📢 본 글은 혼공학습단 미션과 함께 정리해보는 글 입니다.
소스 코드와 명령어
개발자가 작성한 코드를 컴퓨터가 바로 직독직해할 수 있는 것은 아니다.
모든 소스 코드는 컴퓨터 내부에서 명령어로 변환된다.
저급 언어
컴퓨터가 직접 이해하고 실행할 수 있는 언어를 뜻한다. 기계어와 어셈블리어가 있다.
기계어
0과 1의 명령어 비트로 이루어진 언어다.- 0과 1으로만 표현되기 때문에 어떤 의미인지 이해하기 어렵다.
어셈블리어
- 기계어의 뜻을 조금이나마 유추할 수 있도록 만들어진 언어다.
- 즉
0과 1로 이루어진 기계어를 읽기 편한 형태로 번역한 언어다. - 기계어를 번역하긴 했지만 더 쉽게 이해할 수 있는 언어가 필요하다. → 고급 언어의 등장
고급 언어
사람을 위해 만들어진 언어를 뜻하며, 우리가 알고 있는 대부분의 프로그래밍 언어가 고급 언어에 해당된다.
컴파일 언어
컴파일 방식으로 작동하는 프로그래밍 언어를 뜻한다.컴파일은컴파일러에 의해 소스 코드가 저급 언어로 변환되는 것이다. 이때 만들어진 저급 언어를목적 코드 (= 원시 코드)라 한다.
- 소스 코드 내에서 오류를 하나라도 발견하면 컴파일에 실패한다.
인터프리터 언어
인터프리트 방식으로 작동하는 프로그래밍 언어를 뜻한다.인터프리터에 의해소스 코드가 한 줄씩 실행되는 언어이다.- 소스 코드 전체를 저급 언어로 변환하는 시간을 기다릴 필요가 없다.
- 소스 코드 N번째 줄에 문법 오류가 있더라도 N-1번째 줄 까지는 올바르게 수행된다.
- 컴파일 언어에 비해 느리다.
소스 코드 마지막에 이를 때까지 한줄씩 저급 언어로 해석하며 실행해야 하기 때문이다.
컴파일 언어와 인터프리터 언어는 딱 잘라 구분될 수 없다.
인터프리터 언어인 파이썬도 컴파일을 아예 하지 않는 것은 아니며, 자바 또한 저급 언어가 되는 과정에서 컴파일과 인터프리트를 동시에 실행한다.
프로그래밍 언어를 컴파일 언어와 인터프리터 언어로 구분하기보다는고급 언어가 저급 언어로 변환되는 방법이 컴파일과 인터프리터라고 생각하는 게 좋다.
명령어의 구조
명령어의 구조는 다음과 같이 구성된다.
연산 코드와 오퍼랜드
명령어는 무엇을 대상으로 무엇을 수행하라는 구조로 이루어져 있다.
연산 코드
명령어가 수행할 연산을연산 코드(operation code, 연산자)라 한다.- 데이터 전송, 산술/논리 연산, 제어 흐름 변경, 입출력 제어 등을 기본적으로 가진다.
- CPU에 따라 연산 코드의 종류와 생김새가 다르다.
오퍼랜드
연산에 사용할 데이터또는연산에 사용할 데이터가 저장된 위치 (이것을 더 많이 사용)를오퍼랜드(operand, 피연산자)라고 한다.- 오퍼랜드는 명령어 안에 하나도 없을 수도 있고 여러 개 있을 수도 있다. 그 갯수에 따라
n-주소 명령어라고 한다.
주소 지정 방식
오퍼랜드에는 연산에 사용할 데이터가 저장된 위치를 저장할 수도 있다고 하였다. (그리고 이 경우가 더 많다.)
이 이유는 명령어 내에서 표현할 수 있는 데이터의 크기가 제한되기 때문이다.
전체 명령어가 16비트이고 연산 코드 필드가 4비트인 2-주소 명령어에서는 오퍼랜드 필드 당 6비트만 쓸 수 있다. 즉 가지의 정보를 표현할 수 있다. 만약 오퍼랜드가 많아진다면 표현할 수 있는 데이터는 적어질 것이다.
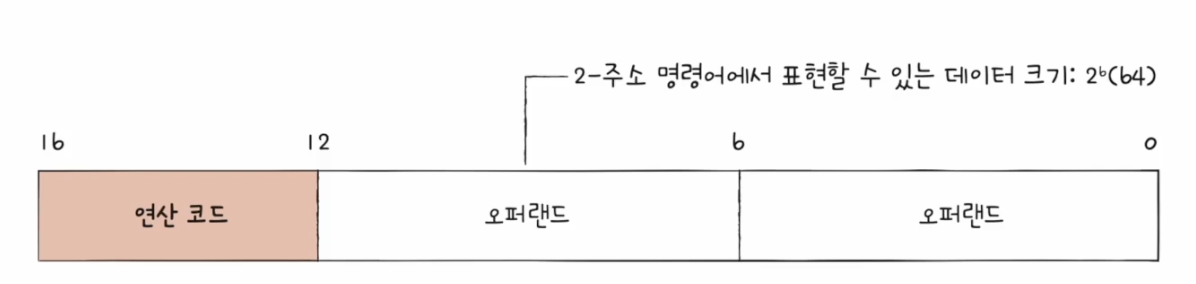
그런데 오퍼랜드 필드 안에 메모리 주소가 담긴다면, 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다.
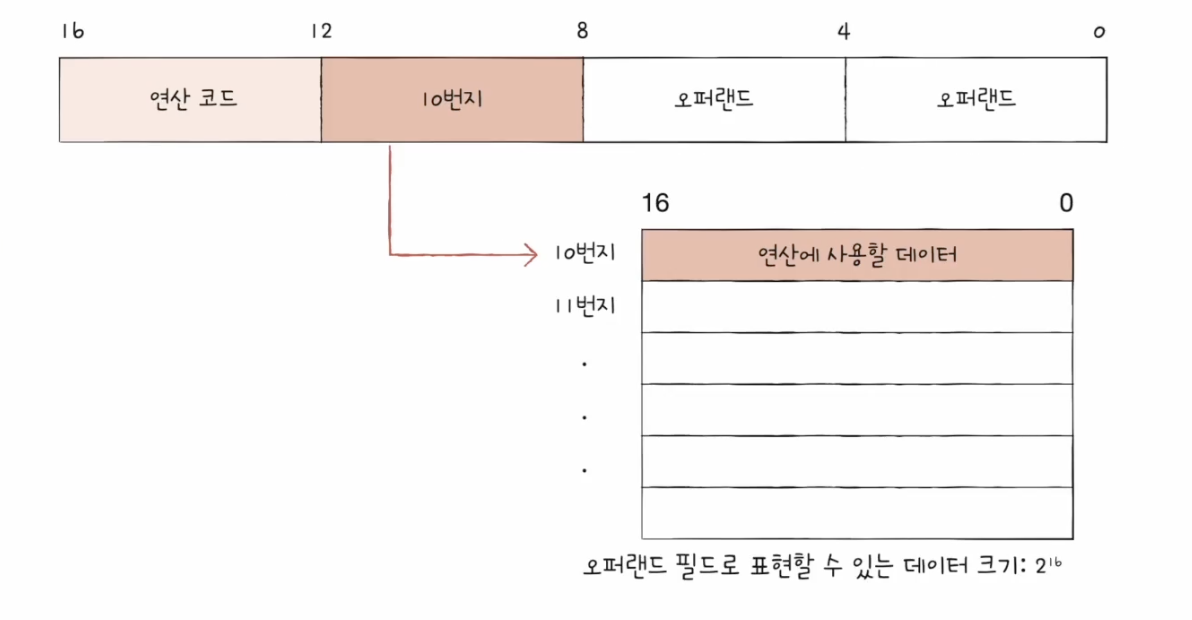
한 주소에 16비트를 저장할 수 있는 구조이므로 오퍼랜드에 다른 주소값을 저장해둔다면 해당 주소를 통해 표현할 수 있는 데이터 크기는 가지일 것이다.
레지스터 이름을 넣어두면 이 또한 표현할 수 있는 정보의 가짓수는 해당 레지스터가 사용할 수 있는 공간만큼 된다.

유효 주소 (effective address)
연산의 대상이 되는 데이터가 저장된 위치를 유효 주소라고 한다.
명령어 주소 지정 방식 (addressing mode)
CPU는 자신이 실행해야 할 명령어에 쓰일 데이터들을 찾아야 한다. 그리고 이들의 위치를 찾는 방법을 주소 지정 방식이라고 한다.
즉 주소 지정 방식은 유효 주소를 찾는 방법을 뜻한다.
레지스터에 대해 더 공부해야만 이해할 수 있는 주소 지정 방식들은 더 나중에 다룬다.
1️⃣ 즉시 주소 지정 방식 (immediate addressing mode)
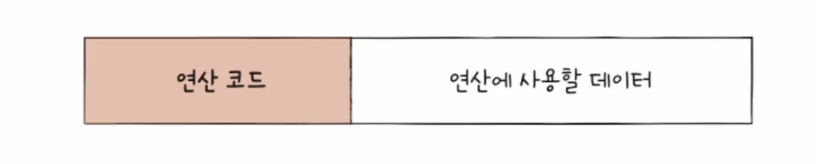
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방법
- 표현할 수 있는 데이터의 크기가 작아짐
- 연산에 사용할 데이터를 다른 곳에서 찾을 필요가 없어 다른 주소 지정 방식들보다 빠름
2️⃣ 직접 주소 지정 방식 (direct addressing mode)

- 오퍼랜드 필드에 유효 주소 직접적으로 명시
- 유효 주소를 표현할 수 있는 크기가 연산 코드만큼 줄어든다. (연산 코드의 크기에 영향을 받는다. 표현할 수 있는 유효 주소에 제한이 생기는 것이다.)
3️⃣ 간접 주소 지정 방식 (indirect addressing mode)
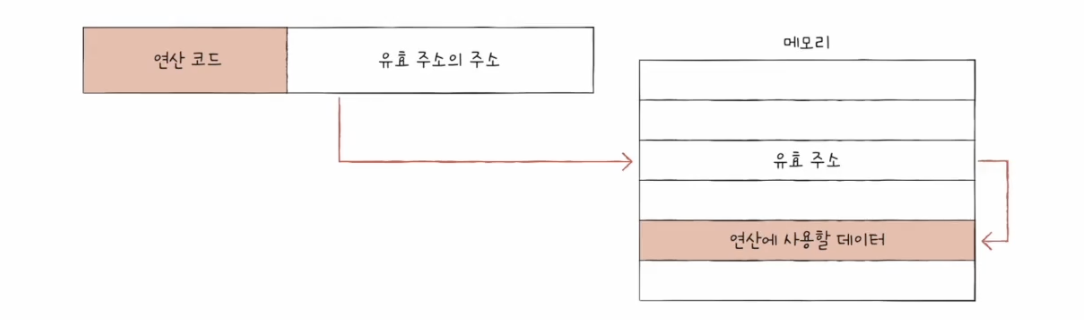
- 오퍼랜드 필드에 유효 주소의 주소를 명시
- 앞선 주소 지정 방식들에 비해 속도가 느리다
4️⃣ 레지스터 주소 지정 방식 (register addressing mode)
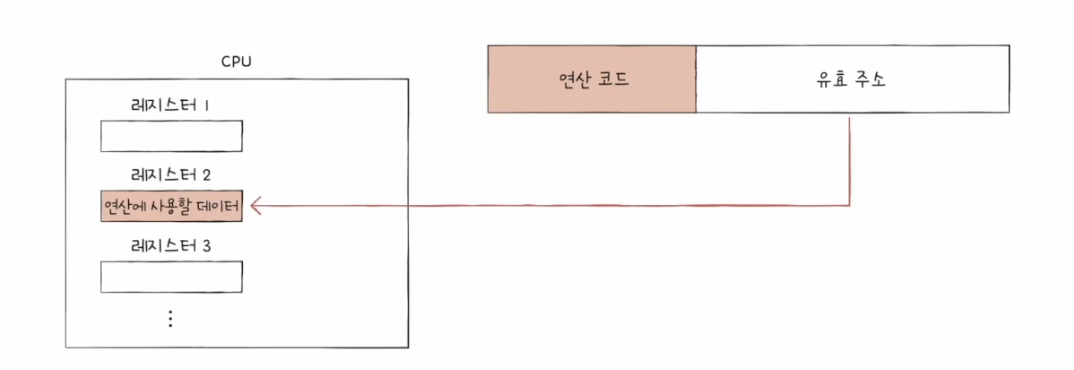
- 연산에 사용할 데이터가 저장된 레지스터를 명시한다.
- 메모리에 접근하는 속도보다 레지스터에 접근하는 게 빠르다.
- 직접 주소 지정 방식처럼 표현할 수 있는 레지스터 크기에 제한이 생긴다.
5️⃣ 레지스터 간접 주소 지정 방식 (register indirect addressing mode)
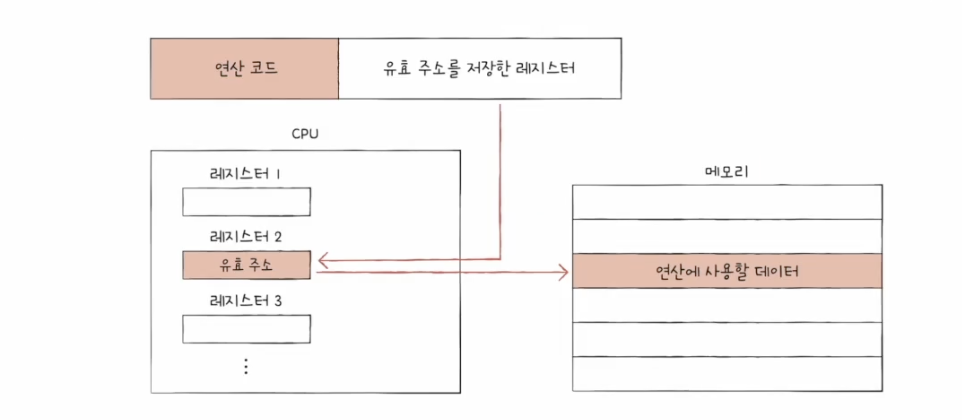
- 연산에 사용할 데이터를 메모리에 저장
- 해당 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
- 메모리에 접근하는 게 한 번이기 때문에 간접 주소 지정 방식보다 빠름
미션
스택과 큐에 대해 개념 정리하기
스택 (Stack)
- 먼저 들어간 게 나중에 나오는 (
LIFO, Last-In-First-Out) 구조이다. - 데이터를 삽입하는 것을 PUSH, 데이터를 꺼내는 것을 POP이라 한다.
- 실생활의 예시로는 프링글스가 있다.
큐 (Queue)
- 먼저 들어간 게 먼저 나오는 (
FIFO, First-In-First-Out) 구조이다. - 데이터를 삽입하는 것을 OFFER, 데이터를 꺼내는 것을 POLL이라 한다.
- 실생활의 예시로는 놀이공원 줄이 있다.
자바에서의 적용
자바에서는 스택과 큐를 ArrayDeque로 구현할 수 있다.
ArrayDeque<Integer> queue = new ArrayDeque<>();
queue.addFirst(5); // [5] → poll 방향도 같다면 스택 (pollFirst), 반대라면 큐 (pollLast)
queue.addLast(2); // [5, 2] → 스택, 큐 구현 시 활용
queue.pollFirst(); // [5] 제거 → 큐 구현 시 활용
queue.pollLast(); // [2] 제거 → 스택 구현 시 활용부족하거나 보완할 점이 있다면 댓글 부탁드립니다 😃
