
Logstash란?
Logstash는 구조화되지 않은 데이터를 구조화되고 쿼리 가능한 것으로 구문 분석하는 Opensource 입니다.
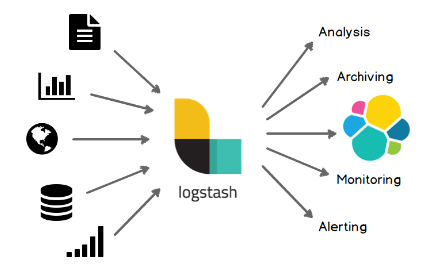
위의 이미지는 Logstash를 한장으로 아주 잘 요약한 이미지 입니다.
여러 비정형데이터들을 Logstash를 통해 수집, 가공하여 원하는 목적지에 적재할 수 있습니다.
비정형 데이터 : 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보
Logstash Pipeline
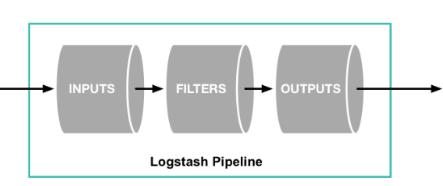
Logstash는 실시간 파이프라인 기능을 가진 오픈소스 데이터 수집 엔진 Logstash는 서로 다른 소스의 데이터를 통합하고 사용자가 선택한 목적지로 데이터를 정규화할 수 있습니다.
Logstash는 다음과 같은 파이프라인을 구성하고 있으며, plugin이 매우 다양하게 존재합니다.
Input
다양한 종류의 비정형 데이터(file, http, tcp, kafka, ...)들을 Input으로 받을 수 있습니다.
원하는 Input을 받기 위해 logstash가 제공하는 플러그인을 사용하면 되며, 원하는 플러그인을 직접 만들 수도 있습니다.
* 공식문서 링크
queue
Logstash는 자체적으로 메모리 큐를 사용합니다. 메모리는 휘발성을 갖고 있기 때문에 문제 상황시 1회의 전송을 보장하기 위한 큐를 별도로 가지고 있습니다.
Persistent queues : Disk의 내부 큐에 이벤트를 저장하여 데이터 손실을 방지합니다.
Dead letter queues : 성공적으로 처리되지 않은 이벤트(처리할 수 없는 이벤트)에 대한 Disk 저장소를 제공하여 사용자가 이벤트를 평가할 수 있도록 합니다.
dead_letter_queue 입력 플러그인을 사용하면 이벤트를 쉽게 재처리할 수 있습니다.
* 공식문서 링크
Filter
데이터를 실제로 사용하기 위해서 가공하는 단계입니다.
대표적으로 grok, mutate 필터 등 다양한 플러그인이 존재합니다.
Output
데이터를 전송할 목적지, 가동된 데이터를 "어딘가의 저장소"에 적재합니다.
* 공식문서 링크
Logstash는 위와 같이 파이프라인을 Input-(queue)-Filter-Output으로 구성하며 순차적으로 실행됩니다.
Logstash 파이프라인은 서비스에 어떤 데이터가 필요한지 정의하고, 이에 따라 어떤 플러그인을 선택하여 필터링 할 것 인가를 고민하여 설계해야 합니다.
