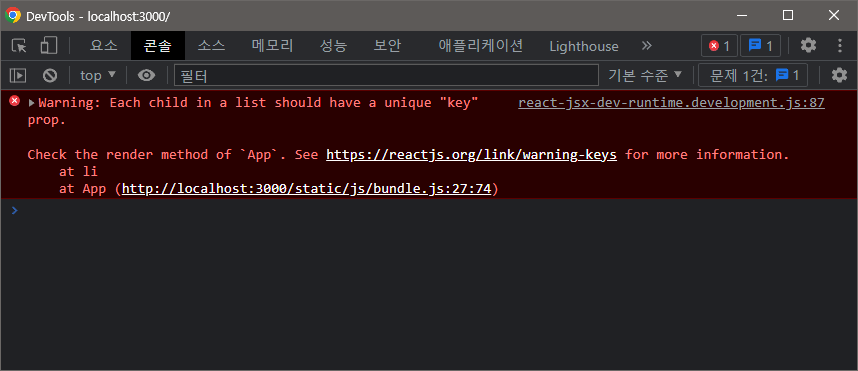
렌더링한 리스트에 상태 변화를 한번 일으켜보자
function App() {
const [list, setList] = useState([
{
title: "1번째 요소",
id: 101,
},
{
title: "2번째 요소",
id: 102,
},
{
title: "3번째 요소",
id: 103,
},
]);
function deleteOne() {
setList(list.filter(item => item.id !== 101))
}
return (<>
<button onClick={deleteOne}>첫번째 요소 삭제</button>
<ul>
{list.map((item) => {
return <li>{item.title}</li>;
})}
</ul>
</>);
}위 예시에서 버튼을 클릭하게 되면 첫번째 요소가 제거되게 되는데, 이 때 key라는 식별자 없이 렌더링 된 요소를 제거하게 되었을 때 내부에서는 기존 가상돔의 상태와 비교해 바뀐 부분부터 다시 렌더링하게 된다.
이와 같이 삭제된 요소가 있을 때 바뀐 부분부터 다시 렌더링하게 된다면 성능에 부정적인 영향을 끼치게 된다.
여기서 key를 쓰는 핵심적인 이유가 발생하는데,
리스트에 key라는 고유한 식별자가 지정되어 있다면 React는 key 값을 활용해 가상 돔에서 변경된 부분만 실제 DOM에 렌더링 해줄 수 있게 되는 재조정을 하게 된다.
고유한 key 값이 부여되어 있는 리스트는 변경사항을 빠르게 추적하고 DOM 업데이트를 최적화 할 수 있게 되는것이다.
쉽게 말해 삭제되거나 추가된 요소만 끼워넣거나 뽑아낼 수 있게 되는것이다.
고유한 key 값을 부여해 아까의 코드를 다시 작성해보면
function App() {
const [list, setList] = useState([
{
title: "1번째 요소",
id: 101,
},
{
title: "2번째 요소",
id: 102,
},
{
title: "3번째 요소",
id: 103,
},
]);
function deleteOne() {
setList(list.filter(item => item.id !== 101))
}
return (<>
<button onClick={deleteOne}>첫번째 요소 삭제</button>
<ul>
{list.map((item) => {
return <li key={item.id}>{item.title}</li>;
})}
</ul>
</>);
}이렇게 작성할 수 있다.
따라서 최상의 성능과 예상한 동작을 얻으려면 일반적으로 목록의 각 항목에 키 값을 지정하는 것이 좋다.
