
The Flux Pattern

Img source: Flux - Those who forget the past...
What is Flux? (vs. MVC)
Flux architecture is one way of handling complex data in which data only flows in one direction, created by Facebook for building client-side web apps and UI. The key idea behind Flux is that there is a single source of truth (the stores), and the only way to update it is by triggering actions. Actions are update requests that get sent to a dispatcher, which then gets broadcast to the stores via registered callbacks. Store data gets updated accordingly, and the state change triggers a re-rendering of what we see (the view).
It can be thought of as a design pattern and conceptual framework that is different from the Model-View-Controller(MVC) pattern, which supports a bi-directional data flow.
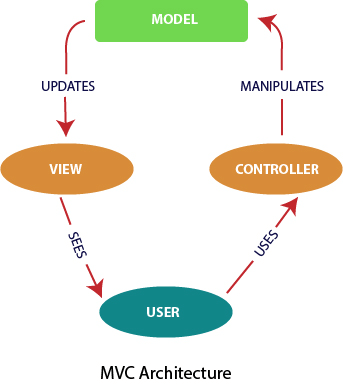
vs. Flux:
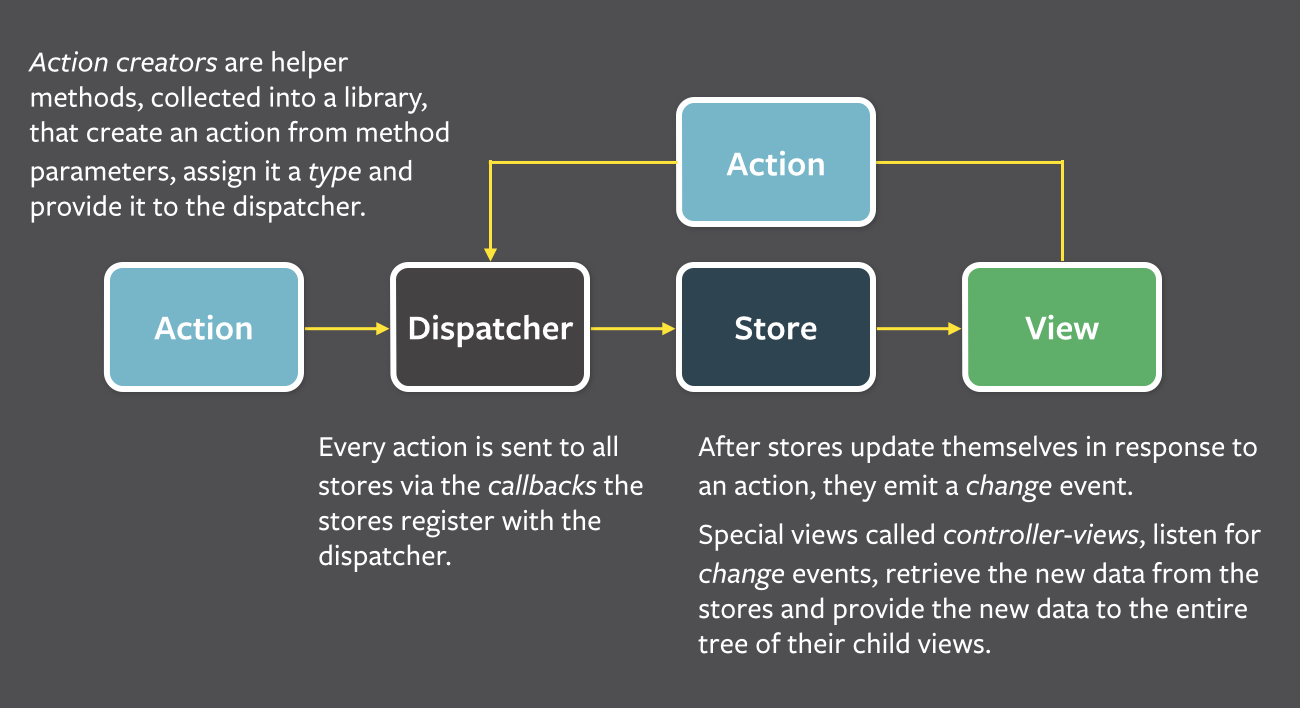
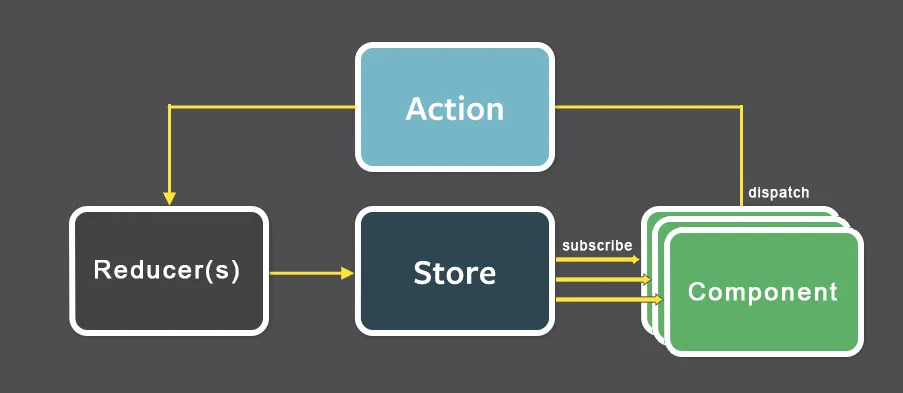
As shown in the diagram, data flows only one way in Flux. User interactions trigger the creation of action objects which are sent to a central dispatcher, which then passes the actions to all stores via its registered callbacks which when invoked, tell the store what to update and how.
Four major components of a Flux pattern are the dispatcher, stores, actions, and views.
- Action: When there is new data introduced to the system as a result of user interaction, that data gets packaged in the form of an object usually containing data on the source of the interaction and the specific type of action that source is bound to.
- The Store: Where all the states are managed. It changes the store by listening to actions, and notifies the views to update.
- Views (e.g. React components): Where the UI is rendered and user interactions happen. Views listen for changes in the store.
- The Dispatcher: The central hub in which the actions are received then broadcast to all registered stores.
Flux: Pros & Cons
While the flux way of doing things may seem needlessly complex to initiates, its structure makes the code and project much easier to debug and test, as well as read, maintain and scale as the project grows in size (at least, according to the sources I have read so far, but there are also those who cast doubt on this claim). Its structure supposedly makes clear where our data is coming from, what's causing it to change, how it changes, and also easy to track specific user flows, and so on. Its unidirectional data flow makes the data flow and interactions easier to manage.
Cons: its structural complexity might be overkill for simpler applications. You also end up writing a lot more code for to implement it. So you need to carefully consider whether the tradeoff is worth it or not.
Some popular tools based on the Flux architecture include Redux, Flummox, and Fluxxor.
Redux: Fundamentals
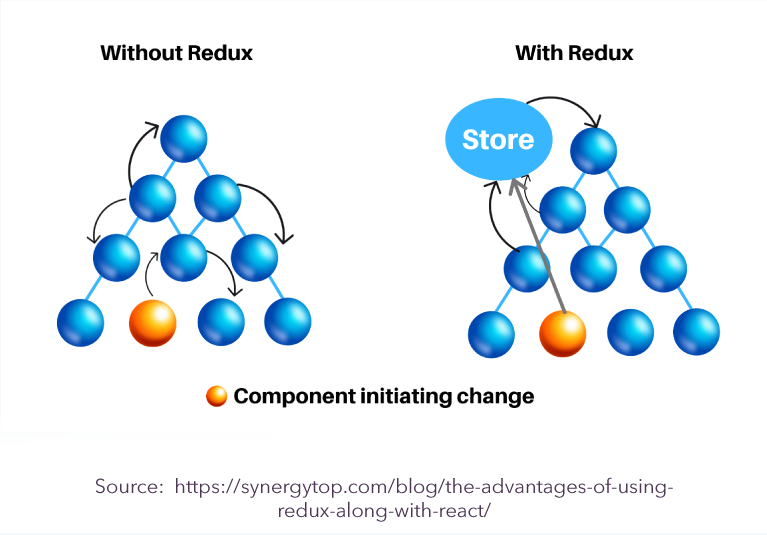
Redux was inspired by Flux, and made simpler by pure functions (state changes are made through pure reducer functions.) As I discussed in my previous post, redux helps us manage our states efficiently and effectively without triggering unnecessary re-renderings of components that are not affected by changes in these states.
Three Rules of Redux
Redux is based on the following three principles:
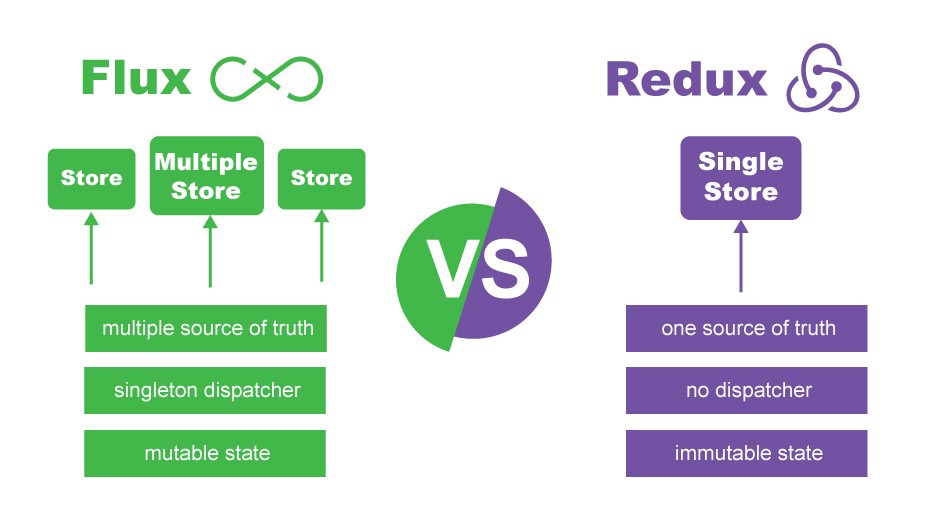
- State is the single source of truth. There is only one store in a Redux app (a single state object called the state or state tree, where all app data managed as a state is stored)
- The state is read-only. It can only be changed by dispatching an action to the store.
- Updates are made with pure functions (reducers). To describe state changes you must write a function that takes the current state and the action to perform. The function must return a new updated state, not a modified version of the existing state. These functions are called Reducers.
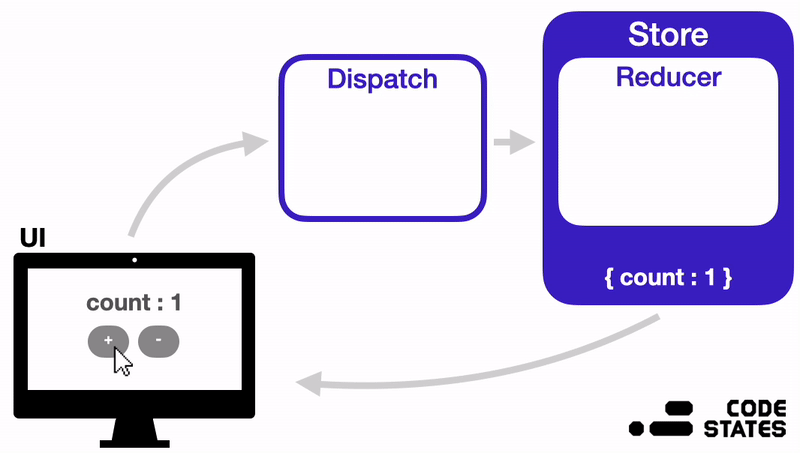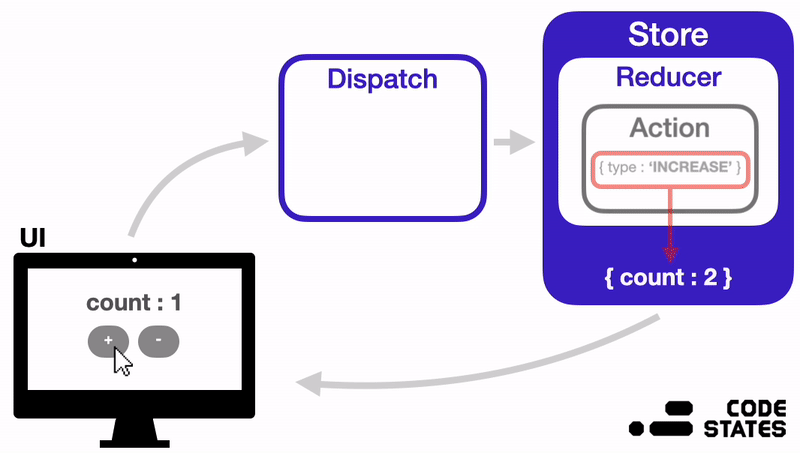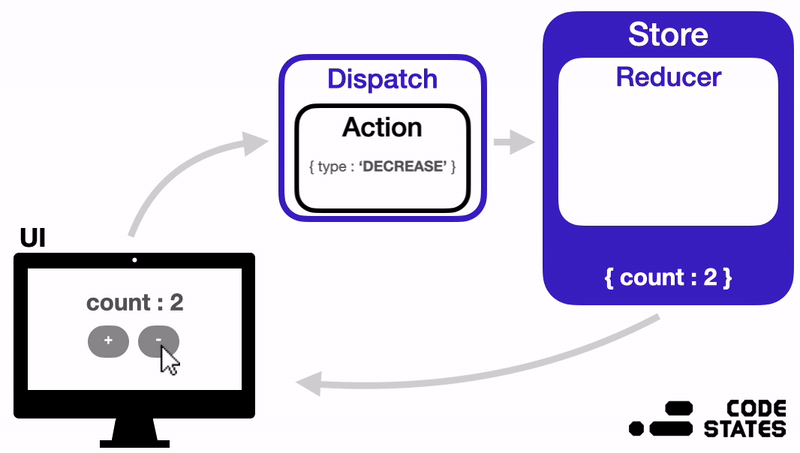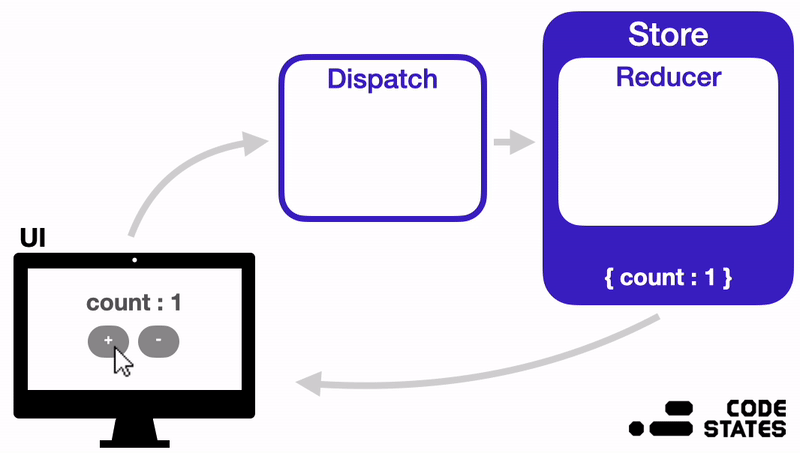
Data Flow
Action → Dispatch → Reducer → Store
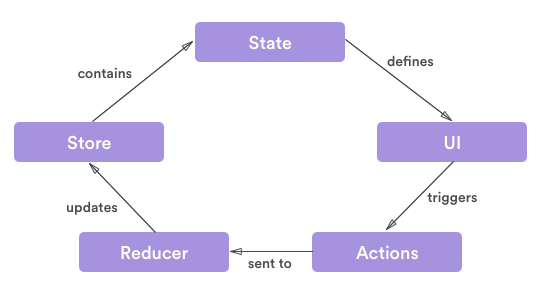
- When a state change event is triggered, an action object containing data on the state to be changed is created.
- This action object is passed as an argument to the dispatch function.
- The dispatch function delivers the action object to the reducer function.
- The reducer function checks the action object's value, and changes the Store's state accordingly.
- When the state is updated, React re-renders the view.
A more detailed diagram of how this works (also from U***y):
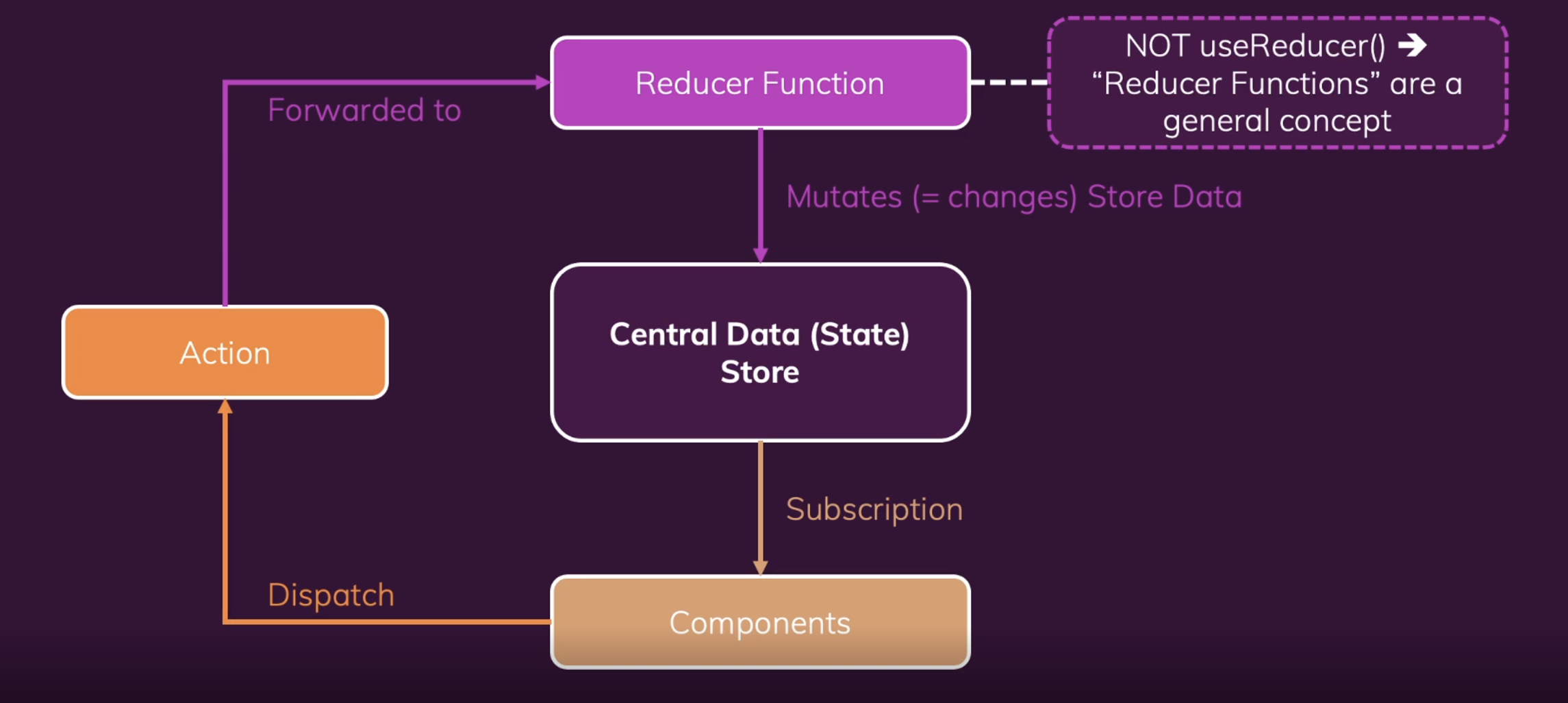
Breakdown of Redux Components
Example of file structuring recommended for implementing Redux
Flux vs. Redux
IMPORTANT: Dispatch function is different from the concept of dispatcher in Flux. Here's how ChatGPT explains it:


useReducer vs. Redux
What is Redux? According to Stephen Grider, Redux is a library for managing state using the same techniques as useReducer. So how do they differ?
Excerpts from U***y's popular lecture (Redux part highly recommended):
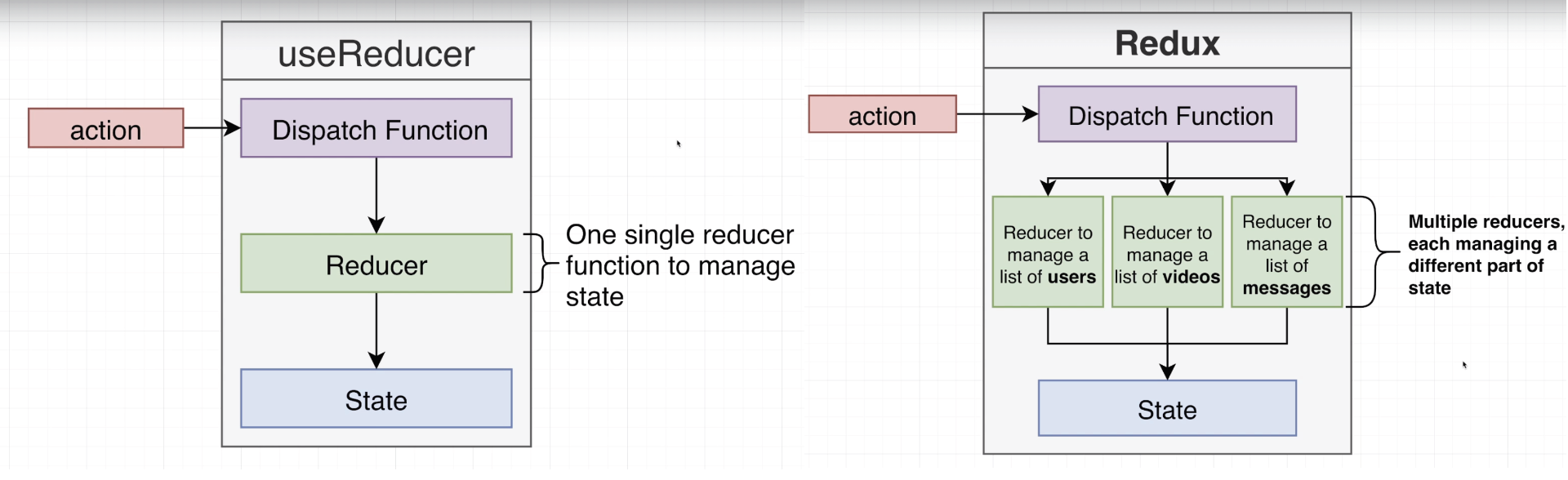
Unlike useReducer, Redux allows many different states within the store state, as well as multiple different reducer functions. State object has several different properties (sub sections), and different reducers can control different parts of it. This is preferable to having one huge reducer function if you need to manage many different kind of states and apply different logic to changing them.
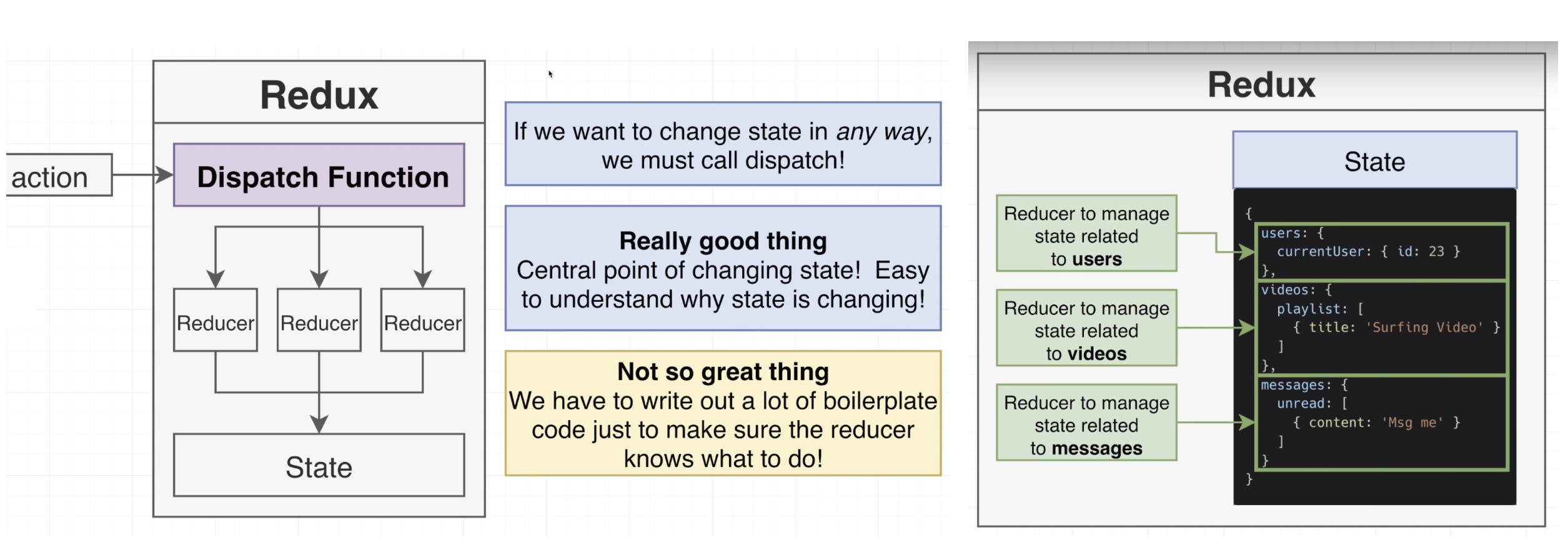
According to Grider, if you don't need multiple reducers, maybe you don't need to be using Redux at all. He also details why we should be using the Redux-toolkit below.
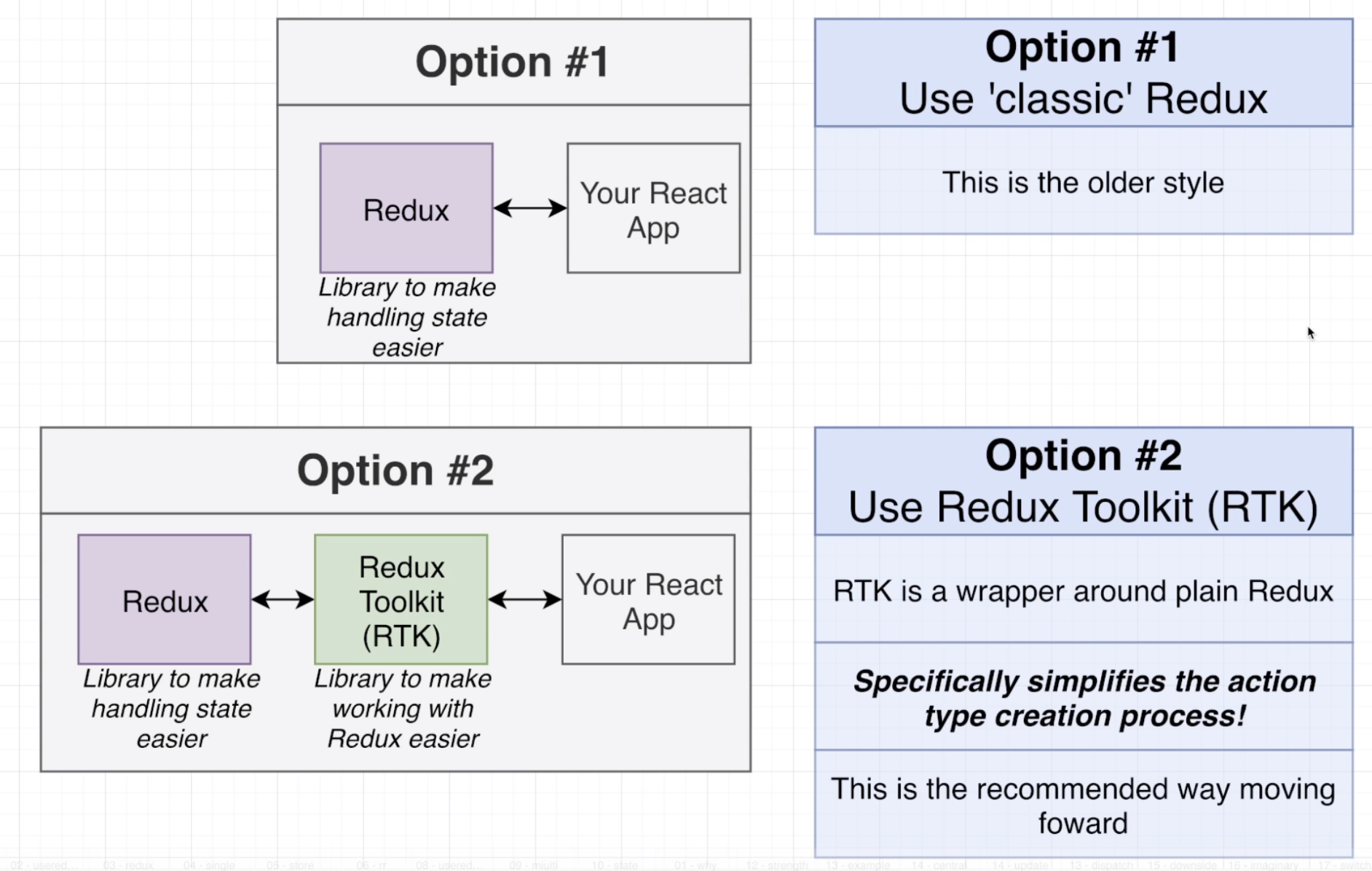
To be added later...
- The nitty gritty of implementing Redux (incl. attaching payload to action (what is a payload? why is it called that?)
References
Flux & Redux
Introduction to Flux
Flux: Actions and the Dispatcher
React Flux vs MVC
MVC vs Flux vs Redux – The Real Differences
Flux vs. Redux: A Comparison (img source)
What is the Flux app architecture?: Is it really simpler and more predictable than MVC?
Redux: Overview
Redux Core Concepts You Need to Know
Redux.js: Prior Art
What is Redux: React Redux Tutorial for Beginners
Updating State with Redux
Immutable Update Patterns
Few Ways to Update a State Array in Redux Reducer
