문제
두 개의 배열(base, sample)을 입력받아 sample이 base의 부분집합인지 여부를 리턴해야 합니다.
<주의사항>
시간 복잡도를 개선하여, Advanced 테스트 케이스(base, sample의 길이가 70,000 이상)를 통과해 보세요.
이 문제를 풀기위해 접근했었던 방법들...(시간복잡도 고려X)
이중반복문 사용
sample배열의 요소를 훑으면서 base요소와 같은지 확인
const isSubsetOf = function(base, sample){
let count = 0;
for(let i=0; i<sample.length; i++){
for(let j=0; j<base.length; j++){
if(sample[i] === base[j]){
count = count + 1;
}
}
}
return count === sample.length;
} 중복요소 제거
base와 sample을 합한 다음 중복되는 요소 제거하고,
제거하고 나서 나온 배열이 base와 일치하는지 보기?
이 방법 또한 중복되는 요소를 제거하면서 시간복잡도가 높아진다.
const isSubsetOf = function(base, sample){
let newArr = base.concat(sample); //합치고
const uniqueArr = newArr.filter((el, index) => newArr.indexOf(el) === index);
//중복되는 요소 제거하기
return JSON.stringify(uniqueArr)===JSON.stringify(base) ;
}every & includes 메소드 사용
every 함수는 배열의 모든 요소가 callbackFunction 에서 true를 리턴해야 true를 리턴, 하나라도 false가 떨어지면 false를 리턴한다.
하지만 이 방법 또한 모든 요소를 탐색하므로 시간복잡도가 높아진다.
const isSubsetOf = function(base, sample){
return sample.every((item) => base.includes(item));
}시간복잡도를 고려한 최종 코드
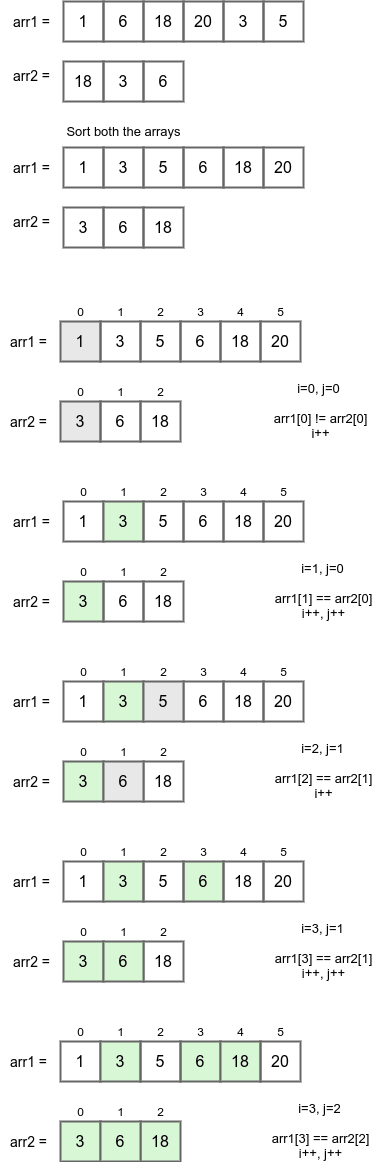
위 사진처럼, 먼저 base와 sample을 정렬시킨다.
sample의 요소와 일치하는지 base 요소들을 탐색할 때 특정범위만 탐색하는 것이 이 문제의 해결 포인트이다!
처음 일치하는 요소의 인덱스 값을 저장해두었다가(baseIdx) 다음 요소를 탐색할 때는 baseIdx부터 탐색을 시작한다.
const isSubsetOf = function (base, sample) {
base.sort((a, b) => a - b);
sample.sort((a, b) => a - b);
// base, sample 배열을 각각 정렬해서
// 만약에 못찾은 상태에서 더 큰 숫자를 탐색하면 바로 false
const findItemInSortedArr = (item, arr, from) => {
for (let i = from; i < arr.length; i++) { //from이하로는 다시 탐색할 필요 없음
if (item === arr[i]) return i;
else if (item < arr[i]) return -1;
}
return -1;
};
let baseIdx = 0;
for (let i = 0; i < sample.length; i++) {
baseIdx = findItemInSortedArr(sample[i], base, baseIdx); //baseIdx이하로는 다시 탐색할 필요 없음
if (baseIdx === -1){
return false; //하나라도 불포함인 것을 알아내면 바로 false
}
}
return true;
};
우당탕탕 개발일기📝🤖